
polaris
Foster the development of impactful AI models in drug discovery.
Stars: 111
Polaris establishes a novel, industry‑certified standard to foster the development of impactful methods in AI-based drug discovery. This library is a Python client to interact with the Polaris Hub. It allows you to download Polaris datasets and benchmarks, evaluate a custom method against a Polaris benchmark, and create and upload new datasets and benchmarks.
README:
| Latest Release |  |
 |
|
| Python Version |  |
| License | |
| Downloads |  |
 |
|
| Citation |
Polaris establishes a novel, industry‑certified standard to foster the development of impactful methods in AI-based drug discovery.
This library is a Python client to interact with the Polaris Hub. It allows you to:
- Download Polaris datasets and benchmarks.
- Evaluate a custom method against a Polaris benchmark.
- Create and upload new datasets and benchmarks.
import polaris as po
# Load the benchmark from the Hub
benchmark = po.load_benchmark("polaris/hello-world-benchmark")
# Get the train and test data-loaders
train, test = benchmark.get_train_test_split()
# Use the training data to train your model
# Get the input as an array with 'train.inputs' and 'train.targets'
# Or simply iterate over the train object.
for x, y in train:
...
# Work your magic to accurately predict the test set
predictions = [0.0 for x in test]
# Evaluate your predictions
results = benchmark.evaluate(predictions)
# Submit your results
results.upload_to_hub(owner="dummy-user")Please refer to the documentation, which contains tutorials for getting started with polaris and detailed descriptions of the functions provided.
Please cite Polaris if you use it in your research. A list of relevant publications:
-
- Preprint, Method Comparison Guidelines.
-
- Nature Correspondence, Call to Action.
-
- Zenodo, Code Repository.
You can install polaris using conda/mamba/micromamba:
conda install -c conda-forge polarisYou can also use pip:
pip install polaris-libconda env create -n polaris -f env.yml
conda activate polaris
pip install --no-deps -e .Other installation options
Alternatively, using [uv](https://github.com/astral-sh/uv):
```shell
uv venv -p 3.12 polaris
source .venv/polaris/bin/activate
uv pip compile pyproject.toml -o requirements.txt --all-extras
uv pip install -r requirements.txt
```
You can run tests locally with:
pytestUnder the Apache-2.0 license. See LICENSE.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for polaris
Similar Open Source Tools
polaris
Polaris establishes a novel, industry‑certified standard to foster the development of impactful methods in AI-based drug discovery. This library is a Python client to interact with the Polaris Hub. It allows you to download Polaris datasets and benchmarks, evaluate a custom method against a Polaris benchmark, and create and upload new datasets and benchmarks.
star-vector
StarVector is a multimodal vision-language model for Scalable Vector Graphics (SVG) generation. It can be used to perform image2SVG and text2SVG generation. StarVector works directly in the SVG code space, leveraging visual understanding to apply accurate SVG primitives. It achieves state-of-the-art performance in producing compact and semantically rich SVGs. The tool provides Hugging Face model checkpoints for image2SVG vectorization, with models like StarVector-8B and StarVector-1B. It also offers datasets like SVG-Stack, SVG-Fonts, SVG-Icons, SVG-Emoji, and SVG-Diagrams for evaluation. StarVector can be trained using Deepspeed or FSDP for tasks like Image2SVG and Text2SVG generation. The tool provides a demo with options for HuggingFace generation or VLLM backend for faster generation speed.
aichat
Aichat is an AI-powered CLI chat and copilot tool that seamlessly integrates with over 10 leading AI platforms, providing a powerful combination of chat-based interaction, context-aware conversations, and AI-assisted shell capabilities, all within a customizable and user-friendly environment.
MaskLLM
MaskLLM is a learnable pruning method that establishes Semi-structured Sparsity in Large Language Models (LLMs) to reduce computational overhead during inference. It is scalable and benefits from larger training datasets. The tool provides examples for running MaskLLM with Megatron-LM, preparing LLaMA checkpoints, pre-tokenizing C4 data for Megatron, generating prior masks, training MaskLLM, and evaluating the model. It also includes instructions for exporting sparse models to Huggingface.

Consistency_LLM
Consistency Large Language Models (CLLMs) is a family of efficient parallel decoders that reduce inference latency by efficiently decoding multiple tokens in parallel. The models are trained to perform efficient Jacobi decoding, mapping any randomly initialized token sequence to the same result as auto-regressive decoding in as few steps as possible. CLLMs have shown significant improvements in generation speed on various tasks, achieving up to 3.4 times faster generation. The tool provides a seamless integration with other techniques for efficient Large Language Model (LLM) inference, without the need for draft models or architectural modifications.
yolo-flutter-app
Ultralytics YOLO for Flutter is a Flutter plugin that allows you to integrate Ultralytics YOLO computer vision models into your mobile apps. It supports both Android and iOS platforms, providing APIs for object detection and image classification. The plugin leverages Flutter Platform Channels for seamless communication between the client and host, handling all processing natively. Before using the plugin, you need to export the required models in `.tflite` and `.mlmodel` formats. The plugin provides support for tasks like detection and classification, with specific instructions for Android and iOS platforms. It also includes features like camera preview and methods for object detection and image classification on images. Ultralytics YOLO thrives on community collaboration and offers different licensing paths for open-source and commercial use cases.

PromptClip
PromptClip is a tool that allows developers to create video clips using LLM prompts. Users can upload videos from various sources, prompt the video in natural language, use different LLM models, instantly watch the generated clips, finetune the clips, and add music or image overlays. The tool provides a seamless way to extract specific moments from videos based on user queries, making video editing and content creation more efficient and intuitive.
rank_llm
RankLLM is a suite of prompt-decoders compatible with open source LLMs like Vicuna and Zephyr. It allows users to create custom ranking models for various NLP tasks, such as document reranking, question answering, and summarization. The tool offers a variety of features, including the ability to fine-tune models on custom datasets, use different retrieval methods, and control the context size and variable passages. RankLLM is easy to use and can be integrated into existing NLP pipelines.
vnc-lm
vnc-lm is a Discord bot designed for messaging with language models. Users can configure model parameters, branch conversations, and edit prompts to enhance responses. The bot supports various providers like OpenAI, Huggingface, and Cloudflare Workers AI. It integrates with ollama and LiteLLM, allowing users to access a wide range of language model APIs through a single interface. Users can manage models, switch between models, split long messages, and create conversation branches. LiteLLM integration enables support for OpenAI-compatible APIs and local LLM services. The bot requires Docker for installation and can be configured through environment variables. Troubleshooting tips are provided for common issues like context window problems, Discord API errors, and LiteLLM issues.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB

agentscope
AgentScope is a multi-agent platform designed to empower developers to build multi-agent applications with large-scale models. It features three high-level capabilities: Easy-to-Use, High Robustness, and Actor-Based Distribution. AgentScope provides a list of `ModelWrapper` to support both local model services and third-party model APIs, including OpenAI API, DashScope API, Gemini API, and ollama. It also enables developers to rapidly deploy local model services using libraries such as ollama (CPU inference), Flask + Transformers, Flask + ModelScope, FastChat, and vllm. AgentScope supports various services, including Web Search, Data Query, Retrieval, Code Execution, File Operation, and Text Processing. Example applications include Conversation, Game, and Distribution. AgentScope is released under Apache License 2.0 and welcomes contributions.
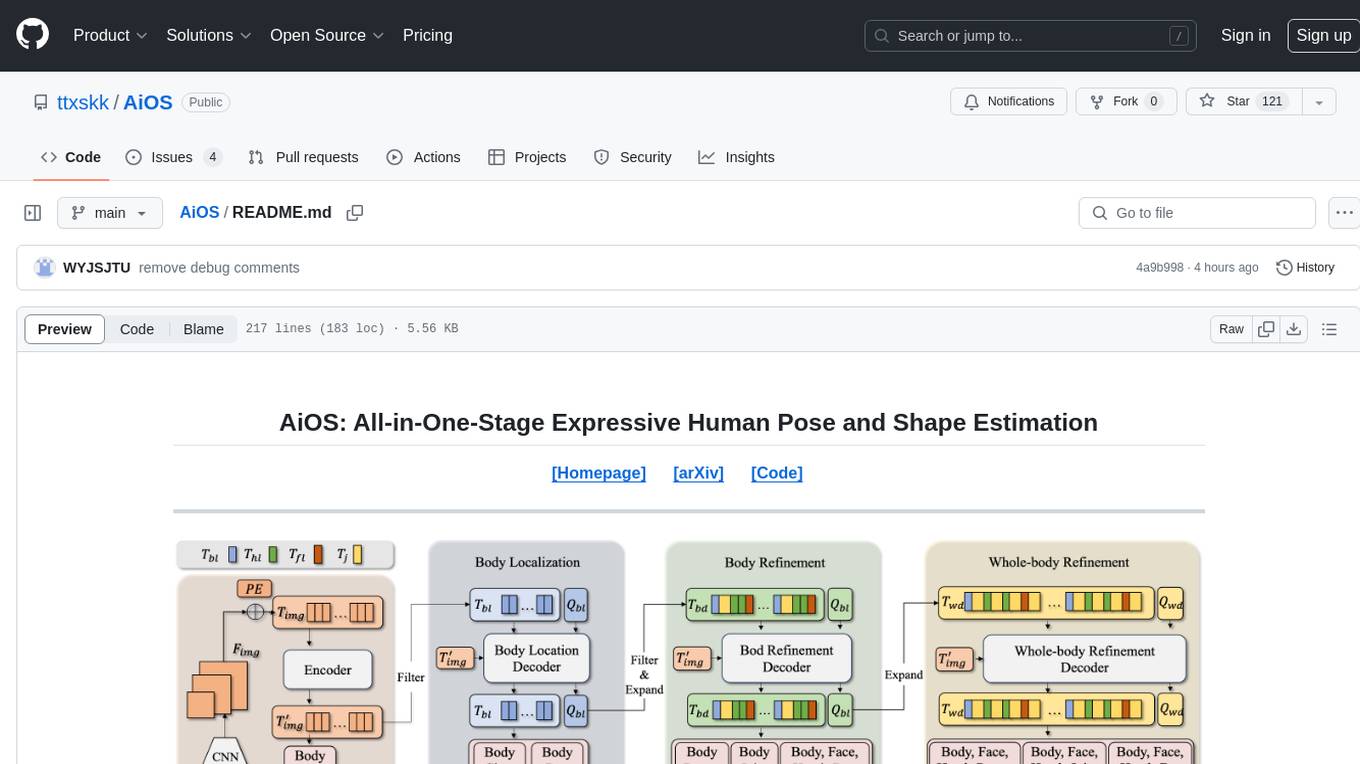
AiOS
AiOS is a tool for human pose and shape estimation, performing human localization and SMPL-X estimation in a progressive manner. It consists of body localization, body refinement, and whole-body refinement stages. Users can download datasets for evaluation, SMPL-X body models, and AiOS checkpoint. Installation involves creating a conda virtual environment, installing PyTorch, torchvision, Pytorch3D, MMCV, and other dependencies. Inference requires placing the video for inference and pretrained models in specific directories. Test results are provided for NMVE, NMJE, MVE, and MPJPE on datasets like BEDLAM and AGORA. Users can run scripts for AGORA validation, AGORA test leaderboard, and BEDLAM leaderboard. The tool acknowledges codes from MMHuman3D, ED-Pose, and SMPLer-X.

parseable
Parseable is a full stack observability platform designed to ingest, analyze, and extract insights from various types of telemetry data. It can be run locally, in the cloud, or as a managed service. The platform offers features like high availability, smart cache, alerts, role-based access control, OAuth2 support, and OpenTelemetry integration. Users can easily ingest data, query logs, and access the dashboard to monitor and analyze data. Parseable provides a seamless experience for observability and monitoring tasks.

OSA
OSA (Open-Source-Advisor) is a tool designed to improve the quality of scientific open source projects by automating the generation of README files, documentation, CI/CD scripts, and providing advice and recommendations for repositories. It supports various LLMs accessible via API, local servers, or osa_bot hosted on ITMO servers. OSA is currently under development with features like README file generation, documentation generation, automatic implementation of changes, LLM integration, and GitHub Action Workflow generation. It requires Python 3.10 or higher and tokens for GitHub/GitLab/Gitverse and LLM API key. Users can install OSA using PyPi or build from source, and run it using CLI commands or Docker containers.
LLM-Finetune-Guide
This project provides a comprehensive guide to fine-tuning large language models (LLMs) with efficient methods like LoRA and P-tuning V2. It includes detailed instructions, code examples, and performance benchmarks for various LLMs and fine-tuning techniques. The guide also covers data preparation, evaluation, prediction, and running inference on CPU environments. By leveraging this guide, users can effectively fine-tune LLMs for specific tasks and applications.
For similar tasks

simpleAI
SimpleAI is a self-hosted alternative to the not-so-open AI API, focused on replicating main endpoints for LLM such as text completion, chat, edits, and embeddings. It allows quick experimentation with different models, creating benchmarks, and handling specific use cases without relying on external services. Users can integrate and declare models through gRPC, query endpoints using Swagger UI or API, and resolve common issues like CORS with FastAPI middleware. The project is open for contributions and welcomes PRs, issues, documentation, and more.
polaris
Polaris establishes a novel, industry‑certified standard to foster the development of impactful methods in AI-based drug discovery. This library is a Python client to interact with the Polaris Hub. It allows you to download Polaris datasets and benchmarks, evaluate a custom method against a Polaris benchmark, and create and upload new datasets and benchmarks.

deepfabric
DeepFabric is a CLI tool and SDK designed for researchers and developers to generate high-quality synthetic datasets at scale using large language models. It leverages a graph and tree-based architecture to create diverse and domain-specific datasets while minimizing redundancy. The tool supports generating Chain of Thought datasets for step-by-step reasoning tasks and offers multi-provider support for using different language models. DeepFabric also allows for automatic dataset upload to Hugging Face Hub and uses YAML configuration files for flexibility in dataset generation.

kan-gpt
The KAN-GPT repository is a PyTorch implementation of Generative Pre-trained Transformers (GPTs) using Kolmogorov-Arnold Networks (KANs) for language modeling. It provides a model for generating text based on prompts, with a focus on improving performance compared to traditional MLP-GPT models. The repository includes scripts for training the model, downloading datasets, and evaluating model performance. Development tasks include integrating with other libraries, testing, and documentation.
LLM-Finetune
LLM-Finetune is a repository for fine-tuning language models for various NLP tasks such as text classification and named entity recognition. It provides instructions and scripts for training and inference using models like Qwen2-VL and GLM4. The repository also includes datasets for tasks like text classification, named entity recognition, and multimodal tasks. Users can easily prepare the environment, download datasets, train models, and perform inference using the provided scripts and notebooks. Additionally, the repository references SwanLab, an AI training record, analysis, and visualization tool.
aishare
Aishare is a collaborative platform for sharing AI models and datasets. It allows users to upload, download, and explore various AI models and datasets. Users can also rate and comment on the shared resources, providing valuable feedback to the community. Aishare aims to foster collaboration and knowledge sharing in the field of artificial intelligence.

long-llms-learning
A repository sharing the panorama of the methodology literature on Transformer architecture upgrades in Large Language Models for handling extensive context windows, with real-time updating the newest published works. It includes a survey on advancing Transformer architecture in long-context large language models, flash-ReRoPE implementation, latest news on data engineering, lightning attention, Kimi AI assistant, chatglm-6b-128k, gpt-4-turbo-preview, benchmarks like InfiniteBench and LongBench, long-LLMs-evals for evaluating methods for enhancing long-context capabilities, and LLMs-learning for learning technologies and applicated tasks about Large Language Models.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.