
elysium
Automatically apply AI-generated code changes in Emacs
Stars: 247
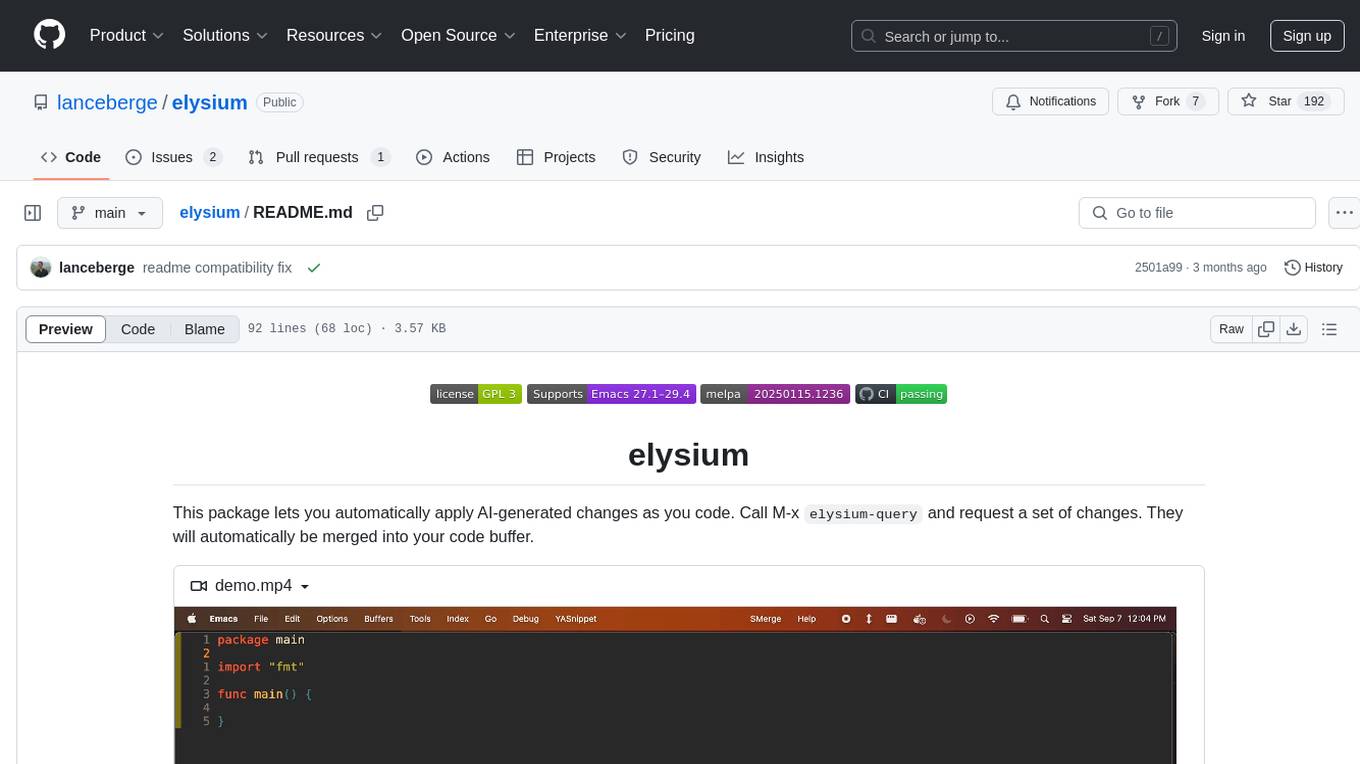
Elysium is an Emacs package that allows users to automatically apply AI-generated changes while coding. By calling `elysium-query`, users can request a set of changes that will be merged into the code buffer. The tool supports making queries on a specific region without leaving the code buffer. It uses the `gptel` backend and currently recommends using the Claude 3-5 Sonnet model for generating code. Users can customize the window size and style of the Elysium buffer. The tool also provides functions to keep or discard AI-suggested changes and navigate conflicting hunks with `smerge-mode`.
README:
This package lets you automatically apply AI-generated changes as you code. Call M-x elysium-query
and request a set of changes. They will automatically be merged into your code buffer.
https://github.com/user-attachments/assets/275e292e-c480-48d1-9a13-27664c0bbf12
You can make queries on a region without leaving the the code buffer
https://github.com/user-attachments/assets/73bd4c38-dc03-47b7-b943-a4b9b3203f06

Elysium is now on Melpa!
(add-to-list 'package-archives
'("melpa-stable" . "https://stable.melpa.org/packages/") t)
(use-package elysium)(use-package elysium
:custom
;; Below are the default values
(elysium-window-size 0.33) ; The elysium buffer will be 1/3 your screen
(elysium-window-style 'vertical)) ; Can be customized to horizontal
(use-package gptel
:custom
(gptel-model 'claude-3-5-sonnet-20240620)
:config
(defun read-file-contents (file-path)
"Read the contents of FILE-PATH and return it as a string."
(with-temp-buffer
(insert-file-contents file-path)
(buffer-string)))
(defun gptel-api-key ()
(read-file-contents "~/secrets/claude_key"))
(setq
gptel-backend (gptel-make-anthropic "Claude"
:stream t
:key #'gptel-api-key)))Use smerge-mode to then merge in the changes
(use-package smerge-mode
:ensure nil
:hook
(prog-mode . smerge-mode))| Function | Description |
|---|---|
elysium-query |
send a query to the gptel backend |
elysium-keep-all-suggested-changes |
keep all of the AI-suggested changes |
elysium-discard-all-suggested-changes |
discard all of the AI-suggested changes |
elysium-clear-buffer |
clear the elysium buffer |
elysium-add-context |
add the contents of a region to the elysium buffer |
smerge-next |
go to the next conflicting hunk |
smerge-previous |
go to the next conflicting hunk |
smerge-keep-other |
keep this set of changes |
smerge-keep-mine |
discard this set of changes |
elysium-toggle-window |
toggle the chat window |
elysium uses gptel as a backend. It supports any of the models supported by gptel, but currently (9/24)
Claude 3-5 Sonnet seems to be the best for generating code.
If there is a region active, then elysium will send only that region to the LLM. Otherwise, the entire code buffer will be sent. If you're using Claude, then I recommend only ever sending a region to avoid getting rate-limited.
- Implementing Prompt Caching with Anthropic to let us send more queries before getting rate-limited
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for elysium
Similar Open Source Tools
elysium
Elysium is an Emacs package that allows users to automatically apply AI-generated changes while coding. By calling `elysium-query`, users can request a set of changes that will be merged into the code buffer. The tool supports making queries on a specific region without leaving the code buffer. It uses the `gptel` backend and currently recommends using the Claude 3-5 Sonnet model for generating code. Users can customize the window size and style of the Elysium buffer. The tool also provides functions to keep or discard AI-suggested changes and navigate conflicting hunks with `smerge-mode`.
minuet-ai.el
Minuet AI is a tool that brings the grace and harmony of a minuet to your coding process. It offers AI-powered code completion with specialized prompts and enhancements for chat-based LLMs, as well as Fill-in-the-middle (FIM) completion for compatible models. The tool supports multiple AI providers such as OpenAI, Claude, Gemini, Codestral, Ollama, and OpenAI-compatible providers. It provides customizable configuration options and streaming support for completion delivery even with slower LLMs.

text-embeddings-inference
Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for popular models like FlagEmbedding, Ember, GTE, and E5. It implements features such as no model graph compilation step, Metal support for local execution on Macs, small docker images with fast boot times, token-based dynamic batching, optimized transformers code for inference using Flash Attention, Candle, and cuBLASLt, Safetensors weight loading, and production-ready features like distributed tracing with Open Telemetry and Prometheus metrics.
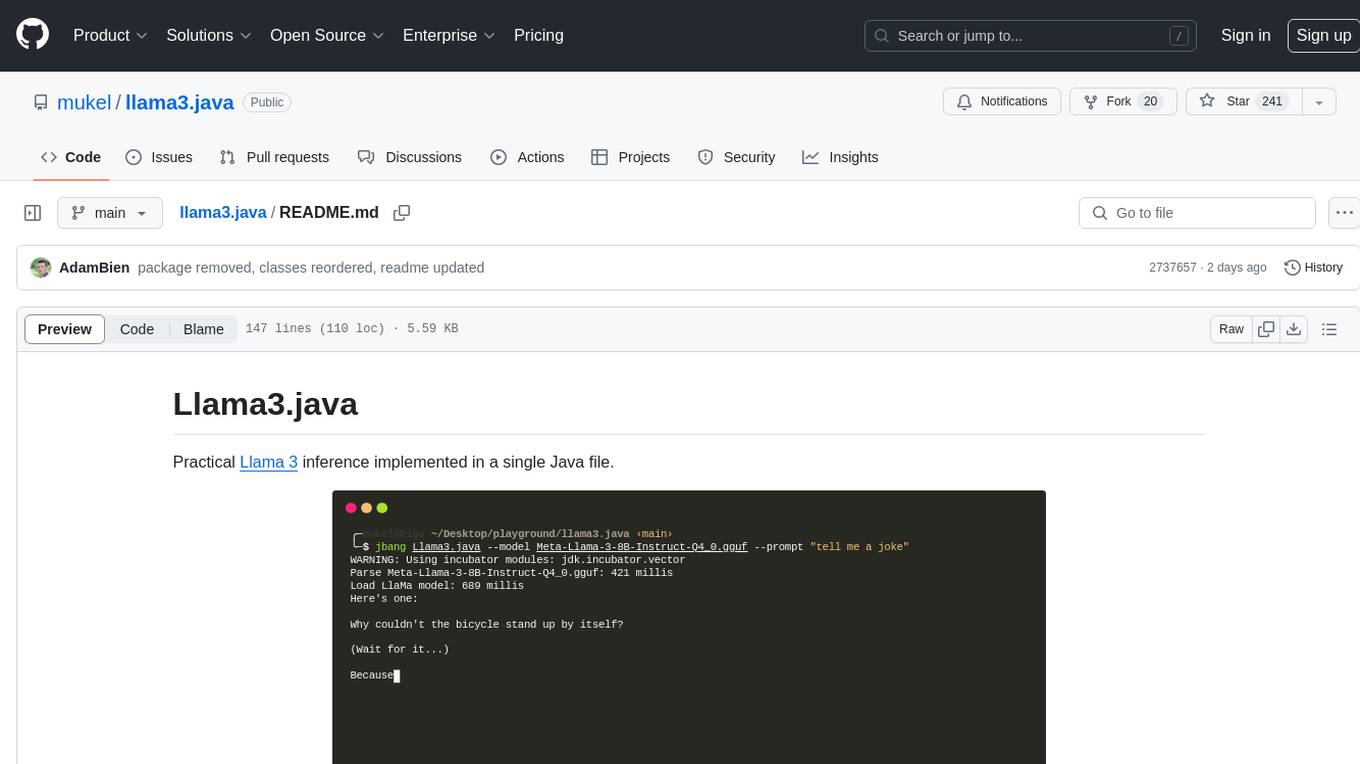
llama3.java
Llama3.java is a practical Llama 3 inference tool implemented in a single Java file. It serves as the successor of llama2.java and is designed for testing and tuning compiler optimizations and features on the JVM, especially for the Graal compiler. The tool features a GGUF format parser, Llama 3 tokenizer, Grouped-Query Attention inference, support for Q8_0 and Q4_0 quantizations, fast matrix-vector multiplication routines using Java's Vector API, and a simple CLI with 'chat' and 'instruct' modes. Users can download quantized .gguf files from huggingface.co for model usage and can also manually quantize to pure 'Q4_0'. The tool requires Java 21+ and supports running from source or building a JAR file for execution. Performance benchmarks show varying tokens/s rates for different models and implementations on different hardware setups.
aidermacs
Aidermacs is an AI pair programming tool for Emacs that integrates Aider, a powerful open-source AI pair programming tool. It provides top performance on the SWE Bench, support for multi-file edits, real-time file synchronization, and broad language support. Aidermacs delivers an Emacs-centric experience with features like intelligent model selection, flexible terminal backend support, smarter syntax highlighting, enhanced file management, and streamlined transient menus. It thrives on community involvement, encouraging contributions, issue reporting, idea sharing, and documentation improvement.
litserve
LitServe is a high-throughput serving engine for deploying AI models at scale. It generates an API endpoint for a model, handles batching, streaming, autoscaling across CPU/GPUs, and more. Built for enterprise scale, it supports every framework like PyTorch, JAX, Tensorflow, and more. LitServe is designed to let users focus on model performance, not the serving boilerplate. It is like PyTorch Lightning for model serving but with broader framework support and scalability.

can-ai-code
Can AI Code is a self-evaluating interview tool for AI coding models. It includes interview questions written by humans and tests taken by AI, inference scripts for common API providers and CUDA-enabled quantization runtimes, a Docker-based sandbox environment for validating untrusted Python and NodeJS code, and the ability to evaluate the impact of prompting techniques and sampling parameters on large language model (LLM) coding performance. Users can also assess LLM coding performance degradation due to quantization. The tool provides test suites for evaluating LLM coding performance, a webapp for exploring results, and comparison scripts for evaluations. It supports multiple interviewers for API and CUDA runtimes, with detailed instructions on running the tool in different environments. The repository structure includes folders for interviews, prompts, parameters, evaluation scripts, comparison scripts, and more.

llama.vim
llama.vim is a plugin that provides local LLM-assisted text completion for Vim users. It offers features such as auto-suggest on cursor movement, manual suggestion toggling, suggestion acceptance with Tab and Shift+Tab, control over text generation time, context configuration, ring context with chunks from open and edited files, and performance stats display. The plugin requires a llama.cpp server instance to be running and supports FIM-compatible models. It aims to be simple, lightweight, and provide high-quality and performant local FIM completions even on consumer-grade hardware.
mem-kk-logic
This repository provides a PyTorch implementation of the paper 'On Memorization of Large Language Models in Logical Reasoning'. The work investigates memorization of Large Language Models (LLMs) in reasoning tasks, proposing a memorization metric and a logical reasoning benchmark based on Knights and Knaves puzzles. It shows that LLMs heavily rely on memorization to solve training puzzles but also improve generalization performance through fine-tuning. The repository includes code, data, and tools for evaluation, fine-tuning, probing model internals, and sample classification.

openedai-speech
OpenedAI Speech is a free, private text-to-speech server compatible with the OpenAI audio/speech API. It offers custom voice cloning and supports various models like tts-1 and tts-1-hd. Users can map their own piper voices and create custom cloned voices. The server provides multilingual support with XTTS voices and allows fixing incorrect sounds with regex. Recent changes include bug fixes, improved error handling, and updates for multilingual support. Installation can be done via Docker or manual setup, with usage instructions provided. Custom voices can be created using Piper or Coqui XTTS v2, with guidelines for preparing audio files. The tool is suitable for tasks like generating speech from text, creating custom voices, and multilingual text-to-speech applications.

raglite
RAGLite is a Python toolkit for Retrieval-Augmented Generation (RAG) with PostgreSQL or SQLite. It offers configurable options for choosing LLM providers, database types, and rerankers. The toolkit is fast and permissive, utilizing lightweight dependencies and hardware acceleration. RAGLite provides features like PDF to Markdown conversion, multi-vector chunk embedding, optimal semantic chunking, hybrid search capabilities, adaptive retrieval, and improved output quality. It is extensible with a built-in Model Context Protocol server, customizable ChatGPT-like frontend, document conversion to Markdown, and evaluation tools. Users can configure RAGLite for various tasks like configuring, inserting documents, running RAG pipelines, computing query adapters, evaluating performance, running MCP servers, and serving frontends.

moatless-tools
Moatless Tools is a hobby project focused on experimenting with using Large Language Models (LLMs) to edit code in large existing codebases. The project aims to build tools that insert the right context into prompts and handle responses effectively. It utilizes an agentic loop functioning as a finite state machine to transition between states like Search, Identify, PlanToCode, ClarifyChange, and EditCode for code editing tasks.
next-token-prediction
Next-Token Prediction is a language model tool that allows users to create high-quality predictions for the next word, phrase, or pixel based on a body of text. It can be used as an alternative to well-known decoder-only models like GPT and Mistral. The tool provides options for simple usage with built-in data bootstrap or advanced customization by providing training data or creating it from .txt files. It aims to simplify methodologies, provide autocomplete, autocorrect, spell checking, search/lookup functionalities, and create pixel and audio transformers for various prediction formats.

co-llm
Co-LLM (Collaborative Language Models) is a tool for learning to decode collaboratively with multiple language models. It provides a method for data processing, training, and inference using a collaborative approach. The tool involves steps such as formatting/tokenization, scoring logits, initializing Z vector, deferral training, and generating results using multiple models. Co-LLM supports training with different collaboration pairs and provides baseline training scripts for various models. In inference, it uses 'vllm' services to orchestrate models and generate results through API-like services. The tool is inspired by allenai/open-instruct and aims to improve decoding performance through collaborative learning.

paxml
Pax is a framework to configure and run machine learning experiments on top of Jax.
podscript
Podscript is a tool designed to generate transcripts for podcasts and similar audio files using Language Model Models (LLMs) and Speech-to-Text (STT) APIs. It provides a command-line interface (CLI) for transcribing audio from various sources, including YouTube videos and audio files, using different speech-to-text services like Deepgram, Assembly AI, and Groq. Additionally, Podscript offers a web-based user interface for convenience. Users can configure keys for supported services, transcribe audio, and customize the transcription models. The tool aims to simplify the process of creating accurate transcripts for audio content.
For similar tasks
elysium
Elysium is an Emacs package that allows users to automatically apply AI-generated changes while coding. By calling `elysium-query`, users can request a set of changes that will be merged into the code buffer. The tool supports making queries on a specific region without leaving the code buffer. It uses the `gptel` backend and currently recommends using the Claude 3-5 Sonnet model for generating code. Users can customize the window size and style of the Elysium buffer. The tool also provides functions to keep or discard AI-suggested changes and navigate conflicting hunks with `smerge-mode`.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.