
svelte-bench
An LLM benchmark for Svelte 5 based on the OpenAI methodology from OpenAIs paper "Evaluating Large Language Models Trained on Code".
Stars: 70
SvelteBench is an LLM benchmark tool for evaluating Svelte components generated by large language models. It supports multiple LLM providers such as OpenAI, Anthropic, Google, and OpenRouter. Users can run predefined test suites to verify the functionality of the generated components. The tool allows configuration of API keys for different providers and offers debug mode for faster development. Users can provide a context file to improve component generation. Benchmark results are saved in JSON format for analysis and visualization.
README:
An LLM benchmark for Svelte 5 based on the OpenAI methodology from OpenAIs paper "Evaluating Large Language Models Trained on Code", using a similar structure to the HumanEval dataset.
Work in progress
SvelteBench evaluates LLM-generated Svelte components by testing them against predefined test suites. It works by sending prompts to LLMs, generating Svelte components, and verifying their functionality through automated tests.
SvelteBench supports multiple LLM providers:
- OpenAI - GPT-4, GPT-4o, o1, o3, o4 models
- Anthropic - Claude 3.5, Claude 4 models
- Google - Gemini 2.5 models
- OpenRouter - Access to multiple providers through a single API
nvm use
npm install
# Create .env file from example
cp .env.example .envThen edit the .env file and add your API keys:
# OpenAI (optional)
OPENAI_API_KEY=your_openai_api_key_here
# Anthropic (optional)
ANTHROPIC_API_KEY=your_anthropic_api_key_here
# Google Gemini (optional)
GEMINI_API_KEY=your_gemini_api_key_here
# OpenRouter (optional)
OPENROUTER_API_KEY=your_openrouter_api_key_here
OPENROUTER_SITE_URL=https://github.com/khromov/svelte-bench # Optional
OPENROUTER_SITE_NAME=SvelteBench # OptionalYou only need to configure the providers you want to test with.
# Run the benchmark with settings from .env file
npm startNOTE: This will run all providers and models that are available!
For faster development, or to run just one provider/model, you can enable debug mode in your .env file:
DEBUG_MODE=true
DEBUG_PROVIDER=anthropic
DEBUG_MODEL=claude-3-7-sonnet-20250219
DEBUG_TEST=counter
Debug mode runs only one provider/model combination, making it much faster for testing during development.
You can now specify multiple models to test in debug mode by providing a comma-separated list:
DEBUG_MODE=true
DEBUG_PROVIDER=anthropic
DEBUG_MODEL=claude-3-7-sonnet-20250219,claude-opus-4-20250514,claude-sonnet-4-20250514
This will run tests with all three models sequentially while still staying within the same provider.
You can provide a context file (like Svelte documentation) to help the LLM generate better components:
# Run with a context file
npm run run-tests -- --context ./context/svelte.dev/llms-small.txt && npm run buildThe context file will be included in the prompt to the LLM, providing additional information for generating components.
After running the benchmark, you can visualize the results using the built-in visualization tool:
npm run buildYou can now find the visualization in the dist directory.
To add a new test:
- Create a new directory in
src/tests/with the name of your test - Add a
prompt.mdfile with instructions for the LLM - Add a
test.tsfile with Vitest tests for the generated component
Example structure:
src/tests/your-test/
├── prompt.md # Instructions for the LLM
└── test.ts # Tests for the generated component
After running the benchmark, results are saved to a JSON file in the benchmarks directory. The file is named benchmark-results-{timestamp}.json.
When running with a context file, the results filename will include "with-context" in the name: benchmark-results-with-context-{timestamp}.json.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for svelte-bench
Similar Open Source Tools
svelte-bench
SvelteBench is an LLM benchmark tool for evaluating Svelte components generated by large language models. It supports multiple LLM providers such as OpenAI, Anthropic, Google, and OpenRouter. Users can run predefined test suites to verify the functionality of the generated components. The tool allows configuration of API keys for different providers and offers debug mode for faster development. Users can provide a context file to improve component generation. Benchmark results are saved in JSON format for analysis and visualization.
humanoid-gym
Humanoid-Gym is a reinforcement learning framework designed for training locomotion skills for humanoid robots, focusing on zero-shot transfer from simulation to real-world environments. It integrates a sim-to-sim framework from Isaac Gym to Mujoco for verifying trained policies in different physical simulations. The codebase is verified with RobotEra's XBot-S and XBot-L humanoid robots. It offers comprehensive training guidelines, step-by-step configuration instructions, and execution scripts for easy deployment. The sim2sim support allows transferring trained policies to accurate simulated environments. The upcoming features include Denoising World Model Learning and Dexterous Hand Manipulation. Installation and usage guides are provided along with examples for training PPO policies and sim-to-sim transformations. The code structure includes environment and configuration files, with instructions on adding new environments. Troubleshooting tips are provided for common issues, along with a citation and acknowledgment section.

llm-memorization
The 'llm-memorization' project is a tool designed to index, archive, and search conversations with a local LLM using a SQLite database enriched with automatically extracted keywords. It aims to provide personalized context at the start of a conversation by adding memory information to the initial prompt. The tool automates queries from local LLM conversational management libraries, offers a hybrid search function, enhances prompts based on posed questions, and provides an all-in-one graphical user interface for data visualization. It supports both French and English conversations and prompts for bilingual use.
xlang
XLang™ is a cutting-edge language designed for AI and IoT applications, offering exceptional dynamic and high-performance capabilities. It excels in distributed computing and seamless integration with popular languages like C++, Python, and JavaScript. Notably efficient, running 3 to 5 times faster than Python in AI and deep learning contexts. Features optimized tensor computing architecture for constructing neural networks through tensor expressions. Automates tensor data flow graph generation and compilation for specific targets, enhancing GPU performance by 6 to 10 times in CUDA environments.
mycoder
An open-source mono-repository containing the MyCoder agent and CLI. It leverages Anthropic's Claude API for intelligent decision making, has a modular architecture with various tool categories, supports parallel execution with sub-agents, can modify code by writing itself, features a smart logging system for clear output, and is human-compatible using README.md, project files, and shell commands to build its own context.

generative-models
Generative Models by Stability AI is a repository that provides various generative models for research purposes. It includes models like Stable Video 4D (SV4D) for video synthesis, Stable Video 3D (SV3D) for multi-view synthesis, SDXL-Turbo for text-to-image generation, and more. The repository focuses on modularity and implements a config-driven approach for building and combining submodules. It supports training with PyTorch Lightning and offers inference demos for different models. Users can access pre-trained models like SDXL-base-1.0 and SDXL-refiner-1.0 under a CreativeML Open RAIL++-M license. The codebase also includes tools for invisible watermark detection in generated images.
agent-service-toolkit
The AI Agent Service Toolkit is a comprehensive toolkit designed for running an AI agent service using LangGraph, FastAPI, and Streamlit. It includes a LangGraph agent, a FastAPI service, a client for interacting with the service, and a Streamlit app for providing a chat interface. The project offers a template for building and running agents with the LangGraph framework, showcasing a complete setup from agent definition to user interface. Key features include LangGraph Agent with latest features, FastAPI Service, Advanced Streaming support, Streamlit Interface, Multiple Agent Support, Asynchronous Design, Content Moderation, RAG Agent implementation, Feedback Mechanism, Docker Support, and Testing. The repository structure includes directories for defining agents, protocol schema, core modules, service, client, Streamlit app, and tests.
mark
Mark is a CLI tool that allows users to interact with large language models (LLMs) using Markdown format. It enables users to seamlessly integrate GPT responses into Markdown files, supports image recognition, scraping of local and remote links, and image generation. Mark focuses on using Markdown as both a prompt and response medium for LLMs, offering a unique and flexible way to interact with language models for various use cases in development and documentation processes.
llm-compressor
llm-compressor is an easy-to-use library for optimizing models for deployment with vllm. It provides a comprehensive set of quantization algorithms, seamless integration with Hugging Face models and repositories, and supports mixed precision, activation quantization, and sparsity. Supported algorithms include PTQ, GPTQ, SmoothQuant, and SparseGPT. Installation can be done via git clone and local pip install. Compression can be easily applied by selecting an algorithm and calling the oneshot API. The library also offers end-to-end examples for model compression. Contributions to the code, examples, integrations, and documentation are appreciated.
RoboMatrix
RoboMatrix is a skill-centric hierarchical framework for scalable robot task planning and execution in an open-world environment. It provides a structured approach to robot task execution using a combination of hardware components, environment configuration, installation procedures, and data collection methods. The framework is developed using the ROS2 framework on Ubuntu and supports robots from DJI's RoboMaster series. Users can follow the provided installation guidance to set up RoboMatrix and utilize it for various tasks such as data collection, task execution, and dataset construction. The framework also includes a supervised fine-tuning dataset and aims to optimize communication and release additional components in the future.

blinkid-ios
BlinkID iOS is a mobile SDK that enables developers to easily integrate ID scanning and data extraction capabilities into their iOS applications. The SDK supports scanning and processing various types of identity documents, such as passports, driver's licenses, and ID cards. It provides accurate and fast data extraction, including personal information and document details. With BlinkID iOS, developers can enhance their apps with secure and reliable ID verification functionality, improving user experience and streamlining identity verification processes.

shellChatGPT
ShellChatGPT is a shell wrapper for OpenAI's ChatGPT, DALL-E, Whisper, and TTS, featuring integration with LocalAI, Ollama, Gemini, Mistral, Groq, and GitHub Models. It provides text and chat completions, vision, reasoning, and audio models, voice-in and voice-out chatting mode, text editor interface, markdown rendering support, session management, instruction prompt manager, integration with various service providers, command line completion, file picker dialogs, color scheme personalization, stdin and text file input support, and compatibility with Linux, FreeBSD, MacOS, and Termux for a responsive experience.
desktop
ComfyUI Desktop is a packaged desktop application that allows users to easily use ComfyUI with bundled features like ComfyUI source code, ComfyUI-Manager, and uv. It automatically installs necessary Python dependencies and updates with stable releases. The app comes with Electron, Chromium binaries, and node modules. Users can store ComfyUI files in a specified location and manage model paths. The tool requires Python 3.12+ and Visual Studio with Desktop C++ workload for Windows. It uses nvm to manage node versions and yarn as the package manager. Users can install ComfyUI and dependencies using comfy-cli, download uv, and build/launch the code. Troubleshooting steps include rebuilding modules and installing missing libraries. The tool supports debugging in VSCode and provides utility scripts for cleanup. Crash reports can be sent to help debug issues, but no personal data is included.
cortex
Nitro is a high-efficiency C++ inference engine for edge computing, powering Jan. It is lightweight and embeddable, ideal for product integration. The binary of nitro after zipped is only ~3mb in size with none to minimal dependencies (if you use a GPU need CUDA for example) make it desirable for any edge/server deployment.

orama-core
OramaCore is a database designed for AI projects, answer engines, copilots, and search functionalities. It offers features such as a full-text search engine, vector database, LLM interface, and various utilities. The tool is currently under active development and not recommended for production use due to potential API changes. OramaCore aims to provide a comprehensive solution for managing data and enabling advanced AI capabilities in projects.

storm
STORM is a LLM system that writes Wikipedia-like articles from scratch based on Internet search. While the system cannot produce publication-ready articles that often require a significant number of edits, experienced Wikipedia editors have found it helpful in their pre-writing stage. **Try out our [live research preview](https://storm.genie.stanford.edu/) to see how STORM can help your knowledge exploration journey and please provide feedback to help us improve the system 🙏!**
For similar tasks
svelte-bench
SvelteBench is an LLM benchmark tool for evaluating Svelte components generated by large language models. It supports multiple LLM providers such as OpenAI, Anthropic, Google, and OpenRouter. Users can run predefined test suites to verify the functionality of the generated components. The tool allows configuration of API keys for different providers and offers debug mode for faster development. Users can provide a context file to improve component generation. Benchmark results are saved in JSON format for analysis and visualization.
ai-cli-lib
The ai-cli-lib is a library designed to enhance interactive command-line editing programs by integrating with GPT large language model servers. It allows users to obtain AI help from servers like Anthropic's or OpenAI's, or a llama.cpp server. The library acts as a command line copilot, providing natural language prompts and responses to enhance user experience and productivity. It supports various platforms such as Debian GNU/Linux, macOS, and Cygwin, and requires specific packages for installation and operation. Users can configure the library to activate during shell startup and interact with command-line programs like bash, mysql, psql, gdb, sqlite3, and bc. Additionally, the library provides options for configuring API keys, setting up llama.cpp servers, and ensuring data privacy by managing context settings.
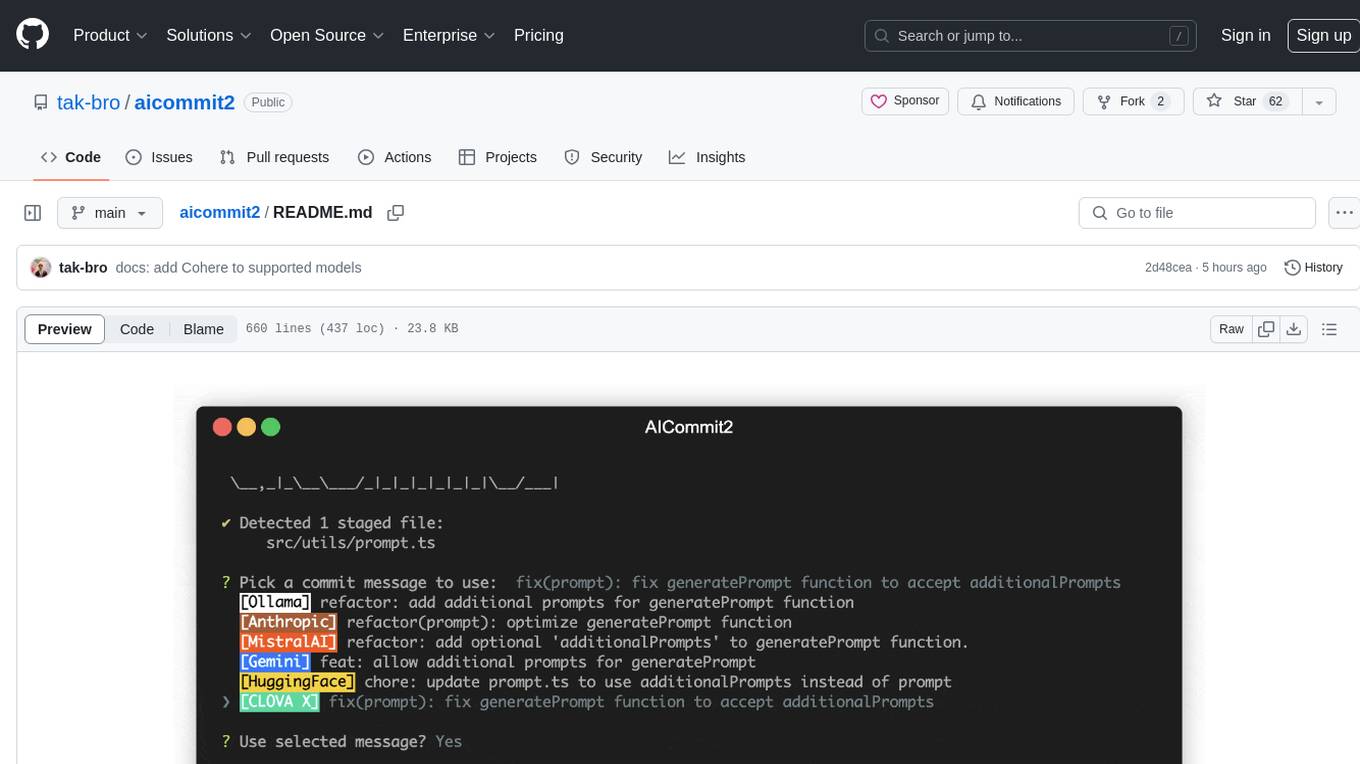
aicommit2
AICommit2 is a Reactive CLI tool that streamlines interactions with various AI providers such as OpenAI, Anthropic Claude, Gemini, Mistral AI, Cohere, and unofficial providers like Huggingface and Clova X. Users can request multiple AI simultaneously to generate git commit messages without waiting for all AI responses. The tool runs 'git diff' to grab code changes, sends them to configured AI, and returns the AI-generated commit message. Users can set API keys or Cookies for different providers and configure options like locale, generate number of messages, commit type, proxy, timeout, max-length, and more. AICommit2 can be used both locally with Ollama and remotely with supported providers, offering flexibility and efficiency in generating commit messages.

TrustEval-toolkit
TrustEval-toolkit is a dynamic and comprehensive framework for evaluating the trustworthiness of Generative Foundation Models (GenFMs) across dimensions such as safety, fairness, robustness, privacy, and more. It offers features like dynamic dataset generation, multi-model compatibility, customizable metrics, metadata-driven pipelines, comprehensive evaluation dimensions, optimized inference, and detailed reports.
prompt-optimizer
Prompt Optimizer is a powerful AI prompt optimization tool that helps you write better AI prompts, improving AI output quality. It supports both web application and Chrome extension usage. The tool features intelligent optimization for prompt words, real-time testing to compare before and after optimization, integration with multiple mainstream AI models, client-side processing for security, encrypted local storage for data privacy, responsive design for user experience, and more.
youtube_summarizer
YouTube AI Summarizer is a modern Next.js-based tool for AI-powered YouTube video summarization. It allows users to generate concise summaries of YouTube videos using various AI models, with support for multiple languages and summary styles. The application features flexible API key requirements, multilingual support, flexible summary modes, a smart history system, modern UI/UX design, and more. Users can easily input a YouTube URL, select language, summary type, and AI model, and generate summaries with real-time progress tracking. The tool offers a clean, well-structured summary view, history dashboard, and detailed history view for past summaries. It also provides configuration options for API keys and database setup, along with technical highlights, performance improvements, and a modern tech stack.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.