
zig-aio
io_uring like asynchronous API and coroutine powered IO tasks for zig
Stars: 215
zig-aio is a library that provides an io_uring-like asynchronous API and coroutine-powered IO tasks for the Zig programming language. It offers support for different operating systems and backends, such as io_uring, iocp, and posix. The library aims to provide efficient IO operations by leveraging coroutines and async IO mechanisms. Users can create servers and clients with ease using the provided API functions for socket operations, sending and receiving data, and managing connections.
README:
zig-aio provides io_uring like asynchronous API and coroutine powered IO tasks for zig
Project is tested on zig version 0.14.0-dev.2851+b074fb7dd
| OS | AIO | CORO |
|---|---|---|
| Linux | io_uring, posix | x86_64, aarch64 |
| Windows | iocp | x86_64, aarch64 |
| Darwin | posix | x86_64, aarch64 |
| *BSD | posix | x86_64, aarch64 |
| WASI | posix | ❌ |
- io_uring AIO backend is very light wrapper, where all the code does is mostly error mapping
- iocp also maps quite well to the io_uring style API
- posix backend is for compatibility, it may not be very effecient
- WASI may eventually get coro support Stack Switching Proposal
const std = @import("std");
const aio = @import("aio");
const coro = @import("coro");
const log = std.log.scoped(.coro_aio);
pub const std_options: std.Options = .{
.log_level = .debug,
};
fn server(startup: *coro.ResetEvent) !void {
var socket: std.posix.socket_t = undefined;
try coro.io.single(.socket, .{
.domain = std.posix.AF.INET,
.flags = std.posix.SOCK.STREAM | std.posix.SOCK.CLOEXEC,
.protocol = std.posix.IPPROTO.TCP,
.out_socket = &socket,
});
const address = std.net.Address.initIp4(.{ 0, 0, 0, 0 }, 1327);
try std.posix.setsockopt(socket, std.posix.SOL.SOCKET, std.posix.SO.REUSEADDR, &std.mem.toBytes(@as(c_int, 1)));
if (@hasDecl(std.posix.SO, "REUSEPORT")) {
try std.posix.setsockopt(socket, std.posix.SOL.SOCKET, std.posix.SO.REUSEPORT, &std.mem.toBytes(@as(c_int, 1)));
}
try std.posix.bind(socket, &address.any, address.getOsSockLen());
try std.posix.listen(socket, 128);
startup.set();
var client_sock: std.posix.socket_t = undefined;
try coro.io.single(.accept, .{ .socket = socket, .out_socket = &client_sock });
var buf: [1024]u8 = undefined;
var len: usize = 0;
try coro.io.multi(.{
aio.op(.send, .{ .socket = client_sock, .buffer = "hey " }, .soft),
aio.op(.send, .{ .socket = client_sock, .buffer = "I'm doing multiple IO ops at once " }, .soft),
aio.op(.send, .{ .socket = client_sock, .buffer = "how cool is that?" }, .soft),
aio.op(.recv, .{ .socket = client_sock, .buffer = &buf, .out_read = &len }, .unlinked),
});
log.warn("got reply from client: {s}", .{buf[0..len]});
try coro.io.multi(.{
aio.op(.send, .{ .socket = client_sock, .buffer = "ok bye" }, .soft),
aio.op(.close_socket, .{ .socket = client_sock }, .soft),
aio.op(.close_socket, .{ .socket = socket }, .unlinked),
});
}
fn client(startup: *coro.ResetEvent) !void {
var socket: std.posix.socket_t = undefined;
try coro.io.single(.socket, .{
.domain = std.posix.AF.INET,
.flags = std.posix.SOCK.STREAM | std.posix.SOCK.CLOEXEC,
.protocol = std.posix.IPPROTO.TCP,
.out_socket = &socket,
});
try startup.wait();
const address = std.net.Address.initIp4(.{ 127, 0, 0, 1 }, 1327);
try coro.io.single(.connect, .{
.socket = socket,
.addr = &address.any,
.addrlen = address.getOsSockLen(),
});
while (true) {
var buf: [1024]u8 = undefined;
var len: usize = 0;
try coro.io.single(.recv, .{ .socket = socket, .buffer = &buf, .out_read = &len });
log.warn("got reply from server: {s}", .{buf[0..len]});
if (std.mem.indexOf(u8, buf[0..len], "how cool is that?")) |_| break;
}
try coro.io.single(.send, .{ .socket = socket, .buffer = "dude, I don't care" });
var buf: [1024]u8 = undefined;
var len: usize = 0;
try coro.io.single(.recv, .{ .socket = socket, .buffer = &buf, .out_read = &len });
log.warn("got final words from server: {s}", .{buf[0..len]});
}
pub fn main() !void {
// var mem: [4096 * 1024]u8 = undefined;
// var fba = std.heap.FixedBufferAllocator.init(&mem);
var gpa: std.heap.GeneralPurposeAllocator(.{}) = .{};
defer _ = gpa.deinit();
var scheduler = try coro.Scheduler.init(gpa.allocator(), .{});
defer scheduler.deinit();
var startup: coro.ResetEvent = .{};
_ = try scheduler.spawn(client, .{&startup}, .{});
_ = try scheduler.spawn(server, .{&startup}, .{});
try scheduler.run(.wait);
}strace -c output from the examples/coro.zig without std.log output and with std.heap.FixedBufferAllocator.
This is using the io_uring backend. posix backend emulates io_uring like interface by using a traditional
readiness event loop, thus it will have larger syscall overhead.
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ------------------
0.00 0.000000 0 2 close
0.00 0.000000 0 4 mmap
0.00 0.000000 0 4 munmap
0.00 0.000000 0 5 rt_sigaction
0.00 0.000000 0 1 bind
0.00 0.000000 0 1 listen
0.00 0.000000 0 2 setsockopt
0.00 0.000000 0 1 execve
0.00 0.000000 0 1 arch_prctl
0.00 0.000000 0 1 gettid
0.00 0.000000 0 2 prlimit64
0.00 0.000000 0 2 io_uring_setup
0.00 0.000000 0 6 io_uring_enter
0.00 0.000000 0 1 io_uring_register
------ ----------- ----------- --------- --------- ------------------
100.00 0.000000 0 33 total
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for zig-aio
Similar Open Source Tools
zig-aio
zig-aio is a library that provides an io_uring-like asynchronous API and coroutine-powered IO tasks for the Zig programming language. It offers support for different operating systems and backends, such as io_uring, iocp, and posix. The library aims to provide efficient IO operations by leveraging coroutines and async IO mechanisms. Users can create servers and clients with ease using the provided API functions for socket operations, sending and receiving data, and managing connections.
zenu
ZeNu is a high-performance deep learning framework implemented in pure Rust, featuring a pure Rust implementation for safety and performance, GPU performance comparable to PyTorch with CUDA support, a simple and intuitive API, and a modular design for easy extension. It supports various layers like Linear, Convolution 2D, LSTM, and optimizers such as SGD and Adam. ZeNu also provides device support for CPU and CUDA (NVIDIA GPU) with CUDA 12.3 and cuDNN 9. The project structure includes main library, automatic differentiation engine, neural network layers, matrix operations, optimization algorithms, CUDA implementation, and other support crates. Users can find detailed implementations like MNIST classification, CIFAR10 classification, and ResNet implementation in the examples directory. Contributions to ZeNu are welcome under the MIT License.

Janus
Janus is a series of unified multimodal understanding and generation models, including Janus-Pro, Janus, and JanusFlow. Janus-Pro is an advanced version that improves both multimodal understanding and visual generation significantly. Janus decouples visual encoding for unified multimodal understanding and generation, surpassing previous models. JanusFlow harmonizes autoregression and rectified flow for unified multimodal understanding and generation, achieving comparable or superior performance to specialized models. The models are available for download and usage, supporting a broad range of research in academic and commercial communities.
island-ai
island-ai is a TypeScript toolkit tailored for developers engaging with structured outputs from Large Language Models. It offers streamlined processes for handling, parsing, streaming, and leveraging AI-generated data across various applications. The toolkit includes packages like zod-stream for interfacing with LLM streams, stream-hooks for integrating streaming JSON data into React applications, and schema-stream for JSON streaming parsing based on Zod schemas. Additionally, related packages like @instructor-ai/instructor-js focus on data validation and retry mechanisms, enhancing the reliability of data processing workflows.
prajna
Prajna is an open-source programming language specifically developed for building more modular, automated, and intelligent artificial intelligence infrastructure. It aims to cater to various stages of AI research, training, and deployment by providing easy access to CPU, GPU, and various TPUs for AI computing. Prajna features just-in-time compilation, GPU/heterogeneous programming support, tensor computing, syntax improvements, and user-friendly interactions through main functions, Repl, and Jupyter, making it suitable for algorithm development and deployment in various scenarios.
Ollama
Ollama SDK for .NET is a fully generated C# SDK based on OpenAPI specification using OpenApiGenerator. It supports automatic releases of new preview versions, source generator for defining tools natively through C# interfaces, and all modern .NET features. The SDK provides support for all Ollama API endpoints including chats, embeddings, listing models, pulling and creating new models, and more. It also offers tools for interacting with weather data and providing weather-related information to users.
orch
orch is a library for building language model powered applications and agents for the Rust programming language. It can be used for tasks such as text generation, streaming text generation, structured data generation, and embedding generation. The library provides functionalities for executing various language model tasks and can be integrated into different applications and contexts. It offers flexibility for developers to create language model-powered features and applications in Rust.
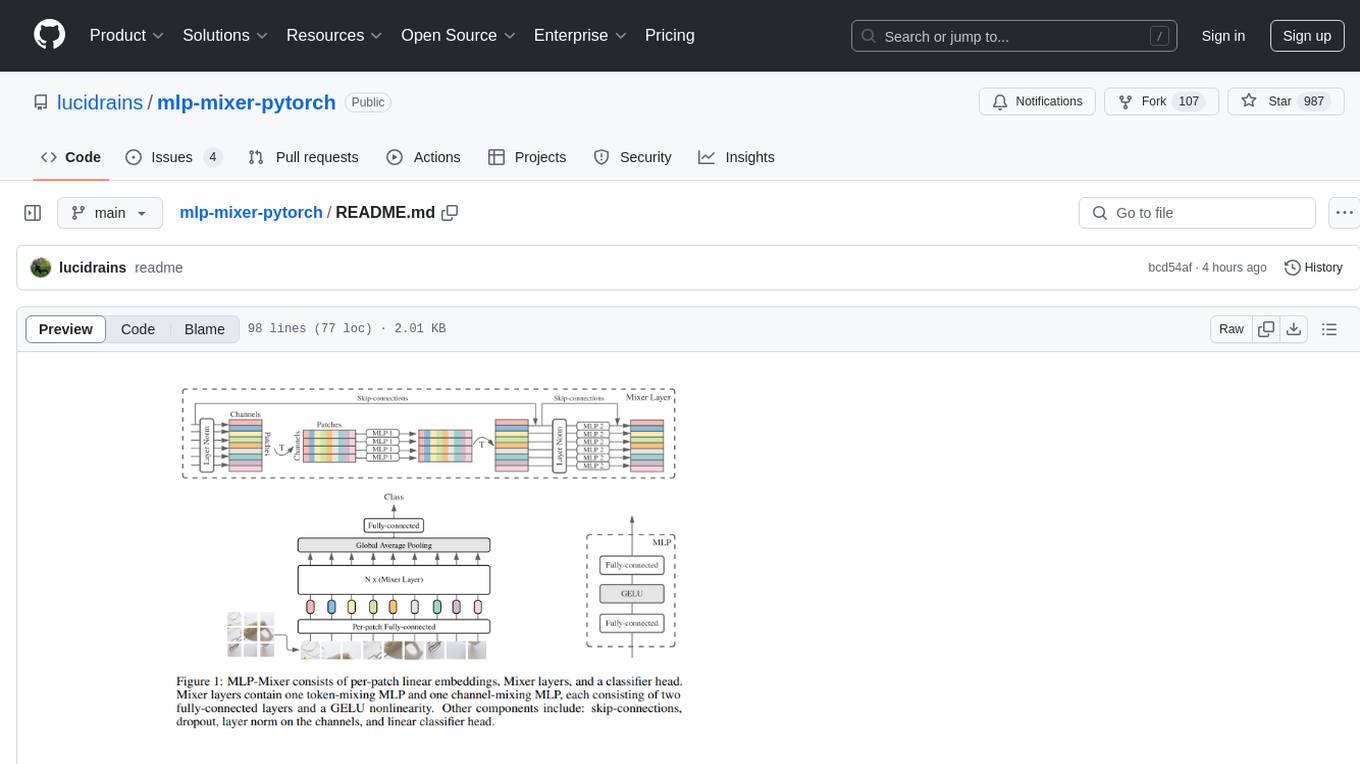
mlp-mixer-pytorch
MLP Mixer - Pytorch is an all-MLP solution for vision tasks, developed by Google AI, implemented in Pytorch. It provides an architecture that does not require convolutions or attention mechanisms, offering an alternative approach for image and video processing. The tool is designed to handle tasks related to image classification and video recognition, utilizing multi-layer perceptrons (MLPs) for feature extraction and classification. Users can easily install the tool using pip and integrate it into their Pytorch projects to experiment with MLP-based vision models.
aidldemo
This repository demonstrates how to achieve cross-process bidirectional communication and large file transfer using AIDL and anonymous shared memory. AIDL is a way to implement Inter-Process Communication in Android, based on Binder. To overcome the data size limit of Binder, anonymous shared memory is used for large file transfer. Shared memory allows processes to share memory by mapping a common memory area into their respective process spaces. While efficient for transferring large data between processes, shared memory lacks synchronization mechanisms, requiring additional mechanisms like semaphores. Android's anonymous shared memory (Ashmem) is based on Linux shared memory and facilitates shared memory transfer using Binder and FileDescriptor. The repository provides practical examples of bidirectional communication and large file transfer between client and server using AIDL interfaces and MemoryFile in Android.

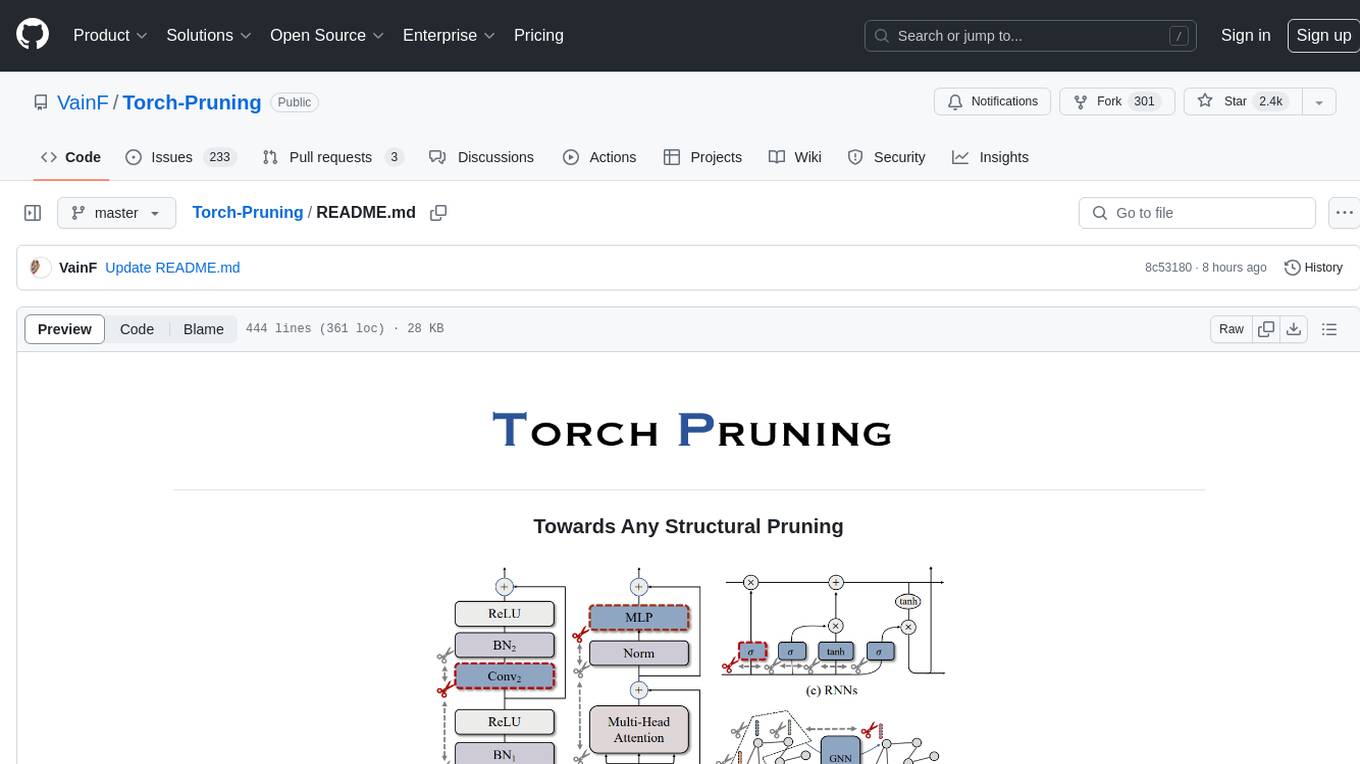
Torch-Pruning
Torch-Pruning (TP) is a library for structural pruning that enables pruning for a wide range of deep neural networks. It uses an algorithm called DepGraph to physically remove parameters. The library supports pruning off-the-shelf models from various frameworks and provides benchmarks for reproducing results. It offers high-level pruners, dependency graph for automatic pruning, low-level pruning functions, and supports various importance criteria and modules. Torch-Pruning is compatible with both PyTorch 1.x and 2.x versions.
jsgrad
jsgrad is a modern ML library for JavaScript and TypeScript that aims to provide a fast and efficient way to run and train machine learning models. It is a rewrite of tinygrad in TypeScript, offering a clean and modern API with zero dependencies. The library supports multiple runtime backends such as WebGPU, WASM, and CLANG, making it versatile for various applications in browser and server environments. With a focus on simplicity and performance, jsgrad is designed to be easy to use for both model inference and training tasks.
nb_utils
nb_utils is a Flutter package that provides a collection of useful methods, extensions, widgets, and utilities to simplify Flutter app development. It includes features like shared preferences, text styles, decorations, widgets, extensions for strings, colors, build context, date time, device, numbers, lists, scroll controllers, system methods, network utils, JWT decoding, and custom dialogs. The package aims to enhance productivity and streamline common tasks in Flutter development.

qianfan-starter
WenXin-Starter is a spring-boot-starter for Baidu's 'WenXin Workshop' large model, facilitating quick integration of Baidu's AI capabilities. It provides complete integration with WenXin Workshop's official API documentation, supports WenShengTu, built-in conversation memory, and supports conversation streaming. It also supports QPS control for individual models and queuing mechanism, with upcoming plugin support.

aiocryptopay
The aiocryptopay repository is an asynchronous API wrapper for interacting with the @cryptobot and @CryptoTestnetBot APIs. It provides methods for creating, getting, and deleting invoices and checks, as well as handling webhooks for invoice payments. Users can easily integrate this tool into their applications to manage cryptocurrency payments and transactions.
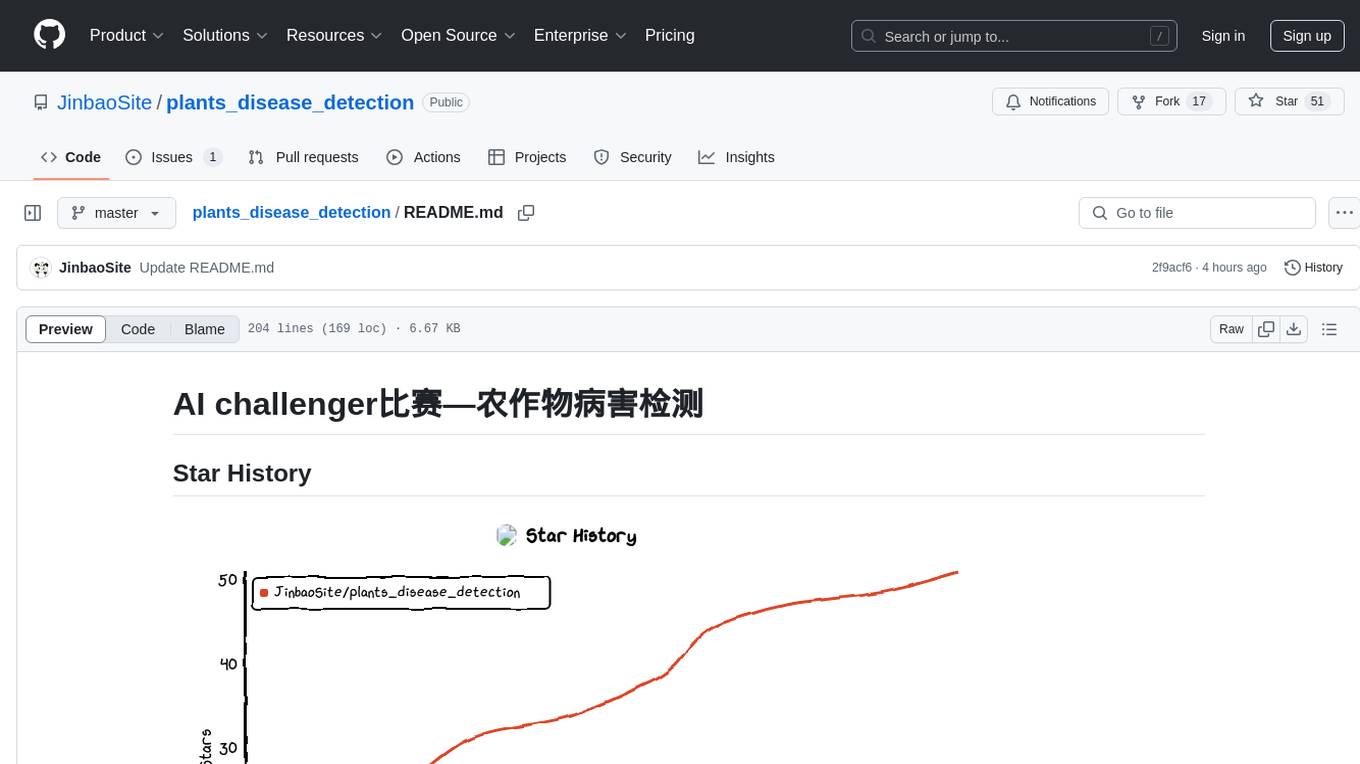
plants_disease_detection
This repository contains code for the AI challenger competition on plant disease detection. The goal is to classify nearly 50,000 plant leaf photos into 61 categories based on 'species-disease-severity'. The framework used is Keras with TensorFlow backend, implementing DenseNet for image classification. Data is uploaded to a private dataset on Kaggle for model training. The code includes data preparation, model training, and prediction steps.
For similar tasks
zig-aio
zig-aio is a library that provides an io_uring-like asynchronous API and coroutine-powered IO tasks for the Zig programming language. It offers support for different operating systems and backends, such as io_uring, iocp, and posix. The library aims to provide efficient IO operations by leveraging coroutines and async IO mechanisms. Users can create servers and clients with ease using the provided API functions for socket operations, sending and receiving data, and managing connections.
mcp-framework
MCP-Framework is a TypeScript framework for building Model Context Protocol (MCP) servers with automatic directory-based discovery for tools, resources, and prompts. It provides powerful abstractions, simple server setup, and a CLI for rapid development and project scaffolding.
mcp
Laravel MCP Server SDK makes it easy to add MCP servers to your project and let AI talk to your apps. It provides tools for creating servers, tools, resources, prompts, and registering servers for web-based and local access. The package includes features for handling tool inputs, annotating tools, tool results, streaming tool responses, creating resources, creating prompts, and authentication using Laravel Passport. The MCP Inspector tool is available for testing and debugging servers.
mcphost
MCPHost is a CLI host application that enables Large Language Models (LLMs) to interact with external tools through the Model Context Protocol (MCP). It acts as a host in the MCP client-server architecture, allowing language models to access external tools and data sources, maintain consistent context across interactions, and execute commands safely. The tool supports interactive conversations with Claude 3.5 Sonnet and Ollama models, multiple concurrent MCP servers, dynamic tool discovery and integration, configurable server locations and arguments, and a consistent command interface across model types.
cursor-talk-to-figma-mcp
This project implements a Model Context Protocol (MCP) integration between Cursor AI and Figma, allowing Cursor to communicate with Figma for reading designs and modifying them programmatically. It provides tools for interacting with Figma such as creating elements, modifying text content, styling, layout & organization, components & styles, export & advanced features, and connection management. The project structure includes a TypeScript MCP server for Figma integration, a Figma plugin for communicating with Cursor, and a WebSocket server for facilitating communication between the MCP server and Figma plugin.
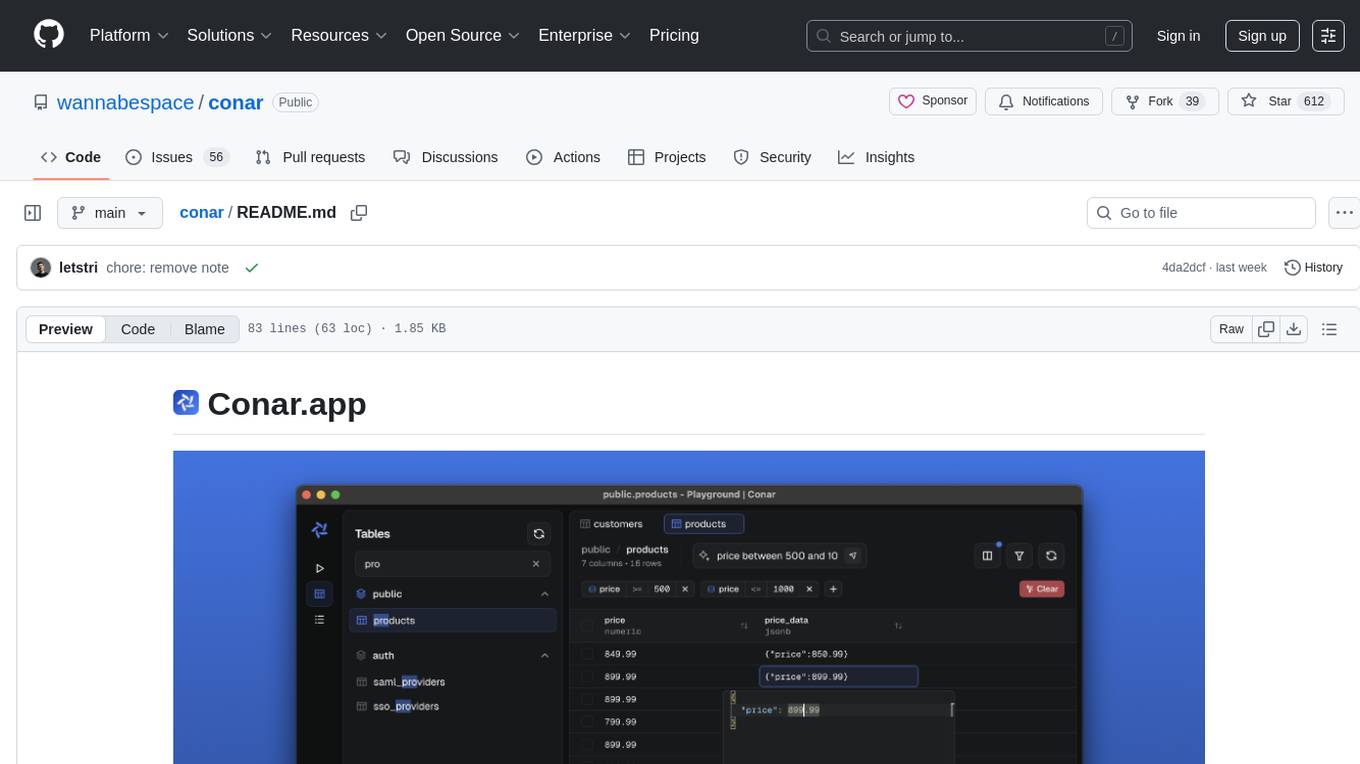
conar
Conar is an AI-powered open-source project designed to simplify database interactions. It is built for PostgreSQL with plans to support other databases in the future. Users can securely store their connections in the cloud and leverage AI assistance to write and optimize SQL queries. The project emphasizes security, multi-database support, and AI-powered features to enhance the database management experience. Conar is developed using React with TypeScript, Electron, and various other technologies to provide a comprehensive solution for database management.
aiocoap
aiocoap is a Python library that implements the Constrained Application Protocol (CoAP) using native asyncio methods in Python 3. It supports various CoAP standards such as RFC7252, RFC7641, RFC7959, RFC8323, RFC7967, RFC8132, RFC9176, RFC8613, and draft-ietf-core-oscore-groupcomm-17. The library provides features for clients and servers, including multicast support, blockwise transfer, CoAP over TCP, TLS, and WebSockets, No-Response, PATCH/FETCH, OSCORE, and Group OSCORE. It offers an easy-to-use interface for concurrent operations and is suitable for IoT applications.
For similar jobs

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

nvidia_gpu_exporter
Nvidia GPU exporter for prometheus, using `nvidia-smi` binary to gather metrics.

tracecat
Tracecat is an open-source automation platform for security teams. It's designed to be simple but powerful, with a focus on AI features and a practitioner-obsessed UI/UX. Tracecat can be used to automate a variety of tasks, including phishing email investigation, evidence collection, and remediation plan generation.

openinference
OpenInference is a set of conventions and plugins that complement OpenTelemetry to enable tracing of AI applications. It provides a way to capture and analyze the performance and behavior of AI models, including their interactions with other components of the application. OpenInference is designed to be language-agnostic and can be used with any OpenTelemetry-compatible backend. It includes a set of instrumentations for popular machine learning SDKs and frameworks, making it easy to add tracing to your AI applications.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

kong
Kong, or Kong API Gateway, is a cloud-native, platform-agnostic, scalable API Gateway distinguished for its high performance and extensibility via plugins. It also provides advanced AI capabilities with multi-LLM support. By providing functionality for proxying, routing, load balancing, health checking, authentication (and more), Kong serves as the central layer for orchestrating microservices or conventional API traffic with ease. Kong runs natively on Kubernetes thanks to its official Kubernetes Ingress Controller.