Best AI tools for< Visual Recognition >
20 - AI tool Sites
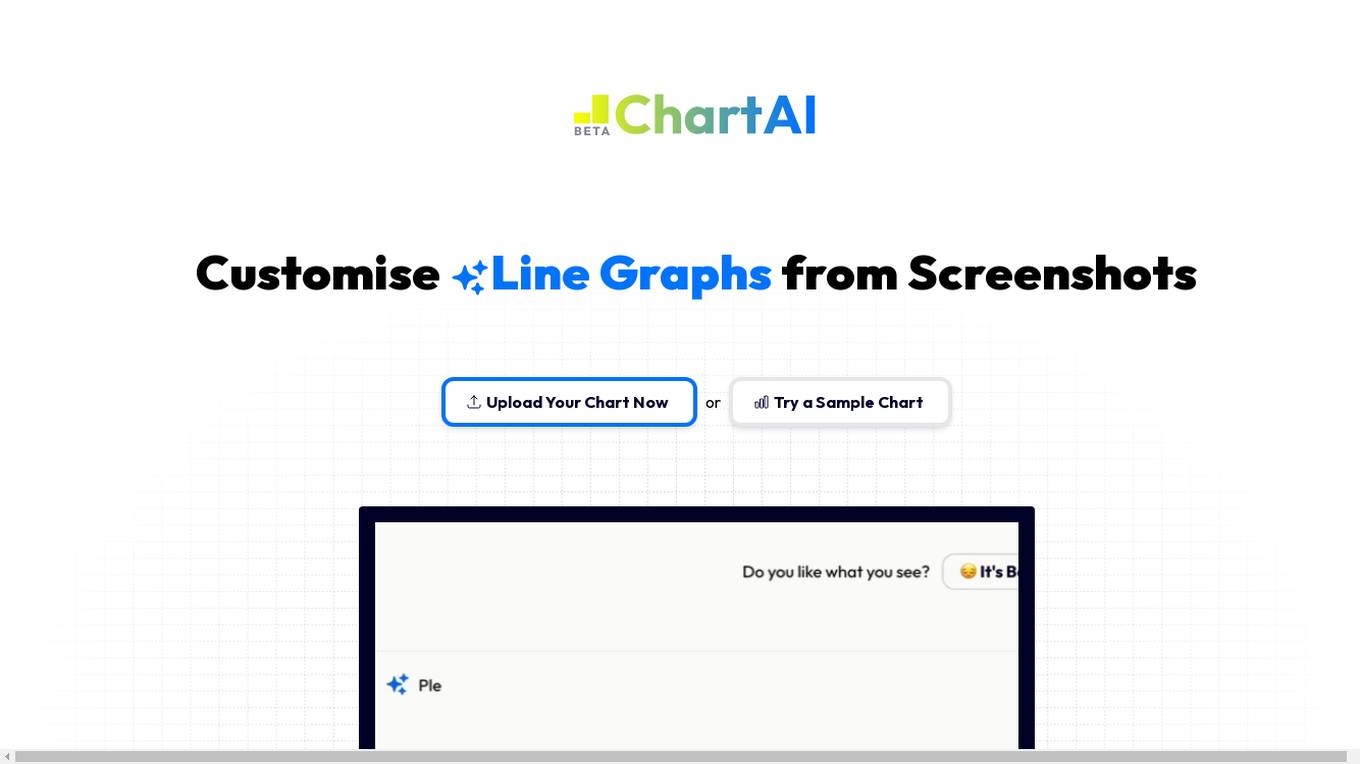
ChartAI
ChartAI is an AI tool that allows users to customize bar charts from screenshots. Users can upload their chart images, and ChartAI's visual recognition technology extracts the data to recreate the chart. Users can adjust the style, add or remove data, and change the chart type effortlessly. The tool simplifies the process of creating charts and provides quick updates based on user requests.
Ximilar Visual AI for Business
Ximilar Visual AI for Business is an AI tool that offers a comprehensive platform for image recognition and visual search solutions. It provides features such as image classification, regression, object detection, AI model combination, image annotation, and more. Users can easily build custom machine learning models without coding, access ready-to-use visual AI demos, and benefit from features like image upscaling, background removal, and color extraction. The platform caters to various industries including fashion, home decor, stock photos, collectibles, med & biotech, manufacturing, and real estate.
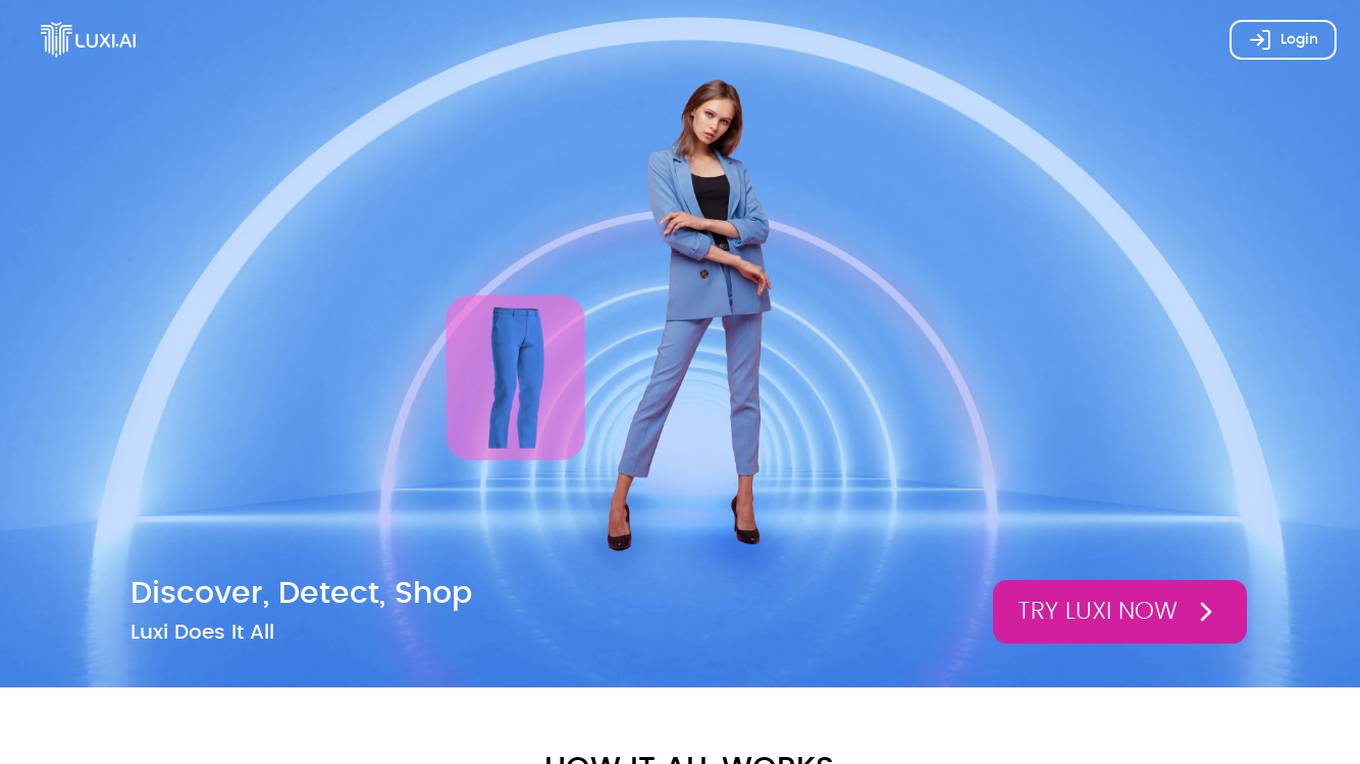
Luxi
Luxi is an AI-powered tool that enables users to automatically discover items in images. By leveraging advanced image recognition technology, Luxi can accurately identify objects within images, making it easier for users to search, categorize, and analyze visual content. With Luxi, users can streamline their image processing workflows, saving time and effort in identifying and tagging objects within large image datasets.
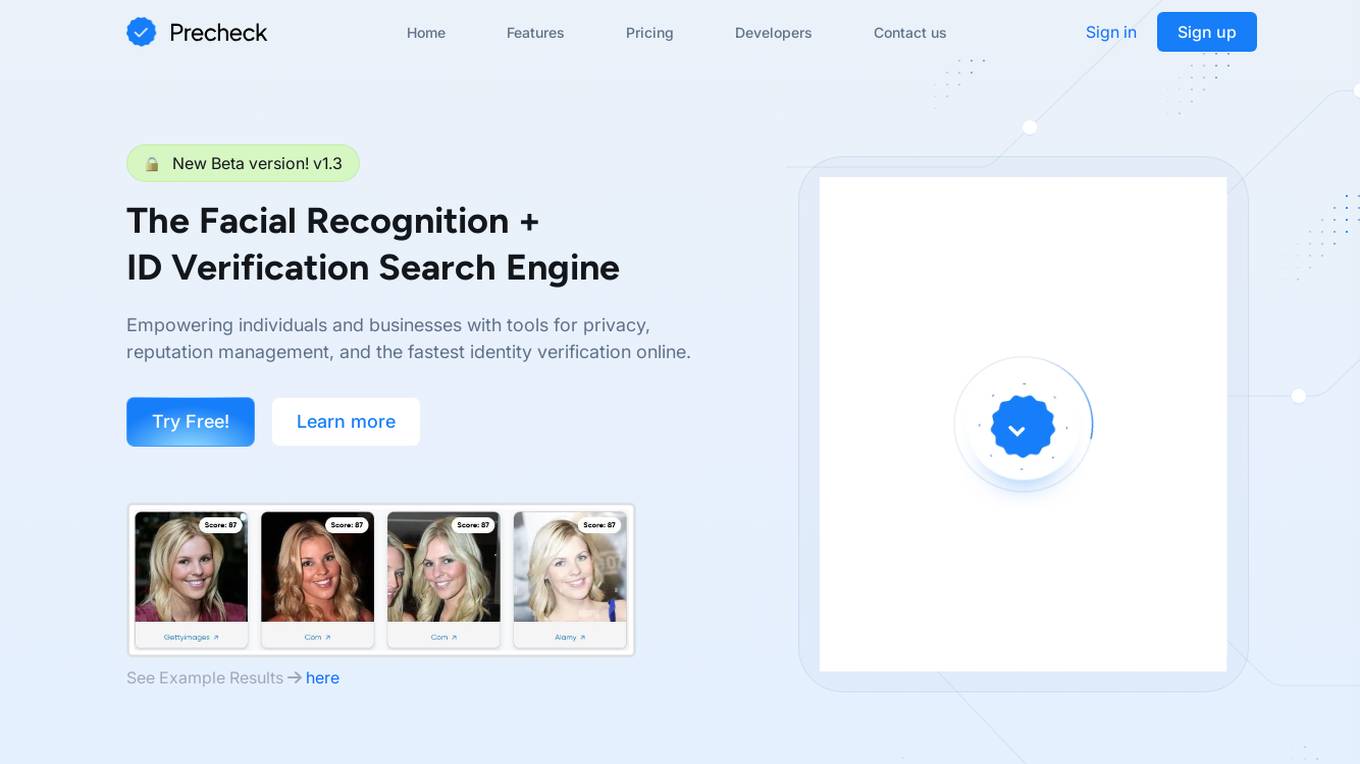
PreCheck.ai
PreCheck.ai is an AI-powered facial recognition and ID verification platform that empowers individuals and businesses with tools for privacy, reputation management, and fast online identity verification. It offers solutions for protecting personal privacy, monitoring online reputation, identifying unauthorized images, finding lost photos, assisting law enforcement, and helping content creators protect their work. The platform provides lightning-fast verification, fraud prevention, and industry-leading accuracy through features like ID/passport scan, facial image search, advanced filtering options, link and photo removal requests, data enrichment, and developer-friendly APIs.

Imagga
Imagga is a leading provider of image recognition solutions for developers and businesses. Its API empowers intelligent apps with customizable machine learning technology. Imagga's solutions include tagging, categorization, cropping, color extraction, visual search, facial recognition, custom training, and content moderation. These solutions are used by over 30K startups, developers, and students, and trusted by over 200 business customers in more than 82 countries worldwide.
GeoInfer
GeoInfer is a professional AI-powered geolocation platform that analyzes photographs to determine where they were taken. It uses visual-only inference technology to examine visual elements like architecture, terrain, vegetation, and environmental markers to identify geographic locations without requiring GPS metadata or EXIF data. The platform offers transparent accuracy levels for different use cases, including a Global Model with 1km-100km accuracy ideal for regional and city-level identification. Additionally, GeoInfer provides custom regional models for organizations requiring higher precision, such as meter-level accuracy for specific geographic areas. The platform is designed for professionals in various industries, including law enforcement, insurance fraud investigation, digital forensics, and security research.
PicTales
PicTales is an AI-powered application that generates unique stories from your favorite images. With PicTales, users can upload their images, select a genre, choose a language, and witness the magic of AI creating personalized stories. The application boasts an AI engine that ensures each story is unique, supports over 100 languages, and offers a variety of genres including Action, Thriller, and Comedy. PicTales is designed to provide users with a creative and engaging storytelling experience, making it the perfect tool for generating captivating narratives from images.
Fotogram.ai
Fotogram.ai is an AI-powered image editing tool that offers a wide range of features to enhance and transform your photos. With Fotogram.ai, users can easily apply filters, adjust colors, remove backgrounds, add effects, and retouch images with just a few clicks. The tool uses advanced AI algorithms to provide professional-level editing capabilities to users of all skill levels. Whether you are a photographer looking to streamline your workflow or a social media enthusiast wanting to create stunning visuals, Fotogram.ai has you covered.
LensAI
LensAI is an AI-powered contextual computer vision ad solution that monetizes any visual content and fine-tunes targeting through identifying objects, logos, actions, and context and matching them with relevant ads.
Custom Vision
Custom Vision is a cognitive service provided by Microsoft that offers a user-friendly platform for creating custom computer vision models. Users can easily train the models by providing labeled images, allowing them to tailor the models to their specific needs. The service simplifies the process of implementing visual intelligence into applications, making it accessible even to those without extensive machine learning expertise.

Viso Suite
Viso Suite is a no-code computer vision platform that enables users to build, deploy, and scale computer vision applications. It provides a comprehensive set of tools for data collection, annotation, model training, application development, and deployment. Viso Suite is trusted by leading Fortune Global companies and has been used to develop a wide range of computer vision applications, including object detection, image classification, facial recognition, and anomaly detection.
Google Lens
Google Lens is an AI-powered visual search tool developed by Google that allows users to search, shop, translate, and identify objects using their camera or images. With Google Lens, users can find similar clothes, furniture, and home decor, translate text in real-time from over 100 languages, get step-by-step homework help for various subjects, and identify plants and animals. The application is available on all devices and in various Google apps, making it convenient for users to access its features anytime, anywhere.

Vize.ai
Vize.ai is a custom image recognition API provided by Ximilar, a leading company in Visual AI and Search. The tool offers powerful artificial intelligence capabilities with high accuracy using deep learning algorithms. It allows users to easily set up and implement cutting-edge vision automation without any development costs. Vize.ai enables users to train custom neural networks to recognize specific images and provides a scalable solution with continuous improvements in machine learning algorithms. The tool features an intuitive interface that requires no machine learning or coding knowledge, making it accessible for a wide range of users across industries.
GPT-4o
GPT-4o is a state-of-the-art AI model developed by OpenAI, capable of processing and generating text, audio, and image outputs. It offers enhanced emotion recognition, real-time interaction, multimodal capabilities, improved accessibility, and advanced language capabilities. GPT-4o provides cost-effective and efficient AI solutions with superior vision and audio understanding. It aims to revolutionize human-computer interaction and empower users worldwide with cutting-edge AI technology.

Tagbox
Tagbox is a creative asset management tool that uses AI to organize and manage media files. It helps teams to easily find and access the assets they need, saving them time and hassle. Tagbox is used by a variety of businesses, including retailers, agencies, and event planners.
Image In Words
Image In Words is a generative model designed for scenarios that require generating ultra-detailed text from images. It leverages cutting-edge image recognition technology to provide high-quality and natural image descriptions. The framework ensures detailed and accurate descriptions, improves model performance, reduces fictional content, enhances visual-language reasoning capabilities, and has wide applications across various fields. Image In Words supports English and has been trained using approximately 100,000 hours of English data. It has demonstrated high quality and naturalness in various tests.
Vansh
Vansh is an AI tool developed by a tech enthusiast. It specializes in Vision AI and Vispark technologies. The tool offers advanced features for image recognition, object detection, and visual data analysis. With a user-friendly interface, Vansh caters to both beginners and experts in the field of artificial intelligence.
RunwayML Experiments
RunwayML Experiments is a platform that allows users to create and share machine learning models. It provides a variety of tools and resources to help users get started with machine learning, including a library of pre-trained models, a visual programming interface, and a community of experts. RunwayML Experiments is used by a variety of people, including researchers, students, and hobbyists.
YouScan
YouScan is an AI-powered social media listening platform that offers industry-leading image recognition capabilities. It provides visual and audience insights, social media monitoring, crisis management, competitor analysis, market research, and influencer discovery. The platform helps businesses analyze consumer opinions, discover actionable insights, and manage brand reputation. With features like Insights Copilot, Visual Insights, and AI-driven tools, YouScan is a comprehensive solution for social media intelligence and brand management.
Joseph Chet Redmon's Computer Vision Platform
The website is a platform maintained by Joseph Chet Redmon, a graduate student working on computer vision. It features information on his projects, publications, talks, and teaching activities. The site also includes details about the Darknet Neural Network Framework, tactics in Coq, and research work. Visitors can learn about computer vision, object recognition, and visual question answering through the resources provided on the site.
1 - Open Source AI Tools
gemini-next-chat
Gemini Next Chat is an open-source, extensible high-performance Gemini chatbot framework that supports one-click free deployment of private Gemini web applications. It provides a simple interface with image recognition and voice conversation, supports multi-modal models, talk mode, visual recognition, assistant market, support plugins, conversation list, full Markdown support, privacy and security, PWA support, well-designed UI, fast loading speed, static deployment, and multi-language support.
20 - OpenAI Gpts
Brico Rigolo
Identifie les outils et matériaux à partir de photos pour l'achat ou la recherche en ligne.

Visual Storyteller
Extract the essence of the novel story according to the quantity requirements and generate corresponding images. The images can be used directly to create novel videos.小说推文图片自动批量生成,可自动生成风格一致性图片
Visual Pedestrian Pathfinder
I create tailored walks, asking detailed preferences and giving distance in km!
Visual Design GPT ✅ ❌
A resource for visual designers, "Principles and Pitfalls" details how to make impactful visual designs and avoid missteps.
Visual Artists Career Guide
A mega-helpful guide for visual artists seeking career and 2024 marketing advice. It includes offering artistic inspiration and balancing creative and business aspects, and it can be trained on and understand your unique journey and aspirations, your challenges, and art forms.
Visual Artist Copilot
This tool is here to help through the creative process generating pictures with DALL.E.
Visual stock analysis
Professional analyzer of stock charts image with factual and concise interpretations.