Best AI tools for< Test Llms >
20 - AI tool Sites

OpenPlayground
OpenPlayground is a cloud-based platform that provides access to a variety of AI tools and resources. It allows users to train and deploy machine learning models, access pre-trained models, and collaborate on AI projects. OpenPlayground is designed to make AI more accessible and easier to use for everyone, from beginners to experienced data scientists.
RoostGPT
RoostGPT is an AI-driven testing copilot that offers automated test case generation and code scanning services. It leverages Generative-AI and Large Language Models (LLMs) to provide reliable software testing solutions. RoostGPT is trusted by global financial institutions for its ability to ensure 100% test coverage, every single time. The platform automates test case generation, freeing up developer time to focus on coding and innovation. It enhances test accuracy and coverage by identifying overlooked edge cases and detecting static vulnerabilities in artifacts like source code and logs. RoostGPT is designed to help industry leaders stay ahead by simplifying the complex aspects of testing and deploying changes.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

Freeplay
Freeplay is a tool that helps product teams experiment, test, monitor, and optimize AI features for customers. It provides a single pane of glass for the entire team, lightweight developer SDKs for Python, Node, and Java, and deployment options to meet compliance needs. Freeplay also offers best practices for the entire AI development lifecycle.
Cabina.AI
Cabina.AI is a free AI platform that allows users to generate content, text, and images online through a single chat interface. It offers a range of AI models such as ChatGpt, DALLE, Claude, Gemini, Flux, Mistral, and more for tasks like content creation, research, and real-time task solving. Users can access different LLMs, compare results, and find the best solutions faster. Cabina.AI also provides personalized actions, organization of chats, and the ability to track various data points. With flexible pricing plans and a friendly community, Cabina.AI aims to be a universal tool for research and content creation.

LLM Clash
LLM Clash is a web-based application that allows users to compare the outputs of different large language models (LLMs) on a given task. Users can input a prompt and select which LLMs they want to compare. The application will then display the outputs of the LLMs side-by-side, allowing users to compare their strengths and weaknesses.
Langtail
Langtail is a platform that helps developers build, test, and deploy AI-powered applications. It provides a suite of tools to help developers debug prompts, run tests, and monitor the performance of their AI models. Langtail also offers a community forum where developers can share tips and tricks, and get help from other users.
Repromptify
Repromptify is an AI tool that simplifies the process of creating AI prompts. It allows users to generate end-to-end optimized prompts for various AI models such as GPT-4, LLMs, DALLE•2, and Midjourney ChatGPT. With Repromptify, users can easily test and generate images and responses tailored to their needs without worrying about ambiguity or details. The tool offers a free trial for users to explore its features upon signing up.

Confident AI
Confident AI is an open-source evaluation infrastructure for Large Language Models (LLMs). It provides a centralized platform to judge LLM applications, ensuring substantial benefits and addressing any weaknesses in LLM implementation. With Confident AI, companies can define ground truths to ensure their LLM is behaving as expected, evaluate performance against expected outputs to pinpoint areas for iterations, and utilize advanced diff tracking to guide towards the optimal LLM stack. The platform offers comprehensive analytics to identify areas of focus and features such as A/B testing, evaluation, output classification, reporting dashboard, dataset generation, and detailed monitoring to help productionize LLMs with confidence.
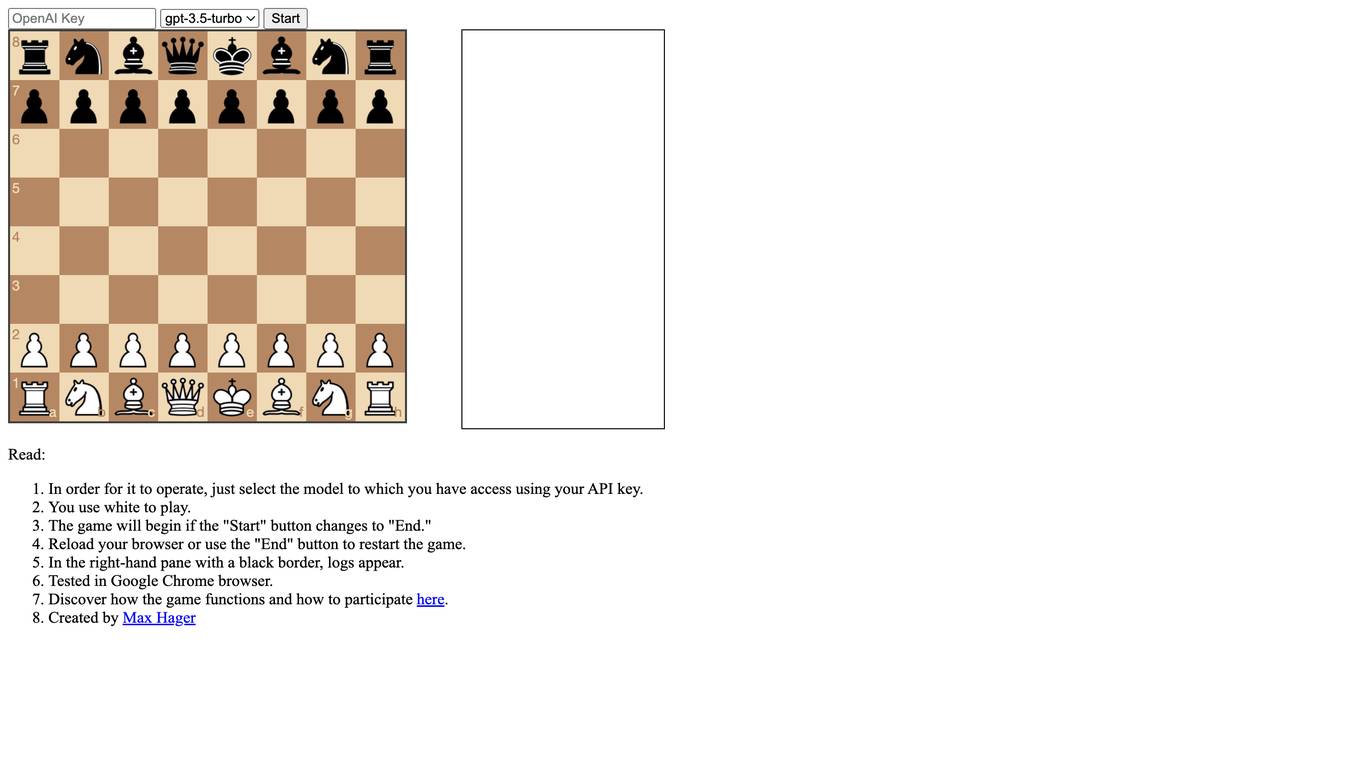
LLMChess
LLMChess is a web-based chess game that utilizes large language models (LLMs) to power the gameplay. Players can select the LLM model they wish to play against, and the game will commence once the "Start" button is clicked. The game logs are displayed in a black-bordered pane on the right-hand side of the screen. LLMChess is compatible with the Google Chrome browser. For more information on the game's functionality and participation guidelines, please refer to the provided link.
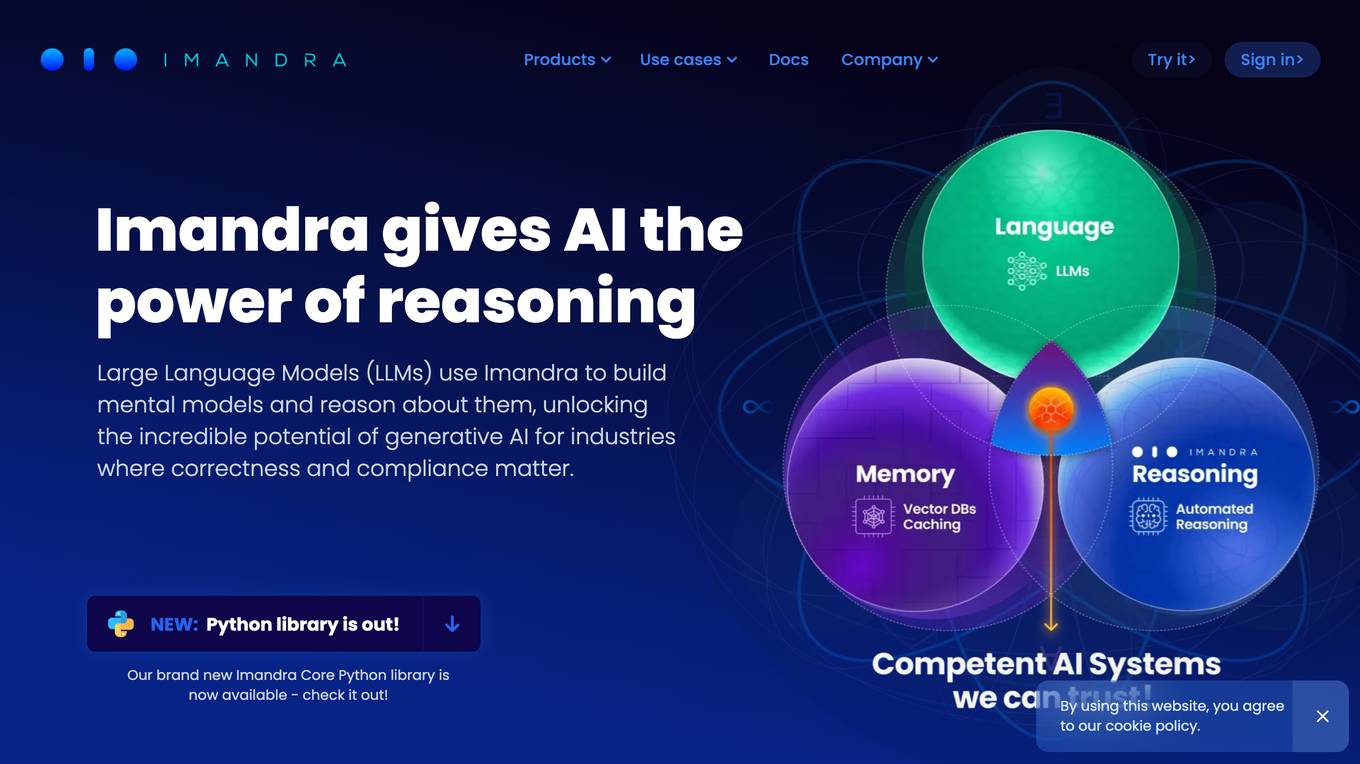
Imandra
Imandra is a company that provides automated logical reasoning for Large Language Models (LLMs). Imandra's technology allows LLMs to build mental models and reason about them, unlocking the potential of generative AI for industries where correctness and compliance matter. Imandra's platform is used by leading financial firms, the US Air Force, and DARPA.
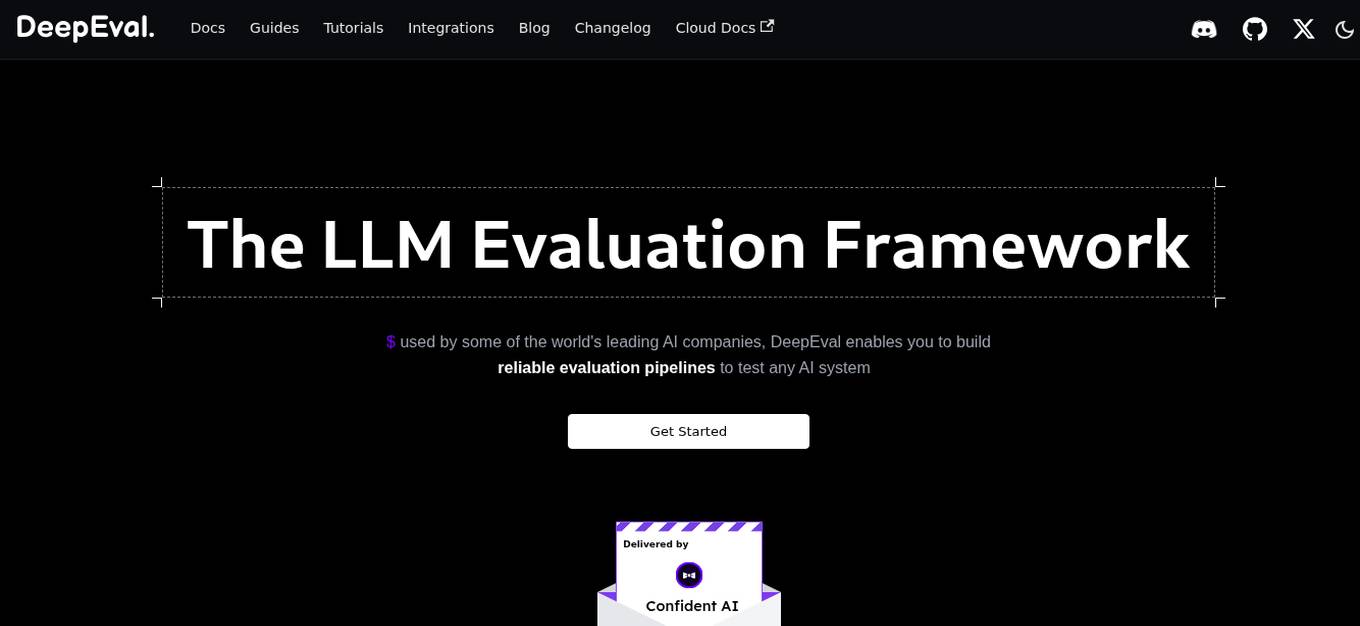
DeepEval
DeepEval by Confident AI is a comprehensive LLM Evaluation Framework used by leading AI companies. It enables users to build reliable evaluation pipelines to test any AI system. With 50+ research-backed metrics, native multi-modal support, and auto-optimization of prompts, DeepEval offers a sophisticated evaluation ecosystem for AI applications. The framework covers unit-testing for LLMs, single and multi-turn evaluations, generation & simulation of test data, and state-of-the-art evaluation techniques like G-Eval and DAG. DeepEval is integrated with Pytest and supports various system architectures, making it a versatile tool for AI testing.
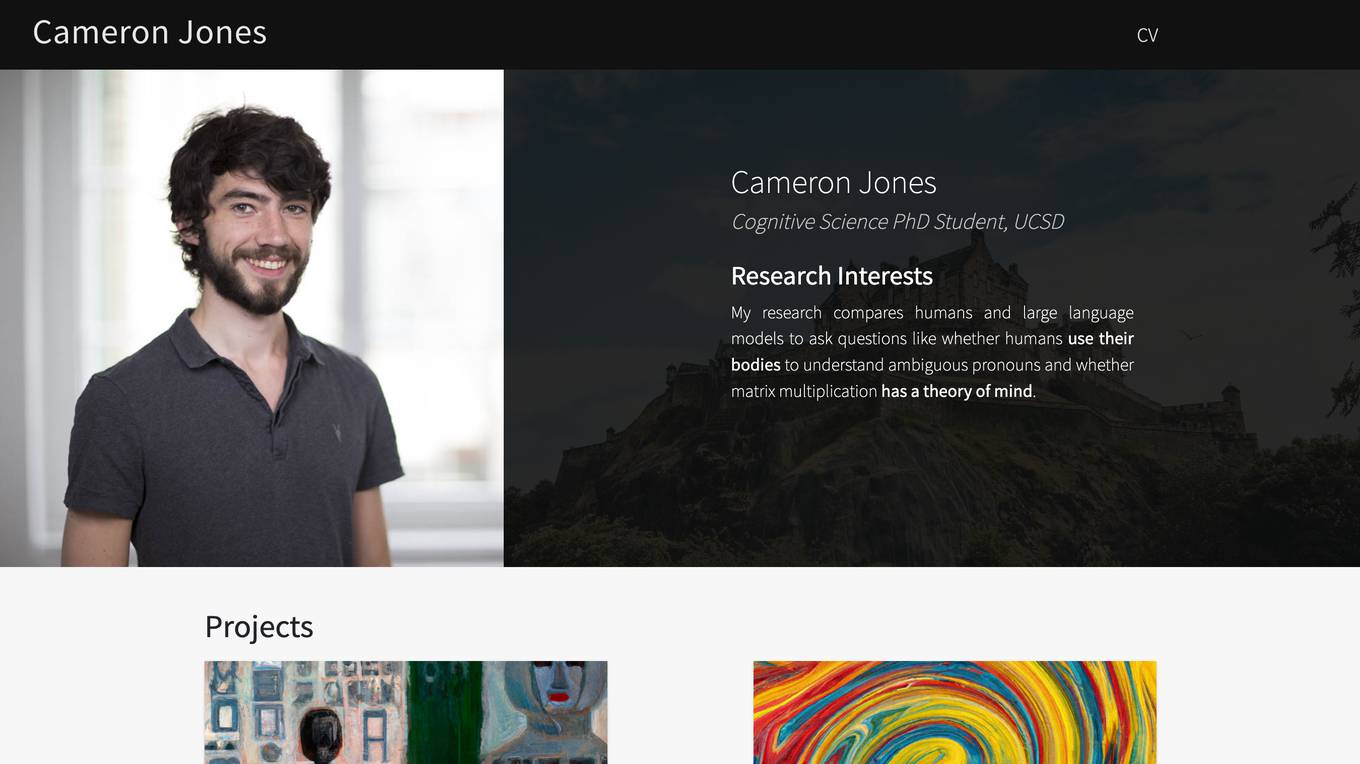
Cameron Jones
The Cameron Jones website is a platform maintained by a Cognitive Science PhD student with a focus on persuasion, deception, and social intelligence in humans and Large Language Models (LLMs). The site showcases the student's publications, projects, and CV, along with research on LLM performance in tasks like the False Belief task and the Turing test.
Infermatic.ai
Infermatic.ai is a platform that provides access to top Large Language Models (LLMs) with a user-friendly interface. It offers complete privacy, robust security, and scalability for projects, research, and integrations. Users can test, choose, and scale LLMs according to their content needs or business strategies. The platform eliminates the complexities of infrastructure management, latency issues, version control problems, integration complexities, scalability concerns, and cost management issues. Infermatic.ai is designed to be secure, intuitive, and efficient for users who want to leverage LLMs for various tasks.
BotStacks
BotStacks is a conversational AI solution that offers premium AI sidekicks to automate, engage, and succeed. It provides a platform for designing, building, and deploying AI chatbots with advanced technology accessible to everyone. With features like canvas designer, knowledge base, and chat SDKs, BotStacks empowers users to create personalized and scalable AI assistants. The application focuses on easy design flow, seamless integration, customization, scalability, and accessibility for non-technical users, making it a gateway to the future of conversational AI.
Riku
Riku is a no-code platform that allows users to build and deploy powerful generative AI for their business. With access to over 40 industry-leading LLMs, users can easily test different prompts to find just the right one for their needs. Riku's platform also allows users to connect siloed data sources and systems together to feed into powerful AI applications. This makes it easy for businesses to automate repetitive tasks, test ideas rapidly, and get answers in real-time.
AI Generated Test Cases
AI Generated Test Cases is an innovative tool that leverages artificial intelligence to automatically generate test cases for software applications. By utilizing advanced algorithms and machine learning techniques, this tool can efficiently create a comprehensive set of test scenarios to ensure the quality and reliability of software products. With AI Generated Test Cases, software development teams can save time and effort in the testing phase, leading to faster release cycles and improved overall productivity.

AI Test Kitchen
AI Test Kitchen is a website that provides a variety of AI-powered tools for creative professionals. These tools can be used to generate images, music, and text, as well as to explore different creative concepts. The website is designed to be a place where users can experiment with AI and learn how to use it to enhance their creative process.
Face Symmetry Test
Face Symmetry Test is an AI-powered tool that analyzes the symmetry of facial features by detecting key landmarks such as eyes, nose, mouth, and chin. Users can upload a photo to receive a personalized symmetry score, providing insights into the balance and proportion of their facial features. The tool uses advanced AI algorithms to ensure accurate results and offers guidelines for improving the accuracy of the analysis. Face Symmetry Test is free to use and prioritizes user privacy and security by securely processing uploaded photos without storing or sharing data with third parties.
Cambridge English Test AI
The AI-powered Cambridge English Test platform offers exercises for English levels B1, B2, C1, and C2. Users can select exercise types such as Reading and Use of English, including activities like Open Cloze, Multiple Choice, Word Formation, and more. The AI, developed by Shining Apps in partnership with Use of English PRO, provides a unique learning experience by generating exercises from a database of over 5000 official exams. It uses advanced Natural Language Processing (NLP) to understand context, tweak exercises, and offer detailed feedback for effective learning.
2 - Open Source AI Tools
empirical
Empirical is a tool that allows you to test different LLMs, prompts, and other model configurations across all the scenarios that matter for your application. With Empirical, you can run your test datasets locally against off-the-shelf models, test your own custom models and RAG applications, view, compare, and analyze outputs on a web UI, score your outputs with scoring functions, and run tests on CI/CD.
bench
Bench is a tool for evaluating LLMs for production use cases. It provides a standardized workflow for LLM evaluation with a common interface across tasks and use cases. Bench can be used to test whether open source LLMs can do as well as the top closed-source LLM API providers on specific data, and to translate the rankings on LLM leaderboards and benchmarks into scores that are relevant for actual use cases.
20 - OpenAI Gpts
Test Shaman
Test Shaman: Guiding software testing with Grug wisdom and humor, balancing fun with practical advice.
Raven's Progressive Matrices Test
Provides Raven's Progressive Matrices test with explanations and calculates your IQ score.

IQ Test Assistant
An AI conducting 30-question IQ tests, assessing and providing detailed feedback.
Test Case GPT
I will provide guidance on testing, verification, and validation for QA roles.

GRE Test Vocabulary Learning
Helps user learn essential vocabulary for GRE test with multiple choice questions
Lab Test Insights
I'm your lab test consultant for blood tests and microbial cultures. How can I help you today?


Cyber Test & CareerPrep
Helping you study for cybersecurity certifications and get the job you want!
Complete Apex Test Class Assistant
Crafting full, accurate Apex test classes, with 100% user service.