Best AI tools for< Process Complex Documents >
20 - AI tool Sites
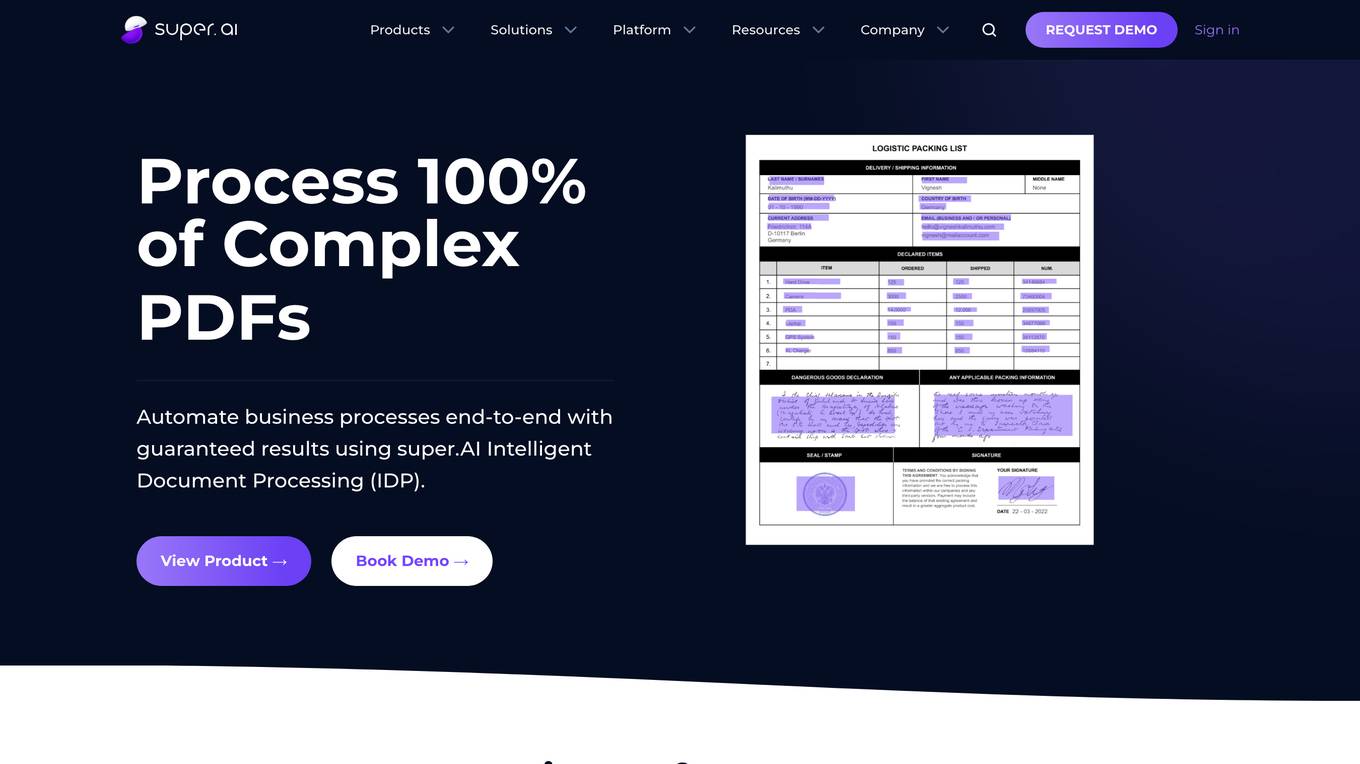
super.AI
Super.AI provides Intelligent Document Processing (IDP) solutions powered by Large Language Models (LLMs) and human-in-the-loop (HITL) capabilities. It automates document processing tasks such as data extraction, classification, and redaction, enabling businesses to streamline their workflows and improve accuracy. Super.AI's platform leverages cutting-edge AI models from providers like Amazon, Google, and OpenAI to handle complex documents, ensuring high-quality outputs. With its focus on accuracy, flexibility, and scalability, Super.AI caters to various industries, including financial services, insurance, logistics, and healthcare.
Lawformer
Lawformer is an AI-powered tool designed to simplify the process of handling complex legal documents. It offers an extensive database of attorney-drafted clauses and terms for any contract, along with a learning platform to enhance practical skills in contract drafting. Users can create a personalized library, manage contract knowledge efficiently, and find relevant contract clauses quickly. Lawformer has been serving Silicon Valley startups and the UK's entrepreneurial community since 2009 and 2015, respectively, and is recognized as an international platform for online payments. The platform is trusted by legal professionals and students alike for its comprehensive resources and user-friendly interface.
Centari
Centari is a platform for deal intelligence that leverages generative AI to transform complex documents into actionable insights. It helps users unlock more dealflow, enrich marketing materials, visualize market trends, and streamline the deal validation process. With features like data extraction, intuitive validation, and deal history visualization, Centari empowers users to make informed decisions and win deals with competitive knowledge.
MapDeduce
MapDeduce is an AI-powered tool that helps users understand and analyze complex documents. It can be used to summarize documents, extract key information, and identify potential red flags. MapDeduce is designed to save users time and effort by automating the process of document analysis.

PaperEntry AI
Deep Cognition offers PaperEntry AI, an Intelligent Document Processing solution powered by generative AI. It automates data entry tasks with high accuracy, scalability, and configurability, handling complex documents of any type or format. The application is trusted by leading global organizations for customs clearance automation and government document processing, delivering significant time and cost savings. With industry-specific features and a proven track record, Deep Cognition provides a state-of-the-art solution for businesses seeking efficient data extraction and automation.
Humata
Humata is a PDF AI that can summarize findings, compare documents, and search for answers in long technical papers. It is designed to help users save time and effort by automating the process of reading and understanding complex documents. Humata is easy to use and can be embedded in any webpage with a single click. It is also secure and reliable, with enterprise-grade data rooms and encryption to protect user data.
ChatInDoc
ChatInDoc is an AI-powered tool designed to revolutionize the way people interact with and comprehend lengthy documents. By leveraging cutting-edge AI technology, ChatInDoc offers users the ability to efficiently analyze, summarize, and extract key information from various file formats such as PDFs, Office documents, and text files. With features like IR analysis, term lookup, PDF viewing, and AI-powered chat capabilities, ChatInDoc aims to streamline the process of digesting complex information and enhance productivity. The application's user-friendly interface and advanced AI algorithms make it a valuable tool for students, professionals, and anyone dealing with extensive document reading tasks.
Infrrd
Infrrd is an intelligent document automation platform that offers advanced document extraction solutions. It leverages AI technology to enhance, classify, extract, and review documents with high accuracy, eliminating the need for human review. Infrrd provides effective process transformation solutions across various industries, such as mortgage, invoice, insurance, and audit QC. The platform is known for its world-class document extraction engine, supported by over 10 patents and award-winning algorithms. Infrrd's AI-powered automation streamlines document processing, improves data accuracy, and enhances operational efficiency for businesses.
Tipis AI
Tipis AI is an AI assistant for data processing that uses Large Language Models (LLMs) to quickly read and analyze mainstream documents with enhanced precision. It can also generate charts, integrate with a wide range of mainstream databases and data sources, and facilitate seamless collaboration with other team members. Tipis AI is easy to use and requires no configuration.
Kopyst
Kopyst is an AI-powered documentation tool that revolutionizes the process of creating engaging video and documents. It helps users streamline workflows, create user manuals, SOPs, and training documents with unmatched accuracy and efficiency. Kopyst offers features like instant documentation, versatile application for various document types, AI-powered intelligence, easy sharing and collaboration, and seamless integration with existing tools. The application empowers users to save time, reduce errors, optimize resources, and enhance productivity in documentation tasks.
PYQ
PYQ is an AI-powered platform that helps businesses automate document-related tasks, such as data extraction, form filling, and system integration. It uses natural language processing (NLP) and machine learning (ML) to understand the content of documents and perform tasks accordingly. PYQ's platform is designed to be easy to use, with pre-built automations for common use cases. It also offers custom automation development services for more complex needs.
Affordibly
Affordibly is an AI-powered platform that offers users the ability to generate personalized legal documents with ease. The platform provides access to a wide range of legal document templates for business, personal, family, and policy-related needs. Additionally, Affordibly features an AI assistant called Adore AI, which is trained to review, analyze, and redraft complex contracts quickly and accurately. Users can also benefit from Adore Projects, a project management software designed for simplicity and efficiency. Affordibly aims to simplify the legal document creation process and empower users with AI-driven contract analysis and project management tools.
Cradl AI
Cradl AI is a no-code AI-powered document workflow automation tool that helps organizations automate document-related tasks, such as data extraction, processing, and validation. It uses AI to automatically extract data from complex document layouts, regardless of layout or language. Cradl AI also integrates with other no-code tools, making it easy to build and deploy custom AI models.
Altilia
Altilia is a Major Player in the Intelligent Document Processing market, offering a cloud-native, no-code, SaaS platform powered by composite AI. The platform enables businesses to automate complex document processing tasks, streamline workflows, and enhance operational performance. Altilia's solution leverages GPT and Large Language Models to extract structured data from unstructured documents, providing significant efficiency gains and cost savings for organizations of all sizes and industries.
Prudent AI
Prudent AI is an AI-powered Income Intelligence Platform designed for lenders, offering fast data extraction, proactive fraud prevention, and in-depth insights on borrower income. The platform simplifies complex income calculations, streamlines the lending process, and enables lenders to make confident loan decisions quickly. Prudent AI is trusted by various lending institutions and has been proven to increase productivity, save time, and improve submission accuracy.
Mapify
Mapify is an AI-powered tool that transforms any type of content, such as text, images, audio, and files, into clear and concise mind maps. It helps users break down complex information into structured visual representations, saving time and enhancing productivity. Mapify offers features like instant mapping from documents and videos, text-to-image conversion, and AI-assisted brainstorming. Users can benefit from built-in AI templates, real-time web access, and chat interactions to optimize their workspace and idea visualization process.
AWS Docs GPT
AWS Docs GPT is an AI-powered search and chat tool designed specifically for AWS Documentation. It utilizes advanced AI technology to provide users with accurate and relevant information from the vast AWS knowledge base. Users can interact with the tool through natural language queries and receive instant responses, making it easier to navigate and understand complex AWS documentation. With features like Antimetal for cost savings and a clear prompt interface, AWS Docs GPT enhances the user experience and streamlines the process of accessing AWS resources.

Code2Docs
Code2Docs is an AI-powered tool designed to automate code documentation for software developers. By leveraging advanced AI technology, Code2Docs streamlines the documentation process, transforming complex codebases into clear and comprehensive documentation. With seamless integration with GitHub and an intuitive user interface, Code2Docs aims to make documentation effortless and efficient, saving time and reducing technical debt for developers.

Hyperscience
Hyperscience is a leading enterprise AI platform that provides hyperautomation solutions for businesses. Its platform enables organizations to automate complex business processes with high accuracy and efficiency. Hyperscience offers a range of solutions across various industries and processes, leveraging technologies such as intelligent document processing, machine learning, and natural language processing. The platform is designed to help businesses transform their operations, improve decision-making, and gain a competitive advantage.
Syntetica
Syntetica is an AI-powered platform that revolutionizes content generation by enabling users to efficiently explore and develop complex ideas and tasks. With a focus on speed and flexibility, Syntetica allows seamless integration of processes into daily workflows. The platform offers features such as generating complete documents, creating customized processes, automating tasks, and integrating with various file types. Syntetica caters to individuals, small teams, and enterprises, providing tailored plans to meet specific needs. The application's user-friendly interface and advanced task automation capabilities make it a valuable tool for professionals across different industries.
1 - Open Source AI Tools
aws-ai-intelligent-document-processing
This repository is part of Intelligent Document Processing with AWS AI Services workshop. It aims to automate the extraction of information from complex content in various document formats such as insurance claims, mortgages, healthcare claims, contracts, and legal contracts using AWS Machine Learning services like Amazon Textract and Amazon Comprehend. The repository provides hands-on labs to familiarize users with these AI services and build solutions to automate business processes that rely on manual inputs and intervention across different file types and formats.
20 - OpenAI Gpts

Fill PDF Forms
Fill legal forms & complex PDF documents easily! Upload a file, provide data sources and I'll handle the rest.
Process Map Optimizer
Upload your process map and I will analyse and suggest improvements
Process Engineering Advisor
Optimizes production processes for improved efficiency and quality.
Customer Service Process Improvement Advisor
Optimizes business operations through process enhancements.

R&D Process Scale-up Advisor
Optimizes production processes for efficient large-scale operations.
Process Optimization Advisor
Improves operational efficiency by optimizing processes and reducing waste.


Manufacturing Process Development Advisor
Optimizes manufacturing processes for efficiency and quality.


Trademarks GPT
Trademark Process Assistant, Not an Attorney & Definitely Not Legal Advice (independently verify info received). Gain insights on U.S. trademark process & concepts, USPTO resources, application steps & more - all while being reminded of the importance of consulting legal pros 4 specific guidance.

Prioritization Matrix Pro
Structured process for prioritizing marketing tasks based on strategic alignment. Outputs in Eisenhower, RACI and other methodologies.

👑 Data Privacy for Insurance Companies 👑
Insurance providers collect and process personal health, financial, and property information, making it crucial to implement comprehensive data protection strategies.

ScriptCraft
To streamline the process of creating scripts for Brut-style videos by providing structured guidance in researching, strategizing, and writing, ensuring the final script is rich in content and visually captivating.