Best AI tools for< Optimize Model Speed >
20 - AI tool Sites
Bibit AI
Bibit AI is a real estate marketing AI designed to enhance the efficiency and effectiveness of real estate marketing and sales. It can help create listings, descriptions, and property content, and offers a host of other features. Bibit AI is the world's first AI for Real Estate. We are transforming the real estate industry by boosting efficiency and simplifying tasks like listing creation and content generation.
Shortcut
Shortcut is an AI-powered Excel tool that revolutionizes spreadsheet work. It is designed to enhance accuracy, auditability, Excel parity, and speed in handling complex tasks. Shortcut ensures professional formatting, never overwrites existing data, and provides instant auditability with enterprise-grade security. With seamless file compatibility, 95% feature parity on the web, and lightning-fast performance, Shortcut is the go-to solution for professionals seeking efficiency and precision in Excel tasks.
AdaL
AdaL is a self-evolving AI coding agent designed for teams and power developers. It learns from your entire team and codebase, reducing syncing time and waiting periods to deliver at the speed of thought. AdaL runs locally on your machine or remote server, ensuring privacy as your code stays private. It offers input via terminal or web interface, allowing for power or visual interactions. With the ability to switch models mid-session and collaborate with multiple models, AdaL aims to help developers bring their ideas to life efficiently and effectively.
Opulli
Opulli is an AI Fashion Model Platform for Clothing Brands that provides a smart and cost-effective solution for fashion retailers to avoid expensive photoshoots. The platform allows users to effortlessly bring product photos to life with captivating AI generated models, offering personalized connection at scale and accelerating market resonance with swift A/B testing. Opulli empowers brands to craft model photos that resonate deeply with their audience, mirroring body shapes, skin tones, and styles, without the limitations of traditional photoshoots.

Unify
Unify is an AI tool that offers a unified platform for accessing and comparing various Language Models (LLMs) from different providers. It allows users to combine models for faster, cheaper, and better responses, optimizing for quality, speed, and cost-efficiency. Unify simplifies the complex task of selecting the best LLM by providing transparent benchmarks, personalized routing, and performance optimization tools.

Maxim
Maxim is an end-to-end AI evaluation and observability platform that empowers modern AI teams to ship products with quality, reliability, and speed. It offers a comprehensive suite of tools for experimentation, evaluation, observability, and data management. Maxim aims to bring the best practices of traditional software development into non-deterministic AI workflows, enabling rapid iteration and deployment of AI models. The platform caters to the needs of AI developers, data scientists, and machine learning engineers by providing a unified framework for evaluation, visual flows for workflow testing, and observability features for monitoring and optimizing AI systems in real-time.
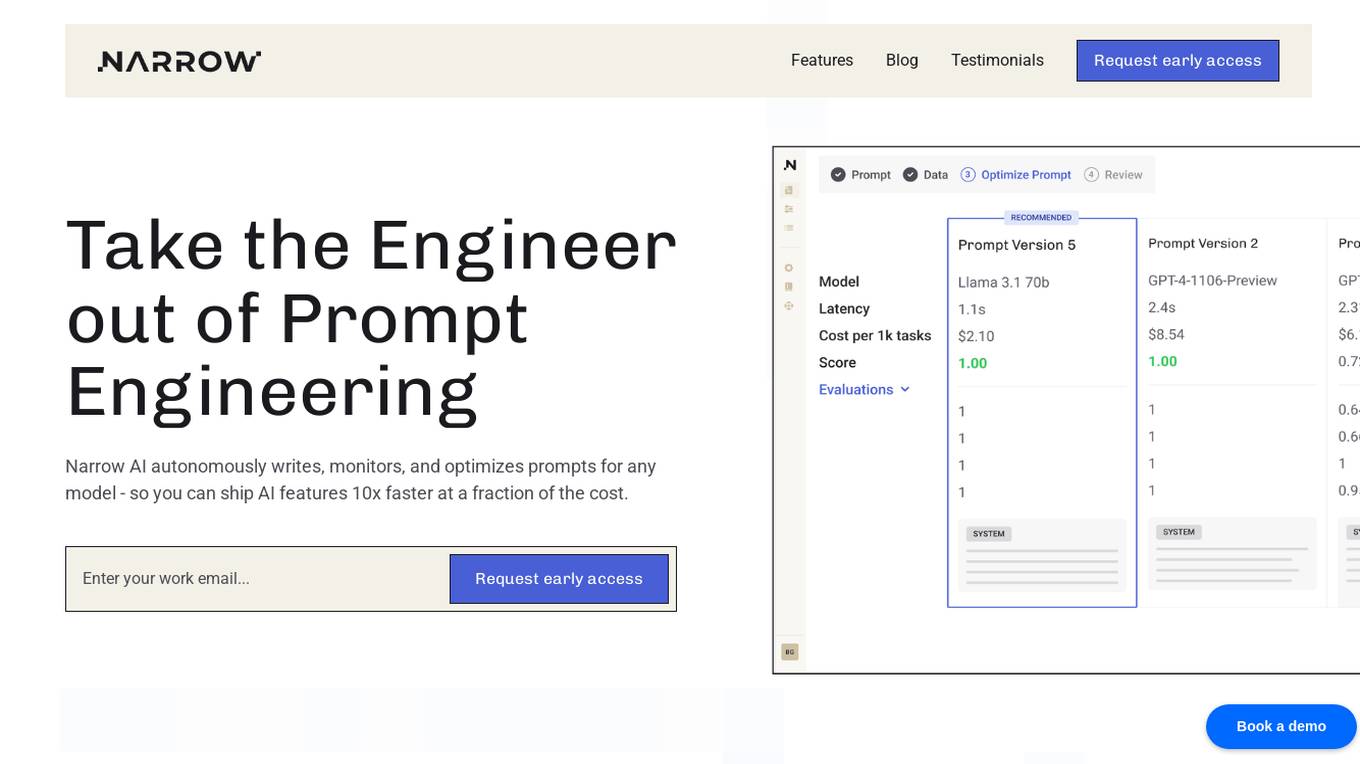
Narrow AI
Narrow AI is an AI application that autonomously writes, monitors, and optimizes prompts for any model, enabling users to ship AI features 10x faster at a fraction of the cost. It streamlines the workflow by allowing users to test new models in minutes, compare prompt performance, and deploy on the optimal model for their use case. Narrow AI helps users maximize efficiency by generating expert-level prompts, adapting prompts to new models, and optimizing prompts for quality, cost, and speed.
ONNX Runtime
ONNX Runtime is a production-grade AI engine designed to accelerate machine learning training and inferencing in various technology stacks. It supports multiple languages and platforms, optimizing performance for CPU, GPU, and NPU hardware. ONNX Runtime powers AI in Microsoft products and is widely used in cloud, edge, web, and mobile applications. It also enables large model training and on-device training, offering state-of-the-art models for tasks like image synthesis and text generation.
Wan Animate AI
Wan Animate AI is an all-in-one professional AI video generator platform that transforms static images into dynamic videos using cutting-edge technology. It offers advanced features such as motion transfer, facial expression technology, environmental lighting integration, high-resolution video generation, and open-source access. Users can create high-quality videos with wan ai intelligence and wan2.2 animate precision for various commercial applications. The platform provides customizable settings and fast processing speed, making it ideal for entertainment, marketing, and educational projects.
JFrog ML
JFrog ML is an AI platform designed to streamline AI development from prototype to production. It offers a unified MLOps platform to build, train, deploy, and manage AI workflows at scale. With features like Feature Store, LLMOps, and model monitoring, JFrog ML empowers AI teams to collaborate efficiently and optimize AI & ML models in production.
NanoBanana AI Image Generator
NanoBanana AI Image Generator is a powerful tool that allows users to create high-quality images from text in seconds. It leverages Google's Nano Banana model to generate sharp and detailed visuals suitable for professional projects, marketing campaigns, and creative content. The tool offers ultra-fast generation, high-quality outputs, SEO-optimized images, an easy-to-use interface, and multi-platform compatibility. Users can access a free trial to explore the tool's capabilities and upgrade to premium plans for unlimited usage and advanced features.

FinetuneFast
FinetuneFast is an AI tool designed to help developers, indie makers, and businesses to efficiently finetune machine learning models, process data, and deploy AI solutions at lightning speed. With pre-configured training scripts, efficient data loading pipelines, and one-click model deployment, FinetuneFast streamlines the process of building and deploying AI models, saving users valuable time and effort. The tool is user-friendly, accessible for ML beginners, and offers lifetime updates for continuous improvement.

Attio
Attio is an AI-powered CRM platform designed to help businesses streamline their customer relationship management processes. It offers a range of features such as data model customization, powerful workflows, intelligent automation, detailed reporting, and AI integration. Attio is built for scale and growth, with a focus on security and data integrity. The platform is praised for its modern interface, flexibility, and speed of setup, making it a popular choice for businesses looking to optimize their GTM strategies.

Caffe
Caffe is a deep learning framework developed by Berkeley AI Research (BAIR) and community contributors. It is designed for speed, modularity, and expressiveness, allowing users to define models and optimization through configuration without hard-coding. Caffe supports both CPU and GPU training, making it suitable for research experiments and industry deployment. The framework is extensible, actively developed, and tracks the state-of-the-art in code and models. Caffe is widely used in academic research, startup prototypes, and large-scale industrial applications in vision, speech, and multimedia.
Frugal
Frugal is an intelligent application cost engineering platform that optimizes code to reduce cloud costs automatically. It is the first AI-powered cost optimization platform built for engineers, empowering them to find and fix inefficiencies in code that drain cloud budgets. The platform aims to reinvent cost engineering by enabling developers to reduce application costs and improve cloud efficiency through automated identification and resolution of wasteful practices.

Groq
Groq is a fast AI inference tool that offers instant intelligence for openly-available models like Llama 3.1. It provides ultra-low-latency inference for cloud deployments and is compatible with other providers like OpenAI. Groq's speed is proven to be instant through independent benchmarks, and it powers leading openly-available AI models such as Llama, Mixtral, Gemma, and Whisper. The tool has gained recognition in the industry for its high-speed inference compute capabilities and has received significant funding to challenge established players like Nvidia.
CodeParrot
CodeParrot is an AI tool designed to speed up frontend development tasks by generating production-ready frontend components from Figma design files using Large Language Models. It helps developers reduce UI development time, improve code quality, and focus on more creative tasks. CodeParrot offers customization options, support for frameworks like React, Vue, and Angular, and integrates seamlessly into various workflows, making it a must-have tool for developers looking to enhance their frontend development process.

Cortex Labs
Cortex Labs is a decentralized world computer that enables AI and AI-powered decentralized applications (dApps) to run on the blockchain. It offers a Layer2 solution called ZkMatrix, which utilizes zkRollup technology to enhance transaction speed and reduce fees. Cortex Virtual Machine (CVM) supports on-chain AI inference using GPU, ensuring deterministic results across computing environments. Cortex also enables machine learning in smart contracts and dApps, fostering an open-source ecosystem for AI researchers and developers to share models. The platform aims to solve the challenge of on-chain machine learning execution efficiently and deterministically, providing tools and resources for developers to integrate AI into blockchain applications.

Cerebium
Cerebium is a serverless AI infrastructure platform that allows teams to build, test, and deploy AI applications quickly and efficiently. With a focus on speed, performance, and cost optimization, Cerebium offers a range of features and tools to simplify the development and deployment of AI projects. The platform ensures high reliability, security, and compliance while providing real-time logging, cost tracking, and observability tools. Cerebium also offers GPU variety and effortless autoscaling to meet the diverse needs of developers and businesses.

Salt AI
Salt AI is a development engine tailored for life sciences organizations, aiming to accelerate advancements in the field by enabling faster adoption and utilization of AI technologies. The platform offers reliable and reproducible AI processes, optimized for speed and efficiency, and promotes transparency and collaboration within workflows. With a focus on supporting best-in-class life sciences research models, Salt AI empowers users to enhance their understanding of biological processes through flexible and performant AI solutions.
1 - Open Source AI Tools

Native-LLM-for-Android
This repository provides a demonstration of running a native Large Language Model (LLM) on Android devices. It supports various models such as Qwen2.5-Instruct, MiniCPM-DPO/SFT, Yuan2.0, Gemma2-it, StableLM2-Chat/Zephyr, and Phi3.5-mini-instruct. The demo models are optimized for extreme execution speed after being converted from HuggingFace or ModelScope. Users can download the demo models from the provided drive link, place them in the assets folder, and follow specific instructions for decompression and model export. The repository also includes information on quantization methods and performance benchmarks for different models on various devices.
20 - OpenAI Gpts

Back Propagation
I'm Back Propagation, here to help you understand and apply back propagation techniques to your AI models.




Modelos de Negocios GPT
Guía paso a paso para la creación y mejora de modelos de negocio usando la metodología Business Model Canvas.
Shell Mentor
An AI GPT model designed to assist with Shell/Bash programming, providing real-time code suggestions, debugging tips, and script optimization for efficient command-line operations.

Octorate Code Companion
I help developers understand and use APIs, referencing a YAML model.
Agent Prompt Generator for LLM's
This GPT generates the best possible LLM-agents for your system prompts. You can also specify the model size, like 3B, 33B, 70B, etc.




Apple CoreData Complete Code Expert
A detailed expert trained on all 5,588 pages of Apple CoreData, offering complete coding solutions. Saving time? https://www.buymeacoffee.com/parkerrex ☕️❤️


