Best AI tools for< Optimize Model >
20 - AI tool Sites
Anycores
Anycores is an AI tool designed to optimize the performance of deep neural networks and reduce the cost of running AI models in the cloud. It offers a platform that provides automated solutions for tuning and inference consultation, optimized networks zoo, and platform for reducing AI model cost. Anycores focuses on faster execution, reducing inference time over 10x times, and footprint reduction during model deployment. It is device agnostic, supporting Nvidia, AMD GPUs, Intel, ARM, AMD CPUs, servers, and edge devices. The tool aims to provide highly optimized, low footprint networks tailored to specific deployment scenarios.
FuriosaAI
FuriosaAI is an AI application that offers Hardware RNGD for LLM and Multimodality, as well as WARBOY for Computer Vision. It provides a comprehensive developer experience through the Furiosa SDK, Model Zoo, and Dev Support. The application focuses on efficient AI inference, high-performance LLM and multimodal deployment capabilities, and sustainable mass adoption of AI. FuriosaAI features the Tensor Contraction Processor architecture, software for streamlined LLM deployment, and a robust ecosystem support. It aims to deliver powerful and efficient deep learning acceleration while ensuring future-proof programmability and efficiency.
Embedl
Embedl is an AI tool that specializes in developing advanced solutions for efficient AI deployment in embedded systems. With a focus on deep learning optimization, Embedl offers a cost-effective solution that reduces energy consumption and accelerates product development cycles. The platform caters to industries such as automotive, aerospace, and IoT, providing cutting-edge AI products that drive innovation and competitive advantage.
FineTuneAIs.com
FineTuneAIs.com is a platform that specializes in custom AI model fine-tuning. Users can fine-tune their AI models to achieve better performance and accuracy. The platform requires JavaScript to be enabled for optimal functionality.
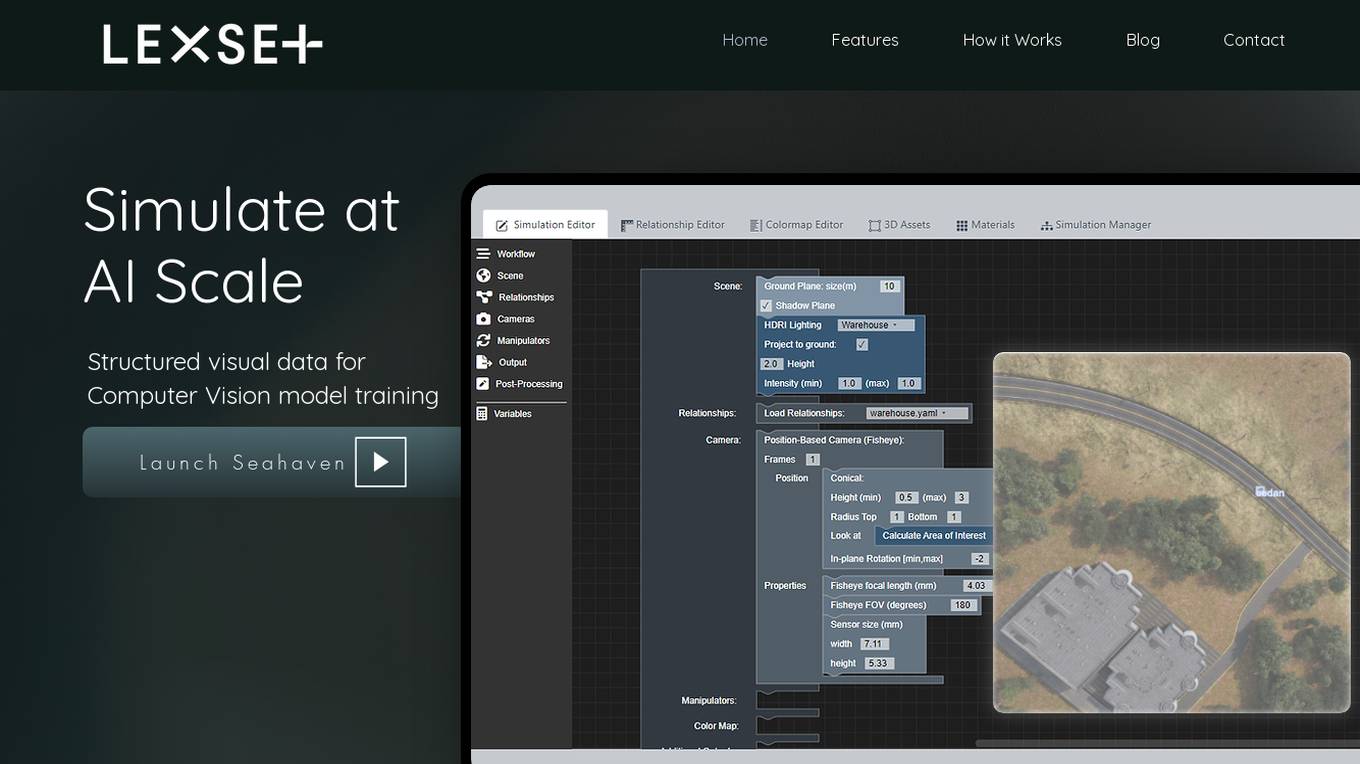
Lexset
Lexset is an AI tool that provides synthetic data generation services for computer vision model training. It offers a no-code interface to create unlimited data with advanced camera controls and lighting options. Users can simulate AI-scale environments, composite objects into images, and create custom 3D scenarios. Lexset also provides access to GPU nodes, dedicated support, and feature development assistance. The tool aims to improve object detection accuracy and optimize generalization on high-quality synthetic data.

LM-Kit.NET
LM-Kit.NET is a comprehensive AI toolkit for .NET developers, offering a wide range of features such as AI agent integration, data processing, text analysis, translation, text generation, and model optimization. The toolkit enables developers to create intelligent and adaptable AI applications by providing tools for language models, sentiment analysis, emotion detection, and more. With a focus on performance optimization and security, LM-Kit.NET empowers developers to build cutting-edge AI solutions seamlessly into their C# and VB.NET applications.
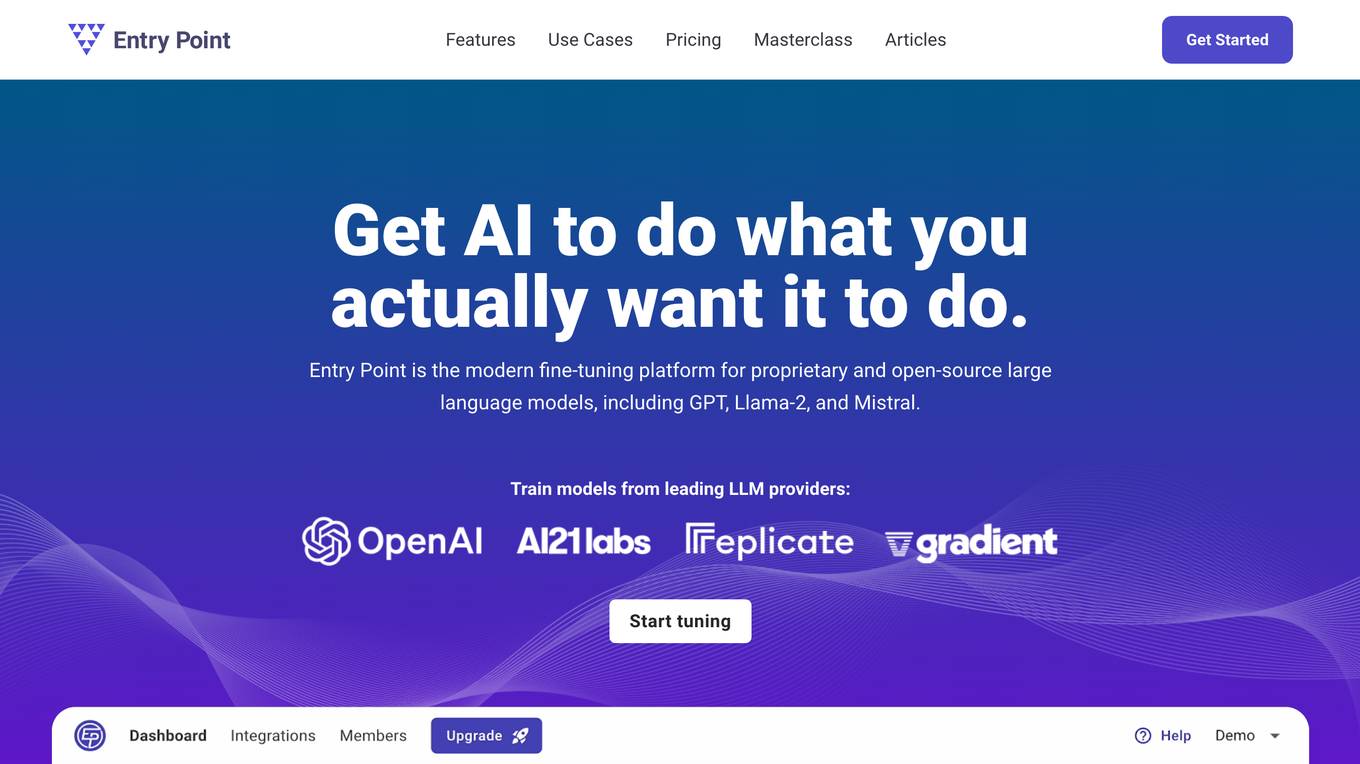
Entry Point AI
Entry Point AI is a modern AI optimization platform for fine-tuning proprietary and open-source language models. It provides a user-friendly interface to manage prompts, fine-tunes, and evaluations in one place. The platform enables users to optimize models from leading providers, train across providers, work collaboratively, write templates, import/export data, share models, and avoid common pitfalls associated with fine-tuning. Entry Point AI simplifies the fine-tuning process, making it accessible to users without the need for extensive data, infrastructure, or insider knowledge.
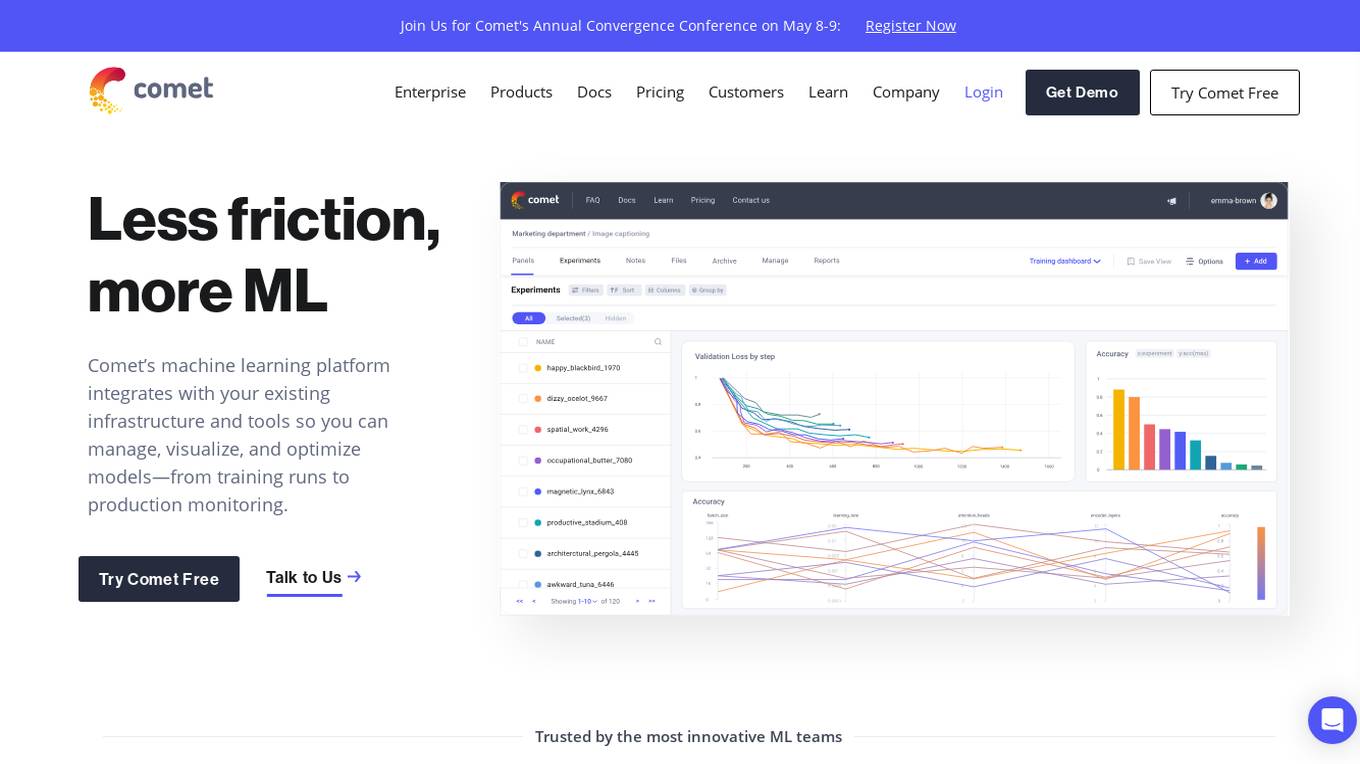
Comet ML
Comet ML is an extensible, fully customizable machine learning platform that aims to move ML forward by supporting productivity, reproducibility, and collaboration. It integrates with existing infrastructure and tools to manage, visualize, and optimize models from training runs to production monitoring. Users can track and compare training runs, create a model registry, and monitor models in production all in one platform. Comet's platform can be run on any infrastructure, enabling users to reshape their ML workflow and bring their existing software and data stack.
Together AI
Together AI is an AI Acceleration Cloud platform that offers fast inference, fine-tuning, and training services. It provides self-service NVIDIA GPUs, model deployment on custom hardware, AI chat app, code execution sandbox, and tools to find the right model for specific use cases. The platform also includes a model library with open-source models, documentation for developers, and resources for advancing open-source AI. Together AI enables users to leverage pre-trained models, fine-tune them, or build custom models from scratch, catering to various generative AI needs.
Comet ML
Comet ML is a machine learning platform that integrates with your existing infrastructure and tools so you can manage, visualize, and optimize models—from training runs to production monitoring.
Comet ML
Comet ML is a machine learning platform that integrates with your existing infrastructure and tools so you can manage, visualize, and optimize models—from training runs to production monitoring.
ONNX
ONNX is an open standard for machine learning interoperability, providing a common format to represent machine learning models. It defines a set of operators and a file format for AI developers to use models across various frameworks, tools, runtimes, and compilers. ONNX promotes interoperability, hardware access, and community engagement.

Bagel
Bagel is an AI & Cryptography Research Lab that focuses on making open source AI monetizable by leveraging novel cryptography techniques. Their innovative fine-tuning technology tracks the evolution of AI models, ensuring every contribution is rewarded. Bagel is built for autonomous AIs with large resource requirements and offers permissionless infrastructure for seamless information flow between machines and humans. The lab is dedicated to privacy-preserving machine learning through advanced cryptography schemes.
Valohai
Valohai is a scalable MLOps platform that enables Continuous Integration/Continuous Deployment (CI/CD) for machine learning and pipeline automation on-premises and across various cloud environments. It helps streamline complex machine learning workflows by offering framework-agnostic ML capabilities, automatic versioning with complete lineage of ML experiments, hybrid and multi-cloud support, scalability and performance optimization, streamlined collaboration among data scientists, IT, and business units, and smart orchestration of ML workloads on any infrastructure. Valohai also provides a knowledge repository for storing and sharing the entire model lifecycle, facilitating cross-functional collaboration, and allowing developers to build with total freedom using any libraries or frameworks.
ONNX Runtime
ONNX Runtime is a production-grade AI engine designed to accelerate machine learning training and inferencing in various technology stacks. It supports multiple languages and platforms, optimizing performance for CPU, GPU, and NPU hardware. ONNX Runtime powers AI in Microsoft products and is widely used in cloud, edge, web, and mobile applications. It also enables large model training and on-device training, offering state-of-the-art models for tasks like image synthesis and text generation.

SambaNova Systems
SambaNova Systems is an AI platform that revolutionizes AI workloads by offering an enterprise-grade full stack platform purpose-built for generative AI. It provides state-of-the-art AI and deep learning capabilities to help customers outcompete their peers. SambaNova delivers the only enterprise-grade full stack platform, from chips to models, designed for generative AI in the enterprise. The platform includes the SN40L Full Stack Platform with 1T+ parameter models, Composition of Experts, and Samba Apps. SambaNova also offers resources to accelerate AI journeys and solutions for various industries like financial services, healthcare, manufacturing, and more.
Sylph AI
Sylph AI is an AI tool designed to maximize the potential of LLM applications by providing an auto-optimization library and an AI teammate to assist users in navigating complex LLM workflows. The tool aims to streamline the process of model fine-tuning, hyperparameter optimization, and auto-data labeling for LLM projects, ultimately enhancing productivity and efficiency for users.
Future AGI
Future AGI is a revolutionary AI data management platform that aims to achieve 99% accuracy in AI applications across software and hardware. It provides a comprehensive evaluation and optimization platform for enterprises to enhance the performance of their AI models. Future AGI offers features such as creating trustworthy, accurate, and responsible AI, 10x faster processing, generating and managing diverse synthetic datasets, testing and analyzing agentic workflow configurations, assessing agent performance, enhancing LLM application performance, monitoring and protecting applications in production, and evaluating AI across different modalities.

OdiaGenAI
OdiaGenAI is a collaborative initiative focused on conducting research on Generative AI and Large Language Models (LLM) for the Odia Language. The project aims to leverage AI technology to develop Generative AI and LLM-based solutions for the overall development of Odisha and the Odia language through collaboration among Odia technologists. The initiative offers pre-trained models, codes, and datasets for non-commercial and research purposes, with a focus on building language models for Indic languages like Odia and Bengali.
deepset
deepset is an AI platform that offers enterprise-level products and solutions for AI teams. It provides deepset Cloud, a platform built with Haystack, enabling fast and accurate prototyping, building, and launching of advanced AI applications. The platform streamlines the AI application development lifecycle, offering processes, tools, and expertise to move from prototype to production efficiently. With deepset Cloud, users can optimize solution accuracy, performance, and cost, and deploy AI applications at any scale with one click. The platform also allows users to explore new models and configurations without limits, extending their team with access to world-class AI engineers for guidance and support.
3 - Open Source AI Tools
llm-export
llm-export is a tool for exporting llm models to onnx and mnn formats. It has features such as passing onnxruntime correctness tests, optimizing the original code to support dynamic shapes, reducing constant parts, optimizing onnx models using OnnxSlim for performance improvement, and exporting lora weights to onnx and mnn formats. Users can clone the project locally, clone the desired LLM project locally, and use LLMExporter to export the model. The tool supports various export options like exporting the entire model as one onnx model, exporting model segments as multiple models, exporting model vocabulary to a text file, exporting specific model layers like Embedding and lm_head, testing the model with queries, validating onnx model consistency with onnxruntime, converting onnx models to mnn models, and more. Users can specify export paths, skip optimization steps, and merge lora weights before exporting.

cake
cake is a pure Rust implementation of the llama3 LLM distributed inference based on Candle. The project aims to enable running large models on consumer hardware clusters of iOS, macOS, Linux, and Windows devices by sharding transformer blocks. It allows running inferences on models that wouldn't fit in a single device's GPU memory by batching contiguous transformer blocks on the same worker to minimize latency. The tool provides a way to optimize memory and disk space by splitting the model into smaller bundles for workers, ensuring they only have the necessary data. cake supports various OS, architectures, and accelerations, with different statuses for each configuration.
llm-deploy
LLM-Deploy focuses on the theory and practice of model/LLM reasoning and deployment, aiming to be your partner in mastering the art of LLM reasoning and deployment. Whether you are a newcomer to this field or a senior professional seeking to deepen your skills, you can find the key path to successfully deploy large language models here. The project covers reasoning and deployment theories, model and service optimization practices, and outputs from experienced engineers. It serves as a valuable resource for algorithm engineers and individuals interested in reasoning deployment.
20 - OpenAI Gpts


Back Propagation
I'm Back Propagation, here to help you understand and apply back propagation techniques to your AI models.





Apple CoreML Complete Code Expert
A detailed expert trained on all 3,018 pages of Apple CoreML, offering complete coding solutions. Saving time? https://www.buymeacoffee.com/parkerrex ☕️❤️


Modelos de Negocios GPT
Guía paso a paso para la creación y mejora de modelos de negocio usando la metodología Business Model Canvas.
LFG GPT
Talk to Navigation with Large Language Models: Semantic Guesswork as a Heuristic for Planning (LFG)