Best AI tools for< Optimize Latency >
20 - AI tool Sites
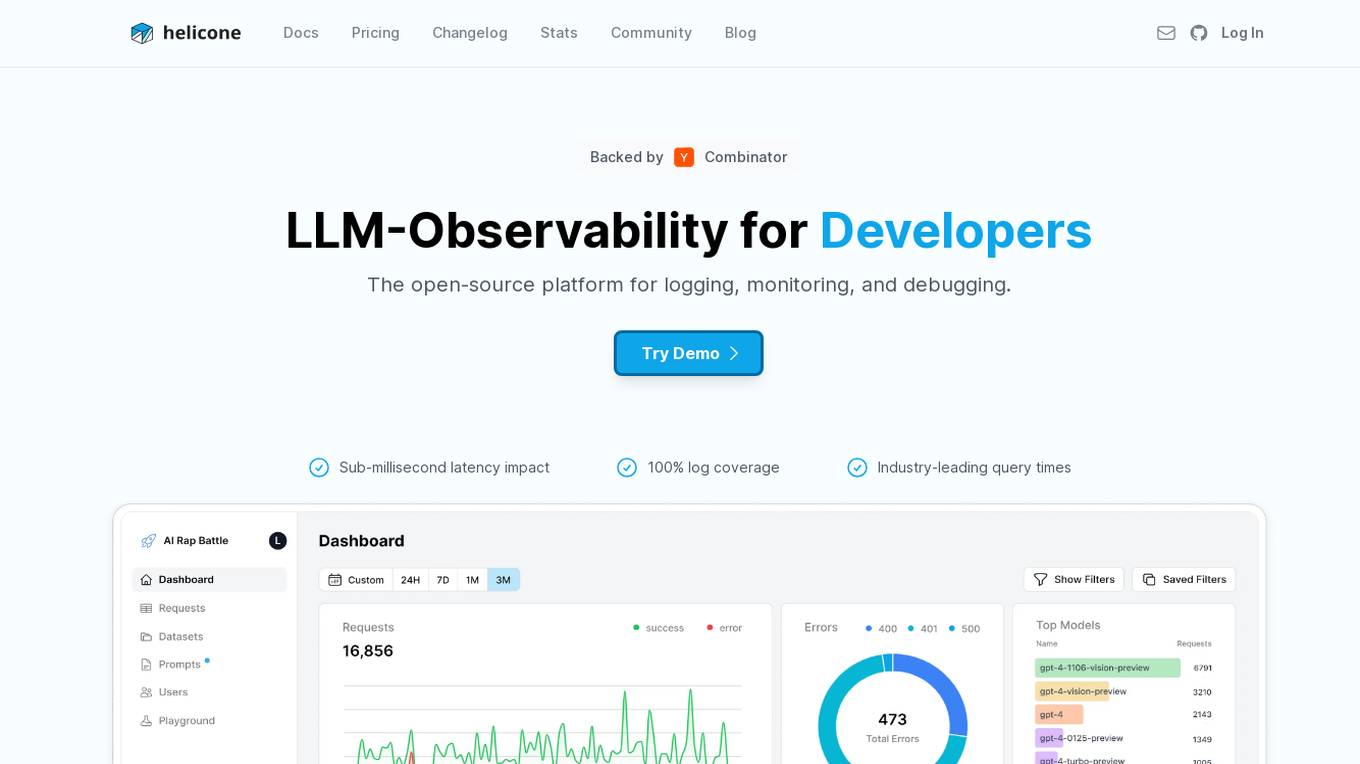
Helicone
Helicone is an open-source platform designed for developers, offering observability solutions for logging, monitoring, and debugging. It provides sub-millisecond latency impact, 100% log coverage, industry-leading query times, and is ready for production-level workloads. Trusted by thousands of companies and developers, Helicone leverages Cloudflare Workers for low latency and high reliability, offering features such as prompt management, uptime of 99.99%, scalability, and reliability. It allows risk-free experimentation, prompt security, and various tools for monitoring, analyzing, and managing requests.

LatenceTech
LatenceTech is a tech startup that specializes in network latency monitoring and analysis. The platform offers real-time monitoring, prediction, and in-depth analysis of network latency using AI software. It provides cloud-based network analytics, versatile network applications, and data science-driven network acceleration. LatenceTech focuses on customer satisfaction by providing full customer experience service and expert support. The platform helps businesses optimize network performance, minimize latency issues, and achieve faster network speed and better connectivity.
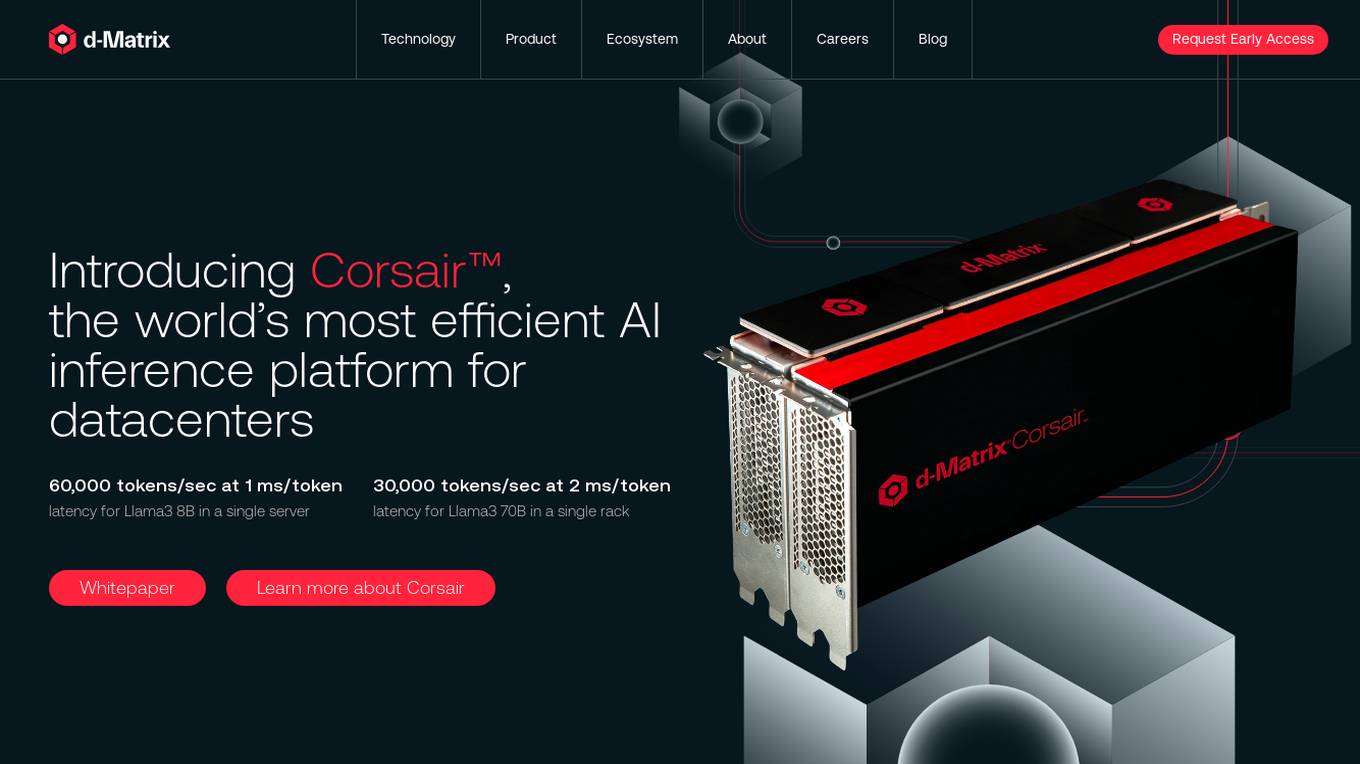
d-Matrix
d-Matrix is an AI tool that offers ultra-low latency batched inference for generative AI technology. It introduces Corsair™, the world's most efficient AI inference platform for datacenters, providing high performance, efficiency, and scalability for large-scale inference tasks. The tool aims to transform the economics of AI inference by delivering fast, sustainable, and scalable AI solutions without compromising on speed or usability.

Unify
Unify is an AI tool that offers a unified platform for accessing and comparing various Language Models (LLMs) from different providers. It allows users to combine models for faster, cheaper, and better responses, optimizing for quality, speed, and cost-efficiency. Unify simplifies the complex task of selecting the best LLM by providing transparent benchmarks, personalized routing, and performance optimization tools.
femtoAI
femtoAI is an embedded AI platform that empowers intelligence in everyday devices. It offers AI models, software, tools, and AI accelerator technology solutions to deliver high performance at lower latency and energy consumption. The platform is built upon a unique accelerator and models that fit large AI into tiny silicon chips, providing ready-to-deploy models, software development kits, and a sparse processing unit for custom applications. femtoAI brings the transformative power of AI to wearables, household appliances, robotics, and autonomous vehicles, enhancing user experiences in various domains.
MagicBid
MagicBid LLC is a web, mobile app, and CTV monetization platform that utilizes new age technology and AI-driven strategies to enhance profits for app and web publishers. The platform offers services such as app monetization, web monetization, and CTV monetization, empowering publishers with tools like Auto AdPilot, in-app bidding app monetization, growth intelligence, power ad servers, demand control center, privacy, and fraud protection. MagicBid aims to optimize ad revenue potential through a single SDK integration, connecting with 200+ top ad demand sources, ensuring impressive fill rates, zero latency, and battery drain. The platform also provides attack protection, privacy, and fraud protection services, complying with industry standards like IAB, GDPR, COPPA, and CCPA.

Groq
Groq is a fast AI inference tool that offers instant intelligence for openly-available models like Llama 3.1. It provides ultra-low-latency inference for cloud deployments and is compatible with other providers like OpenAI. Groq's speed is proven to be instant through independent benchmarks, and it powers leading openly-available AI models such as Llama, Mixtral, Gemma, and Whisper. The tool has gained recognition in the industry for its high-speed inference compute capabilities and has received significant funding to challenge established players like Nvidia.
Inworld
Inworld is an AI framework designed for games and media, offering a production-ready framework for building AI agents with client-side logic and local model inference. It provides tools optimized for real-time data ingestion, low latency, and massive scale, enabling developers to create engaging and immersive experiences for users. Inworld allows for building custom AI agent pipelines, refining agent behavior and performance, and seamlessly transitioning from prototyping to production. With support for C++, Python, and game engines, Inworld aims to future-proof AI development by integrating 3rd-party components and foundational models to avoid vendor lock-in.

Valyr
Valyr is a tool that helps you track usage, costs, and latency metrics for your GPT-3 logs with just one line of code. It's easy to get started and can be up and running in less than 3 minutes.
Eden AI
Eden AI is a platform that provides access to over 100 AI models through a unified API gateway. Users can easily integrate and manage multiple AI models from a single API, with control over cost, latency, and quality. The platform offers ready-to-use AI APIs, custom chatbot, image generation, speech to text, text to speech, OCR, prompt optimization, AI model comparison, cost monitoring, API monitoring, batch processing, caching, multi-API key management, and more. Additionally, professional services are available for custom AI projects tailored to specific business needs.
Daily
Daily is a platform offering real-time voice, video, and AI solutions for developers. It provides ultra-low latency, open-source SDKs, and enterprise reliability since 2016. Daily collaborates with NVIDIA on Voice Agent Blueprint, offers Pipecat - a vendor-neutral open-source orchestration framework, Daily Bots for Pipecat Cloud deployment, and Daily Infrastructure for running real-time calls on WebRTC global infrastructure. The platform ensures the best video quality on every network, with a global mesh network, low latency, and enterprise-grade security features.
Infermatic.ai
Infermatic.ai is a platform that provides access to top Large Language Models (LLMs) with a user-friendly interface. It offers complete privacy, robust security, and scalability for projects, research, and integrations. Users can test, choose, and scale LLMs according to their content needs or business strategies. The platform eliminates the complexities of infrastructure management, latency issues, version control problems, integration complexities, scalability concerns, and cost management issues. Infermatic.ai is designed to be secure, intuitive, and efficient for users who want to leverage LLMs for various tasks.
Beam Eye Tracker
Beam Eye Tracker is a software application that allows users to turn their webcam or phone into an eye tracker for in-game camera control. It offers more immersion in over 200 compatible PC games without the need for extra hardware. The application seamlessly integrates with Opentrack for head and eye tracking in various game genres such as flight simulators, space sims, and racing games. Beam Eye Tracker provides eye tracking performance comparable to dedicated hardware devices, powered by existing webcams capable of 60fps or higher for minimal latency. Users can enjoy a risk-free trial with a 14-day money-back guarantee for the standalone version or a 3-hour free trial on Steam, with easy setup in under 5 minutes.

noluai.com
The website page provides detailed insights into the mechanics and technologies behind poker platforms in the online gaming industry. It delves into topics such as Random Number Generators (RNGs), fair play, anti-cheat technologies, server-side logic, player matching, platform stability, multi-table functionality, mobile vs desktop platforms, in-game communication systems, real-time hand histories, hand evaluation algorithms, card shuffling algorithms, security layers, handling player disconnections, payment system integration, casino bonus integration, leaderboards, low latency importance, rebuy and add-on mechanics, automatic tournament scheduling, Sit & Go vs scheduled tournaments, virtual economy, AI opponents, player statistics, sound design, testing processes, technical issues, emerging technologies, regulatory compliance, taxes handling, game variations, card animation, and the future of poker platform mechanics.
Millis AI
Millis AI is an instant, natural, and affordable voice AI platform designed for developers to create cutting-edge voice agents with low latency. The platform offers optimized conversation flow handling, affordable accessibility, seamless integration, and scalable expertise. With rates starting at $0.06/min, Millis AI enables users to build human-like voice agents that can manage interruptions and understand human intent. The platform also provides DevOps engineers' expertise in scaling systems for enterprise-level applications.
DataVisor
DataVisor is a modern, end-to-end fraud and risk SaaS platform powered by AI and advanced machine learning for financial institutions and large organizations. It provides a comprehensive suite of capabilities to combat a variety of fraud and financial crimes in real time. DataVisor's hyper-scalable, modern architecture allows you to leverage transaction logs, user profiles, dark web and other identity signals with real-time analytics to enrich and deliver high quality detection in less than 100-300ms. The platform is optimized to scale to support the largest enterprises with ultra-low latency. DataVisor enables early detection and adaptive response to new and evolving fraud attacks combining rules, machine learning, customizable workflows, device and behavior signals in an all-in-one platform for complete protection. Leading with an Unsupervised approach, DataVisor is the only proven, production-ready solution that can proactively stop fraud attacks before they result in financial loss.
Webflow Optimize
Webflow Optimize is a website optimization and personalization tool that empowers users to create, edit, and manage web content with ease. It offers features such as A/B testing, personalized site experiences, and AI-powered optimization. With Webflow Optimize, users can enhance their digital experiences, experiment with different variations, and deliver personalized content to visitors. The platform integrates seamlessly with Webflow's visual development environment, allowing users to create and launch variations without complex code implementations.

Qualtrics XM
Qualtrics XM is a leading Experience Management Software that helps businesses optimize customer experiences, employee engagement, and market research. The platform leverages specialized AI to uncover insights from data, prioritize actions, and empower users to enhance customer and employee experience outcomes. Qualtrics XM offers solutions for Customer Experience, Employee Experience, Strategy & Research, and more, enabling organizations to drive growth and improve performance.
Jobscan
Jobscan is a comprehensive job search tool that helps job seekers optimize their resumes, cover letters, and LinkedIn profiles to increase their chances of getting interviews. It uses artificial intelligence and machine learning technology to analyze job descriptions and identify the skills and keywords that recruiters are looking for. Jobscan then provides personalized suggestions on how to tailor your application materials to each specific job you apply for. In addition to its resume and cover letter optimization tools, Jobscan also offers a job tracker, a LinkedIn optimization tool, and a career change tool. With its powerful suite of features, Jobscan is an essential tool for any job seeker who wants to land their dream job.
TestMarket
TestMarket is an AI-powered sales optimization platform for online marketplace sellers. It offers a range of services to help sellers increase their visibility, boost sales, and improve their overall performance on marketplaces such as Amazon, Etsy, and Walmart. TestMarket's services include product promotion, keyword analysis, Google Ads and SEO optimization, and advertising optimization.
2 - Open Source AI Tools
willow-inference-server
Willow Inference Server (WIS) is a highly optimized language inference server implementation focused on enabling performant, cost-effective self-hosting of state-of-the-art models for speech and language tasks. It supports ASR and TTS tasks, runs on CUDA with low-end device support, and offers various transport options like REST, WebRTC, and Web Sockets. WIS is memory optimized, leverages CTranslate2 for Whisper support, and enables custom TTS voices. The server automatically detects available CUDA VRAM and optimizes functionality accordingly. Users can programmatically select Whisper models and parameters for each request to balance speed and quality.
TileRT
TileRT is a project designed to serve large language models (LLMs) in ultra-low-latency scenarios. It aims to push the latency limits of LLMs without compromising model size or quality, enabling models with hundreds of billions of parameters to achieve millisecond-level time per output token. TileRT prioritizes responsiveness for applications like high-frequency trading, interactive AI, real-time decision-making, long-running agents, and AI-assisted coding. It introduces a tile-level runtime engine that dynamically reschedules computation, I/O, and communication across multiple devices to minimize idle time and improve hardware utilization. The project is actively evolving, with compiler techniques gradually shared with the community through TileLang and TileScale.
20 - OpenAI Gpts

CV & Resume ATS Optimize + 🔴Match-JOB🔴
Professional Resume & CV Assistant 📝 Optimize for ATS 🤖 Tailor to Job Descriptions 🎯 Compelling Content ✨ Interview Tips 💡



Website Conversion by B12
I'll help you optimize your website for more conversions, and compare your site's CRO potential to competitors’.

Thermodynamics Advisor
Advises on thermodynamics processes to optimize system efficiency.

Cloud Architecture Advisor
Guides cloud strategy and architecture to optimize business operations.

International Tax Advisor
Advises on international tax matters to optimize company's global tax position.
Investment Management Advisor
Provides strategic financial guidance for investment behavior to optimize organization's wealth.
ESG Strategy Navigator 🌱🧭
Optimize your business with sustainable practices! ESG Strategy Navigator helps integrate Environmental, Social, Governance (ESG) factors into corporate strategy, ensuring compliance, ethical impact, and value creation. 🌟
Floor Plan Optimization Assistant
Help optimize floor plan, for better experience, please visit collov.ai
AI Business Transformer
Top AI for business automation, data analytics, content creation. Optimize efficiency, gain insights, and innovate with AI Business Transformer.
Business Pricing Strategies & Plans Toolkit
A variety of business pricing tools and strategies! Optimize your price strategy and tactics with AI-driven insights. Critical pricing tools for businesses of all sizes looking to strategically navigate the market.
Purchase Order Management Advisor
Manages purchase orders to optimize procurement operations.
E-Procurement Systems Advisor
Advises on e-procurement systems to optimize purchasing processes.
Contract Administration Advisor
Advises on contract administration to optimize procurement processes.