Best AI tools for< Improve Video Quality >
20 - AI tool Sites
AVCLabs Video Enhancer AI
AVCLabs Video Enhancer AI is a powerful AI-powered video enhancement tool that can automatically improve the quality of your videos. With its advanced AI algorithms, it can remove blur, spots, noise, and other imperfections from your footage, and upscale it to 4K or even 8K resolution. It's easy to use, fully automatic, and can process videos of all types, including old home videos, films, recordings, animes, and cartoons.
UniFab
UniFab is an AI-powered video and audio enhancing solution that offers a comprehensive set of tools to elevate the quality of videos and audio tracks. With features like HDR upconversion, video upscaling, deinterlacing, audio upmixing, vocal removal, and more, UniFab empowers users to enhance their content with advanced AI algorithms. The tool is designed to improve video clarity, detail, and visual effects, providing a seamless and immersive viewing experience. UniFab is a one-stop solution for video and audio editing, offering over 1,000 format conversions and advanced AI technologies for content enhancement.
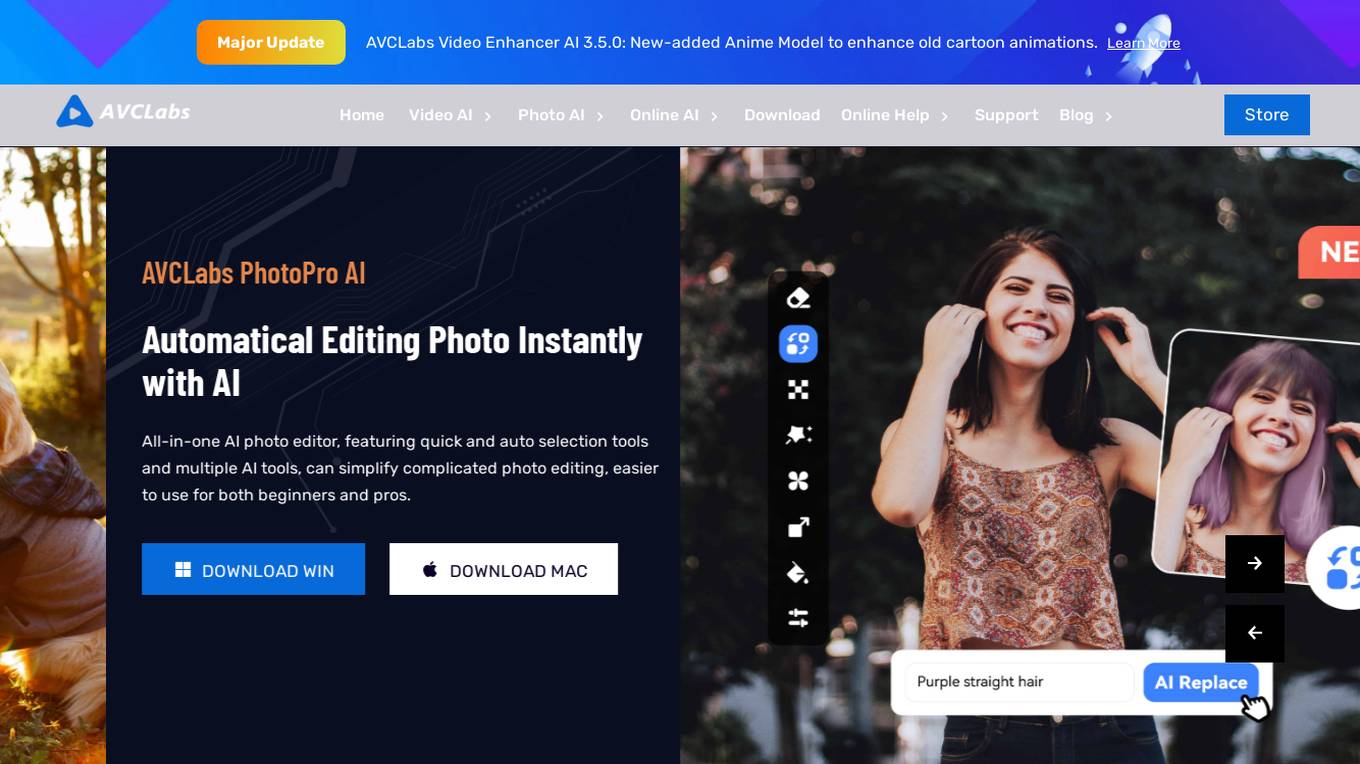
AVCLabs
AVCLabs provides a suite of AI-powered tools for enhancing videos and photos. Their flagship product, Video Enhancer AI, uses deep-learning neural networks to improve video quality, increase resolution, remove noise, restore face details, deinterlace, and more. Other products include AI Photo Editor, Photo Enhancer AI, Video Blur AI, AI Objects Remover, AI Image Upscaler, AI Face Refinement, and AI Image Colorizer. These tools are designed to make photo and video editing easier and more accessible for both beginners and professionals.
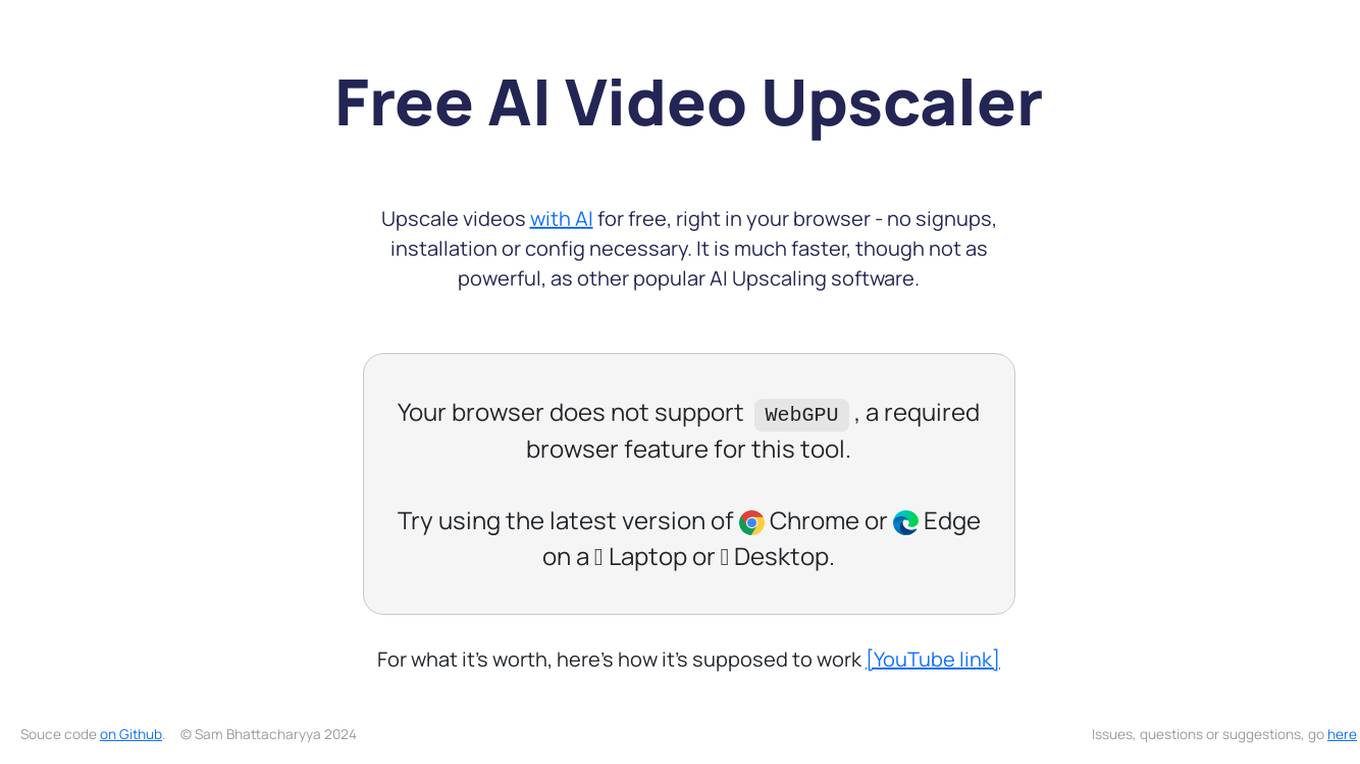
Free AI Video Upscaler
Free AI Video Upscaler is a free, open-source tool that allows users to upscale videos with AI right in their browser. It is quick, easy to use, and does not require any signups or installation. The tool is particularly well-suited for upscaling animated content.
Aimages
Aimages is an online AI video enhancer and upscaler that allows users to improve and upscale videos using AI technology directly from a web browser. The platform offers a simple and efficient way to enhance video quality in less than 3 minutes without the need for installation. Aimages is trusted by thousands of users and has been used to enhance thousands of videos and images daily, providing high-quality results with minimal artifacts.
AI Video Creations
The website offers a range of products for creating videos using AI technology. Users can find products for making realistic photographic portraits, HD presenters, and creating images and videos that sell with AI. The platform provides tools for enhancing video quality, generating realistic food photos, and adding special effects to texts. With a focus on AI-powered solutions, the website aims to assist users in creating professional and engaging visual content.
Smartrazor
Smartrazor is an AI-powered video editing tool designed for YouTubers and content creators to streamline the editing process. It automates repetitive tasks, such as clipping raw footage and enhancing video quality, allowing users to focus on creative aspects of content creation. With a user-friendly interface and compatibility with industry-standard editing software, Smartrazor aims to save time and improve editing efficiency for creators of 'talking head' style videos.
FilmBase
FilmBase is an AI-powered video editing tool that helps you remove silences and filler words from your videos with a single click. It uses AI technology to detect the unwanted parts of your video and allows you to edit them with its transcript editor. FilmBase supports exporting to multiple different video editors, including Final Cut Pro, DaVinci Resolve, and Adobe Premiere Pro.
X-Design
X-Design is an AI-powered photo editing studio tailored for marketing and e-commerce businesses. It offers a suite of AI tools for background removal, image generation, and retouching to create professional-quality photos effortlessly. Users can enhance product visuals, create fashion model images, change colors, and upscale images with AI technology. The platform provides a smooth editing experience with extensive templates and seamless workflows, empowering users to design like a pro and optimize their online sales processes.
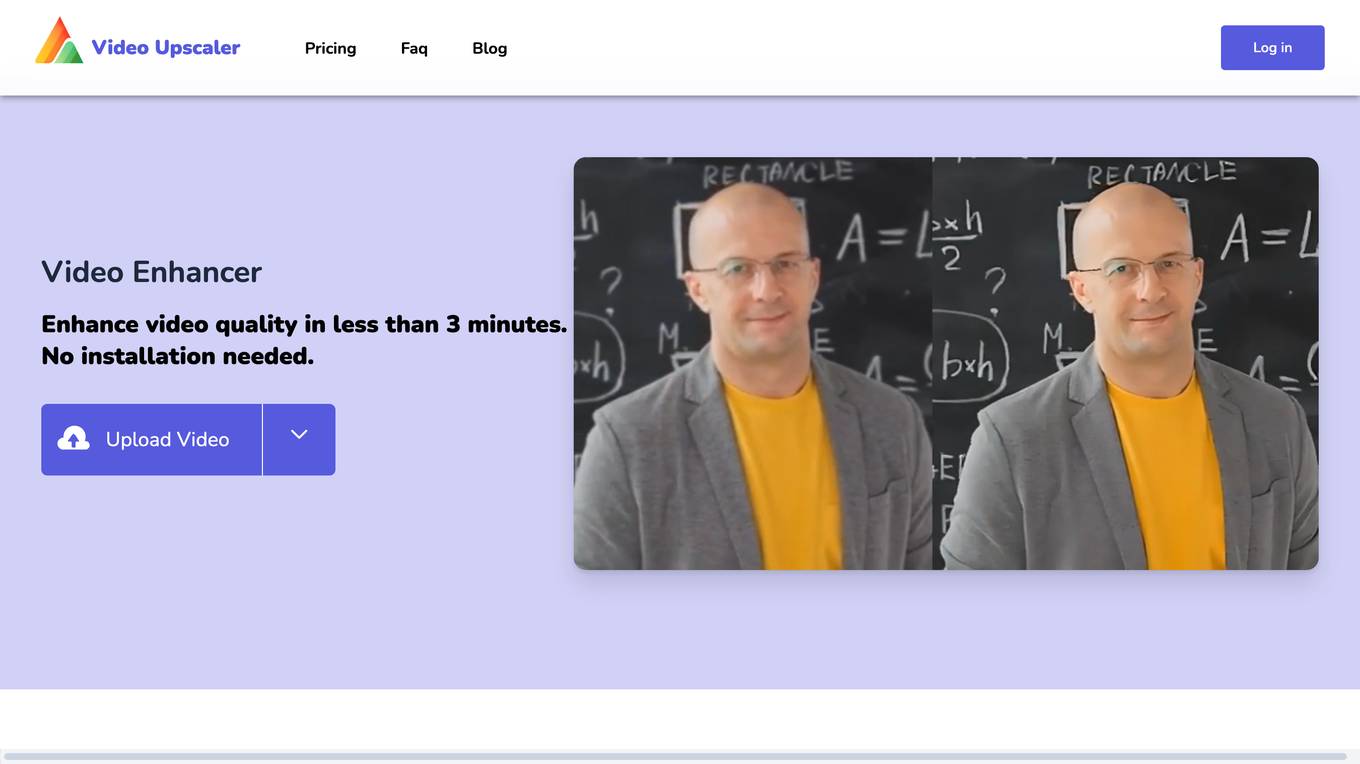
Video Upscaler
Video Upscaler is an online video enhancement platform that utilizes advanced AI algorithms to automatically enhance the quality of videos in just seconds. It offers a simple and effective solution for users to upscale their videos to 4K resolution without any loss of detail or quality. The platform is user-friendly, affordable, and constantly updating its models to provide the highest quality results across various categories.
Pixop
Pixop is a cloud-based AI- and ML-powered video enhancer that is designed to help production companies, TV stations, rightsholders and independent creators monetize their digital archives by enhancing and upscaling footage to fit today's screens. Pixop's automated AI and ML filters make easy work of remastering your digital masters from SD all the way to UHD 8K. No expensive hardware or complicated setups involved.

Pixop
Pixop is a cloud-based AI- and ML-powered video enhancer that is designed to help production companies, TV stations, rightsholders and independent creators monetize their digital archives by enhancing and upscaling footage to fit today's screens. It offers a range of features such as video asset management, storage, video quality analysis, transcoding and tools for easy collaboration between colleagues and clients.
Ray3 AI
Ray3 AI is an AI video generator tool that allows users to create high-quality videos effortlessly. With features like text-to-image conversion, image editing, and aspect ratio adjustment, Ray3 AI simplifies the video creation process. Users can generate videos in various formats, including 16:9 and 9:16, with auto credits costing 10 per creation. The tool is powered by Tencent Hunyuan LIVE 5.0 and offers a seamless user experience for both beginners and experienced video creators.
Video Silence Remover
Video Silence Remover is a free AI-powered video editing tool that helps users trim silent and quiet parts of their videos quickly and efficiently. The tool operates on the cloud, allowing users to go from a raw video to a first cut edit in minutes. It supports MP4 and other video files, enabling users to create AI-edited and captioned shorts and reels from full-form videos. Video Silence Remover is ideal for content creators, video editors, social media managers, course creators, and anyone looking to enhance video quality with minimal time investment.
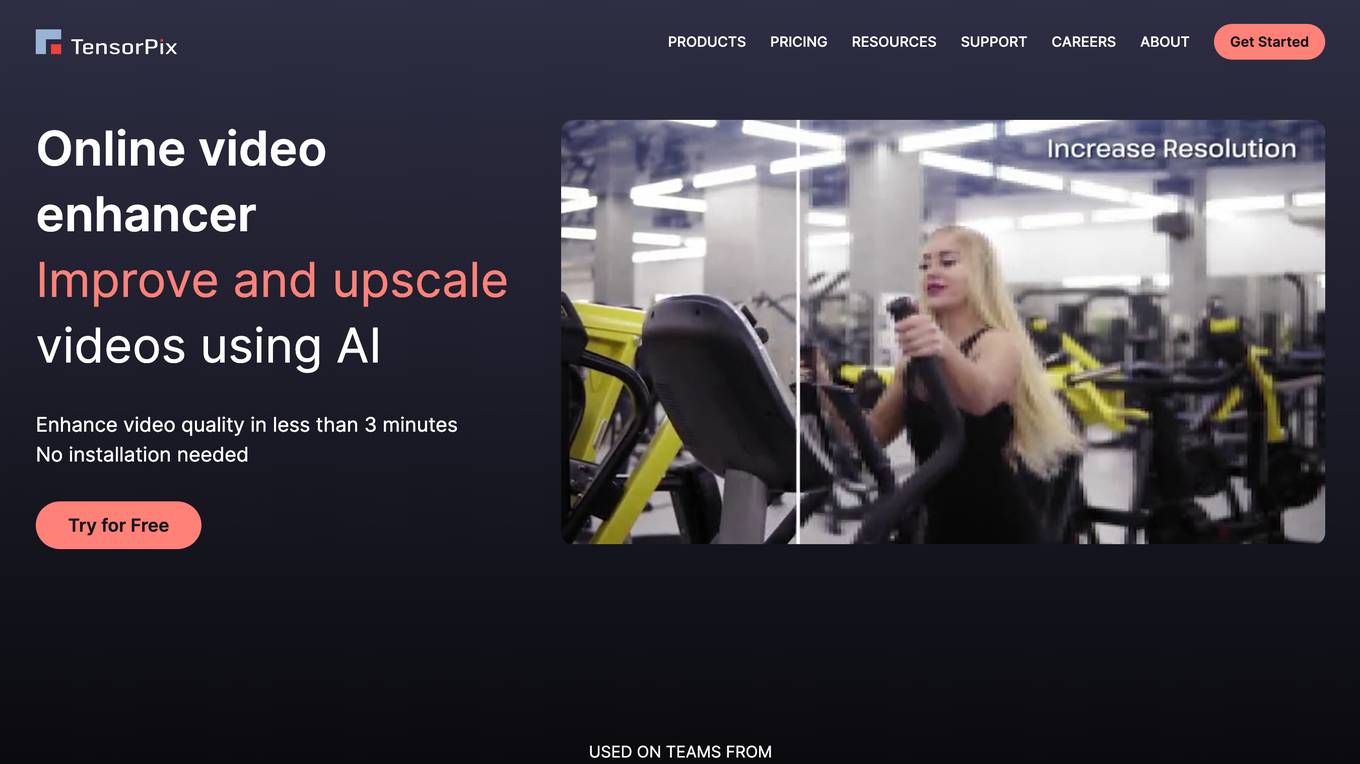
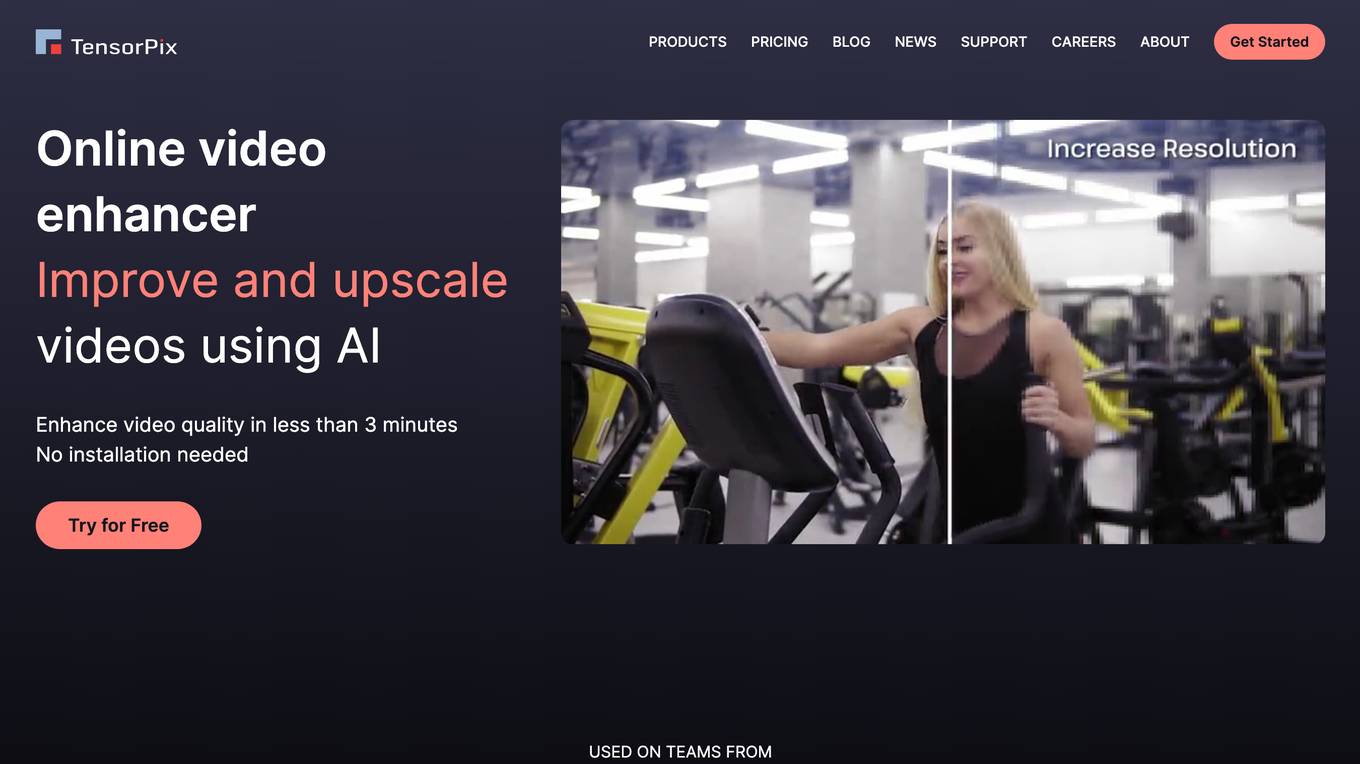
TensorPix
TensorPix is an online AI-powered video enhancer and upscaler that can improve and upscale videos in less than 3 minutes. It is a cloud-based service that can be used to enhance videos from any device, including smartphones and tablets. TensorPix uses AI to enhance video quality, including resolution, framerate, and color correction. It can also remove flickering, film dirt, and interlacing artifacts from old videos. TensorPix is used by thousands of users, including filmmakers, studios, and businesses. It is a powerful tool that can help you improve the quality of your videos and images.
Hedra AI
Hedra AI is an advanced tool that allows users to generate realistic videos with perfect lip sync by combining facial images and audio. It offers features like multilingual lip-sync, controllable eye blinking, dynamic video driving, unparalleled performance, and easy video creation steps. The application is highly praised for its accuracy in lip-sync and realistic video quality, making it a preferred choice for professionals in multimedia production, gaming, and virtual reality.
Bidinfluence
Bidinfluence is a cutting-edge SSP that helps publishers maximize ad revenue through programmatic technology. Their robust platform automates monetization, offering real-time data and full-featured SSP. With a team of passionate adtech professionals, their mission is to improve monetization opportunities for independent publishers. Bidinfluence's AI and machine learning solution empowers publishers to unlock additional revenue potential, delivering ads across screens, formats, and verticals.
AutoCut
AutoCut is a Premiere Pro plugin that leverages AI technology to automate manual editing tasks and save hours for video editors. With features like automatic silence removal, animated captions creation, podcast editing, and more, AutoCut streamlines the video editing process and enhances the overall quality of video content. Trusted by over 10,000 paid users, AutoCut revolutionizes the way videos are edited by offering a wide range of AI-powered tools that simplify complex editing tasks and improve efficiency.
Subscribr
Subscribr is an AI tool designed exclusively for YouTube scriptwriting, aiming to revolutionize the script creation process by providing fast ideation, high-quality research, scriptwriting on easy mode, instant feedback, and the ability to remix proven viral videos. Founded by Gil Hildebrand, Subscribr addresses the common challenges faced by content creators on YouTube, offering a solution that streamlines the scriptwriting workflow and enhances the overall quality of video content.
Dream Machine AI
Dream Machine AI by Luma Labs is an advanced artificial intelligence model designed to generate high-quality, realistic videos quickly from text and images. This highly scalable and efficient transformer model is trained directly on videos, enabling it to produce physically accurate, consistent, and eventful shots. The AI can generate 5-second video clips with smooth motion, cinematic quality, and dramatic elements, transforming static snapshots into dynamic stories. It understands interactions between people, animals, and objects, allowing for videos with great character consistency and accurate physics. Dream Machine AI supports a wide range of fluid, cinematic, and naturalistic camera motions that match the emotion and content of the scene.
2 - Open Source AI Tools
Upscaler
Holloway's Upscaler is a consolidation of various compiled open-source AI image/video upscaling products for a CLI-friendly image and video upscaling program. It provides low-cost AI upscaling software that can run locally on a laptop, programmable for albums and videos, reliable for large video files, and works without GUI overheads. The repository supports hardware testing on various systems and provides important notes on GPU compatibility, video types, and image decoding bugs. Dependencies include ffmpeg and ffprobe for video processing. The user manual covers installation, setup pathing, calling for help, upscaling images and videos, and contributing back to the project. Benchmarks are provided for performance evaluation on different hardware setups.

ComfyUI-TopazVideoAI
ComfyUI-TopazVideoAI is a tool designed to facilitate the usage of TopazVideoAI for creating short AI-generated videos. Users can connect this node between video output and video save to enhance the quality of videos. The tool requires a licensed installation of TopazVideoAI and provides instructions for setting up environment variables and paths. It is recommended to use upscale factors of 2 or 4 to avoid errors. The tool encodes and decodes videos as image batches, which may result in longer processing times compared to the TopazVideoAI GUI. Common errors include 'No such filter: 'tvai_up'' which can be resolved by ensuring the correct ffmpeg path and removing conflicting ffmpeg installations.
20 - OpenAI Gpts
Video Generator
This GPTs engages with users through friendly and professional dialogue to create higher quality video covers. https://www.aisora.org By Mr Sora
Video Editing Tutor
Offers step-by-step video editing lessons, from basic cuts to advanced effects, tailored to various software platforms.
Subtitle Proofreader
For Proofreading the Auto-Generated YouTube subtitles. To prepare for translation.


Stock Footage Metadata
Expert in video titles and keywords, with strict adherence to best practices.


The Video Content Creator Coach
A content creator coach aiding in YouTube video content creation, analysis, script writing and storytelling. Designed by a successful YouTuber to help other YouTubers grow their channels.

CreceTube Experto
Asistente multilingüe para la creación de contenido de video, con apoyo y consejos creativos en múltiples idiomas.