Best AI tools for< Improve Benchmark >
20 - AI tool Sites
Spotrank.ai
Spotrank.ai is an AI-powered platform that provides advanced analytics and insights for businesses and individuals. It leverages artificial intelligence algorithms to analyze data and generate valuable reports to help users make informed decisions. The platform offers a user-friendly interface and customizable features to cater to diverse needs across various industries. Spotrank.ai is designed to streamline data analysis processes and enhance decision-making capabilities through cutting-edge AI technology.
PR Daily
PR Daily is an AI-powered platform that empowers PR professionals with the latest news, insights, and networking opportunities. It provides a comprehensive resource for industry trends, best practices, and expert advice to enhance communication strategies and campaigns. The platform utilizes artificial intelligence to deliver personalized content, analyze data, and optimize media relations workflows. PR Daily aims to streamline PR processes, improve brand reputation, and drive engagement through innovative AI technologies.
Yoodli
Yoodli is a free communication coach that provides private, real-time, and judgment-free coaching to help users improve their communication skills. It works like Grammarly but for speech, giving users in-the-moment nudges to help them sound confident during calls. Yoodli also tracks users' progress over time, showing them how they are doing relative to recommended benchmarks.
Flowtrace
Flowtrace is an AI-powered Company Analytics Productivity tool that focuses on improving meeting culture, collaboration, and engagement within organizations. It analyzes meeting data to provide actionable recommendations for enhancing team performance and productivity. With features like industry benchmarks, integration with common SaaS tools, and personalized insights, Flowtrace aims to help teams work more efficiently and effectively. The tool helps in reducing meeting costs, increasing productivity, removing distractions, and transforming meeting culture for better decision-making and outcomes.
SeeMe Index
SeeMe Index is an AI tool for inclusive marketing decisions. It helps brands and consumers by measuring brands' consumer-facing inclusivity efforts across public advertisements, product lineup, and DEI commitments. The tool utilizes responsible AI to score brands, develop industry benchmarks, and provide consulting to improve inclusivity. SeeMe Index awards the highest-scoring brands with an 'Inclusive Certification', offering consumers an unbiased way to identify inclusive brands.
Peec AI
Peec AI is an AI search analytics tool designed for marketing teams to track, analyze, and improve brand performance on AI search platforms. It provides key metrics such as Visibility, Position, and Sentiment to help businesses understand how AI perceives their brand. The platform offers insights on AI visibility, prompts analysis, and competitor tracking to enhance marketing strategies in the era of AI and generative search.
mySQM™ QA
SQM Group's mySQM™ QA software is a comprehensive solution for call centers to monitor, motivate, and manage agents, ultimately improving customer experience (CX) and reducing QA costs by 50%. It combines three data sources: post-call surveys, call handling data, and call compliance feedback, providing holistic CX insights. The software offers personalized agent self-coaching suggestions, real-time recognition for great CX delivery, and benchmarks, ranks, awards, and certifies Csat, FCR, and QA performance.
ARC Prize
ARC Prize is a platform hosting a $1,000,000+ public competition aimed at beating and open-sourcing a solution to the ARC-AGI benchmark. The platform is dedicated to advancing open artificial general intelligence (AGI) for the public benefit. It provides a formal benchmark, ARC-AGI, created by François Chollet, to measure progress towards AGI by testing the ability to efficiently acquire new skills and solve open-ended problems. ARC Prize encourages participants to try solving test puzzles to identify patterns and improve their AGI skills.
Am I On AI
Am I On AI is a platform designed to help businesses improve their visibility in AI responses, specifically focusing on ChatGPT. It provides personalized action plans to enhance brand visibility, track mentions, identify source websites, benchmark against competitors, and execute strategic improvements. The platform offers features such as AI brand monitoring, competitor rank analysis, sentiment analysis, citation tracking, and actionable insights. With a user-friendly interface and measurable results, Am I On AI is a valuable tool for marketers, SEO professionals, and agencies looking to optimize their AI visibility.

Frequently.ai
Frequently.ai is an AI-powered tool designed to provide valuable insights and analytics based on customer feedback and reviews. It helps businesses analyze and understand customer sentiments, trends, and preferences to improve their products and services. The tool utilizes advanced natural language processing and machine learning algorithms to extract meaningful data from various sources, such as online reviews and social media comments. With its user-friendly interface and customizable features, Frequently.ai offers a comprehensive solution for businesses looking to enhance their customer experience and make data-driven decisions.
Deepfake Detection Challenge Dataset
The Deepfake Detection Challenge Dataset is a project initiated by Facebook AI to accelerate the development of new ways to detect deepfake videos. The dataset consists of over 100,000 videos and was created in collaboration with industry leaders and academic experts. It includes two versions: a preview dataset with 5k videos and a full dataset with 124k videos, each featuring facial modification algorithms. The dataset was used in a Kaggle competition to create better models for detecting manipulated media. The top-performing models achieved high accuracy on the public dataset but faced challenges when tested against the black box dataset, highlighting the importance of generalization in deepfake detection. The project aims to encourage the research community to continue advancing in detecting harmful manipulated media.
Glia
Glia is a digital customer service technology platform designed for financial services and beyond. It offers solutions to drive more sales online, increase customer loyalty, modernize support, and identify improvement areas through advanced benchmarks. With a focus on digital-centric and phone-centric customer support, Glia provides services such as video banking, personalized expert service, and AI management. The platform also emphasizes security, offering new apps, features, and ways to engage customers. Glia aims to revolutionize customer communication in industries like banking, credit unions, fintech, insurance, and lending.
Abeille.ai
Abeille.ai is a leading B2B Sales Coaching Platform that offers a Human+AI Growth & Coaching Framework. It provides a global network of experts for 1-to-1 coaching in sales and procurement, specialized AI sales coaches, and a peer community of sales professionals. The platform offers always-on 24/7 sales coaching, interactive best practice frameworks, team-level and industry-level benchmarking, and access to expert consultants with vast experience across regions, industries, and cultures. Abeille.ai aims to help businesses sell smarter and better by leveraging AI technology and expert coaching.
WorkViz
WorkViz is an AI-powered performance tool designed for remote teams to visualize productivity, maximize performance, and foresee the team's potential. It offers features such as automated daily reports, employee voice expression through emojis, workload management alerts, productivity solutions, and intelligent summaries. WorkViz ensures data security through guaranteed audit, desensitization, and SSL security protocols. The application has received positive feedback from clients for driving improvements, providing KPIs and benchmarks, and simplifying daily reporting. It helps users track work hours, identify roadblocks, and improve team performance.
Lunary
Lunary is an AI developer platform designed to bring AI applications to production. It offers a comprehensive set of tools to manage, improve, and protect LLM apps. With features like Logs, Metrics, Prompts, Evaluations, and Threads, Lunary empowers users to monitor and optimize their AI agents effectively. The platform supports tasks such as tracing errors, labeling data for fine-tuning, optimizing costs, running benchmarks, and testing open-source models. Lunary also facilitates collaboration with non-technical teammates through features like A/B testing, versioning, and clean source-code management.
Proxima
Proxima is a predictive data intelligence tool that offers custom audiences for paid social, analytics, and tactical benchmarks. It helps businesses lower acquisition costs, increase customer lifetime value, and grow profitably by leveraging AI-powered advertising solutions. With a focus on predictive insights and enterprise-grade analytics, Proxima empowers users to make data-driven decisions that fuel growth and optimize marketing performance.
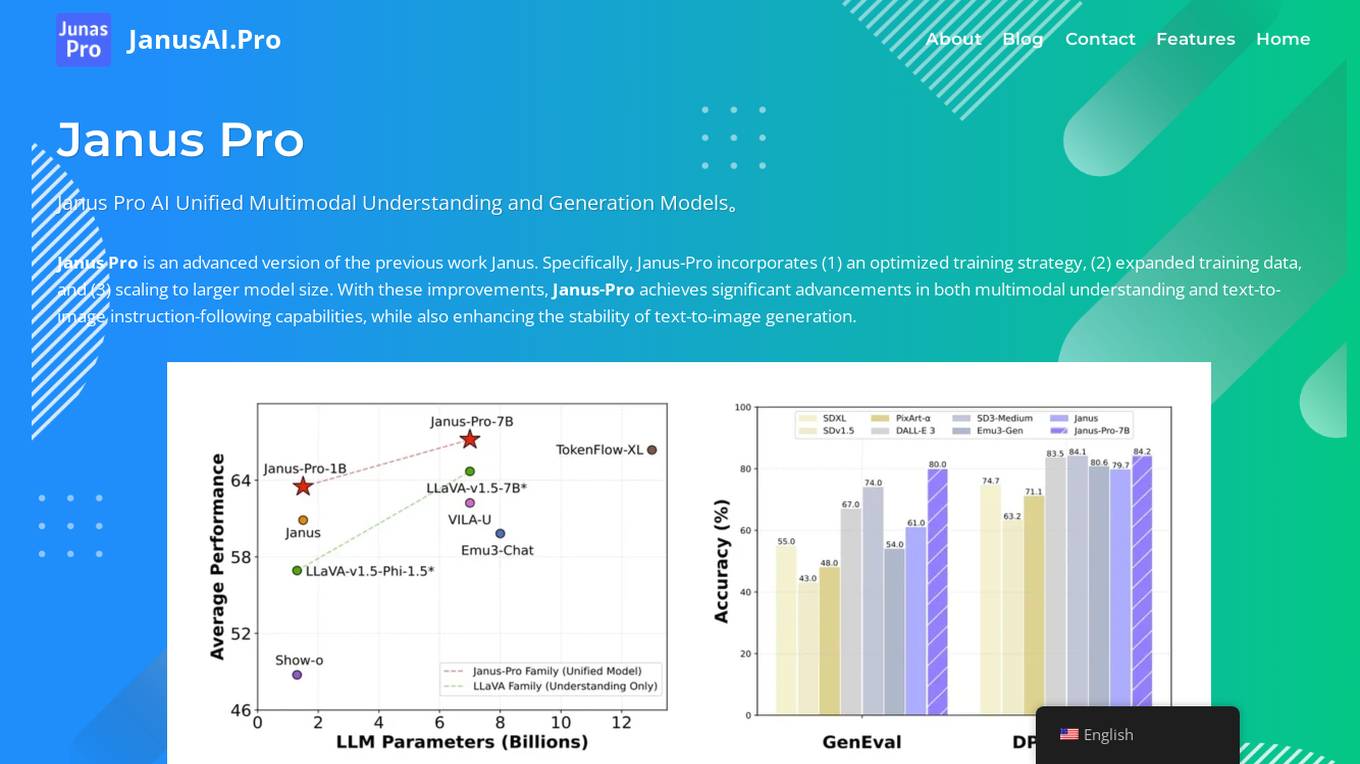
Janus Pro AI
Janus Pro AI is an advanced unified multimodal AI model that combines image understanding and generation capabilities. It incorporates optimized training strategies, expanded training data, and larger model scaling to achieve significant advancements in both multimodal understanding and text-to-image generation tasks. Janus Pro features a decoupled visual encoding system, outperforming leading models like DALL-E 3 and Stable Diffusion in benchmark tests. It offers open-source compatibility, vision processing specifications, cost-effective scalability, and an optimized training framework.
Optimove
Optimove is a Customer-Led Marketing Platform that leverages a real-time Customer Data Platform (CDP) to orchestrate personalized multichannel campaigns optimized by AI. It enables businesses to deliver personalized experiences in real-time across various channels such as web, app, and marketing channels. With a focus on customer-led marketing, Optimove helps brands improve customer KPIs through data-driven campaigns and top-tier personalization. The platform offers a range of resources, including industry benchmarks, marketing guides, success stories, and best practices, to help users achieve marketing mastery.
Flick
Flick is an AI-powered social media marketing platform that offers a comprehensive suite of tools to help users plan, schedule, analyze, and optimize their social media content. With features like AI strategy and planning, hashtag tools, post scheduler, and analytics, Flick simplifies the social media process for business owners, marketers, and creators. The platform also provides resources such as training, templates, and industry benchmarks to help users enhance their social media presence. Flick is designed to save time, improve results, and empower users to succeed in the competitive world of social media marketing.
CostGPT
CostGPT is an AI application designed to simplify software project planning by providing comprehensive roadmaps that include detailed estimates like costs, features, sitemaps, and milestones. It offers a straightforward pricing model with no subscription fees and provides a basic foundation for project planning with the free plan. The application is trained on data from over 2000 projects using historical project data, industry benchmarks, and advanced machine learning algorithms to continuously improve accuracy and relevance over time.
1 - Open Source AI Tools

babilong
BABILong is a generative benchmark designed to evaluate the performance of NLP models in processing long documents with distributed facts. It consists of 20 tasks that simulate interactions between characters and objects in various locations, requiring models to distinguish important information from irrelevant details. The tasks vary in complexity and reasoning aspects, with test samples potentially containing millions of tokens. The benchmark aims to challenge and assess the capabilities of Large Language Models (LLMs) in handling complex, long-context information.
20 - OpenAI Gpts


UX & UI
Gives you tips and suggestions on how you can improve your application for your users.


Memory Enhancer
Offers exercises and techniques to improve memory retention and cognitive functions.
English Conversation Role Play Creator
Generates conversation examples and chunks for specified situations. Improve your instantaneous conversational skills through repetitive practice!
Customer Retention Consultant
Analyzes customer churn and provides strategies to improve loyalty and retention.

Agile Coach Expert
Agile expert providing practical, step-by-step advice with the agile way of working of your team and organisation. Whether you're looking to improve your Agile skills or find solutions to specific problems. Including Scrum, Kanban and SAFe knowledge.
Kemi - Research & Creative Assistant
I improve marketing effectiveness by designing stunning research-led assets in a flash!
Quickest Feedback for Language Learner
Helps improve language skills through interactive scenarios and feedback.
Le VPN - Your Secure Internet Proxy
Bypass Internet censorship & improve your security online

実践スキルが身につく営業ロールプレイング:【エキスパートクラス】
実践スキル向上のための対話型学習アシスタント (Interactive learning assistant to improve practical skills)
Your personal GRC & Security Tutor
A training tool for infosec professionals to improve their skills in GRC & security and help obtain related certifications.
Anna, the Ethical Essay Guide
Guides in structuring essays to improve writing skills, adapting to skill levels.