Best AI tools for< Generate Speech From Text >
20 - AI tool Sites
Synthesis
Synthesis is a web-based application that allows users to create realistic-sounding synthetic speech from text. The application uses a variety of AI techniques, including natural language processing and machine learning, to generate speech that is both natural-sounding and easy to understand. Synthesis can be used for a variety of purposes, including creating voiceovers for videos, podcasts, and presentations.
Free Text to Speech Online Converter Tools
This website provides a free text-to-speech converter tool that utilizes Microsoft's AI speech library to synthesize realistic-sounding speech from text. It offers customizable voice options, fine-tuned speech controls, and multilingual support with over 330 neural network voices across 129 languages. The tool is accessible on various browsers, including Chrome, Firefox, and Edge, and can be used for a range of applications, such as text readers and voice-enabled assistants.
Speechelo
Speechelo is a text-to-speech software that allows users to instantly generate human-sounding voiceovers from text. It offers a wide range of features, including over 30 human-sounding voices, the ability to add breathing sounds and pauses, and the ability to generate voiceovers in over 23 languages. Speechelo is easy to use and can be integrated with any video creation software. It is a great tool for creating voiceovers for sales videos, training videos, educational videos, and more.
ChatTTS
ChatTTS is an open-source text-to-speech model designed for dialogue scenarios, supporting both English and Chinese speech generation. Trained on approximately 100,000 hours of Chinese and English data, it delivers speech quality comparable to human dialogue. The tool is particularly suitable for tasks involving large language model assistants and creating dialogue-based audio and video introductions. It provides developers with a powerful and easy-to-use tool based on open-source natural language processing and speech synthesis technologies.
AI Voice Studio
AI Voice Studio is an innovative online tool that allows users to convert text into lifelike speech using advanced AI technology. With AI Voice Studio, users can easily create high-quality voiceovers for various purposes such as videos, podcasts, and presentations. The tool offers a user-friendly interface and a wide range of customization options to tailor the voice output to specific needs. Whether you are a content creator, marketer, or educator, AI Voice Studio provides a convenient and efficient solution for generating natural-sounding voice content.
TTS Generator AI
TTS Generator AI is a free online text-to-speech tool that leverages cutting-edge AI technology to convert written text into high-quality, natural-sounding audio. This tool is invaluable for a variety of users, including students who need auditory learning materials, researchers who want to listen to long documents, and professionals seeking to make their written content more accessible. One of the standout features of TTS Tool is its ability to support a range of text formats, from simple text files to complex PDFs, making it incredibly versatile.
Podcastle
Podcastle is an all-in-one podcasting software that empowers creators of all backgrounds and experience levels with an intuitive, AI-powered platform. It offers a wide range of features, including a recording studio, audio editor, video editor, AI-generated voices, and hosting hub, making it easy to create, edit, and publish high-quality podcasts and videos. Podcastle is designed to be user-friendly and accessible, with no prior experience or technical expertise required.
ChatTTS
ChatTTS is a natural and expressive text-to-speech tool designed for dialogue applications. It supports mixed language input and offers multi-speaker capabilities with precise control over prosodic elements like laughter, pauses, and intonation. Users can explore the unique capabilities of ChatTTS, enjoy conversational TTS optimized for dialogue-based tasks, and benefit from fine-grained control over prosodic features. The tool is multilingual, supporting both English and Chinese languages, and is open-source and customizable with pretrained models available for further research and development.
SORA AI Video Generator
SORA AI Video Generator is a powerful online tool that allows you to create stunning videos from text. With SORA AI, you can easily convert your written content into engaging and informative videos, perfect for marketing, education, and more. SORA AI's advanced artificial intelligence technology analyzes your text and automatically generates a video that is tailored to your specific needs. You can customize your videos with a variety of features, including text-to-speech narration, background music, and images. SORA AI also offers a wide range of templates to help you get started quickly and easily.
AssemblyAI
AssemblyAI is an AI tool that provides AI models for transcribing and understanding speech. It offers real-time transcription, speech-to-text, speech understanding, and speech-to-speech capabilities. The platform caters to various use cases such as conversation intelligence, medical transcription, contact centers, and voice agents. AssemblyAI is trusted by top VoiceAI companies for its accurate and fully-featured models, enabling users to build innovative products and experiences with confidence.
ElevateAI by NICE
ElevateAI by NICE is a market-leading AI-powered speech-to-text application that offers transcription models, Generative AI, Enlighten AI, and CX AI features. It provides insights by pairing free Generative AI with NICE's transcription models to uncover hidden insights in data. ElevateAI aims to make AI-powered technology accessible for all, with easy integration, deployment, and user-friendly APIs. The application is designed to help contact centers leverage the power of AI for enhanced customer experiences and innovation.
MyVocal.ai
MyVocal.ai is a text-to-speech and voice cloning tool that allows users to create realistic-sounding voices from text. With MyVocal.ai, you can clone your own voice or choose from a variety of pre-recorded voices. You can then use these voices to create songs, audiobooks, podcasts, and other audio content. MyVocal.ai also offers a variety of features to help you customize your voice, including the ability to change the pitch, speed, and volume. Additionally, MyVocal.ai offers a variety of features to help you create high-quality audio content, including the ability to add background music and sound effects.
Yestool.ai
Yestool.ai is an all-in-one AI platform that offers a range of AI tools to create professional videos effortlessly. Users can input scripts, stories, or content descriptions into the AI-powered editor, which then processes the content to generate high-quality videos with visuals, voiceover, and music. The platform allows instant download and sharing of the created videos in HD quality, suitable for any platform. Yestool.ai also provides tools for upscaling videos, converting speech to video, generating music from text or lyrics, and creating images from text or existing images. With a focus on simplicity and efficiency, Yestool.ai aims to empower users to enhance their video creation process using advanced AI technology.
Covers AI
Covers AI is a website that provides AI-powered tools for generating voiceovers and songs. With Covers AI, you can create realistic voiceovers and songs from text using advanced AI algorithms. The website is easy to use and offers a variety of features to help you create high-quality audio content.
VoiceGen
VoiceGen is an AI audio platform that enables users to create realistic speech using the best technology from leading providers like OpenAI, Google, AWS, and Azure. It offers natural, high-quality voices with support for multiple languages and unrestricted commercial use. VoiceGen prioritizes simplicity, transparency, and innovation, providing an accessible and affordable solution for voice generation needs. The platform ensures security and privacy of user data, offering a pay-as-you-go pricing model with fair and transparent costs.
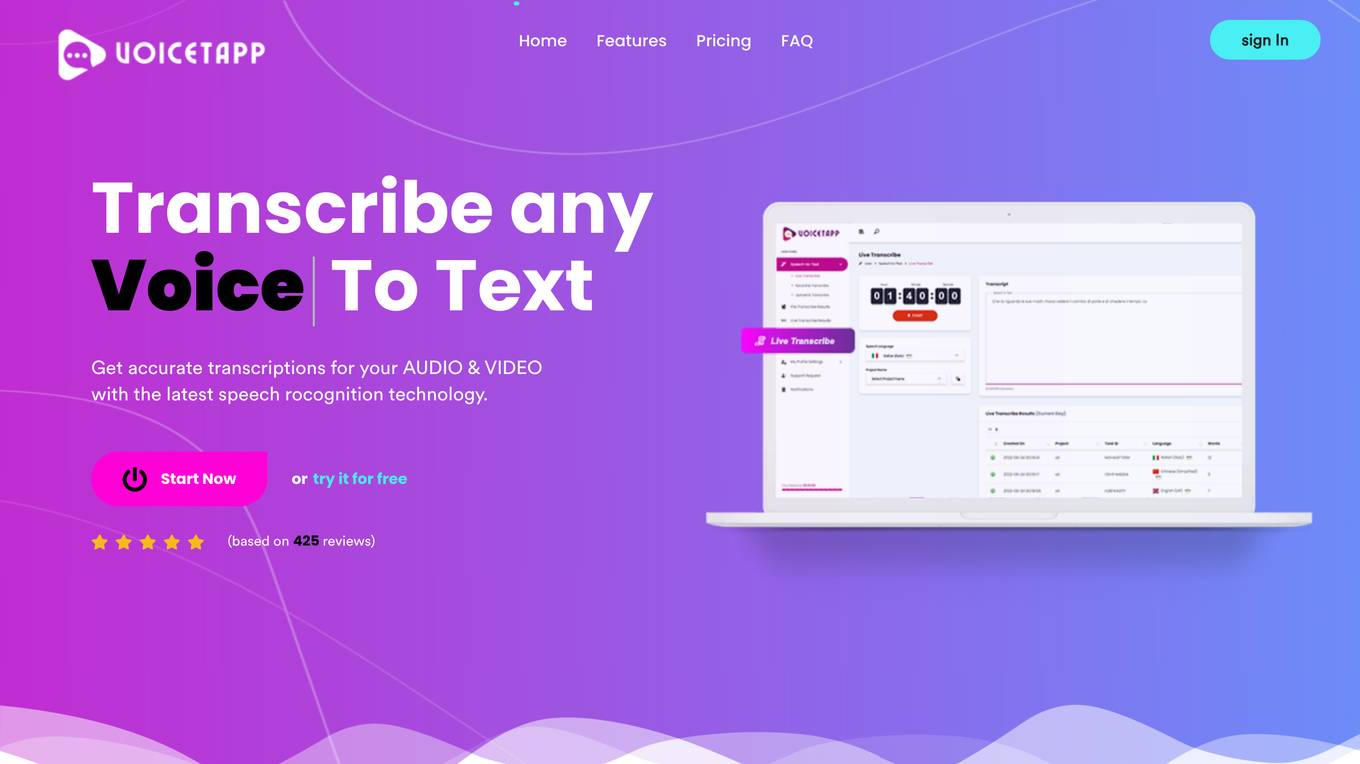
Voicetapp
Voicetapp is a powerful cloud-based artificial intelligence software that helps you automatically convert audio to text with up to 100% accuracy. It supports over 170 languages and dialects, allowing you to quickly and accurately transcribe speech from audio and video files. Voicetapp also offers features such as speaker identification, live transcription, and multiple input formats, making it a versatile tool for various use cases.
BlendAI
BlendAI is a platform that centralizes top AI models in one place, offering a pay-as-you-go model without the need for a monthly subscription. Its multi-modal graph interface allows easy chaining of models where you can do text to text to image to video to anything.
Ai-Wordsmith
Ai-Wordsmith is a powerful AI tool that serves as an AI-Writer & Assistant, offering a wide range of features to help users generate AI content effortlessly. From text generation to image creation, code generation, chatbot assistance, speech-to-text conversion, brainstorming, and more, Ai-Wordsmith is designed to streamline various tasks and enhance productivity. Trusted by over 1000 companies worldwide, Ai-Wordsmith provides a user-friendly interface and robust functionalities to cater to the needs of digital agencies, product designers, entrepreneurs, copywriters, digital marketers, and developers.
Audyo
Audyo is a text-to-speech tool that allows users to create realistic-sounding audio from text. With over 100 voices to choose from, users can create audio in a variety of languages and accents. Audyo is easy to use, simply type in your text and select a voice. You can then download your audio file or embed it on your website or blog. Audyo is a great tool for creating voiceovers for videos, podcasts, audiobooks, and more.
Lip Sync AI
Lip Sync AI is a cutting-edge online AI tool that transforms audio into synchronized video content. It offers advanced capabilities to create lifelike talking avatars from text descriptions, videos, and images. With features like precise mouth animation, multi-language support, emotion preservation, and high-definition output, Lip Sync AI revolutionizes the way presentations, marketing materials, and educational content are produced. The platform is user-friendly, allowing users to easily upload their audio and visual assets to generate professional-quality videos with perfectly synchronized lip movements.
2 - Open Source AI Tools
whispering-ui
Whispering Tiger UI is a Native-UI tool designed to control the Whispering Tiger application, a free and Open-Source tool that can listen/watch to audio streams or in-game images on your machine and provide transcription or translation to a web browser using Websockets or over OSC. It features a Native-UI for Windows, easy access to all Whispering Tiger features including transcription, translation, text-to-speech, and in-game image recognition. The tool supports loopback audio device, configuration saving/loading, plugin support for additional features, and auto-update functionality. Users can create profiles, configure audio devices, select A.I. devices for speech-to-text, and install/manage plugins for extended functionality.

LLMVoX
LLMVoX is a lightweight 30M-parameter, LLM-agnostic, autoregressive streaming Text-to-Speech (TTS) system designed to convert text outputs from Large Language Models into high-fidelity streaming speech with low latency. It achieves significantly lower Word Error Rate compared to speech-enabled LLMs while operating at comparable latency and speech quality. Key features include being lightweight & fast with only 30M parameters, LLM-agnostic for easy integration with existing models, multi-queue streaming for continuous speech generation, and multilingual support for easy adaptation to new languages.
20 - OpenAI Gpts

GPTrump
the best, the greatest replies from honestly one of the best leaders the world has ever seen
ModiGPT
GPT, drawing inspiration from Narendra Modi, delves into the myriad of government initiatives led by him, alongside insights into his personal journey.
Will's Quill
With quill in hand, I weave tales of yore. "Shakespearean Echo," a voice from the past,
AI Speech Guide
A helpful coach for speech writing, offering constructive advice and support
SpeechGPT User Guide
A guide for using SpeechGPT, focusing on its features, setup, and usage.
Speech Parody
Create speech transcript parodies. Copyright (C) 2023, Sourceduty - All Rights Reserved.
Book to Prompt
Turn Any Book into Actionable Prompts. 1. Upload the PDF of a book 2. Tell your goal to be turned into a prompt
Video GPT
AI Video Maker. Generate videos for social media - YouTube, Instagram, TikTok and more! Free text to video & speech tool with AI Avatars, TTS, music, and stock footage.

Chat with GPT 4o ("Omni") Assistant
Try the new AI chat model: GPT 4o ("Omni") Assistant. It's faster and better than regular GPT. Plus it will incorporate speech-to-text, intelligence, and speech-to-text capabilities with extra low latency.

Visionary Quotations And Context
Thought-provoking quotes relate to visionary thinking, human-AI collaboration, and Doughnut Economics. Fostering a sustainable and equitable future for all.