Best AI tools for< Extract Named Entities >
20 - AI tool Sites
Predibase
Predibase is a platform for fine-tuning and serving Large Language Models (LLMs). It provides a cost-effective and efficient way to train and deploy LLMs for a variety of tasks, including classification, information extraction, customer sentiment analysis, customer support, code generation, and named entity recognition. Predibase is built on proven open-source technology, including LoRAX, Ludwig, and Horovod.
Explosion
Explosion is a software company specializing in developer tools and tailored solutions for AI, Machine Learning, and Natural Language Processing (NLP). They are the makers of spaCy, one of the leading open-source libraries for advanced NLP. The company offers consulting services and builds developer tools for various AI-related tasks, such as coreference resolution, dependency parsing, image classification, named entity recognition, and more.
Tinq.ai
Tinq.ai is a natural language processing (NLP) tool that provides a range of text analysis capabilities through its API. It offers tools for tasks such as plagiarism checking, text summarization, sentiment analysis, named entity recognition, and article extraction. Tinq.ai's API can be integrated into applications to add NLP functionality, such as content moderation, sentiment analysis, and text rewriting.
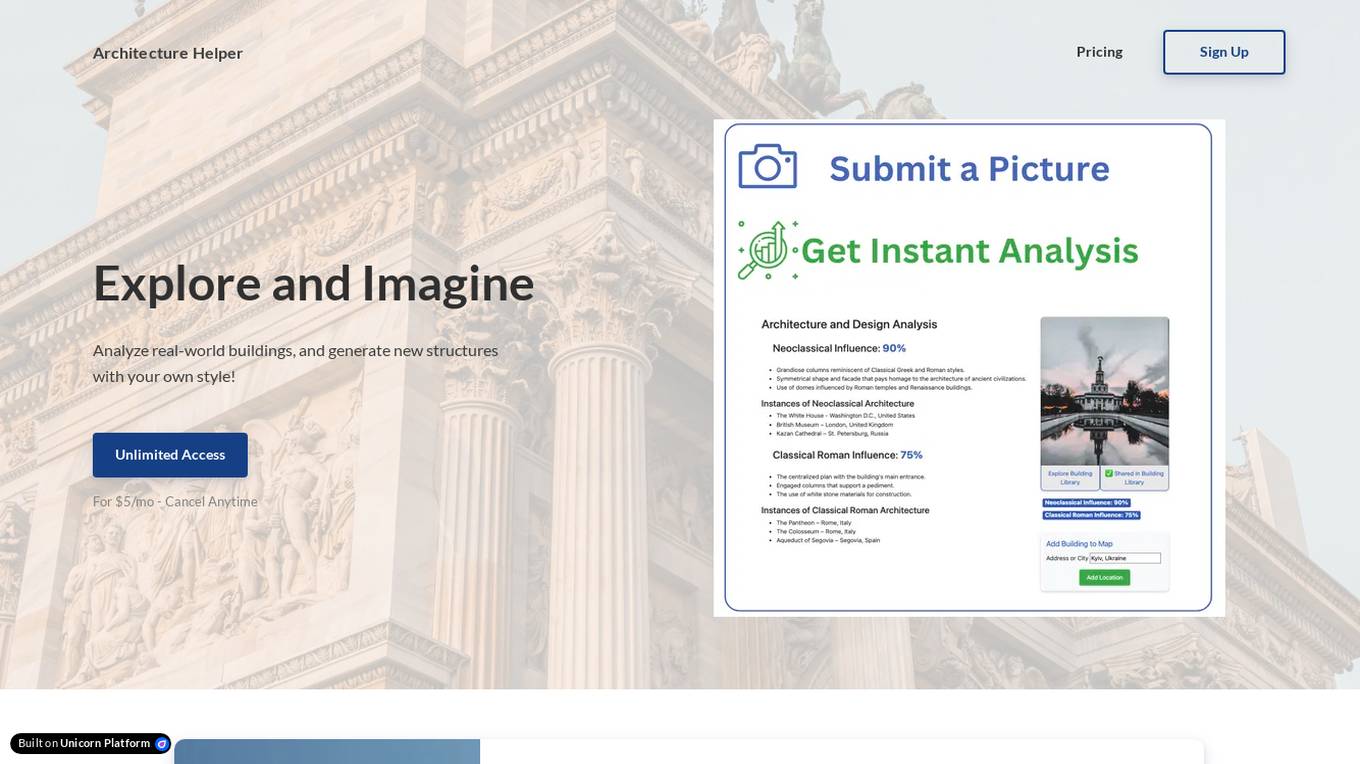
Architecture Helper
Architecture Helper is an AI-based application that allows users to analyze real-world buildings, explore architectural influences, and generate new structures with customizable styles. Users can submit images for instant design analysis, mix and match different architectural styles, and create stunning architectural and interior images. The application provides unlimited access for $5 per month, with the flexibility to cancel anytime. Named as a 'Top AI Tool' in Real Estate by CRE Software, Architecture Helper offers a powerful and playful tool for architecture enthusiasts to explore, learn, and create.

ColorMagic
ColorMagic is a powerful AI color palette generator that helps designers create beautiful color palettes in seconds. Users can generate color schemes from names, images, text, or hex codes effortlessly. The tool offers a variety of features such as generating palettes from names or images, mixing and blending colors, creating CSS gradients, and providing color palette ideas for different design styles.
OddBooks
OddBooks is an AI-powered tool that transforms books into scenarios, enabling users to create various content types such as audiobooks, webtoons, animations, and movies. It simplifies the process of producing derivative works by extracting character names, emotions, spatial and sound keywords, and inferring character personalities from the text. With OddBooks, users can easily generate scripts for secondary works in a fraction of the time it would traditionally take, revolutionizing the scenario creation process.
Insight7
Insight7 is a powerful AI-powered tool that helps businesses extract insights from customer and employee interviews. It uses natural language processing and machine learning to analyze large volumes of unstructured data, such as transcripts, audio recordings, and videos. Insight7 can identify key themes, trends, and sentiment, which can then be used to improve products, services, and customer experiences.
Kadoa
Kadoa is an AI web scraper tool that extracts unstructured web data at scale automatically, without the need for coding. It offers a fast and easy way to integrate web data into applications, providing high accuracy, scalability, and automation in data extraction and transformation. Kadoa is trusted by various industries for real-time monitoring, lead generation, media monitoring, and more, offering zero setup or maintenance effort and smart navigation capabilities.
FormX.ai
FormX.ai is an AI-powered data extraction and conversion tool that automates the process of extracting data from physical documents and converting it into digital formats. It supports a wide range of document types, including invoices, receipts, purchase orders, bank statements, contracts, HR forms, shipping orders, loyalty member applications, annual reports, business certificates, personnel licenses, and more. FormX.ai's pre-configured data extraction models and effortless API integration make it easy for businesses to integrate data extraction into their existing systems and workflows. With FormX.ai, businesses can save time and money on manual data entry and improve the accuracy and efficiency of their data processing.
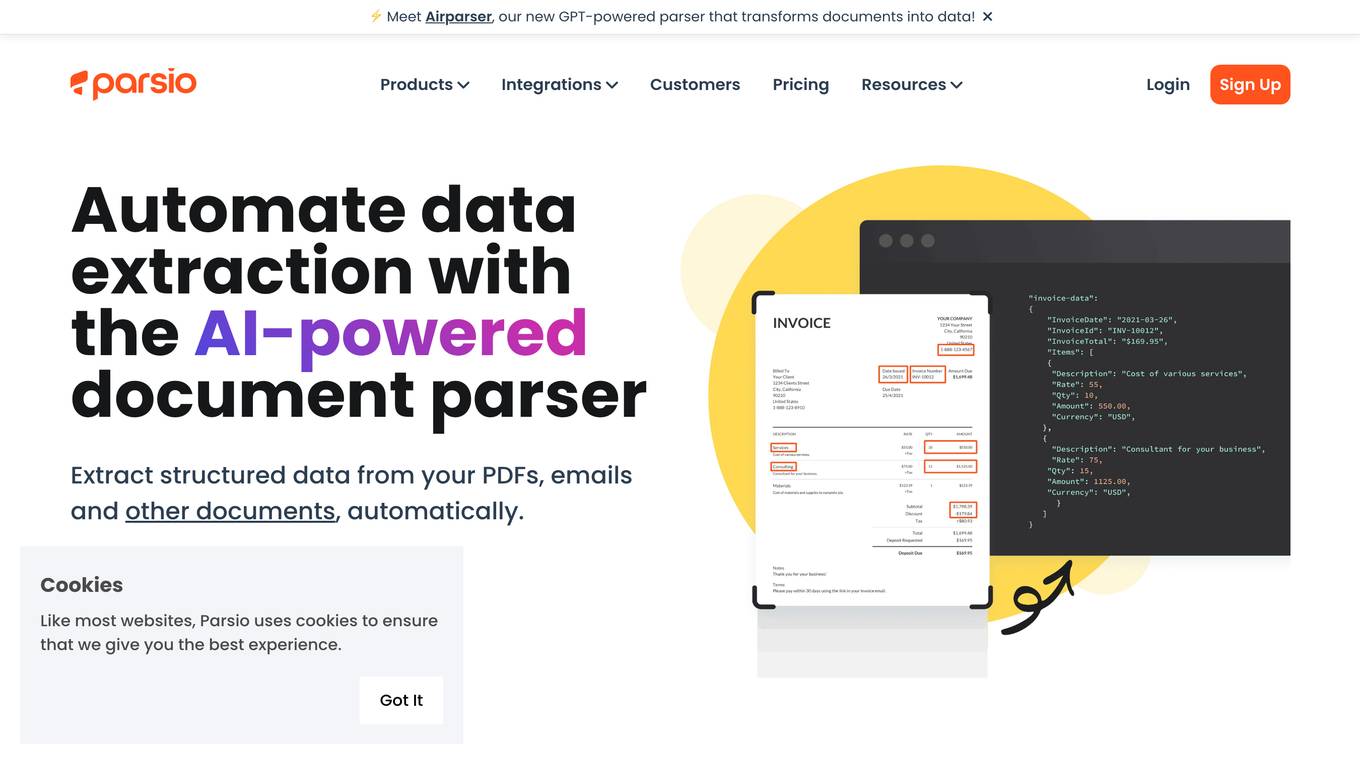
Parsio
Parsio is an AI-powered document parser that can extract structured data from PDFs, emails, and other documents. It uses natural language processing to understand the context of the document and identify the relevant data points. Parsio can be used to automate a variety of tasks, such as extracting data from invoices, receipts, and emails.

RIDO Protocol
RIDO Protocol is a decentralized data protocol that allows users to extract value from their personal data in Web2 and Web3. It provides users with a variety of features, including programmable data generation, programmable access control, and cross-application data sharing. RIDO also has a data marketplace where users can list or offer their data information and ownership. Additionally, RIDO has a DataFi protocol which promotes the flowing of data information and value.
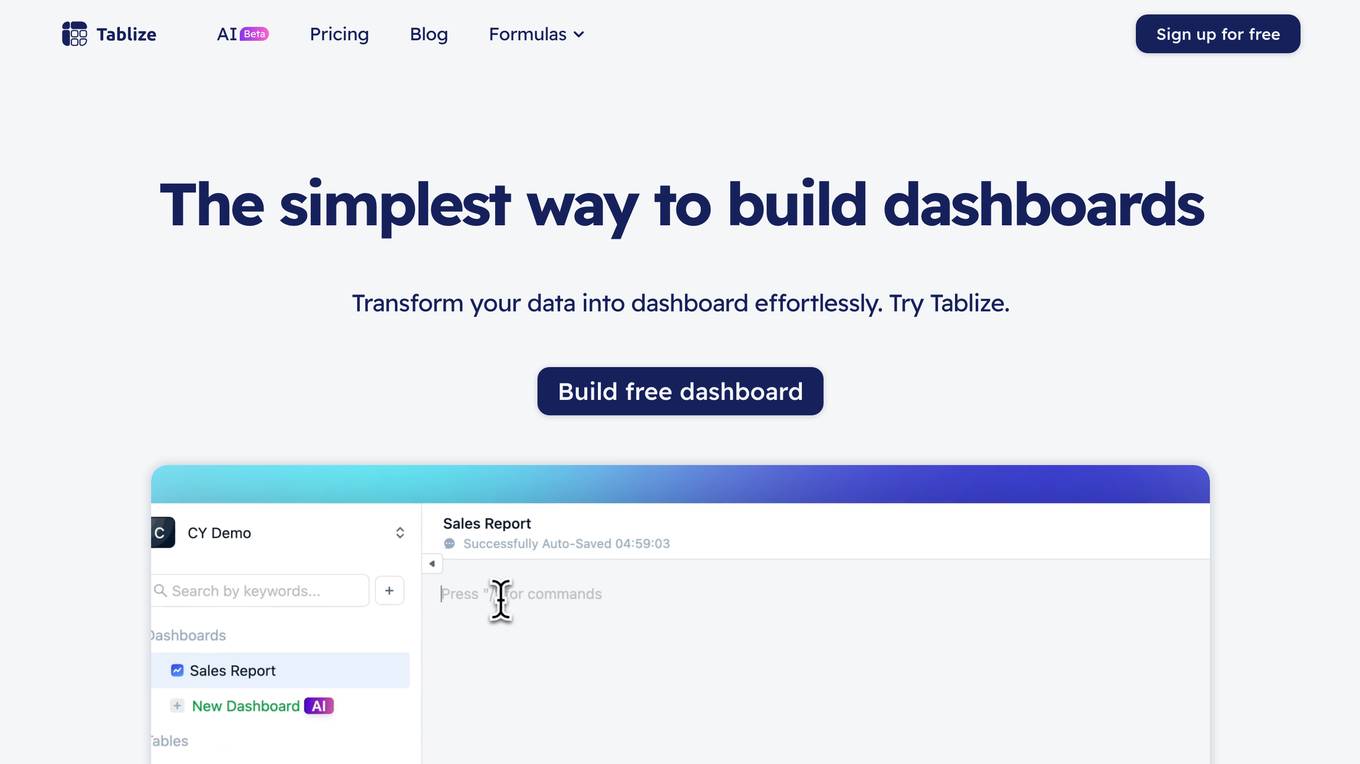
Tablize
Tablize is a powerful data extraction tool that helps you turn unstructured data into structured, tabular format. With Tablize, you can easily extract data from PDFs, images, and websites, and export it to Excel, CSV, or JSON. Tablize uses artificial intelligence to automate the data extraction process, making it fast and easy to get the data you need.
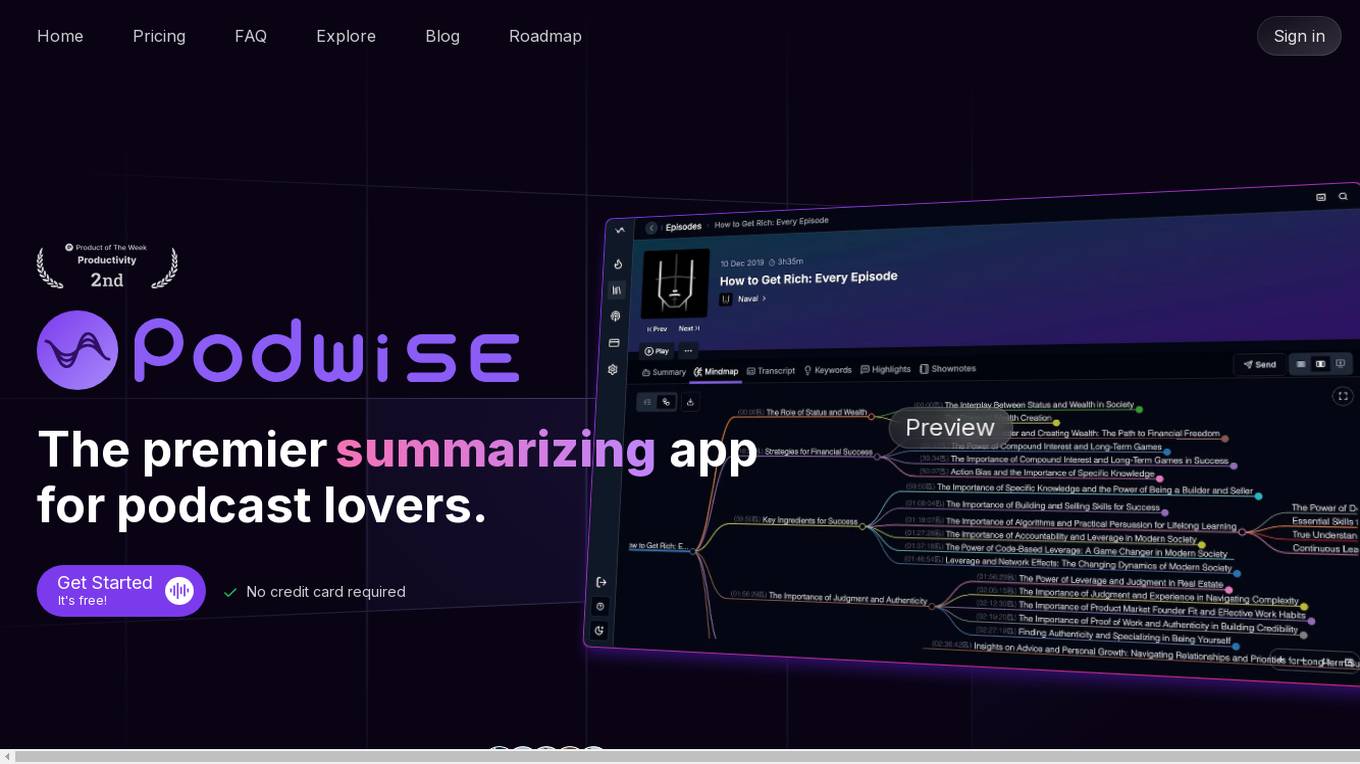
Podwise
Podwise is an AI-powered podcast tool designed for podcast lovers to extract structured knowledge from episodes at 10x speed. It offers features such as AI-powered summarization, mind mapping, content outlining, transcription, and seamless integration with knowledge management workflows. Users can subscribe to favorite content, get lightning-speed access to structured knowledge, and discover episodes of interest. Podwise aims to address the challenge of enjoying podcasts, recalling less, and forgetting quickly, by providing a meticulous, accurate, and impactful tool for efficient podcast referencing and note consolidation.
Kazuha
Kazuha is an AI-powered platform that provides investment insights extracted from top financial content creators on platforms like podcasts, YouTube, and Twitter. The platform uses advanced AI algorithms to analyze hours of content and generate concise summaries and key takeaways for investors. Users can stay informed about the latest investment opportunities and never miss actionable insights buried in lengthy financial content.
Nex
Nex is an AI Knowledge Copilot application designed to help users efficiently extract main points from long YouTube videos and articles. It offers features like summarizing content, providing quick takeaways, highlighting essential parts, and saving inspirations. With Nex, users can improve their information absorption and save time by focusing on the most relevant parts of the content.
Vocal Remover Oak
Vocal Remover Oak is an advanced AI tool designed for music producers, video makers, and karaoke enthusiasts to easily separate vocals and accompaniment in audio files. The website offers a free online vocal remover service that utilizes deep learning technology to provide fast processing, high-quality output, and support for various audio and video formats. Users can upload local files or provide YouTube links to extract vocals, accompaniment, and original music. The tool ensures lossless audio output quality and compatibility with multiple formats, making it suitable for professional music production and personal entertainment projects.

goPDF
goPDF is a comprehensive PDF management platform that offers a suite of tools for creating, converting, capturing, and interacting with PDFs. With its advanced features and user-friendly API, goPDF simplifies the handling of PDF documents for various purposes, including collaborative work, quick assistance, and engaging training. The platform's AI capabilities enhance the user experience by providing interactive reading, content summarization, and chatbot functionality.
Doclingo
Doclingo is an AI-powered document translation tool that supports translating documents in various formats such as PDF, Word, Excel, PowerPoint, SRT subtitles, ePub ebooks, AR&ZIP packages, and more. It utilizes large language models to provide accurate and professional translations, preserving the original layout of the documents. Users can enjoy a limited-time free trial upon registration, with the option to subscribe for more features. Doclingo aims to offer high-quality translation services through continuous algorithm improvements.

Reworkd
Reworkd is a web data extraction tool that uses AI to generate and repair web extractors on the fly. It allows users to retrieve data from hundreds of websites without the need for developers. Reworkd is used by businesses in a variety of industries, including manufacturing, e-commerce, recruiting, lead generation, and real estate.
super.AI
Super.AI provides Intelligent Document Processing (IDP) solutions powered by Large Language Models (LLMs) and human-in-the-loop (HITL) capabilities. It automates document processing tasks such as data extraction, classification, and redaction, enabling businesses to streamline their workflows and improve accuracy. Super.AI's platform leverages cutting-edge AI models from providers like Amazon, Google, and OpenAI to handle complex documents, ensuring high-quality outputs. With its focus on accuracy, flexibility, and scalability, Super.AI caters to various industries, including financial services, insurance, logistics, and healthcare.
2 - Open Source AI Tools
automatic-KG-creation-with-LLM
This repository presents a (semi-)automatic pipeline for Ontology and Knowledge Graph Construction using Large Language Models (LLMs) such as Mixtral 8x22B Instruct v0.1, GPT-4o, GPT-3.5, and Gemini. It explores the generation of Knowledge Graphs by formulating competency questions, developing ontologies, constructing KGs, and evaluating the results with minimal human involvement. The project showcases the creation of a KG on deep learning methodologies from scholarly publications. It includes components for data preprocessing, prompts for LLMs, datasets, and results from the selected LLMs.

OneKE
OneKE is a flexible dockerized system for schema-guided knowledge extraction, capable of extracting information from the web and raw PDF books across multiple domains like science and news. It employs a collaborative multi-agent approach and includes a user-customizable knowledge base to enable tailored extraction. OneKE offers various IE tasks support, data sources support, LLMs support, extraction method support, and knowledge base configuration. Users can start with examples using YAML, Python, or Web UI, and perform tasks like Named Entity Recognition, Relation Extraction, Event Extraction, Triple Extraction, and Open Domain IE. The tool supports different source formats like Plain Text, HTML, PDF, Word, TXT, and JSON files. Users can choose from various extraction models like OpenAI, DeepSeek, LLaMA, Qwen, ChatGLM, MiniCPM, and OneKE for information extraction tasks. Extraction methods include Schema Agent, Extraction Agent, and Reflection Agent. The tool also provides support for schema repository and case repository management, along with solutions for network issues. Contributors to the project include Ningyu Zhang, Haofen Wang, Yujie Luo, Xiangyuan Ru, Kangwei Liu, Lin Yuan, Mengshu Sun, Lei Liang, Zhiqiang Zhang, Jun Zhou, Lanning Wei, Da Zheng, and Huajun Chen.
20 - OpenAI Gpts

Podcast Summarizer - Pro
Provide podcast name and episode or Spotify URL. Get key quotes. Ask questions.

Simplexity (TM)
Simple rich summaries ---keyword it with movies, celebs, sports figures, technologies, cities, patents, company name
PDF Ninja
I extract data and tables from PDFs to CSV, focusing on data privacy and precision.
Visual Storyteller
Extract the essence of the novel story according to the quantity requirements and generate corresponding images. The images can be used directly to create novel videos.小说推文图片自动批量生成,可自动生成风格一致性图片
Receipt CSV Formatter
Extract from receipts to CSV: Date of Purchase, Item Purchased, Quantity Purchased, Units
PDF AI
PDFChat : Analyse 1000's of PDF's in seconds, extract and chat with PDFs in any language.
Watch Identification, Pricing, Sales Research Tool
Analyze watch images, extract text, and craft sales descriptions. Add 1 or more images for a single watch to get started.
The Enigmancer
Put your prompt engineering skills to the ultimate test! Embark on a journey to outwit a mythical guardian of ancient secrets. Try to extract the secret passphrase hidden in the system prompt and enter it in chat when you think you have it and claim your glory. Good luck!

Dissertation & Thesis GPT
An Ivy Leage Scholar GPT equipped to understand your research needs, formulate comprehensive literature review strategies, and extract pertinent information from a plethora of academic databases and journals. I'll then compose a peer review-quality paper with citations.


ExtractWisdom
Takes in any text and extracts the wisdom from it like you spent 3 hours taking handwritten notes.

QCM
ce GPT va recevoir des images dans lesquelles il y a des questions QCM codingame ou Problem Solving sur les sujets : Java, Hibernate, Angular, Spring Boot, SQL. Il doit extraire le texte depuis l'image et répondre au question QCM le plus rapidement possible.
Ringkesan
Nyimpulkeun sareng nimba poin konci tina téks, artikel, video, dokumén sareng seueur deui