Best AI tools for< Evaluate Product Performance >
20 - AI tool Sites
Insidr AI
Insidr AI is a real-time analysis tool that helps users track their competition by providing actionable insights about products. Powered by Supervised AI, the tool offers features such as analyzing user reviews, gaining insights on competitors, and performing various analyses like sentiment analysis, SWOT analysis, and trend analysis. Users can also transcribe recordings, perform KPI analysis, and find competitive edges. With a focus on providing accurate data and insights, Insidr AI aims to help businesses make informed decisions and stay ahead of the competition.

Libera Global AI
Libera Global AI is an AI and blockchain solution provider for emerging market retail. The platform empowers small businesses and brands in emerging markets with AI-driven insights to enhance visibility, efficiency, and profitability. By harnessing the power of AI and blockchain, Libera aims to create a more connected and transparent retail ecosystem in regions like Asia, Africa, and beyond. The company offers innovative solutions such as Display AI, Receipt AI, Knowledge Graph API, and Large Vision Model to revolutionize market evaluation and decision-making processes. With a mission to bridge the gap in retail data challenges, Libera is shaping the future of retail by enabling businesses to make smarter decisions and drive growth.

Sereda.ai
Sereda.ai is an AI-powered platform designed to unleash a team's potential by offering solutions for employee knowledge management, surveys, performance reviews, learning, and more. It integrates artificial intelligence to streamline HR processes, improve employee engagement, and boost productivity. The platform provides a user-friendly interface, personalized settings, and automation features to enhance organizational efficiency and reduce costs.

FinetuneDB
FinetuneDB is an AI fine-tuning platform that allows users to easily create and manage datasets to fine-tune LLMs, evaluate outputs, and iterate on production data. It integrates with open-source and proprietary foundation models, and provides a collaborative editor for building datasets. FinetuneDB also offers a variety of features for evaluating model performance, including human and AI feedback, automated evaluations, and model metrics tracking.

Confident AI
Confident AI is an AI evaluation and observability platform designed to help engineers, QA teams, and product leaders build reliable AI systems. It offers best-in-class evaluation metrics powered by DeepEval, real-time production alerts, and tools for tracing and monitoring AI performance. The platform aims to streamline dataset curation, metric alignment, and LLM testing automation, ultimately saving time, reducing costs, and ensuring continuous improvement of AI models.

Confident AI
Confident AI is an open-source evaluation infrastructure for Large Language Models (LLMs). It provides a centralized platform to judge LLM applications, ensuring substantial benefits and addressing any weaknesses in LLM implementation. With Confident AI, companies can define ground truths to ensure their LLM is behaving as expected, evaluate performance against expected outputs to pinpoint areas for iterations, and utilize advanced diff tracking to guide towards the optimal LLM stack. The platform offers comprehensive analytics to identify areas of focus and features such as A/B testing, evaluation, output classification, reporting dashboard, dataset generation, and detailed monitoring to help productionize LLMs with confidence.
Coval
Coval is an AI tool designed to help users ship reliable AI agents faster by providing simulation and evaluations for voice and chat agents. It allows users to simulate thousands of scenarios from a few test cases, create prompts for testing, and evaluate agent interactions comprehensively. Coval offers AI-powered simulations, voice AI compatibility, performance tracking, workflow metrics, and customizable evaluation metrics to optimize AI agents efficiently.
Respan
Respan is an AI observability platform designed to trace, evaluate, optimize, deploy, and monitor AI agents. It provides self-driving observability and evaluations for agents, allowing users to surface issues automatically, fix problems faster, and ensure that AI behaves as intended. The platform offers features such as tracing agent behavior, evaluating system performance, optimizing prompts and tools, deploying through a single gateway, and monitoring production shifts. Respan is loved by world-class founders, engineers, and product teams for its user-friendly interface and real-time observability capabilities.
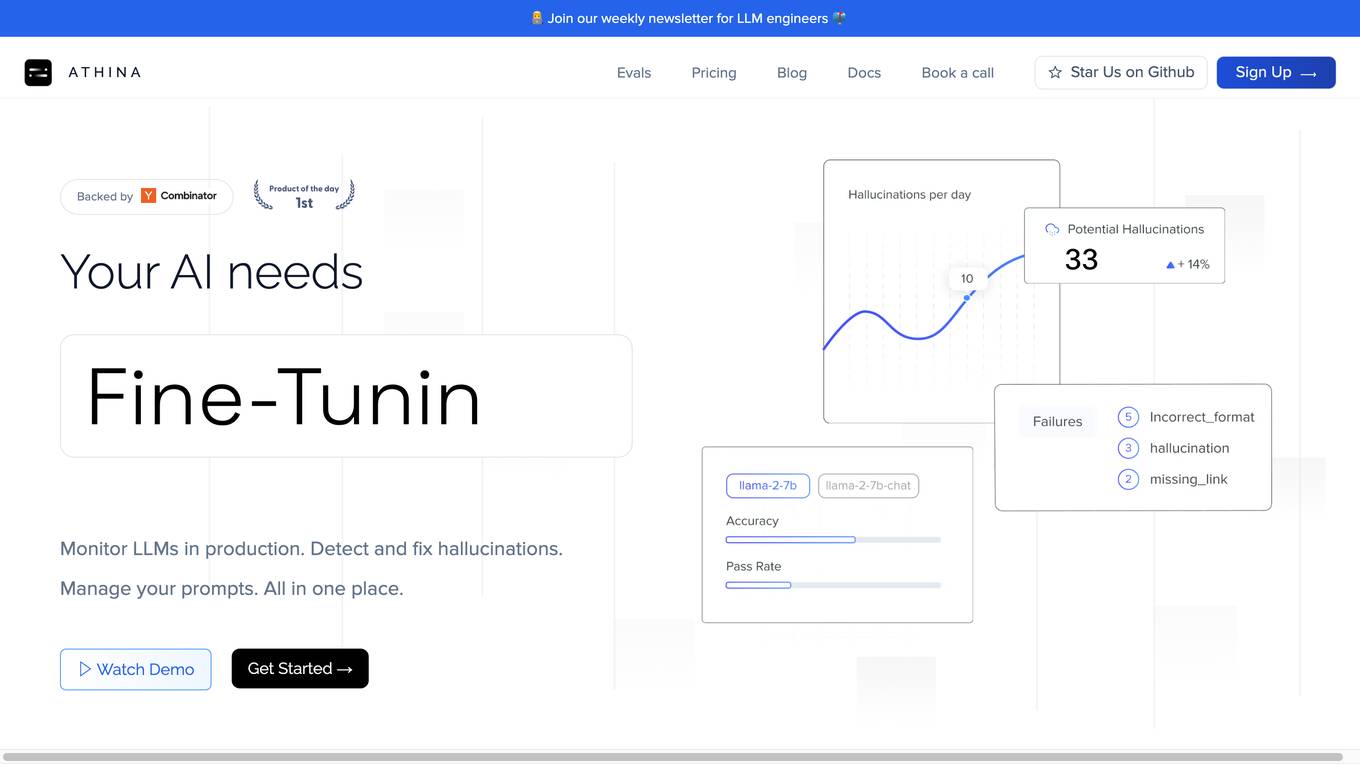
Athina AI
Athina AI is a comprehensive platform designed to monitor, debug, analyze, and improve the performance of Large Language Models (LLMs) in production environments. It provides a suite of tools and features that enable users to detect and fix hallucinations, evaluate output quality, analyze usage patterns, and optimize prompt management. Athina AI supports integration with various LLMs and offers a range of evaluation metrics, including context relevancy, harmfulness, summarization accuracy, and custom evaluations. It also provides a self-hosted solution for complete privacy and control, a GraphQL API for programmatic access to logs and evaluations, and support for multiple users and teams. Athina AI's mission is to empower organizations to harness the full potential of LLMs by ensuring their reliability, accuracy, and alignment with business objectives.

Lisapet.AI
Lisapet.AI is an AI prompt testing suite designed for product teams to streamline the process of designing, prototyping, testing, and shipping AI features. It offers a comprehensive platform with features like best-in-class AI playground, variables for dynamic data inputs, structured outputs, side-by-side editing, function calling, image inputs, assertions & metrics, performance comparison, data sets organization, shareable reports, comments & feedback, token & cost stats, and more. The application aims to help teams save time, improve efficiency, and ensure the reliability of AI features through automated prompt testing.

Truesight
Goodeye Labs offers Truesight, an AI evaluation tool designed for domain experts to assess the performance of AI products without the need for extensive technical expertise. Truesight bridges the gap between domain knowledge and technical implementation, enabling users to evaluate AI-generated content against specific standards and factors. By empowering domain experts to provide judgment on AI performance, Truesight streamlines the evaluation process, reducing costs, meeting deadlines, and enhancing the reliability of AI products.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.
AARENA
AARENA is an AI-powered platform that allows users to build fully functional apps and websites through simple conversations. It provides a user-friendly interface where individuals can create various digital products without the need for coding knowledge. AARENA leverages AI technology to streamline the development process and empower users to bring their ideas to life efficiently.
Arthur
Arthur is an industry-leading MLOps platform that simplifies deployment, monitoring, and management of traditional and generative AI models. It ensures scalability, security, compliance, and efficient enterprise use. Arthur's turnkey solutions enable companies to integrate the latest generative AI technologies into their operations, making informed, data-driven decisions. The platform offers open-source evaluation products, model-agnostic monitoring, deployment with leading data science tools, and model risk management capabilities. It emphasizes collaboration, security, and compliance with industry standards.
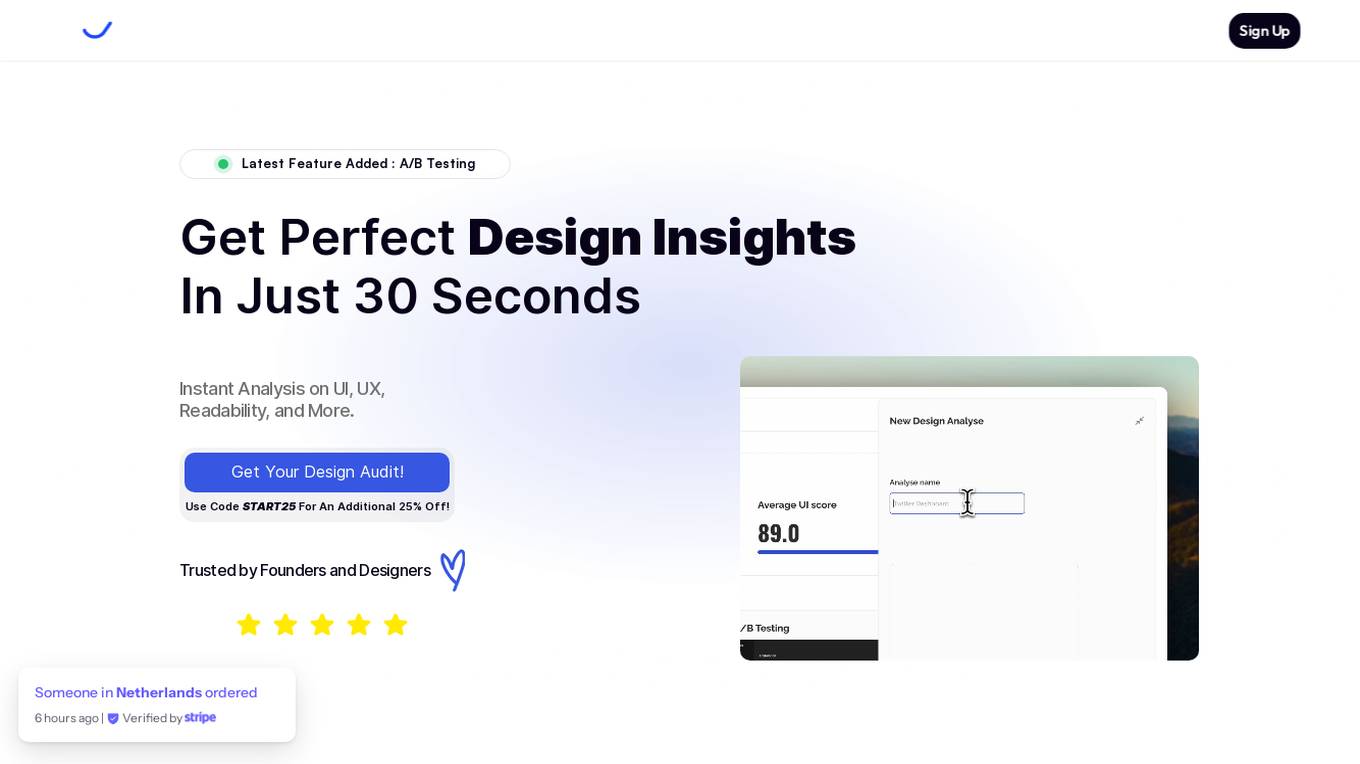
VisualHUB
VisualHUB is an AI-powered design analysis tool that provides instant insights on UI, UX, readability, and more. It offers features like A/B Testing, UI Analysis, UX Analysis, Readability Analysis, Margin and Hierarchy Analysis, and Competition Analysis. Users can upload product images to receive detailed reports with actionable insights and scores. Trusted by founders and designers, VisualHUB helps optimize design variations and identify areas for improvement in products.
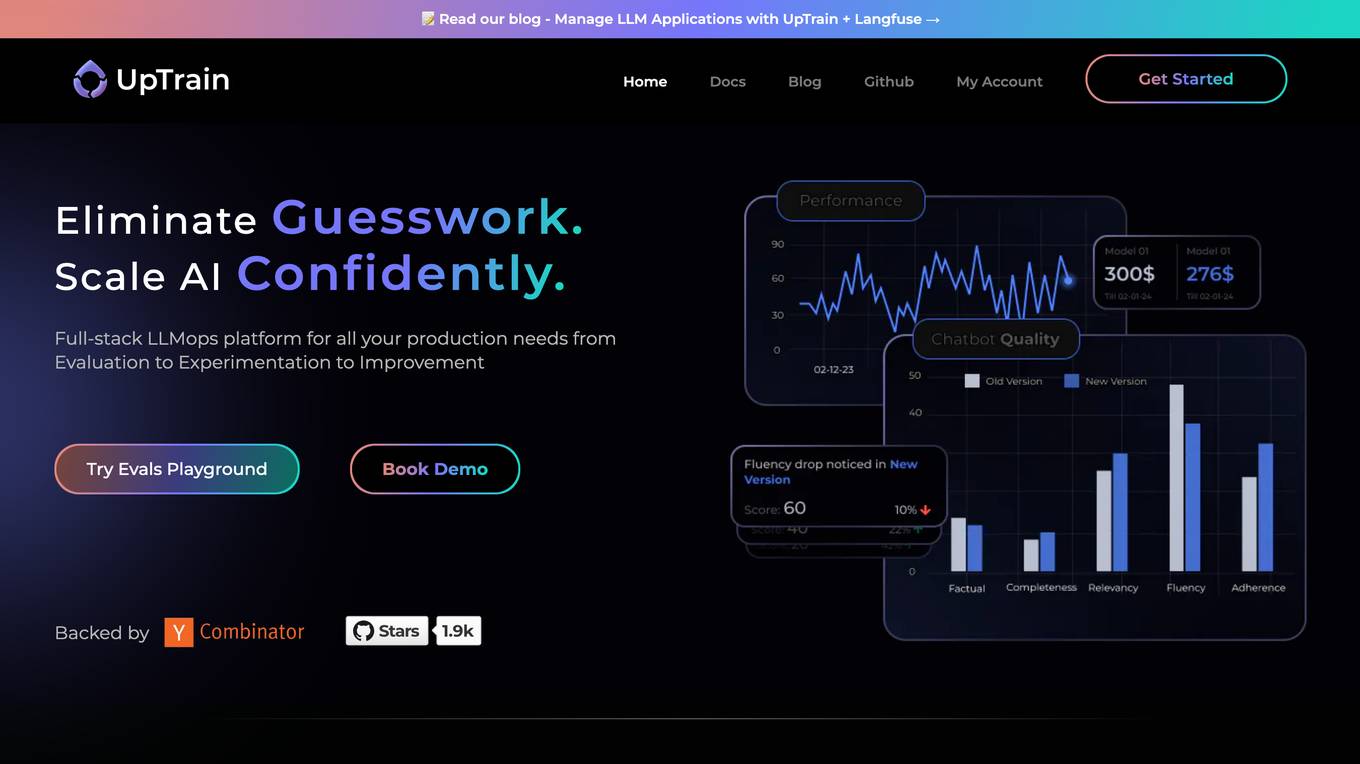
UpTrain
UpTrain is a full-stack LLMOps platform designed to help users confidently scale AI by providing a comprehensive solution for all production needs, from evaluation to experimentation to improvement. It offers diverse evaluations, automated regression testing, enriched datasets, and innovative techniques to generate high-quality scores. UpTrain is built for developers, compliant to data governance needs, cost-efficient, remarkably reliable, and open-source. It provides precision metrics, task understanding, safeguard systems, and covers a wide range of language features and quality aspects. The platform is suitable for developers, product managers, and business leaders looking to enhance their LLM applications.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.
PandaRocket
PandaRocket is an AI-powered suite designed to support various eCommerce business models. It offers a range of tools for product research, content creation, and store management. With features like market analysis, customer segmentation, and predictive intelligence, PandaRocket helps users make data-driven decisions to optimize their online stores and maximize profits.

A Million Dollar Idea
A Million Dollar Idea is an AI-powered business idea generator that helps entrepreneurs and small business owners come up with new and innovative business ideas. The tool uses a variety of data sources, including industry trends, market research, and user feedback, to generate ideas that are tailored to the user's specific needs and interests. A Million Dollar Idea is a valuable resource for anyone who is looking to start a new business or grow an existing one.
Unified DevOps platform to build AI applications
This is a unified DevOps platform to build AI applications. It provides a comprehensive set of tools and services to help developers build, deploy, and manage AI applications. The platform includes a variety of features such as a code editor, a debugger, a profiler, and a deployment manager. It also provides access to a variety of AI services, such as natural language processing, machine learning, and computer vision.
0 - Open Source AI Tools
20 - OpenAI Gpts
Software Comparison
I compare different software, providing detailed, balanced information.

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model

B2B Startup Ideal Customer Co-pilot
Guides B2B startups in a structured customer segment evaluation process. Stop guessing! Ideate, Evaluate & Make data-driven decision.
Product Improvement Research Advisor
Improves product quality through innovative research and development.


Competitive Defensibility Analyzer
Evaluates your long-term market position based on value offered and uniqueness against competitors.

Quality Assurance Advisor
Ensures product quality through systematic process monitoring and evaluation.

Startup Advisor
Startup advisor guiding founders through detailed idea evaluation, product-market-fit, business model, GTM, and scaling.
Startup Critic
Apply gold-standard startup valuation and assessment methods to identify risks and gaps in your business model and product ideas.

Vorstellungsgespräch Simulator Bewerbung Training
Wertet Lebenslauf und Stellenanzeige aus und simuliert ein Vorstellungsgespräch mit anschließender Auswertung: Lebenslauf und Anzeige einfach hochladen und starten.

API Evaluator Pro
Examines and evaluates public API documentation and offers detailed guidance for improvements, including AI usability