AI tools for Flux video
Related Tools:

Flux Video AI
Flux Video AI is an advanced AI-powered video creation platform that transforms images and text into stunning, cinematic videos with movie-grade camera movements and lifelike visuals. It offers smart video creation from text, supporting multiple languages, and delivers professional-grade video experiences for various purposes such as marketing, education, and storytelling. Users can effortlessly create high-quality videos with Flux Video AI's image-to-video and text-to-video features, enhancing content diversity and expression.
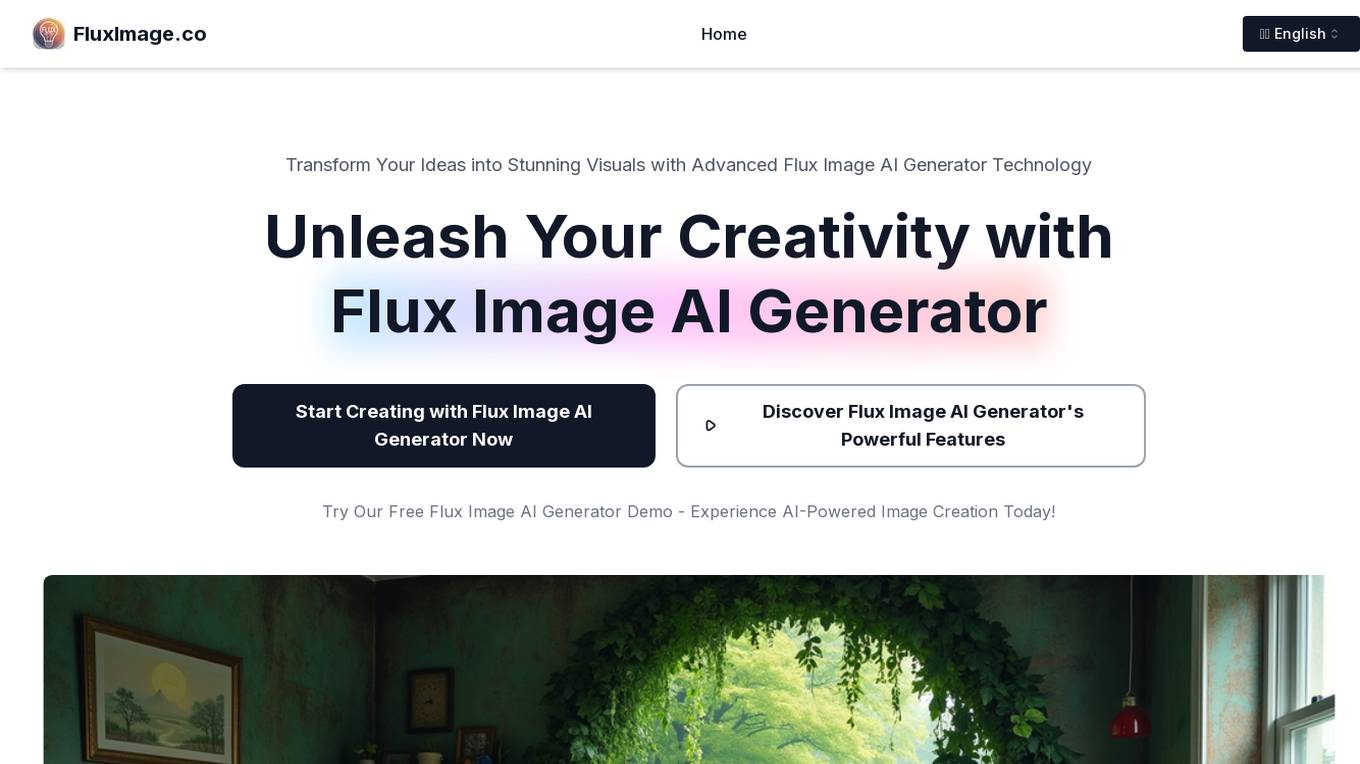
Flux Image AI Generator
Flux Image AI Generator is an online tool that utilizes advanced AI technology to transform text prompts into high-quality images in seconds. It offers a range of models catering to different needs, from commercial projects to non-commercial experimentation. With features like image-to-image generation and advanced language understanding, Flux Image AI Generator provides users with unprecedented creative control and speed in generating visuals.
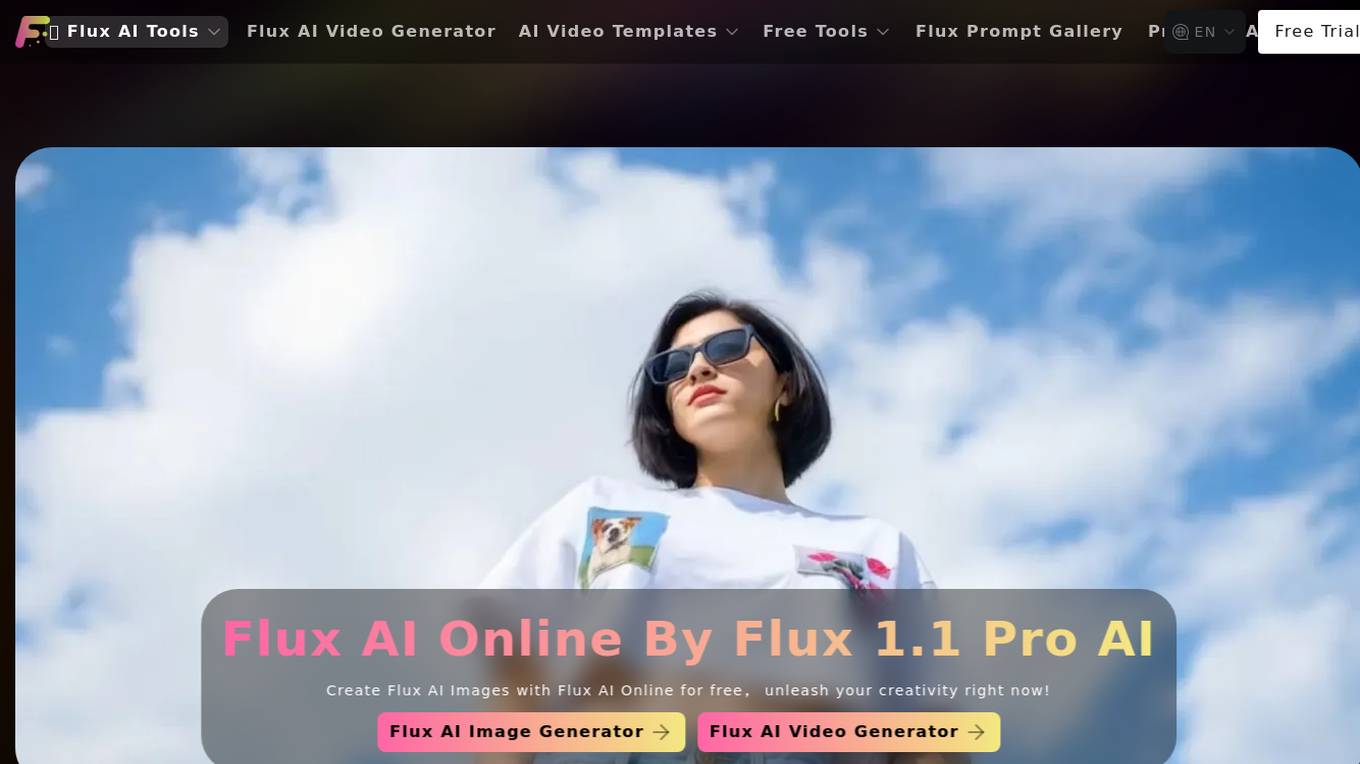
Flux AI Online
Flux AI Online is an advanced AI tool that offers a wide range of features for image and video generation. Users can create stunning images and videos using Flux Pro AI models such as Flux Lora Image Generator, Flux AI Anime Image Generator, and more. The tool also includes AI tools like Flux Canny/Depth AI for image processing and Flux Fill AI for image completion. With Flux AI, users can effortlessly enhance their creative workflow and bring ideas to life with high-quality visuals.

FLUX.1
FLUX.1 is an AI image generator and prompt generator tool that transforms text descriptions into high-quality images. It offers different versions for various purposes, such as professional image generation, personal projects, and quick local development. FLUX.1 is designed to democratize access to high-quality content creation tools, catering to professionals and hobbyists in industries like advertising, entertainment, social media, and education. Despite its strengths, FLUX.1 may face challenges with complex visual scenes and specific output demands, requiring fine-tuning for certain applications. The tool is open-source, encouraging community collaboration and new ideas among developers for future opportunities in text-to-video systems.
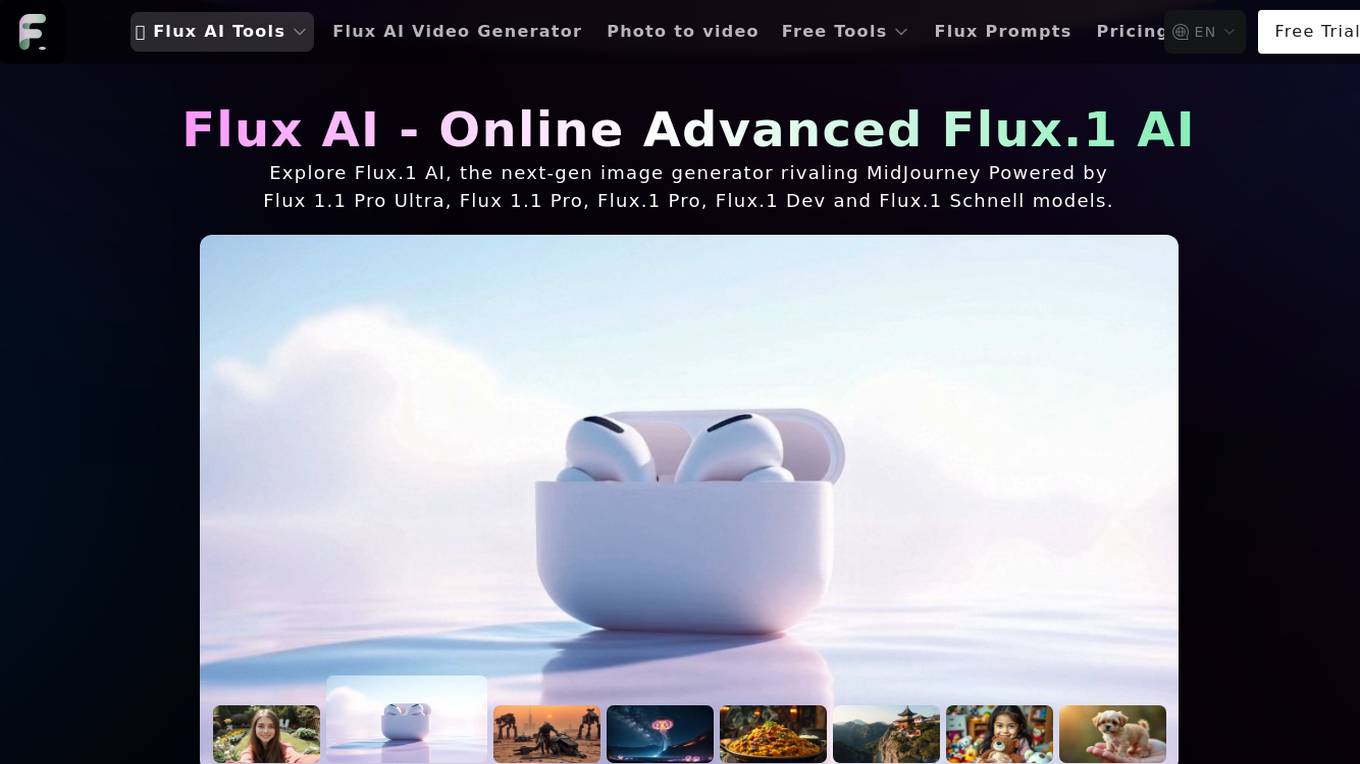
Flux AI
Flux AI is a cutting-edge AI tool that offers a range of advanced features for image and video generation. It provides users with the ability to transform text and images into stunning visuals and videos using state-of-the-art AI models. With customizable styles, instant rendering, and high-quality output, Flux AI empowers users to unleash their creativity and bring their ideas to life with ease. The application also includes tools for image inpainting, image enhancement, and prompt generation, catering to a wide range of creative needs. Whether you're a novice or a professional, Flux AI offers endless possibilities for creating magic in seconds.

RepublicLabs.ai
RepublicLabs.ai is an AI tool that allows users to generate images and videos using AI generative models. The platform offers a user-friendly experience with no commitments or subscriptions required. Users can access the latest AI models for multi-model generation and create content without the need for a credit card. RepublicLabs.ai aims to empower people to unleash their creativity through the use of cutting-edge AI technology.

MixHub AI
MixHub AI is an all-in-one platform offering free AI chat, image, and video models. It provides powerful and affordable AI tools for various creative needs, such as text-to-video, image-to-video, and video generation. With a user-friendly interface and versatile creation methods, MixHub AI caters to both entertainment and professional scenarios. The platform supports top AI models like Runway, Kling, and Sora, ensuring high-quality output without technical barriers. Users can easily create animations, special effects, and cartoons using 150+ popular video and image effects.

Flux Image AI
Flux Image AI is a cutting-edge AI art generator powered by the Flux.1 model developed by Black Forest Labs. It revolutionizes the image creation process by rapidly generating high-quality images from text prompts. With exceptional prompt adherence, image detail, and style diversity, Flux Image AI empowers creators worldwide to bring their wildest ideas to life in minutes, saving time and enhancing creative output.
Pixel Dojo
Pixel Dojo is an AI-powered platform that offers a wide range of tools for creators to generate AI art, videos, and character designs. With features like image enhancement, animation, inpainting, and more, Pixel Dojo aims to simplify and elevate the creative process for both beginners and advanced users. The platform integrates multiple professional-grade AI models to provide a seamless and intuitive experience.
Flux Pro Image Generator
Flux Pro Image Generator is an advanced AI tool that revolutionizes text-to-image generation. It offers cutting-edge features such as lightning-fast image creation, unparalleled image quality, user-friendly interface, advanced control options, and a collection of fun tools to spark creativity. Users can easily turn their ideas into stunning visuals in seconds without requiring expertise. Flux Pro is faster, more user-friendly, and produces higher quality images compared to many competitors. It is open-source, regularly updated, and allows for commercial use of generated images. The tool is web-based with potential mobile app releases in the future.

Flux Image
Flux Image is an AI-powered tool that generates free high-quality images for various purposes. Users can access a wide range of image themes and styles, from enchanted twilight scenes to whimsical fairytale settings. The tool offers a user-friendly interface for easy image generation, allowing users to create unique visuals for their projects. With a vast library of AI-generated images, Flux Image provides a convenient solution for individuals and businesses seeking creative visuals without the need for photography skills or expensive stock images.
FLUX.1
FLUX.1 is an open-source image generation model developed by Black Forest Labs. It excels in rapid image generation, exceptional prompt adherence, and superior capabilities across various metrics. Users can input detailed descriptions to generate high-quality images quickly, with options for different versions offering varying speeds and features. FLUX.1 outperforms competitors in visual quality, prompt adherence, and versatility, making it suitable for diverse applications from creative projects to commercial use.

Flux LoRA Model Library
Flux LoRA Model Library is an AI tool that provides a platform for finding and using Flux LoRA models suitable for various projects. Users can browse a catalog of popular Flux LoRA models and learn about FLUX models and LoRA (Low-Rank Adaptation) technology. The platform offers resources for fine-tuning models and ensuring responsible use of generated images.
Flux AI
Flux AI is a cutting-edge text-to-image AI model developed by Black Forest Labs. It uses advanced transformer-powered flow models to generate high-quality images from text descriptions. Flux AI offers multiple model variants catering to different use cases and performance levels, with the fastest model, FLUX.1 [schnell], available for free under an Apache 2.0 license. Users can create various styles of images with prompt adherence, size/aspect variability, and output diversity. The application is committed to making advanced AI technology accessible to all users, fostering innovation and collaboration within the AI community.

FLUX.1 AI
FLUX.1 AI is an advanced text-to-image generation model developed by Black Forest Labs. It utilizes cutting-edge AI technology to create stunning, diverse, and highly detailed images from text prompts. The application offers exceptional image quality, prompt adherence, style diversity, and scene complexity, setting new standards in text-to-image synthesis. FLUX.1 AI supports various aspect ratios and resolutions, providing flexibility in image creation. It is available in three versions: FLUX.1 [pro], FLUX.1 [dev], and FLUX.1 [schnell], each catering to different needs and access levels.
FluxAI.art
FluxAI.art is an AI image generator developed by Black Forest Labs, offering state-of-the-art text-to-image models with advanced features and cutting-edge technology. The Flux.1 suite includes Flux.1 [pro] for commercial applications, Flux.1 [dev] for non-commercial use, and Flux.1 [schnell] for optimized speed and efficiency. With a focus on image quality, prompt adherence, and diversity, FluxAI.art sets a new standard in AI-powered image synthesis, catering to artists, designers, and developers seeking innovative image generation solutions.

Flux AI
Flux AI Online is a next-generation AI image generation tool that outperforms competitors in speed and quality. It offers lightning-fast image generation, unparalleled quality with the Flux.1 model, and a user-friendly interface perfect for beginners and professionals. Users can create stunning visuals in seconds, explore advanced features like Flux Pro and Flux Schnell, and choose from various pricing plans to suit their needs. Flux AI is open-source, available on GitHub and Hugging Face, and allows for commercial use.
Flux Image Generator
Flux Image Generator is a cutting-edge AI tool that transforms text descriptions into high-quality images with exceptional prompt accuracy, premium image quality, and lightning-fast generation. It offers a versatile style range, commercial-ready output, and ironclad privacy protection. Users can create a broad spectrum of artistic styles and visual effects, from photorealistic images to abstract art, landscapes, portraits, and product visualizations. The tool is available in three versions: Flux.1 Schnell, Flux.1 Dev, and Flux.1 Pro, each catering to different user needs and preferences.

Flux AI Image Generator
Flux AI Image Generator is a cutting-edge AI tool developed by Black Forest Labs, offering state-of-the-art text-to-image generation capabilities. Powered by the Flux.1 model family, this AI application transforms text descriptions into captivating visuals with exceptional quality and precision. With versatile model suites, wide-ranging image generation capabilities, and user-friendly platform, Flux AI sets a new standard in AI-driven image creation. The platform caters to personal, research, and commercial applications, making it suitable for various industries such as creative, marketing, entertainment, and education.

Flux AI
Flux AI is an image generator tool that utilizes the Flux.1 model to create stunning images from text descriptions. It offers precision text rendering, complex composition mastering, enhanced anatomical accuracy, and diverse model variants to cater to various creative needs. Users can easily generate images by selecting the model, entering a description, and clicking 'Generate'. Flux AI is open-source and developed by Black Forest Labs, providing a seamless experience for image creation.
ComfyUI-fal-API
ComfyUI-fal-API is a repository containing custom nodes for using Flux models with fal API in ComfyUI. It provides nodes for image generation, video generation, language models, and vision language models. Users can easily install and configure the repository to access various nodes for different tasks such as generating images, creating videos, processing text, and understanding images. The repository also includes troubleshooting steps and is licensed under the Apache License 2.0.
VideoTuna
VideoTuna is a codebase for text-to-video applications that integrates multiple AI video generation models for text-to-video, image-to-video, and text-to-image generation. It provides comprehensive pipelines in video generation, including pre-training, continuous training, post-training, and fine-tuning. The models in VideoTuna include U-Net and DiT architectures for visual generation tasks, with upcoming releases of a new 3D video VAE and a controllable facial video generation model.
Pallaidium
Pallaidium is a generative AI movie studio integrated into the Blender video editor. It allows users to AI-generate video, image, and audio from text prompts or existing media files. The tool provides various features such as text to video, text to audio, text to speech, text to image, image to image, image to video, video to video, image to text, and more. It requires a Windows system with a CUDA-supported Nvidia card and at least 6 GB VRAM. Pallaidium offers batch processing capabilities, text to audio conversion using Bark, and various performance optimization tips. Users can install the tool by downloading the add-on and following the installation instructions provided. The tool comes with a set of restrictions on usage, prohibiting the generation of harmful, pornographic, violent, or false content.
Stable-Diffusion
Stable Diffusion is a text-to-image AI model that can generate realistic images from a given text prompt. It is a powerful tool that can be used for a variety of creative and practical applications, such as generating concept art, creating illustrations, and designing products. Stable Diffusion is also a great tool for learning about AI and machine learning. This repository contains a collection of tutorials and resources on how to use Stable Diffusion.
img-prompt
IMGPrompt is an AI prompt editor tailored for image and video generation tools like Stable Diffusion, Midjourney, DALL·E, FLUX, and Sora. It offers a clean interface for viewing and combining prompts with translations in multiple languages. The tool includes features like smart recommendations, translation, random color generation, prompt tagging, interactive editing, categorized tag display, character count, and localization. Users can enhance their creative workflow by simplifying prompt creation and boosting efficiency.
story-flicks
This project enables users to create story videos by inputting a story theme, utilizing a large language model to generate AI-generated images, story content, audio, and subtitles. The backend is built with Python and FastAPI, while the frontend utilizes React, Ant Design, and Vite.

stable-diffusion.cpp
The stable-diffusion.cpp repository provides an implementation for inferring stable diffusion in pure C/C++. It offers features such as support for different versions of stable diffusion, lightweight and dependency-free implementation, various quantization support, memory-efficient CPU inference, GPU acceleration, and more. Users can download the built executable program or build it manually. The repository also includes instructions for downloading weights, building from scratch, using different acceleration methods, running the tool, converting weights, and utilizing various features like Flash Attention, ESRGAN upscaling, PhotoMaker support, and more. Additionally, it mentions future TODOs and provides information on memory requirements, bindings, UIs, contributors, and references.

CogVideo
CogVideo is an open-source repository that provides pretrained text-to-video models for generating videos based on input text. It includes models like CogVideoX-2B and CogVideo, offering powerful video generation capabilities. The repository offers tools for inference, fine-tuning, and model conversion, along with demos showcasing the model's capabilities through CLI, web UI, and online experiences. CogVideo aims to facilitate the creation of high-quality videos from textual descriptions, catering to a wide range of applications.
NeuroSandboxWebUI
A simple and convenient interface for using various neural network models. Users can interact with LLM using text, voice, and image input to generate images, videos, 3D objects, music, and audio. The tool supports a wide range of models for different tasks such as image generation, video generation, audio file separation, voice conversion, and more. Users can also view files from the outputs directory in a gallery, download models, change application settings, and check system sensors. The goal of the project is to create an easy-to-use application for utilizing neural network models.

CogVideo
CogVideo is a Python library for analyzing and processing video data. It provides functionalities for video segmentation, object detection, and tracking. With CogVideo, users can extract meaningful information from video streams, enabling applications in computer vision, surveillance, and video analytics. The library is designed to be user-friendly and efficient, making it suitable for both research and industrial projects.

ComfyUI
ComfyUI is a powerful and modular visual AI engine and application that allows users to design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface. It provides a user-friendly environment for creating complex Stable Diffusion workflows without the need for coding. ComfyUI supports various models for image editing, video processing, audio manipulation, 3D modeling, and more. It offers features like smart memory management, support for different GPU types, loading and saving workflows as JSON files, and offline functionality. Users can also use API nodes to access paid models from external providers through the online Comfy API.
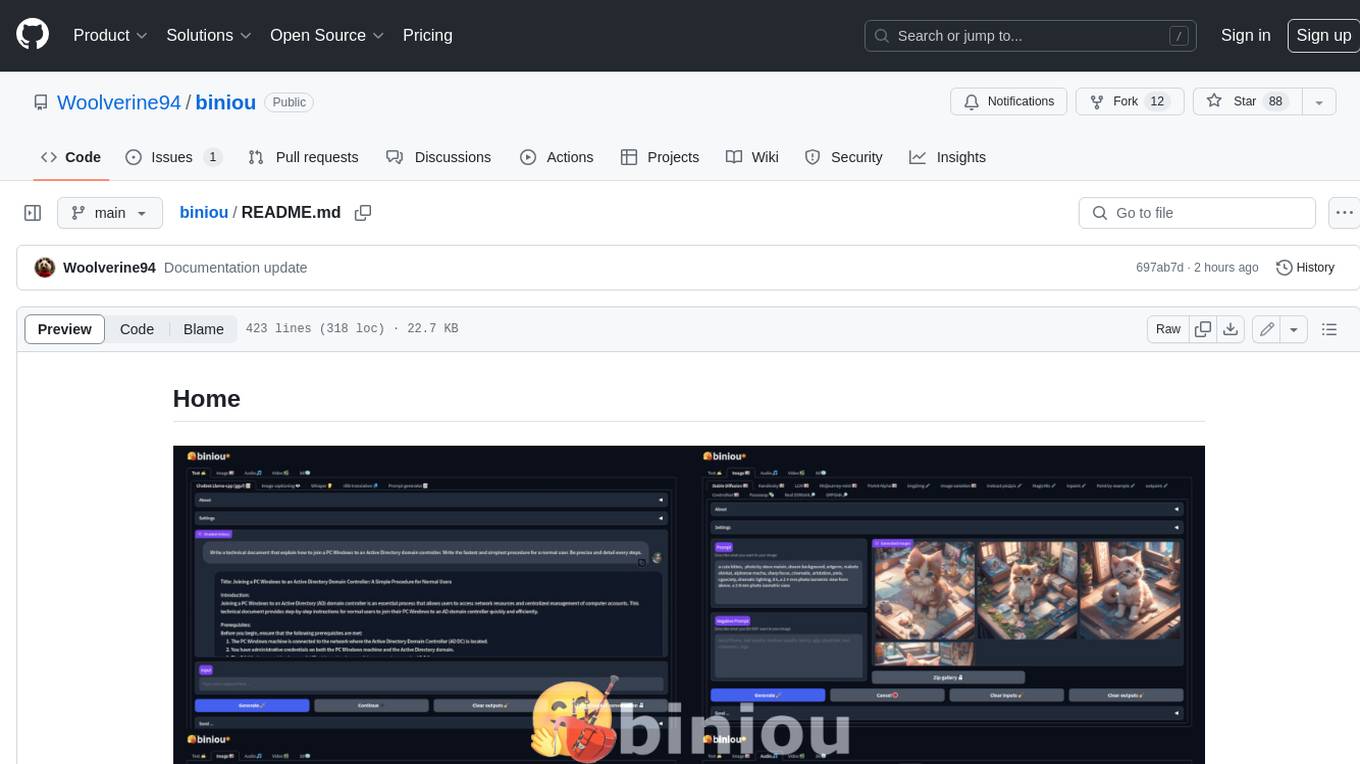
biniou
biniou is a self-hosted webui for various GenAI (generative artificial intelligence) tasks. It allows users to generate multimedia content using AI models and chatbots on their own computer, even without a dedicated GPU. The tool can work offline once deployed and required models are downloaded. It offers a wide range of features for text, image, audio, video, and 3D object generation and modification. Users can easily manage the tool through a control panel within the webui, with support for various operating systems and CUDA optimization. biniou is powered by Huggingface and Gradio, providing a cross-platform solution for AI content generation.
Azure-OpenAI-demos
Azure OpenAI demos is a repository showcasing various demos and use cases of Azure OpenAI services. It includes demos for tasks such as image comparisons, car damage copilot, video to checklist generation, automatic data visualization, text analytics, and more. The repository provides a wide range of examples on how to leverage Azure OpenAI for different applications and industries.
awesome-ai-painting
This repository, named 'awesome-ai-painting', is a comprehensive collection of resources related to AI painting. It is curated by a user named 秋风, who is an AI painting enthusiast with a background in the AIGC industry. The repository aims to help more people learn AI painting and also documents the user's goal of creating 100 AI products, with current progress at 4/100. The repository includes information on various AI painting products, tutorials, tools, and models, providing a valuable resource for individuals interested in AI painting and related technologies.

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.
Nexior
Nexior allows users to deploy their own AI application site in minutes, offering services like GPT, Midjourney, ChatDoc, QrArt, etc. Users can use the platform without any development experience, AI account purchases, API support concerns, or payment system configurations. It supports various features such as GPT 3.5/4.0, Midjourney modes, unlimited document uploads, artistic QR code generation, payment and referral systems, and user system support. Nexior is open source, free under the MIT license, and easy to configure and deploy.
ComfyUI-OllamaGemini
ComfyUI GeminiOllama Extension integrates Google's Gemini API, OpenAI (ChatGPT), Anthropic's Claude, Ollama, Qwen, and image processing tools into ComfyUI for leveraging powerful models and features directly within workflows. Features include multiple AI API integrations, advanced prompt engineering, Gemini image generation, background removal, SVG conversion, FLUX resolutions, ComfyUI Styler, smart prompt generator, and more. The extension offers comprehensive API integration, advanced prompt engineering with researched templates, high-quality tools like Smart Prompt Generator and BRIA RMBG, and supports video & audio processing. It provides a single interface to access powerful AI models, transform prompts into detailed instructions, and use various tools for image processing, styling, and content generation.
krita-ai-diffusion
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.
SwarmUI
SwarmUI is a modular stable diffusion web-user-interface designed to make powertools easily accessible, high performance, and extensible. It is in Beta status, offering a primary Generate tab for beginners and a Comfy Workflow tab for advanced users. The tool aims to become a full-featured one-stop-shop for all things Stable Diffusion, with plans for better mobile browser support, detailed 'Current Model' display, dynamic tab shifting, LLM-assisted prompting, and convenient direct distribution as an Electron app.

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.