
Pallaidium
PALLAIDIUM - a generative AI movie studio integrated in the Blender Video Editor.
Stars: 1086
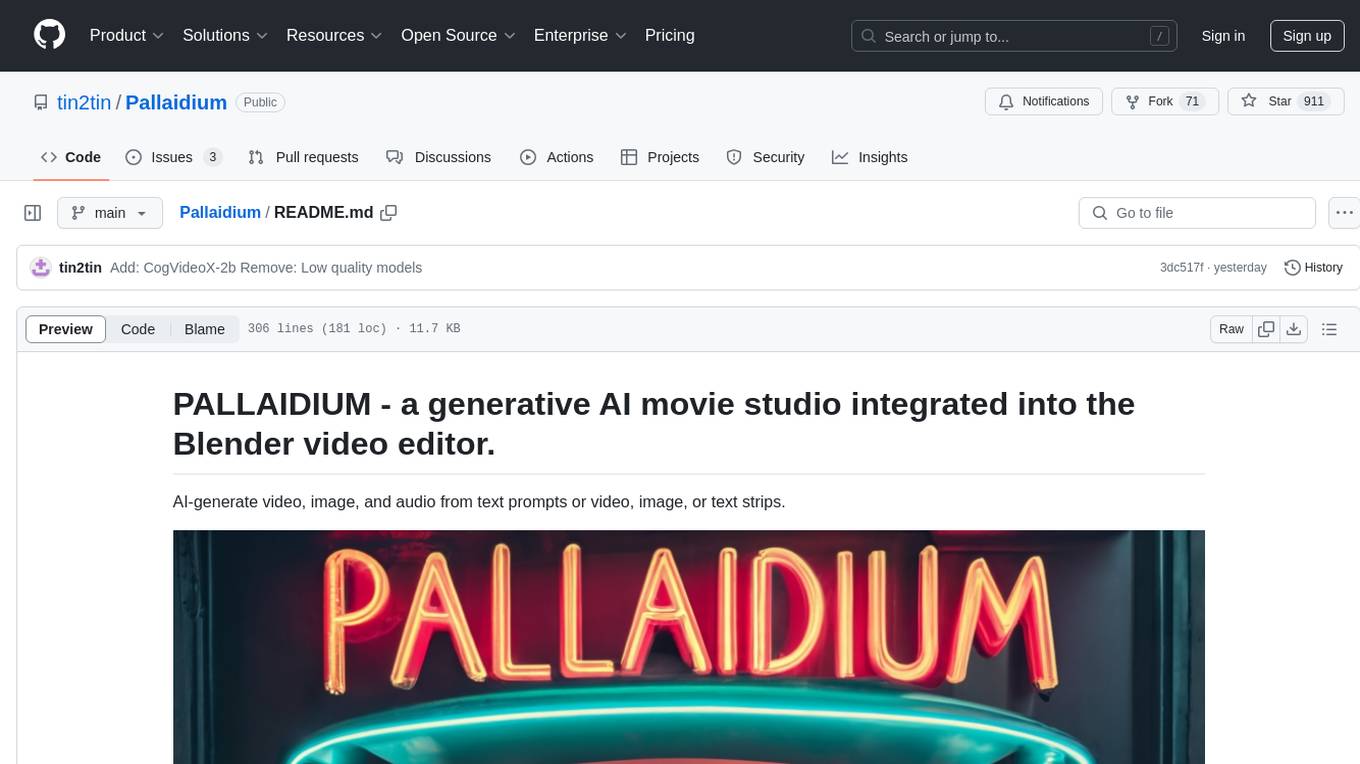
Pallaidium is a generative AI movie studio integrated into the Blender video editor. It allows users to AI-generate video, image, and audio from text prompts or existing media files. The tool provides various features such as text to video, text to audio, text to speech, text to image, image to image, image to video, video to video, image to text, and more. It requires a Windows system with a CUDA-supported Nvidia card and at least 6 GB VRAM. Pallaidium offers batch processing capabilities, text to audio conversion using Bark, and various performance optimization tips. Users can install the tool by downloading the add-on and following the installation instructions provided. The tool comes with a set of restrictions on usage, prohibiting the generation of harmful, pornographic, violent, or false content.
README:
[!WARNING] SCAM ALERT! Scammers are misusing our free software, Pallaidium, along with our content and name, on a phishing site: pallaidium . com. We are NOT associated with this site! 🚨 Please help us report this scam — otherwise, we may be forced to take down this GitHub repository.
A free generative AI movie studio integrated into the Blender Video Editor.

AI-generate video, image, and audio from text prompts or video, image, or text strips.
| Text to video | Text to image | Text to text |
| Text to speech | Text to audio | Text to music |
| Image to image | Image to video | Image to text |
| Video to video | Video to Image | Video to text |
| ControlNet | OpenPose | Canny |
| ADetailer | IP Adapter Face | IP Adapter Style |
| Multiple LoRAs | LoRA Weight | Style selector |
| Seed | Quality steps | Strip power |
| Frames (Duration) | Word power | Model card selector |
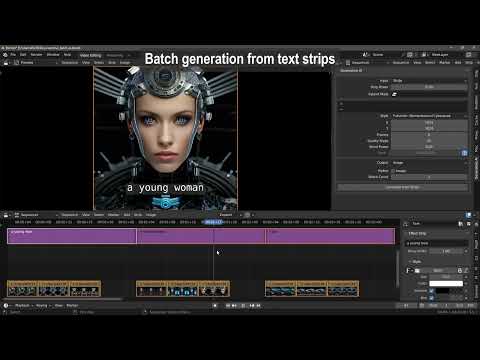
| Batch conversion | Batch refinement of images. | Prompt batching |
| Batch upscale & refinement of movies. | Render-to-path selector. | Render finished notification. |
| User-defined file path for generated files. | Seed and prompt added to strip name. | One-click install and uninstall dependencies. |
- Windows (Unsupported: Linux and MacOS).
- A CUDA-supported Nvidia card with at least 6 GB VRAM.
- CUDA: 12.4
- 20+ GB HDD. (Each model is 6+ GB).
For Mac and Linux, we'll have to rely on contributor support. So, post your issues here for Mac: https://github.com/tin2tin/Pallaidium/issues/106 and here for Linux: https://github.com/tin2tin/Pallaidium/issues/105, and hope some contributor wants to help you out.
-
First, download and install git (must be on PATH): https://git-scm.com/downloads
-
Download the add-on: https://github.com/tin2tin/text_to_video/archive/refs/heads/main.zip
-
On Windows, right-click on the Blender icon and "Run Blender as Administrator"(or you'll get write permission errors).
-
Install the add-on as usual: Preferences > Add-ons > Install > select file > enable the add-on.
-
In the Generative AI add-on preferences, hit the "Uninstall Dependencies" button (to clear out any incompatible libs).
-
Restart Blender via "Run as Administrator".
-
In the Generative AI add-on preferences, hit the "Install Dependencies" button.
-
Restart the computer and run Blender via "Run as Administrator".
-
Open the add-on UI in the Sequencer > Sidebar > Generative AI.
-
5-10 GB must be downloaded first the first time any model is executed.
| If any Python modules are missing, use this add-on to install them manually: |
|---|
| https://github.com/tin2tin/blender_pip |
| If "WARNING: Failed to find MSVC", install "Tools for Visual Studio": |
| https://aka.ms/vs/17/release/vs_BuildTools.exe |
Hugging Face Diffusers models are downloaded from the hub and saved to a local cache directory. Delete the folder manually:
On Linux and macOS: ~/.cache/huggingface/hub
On Windows: %userprofile%\.cache\huggingface\hub
- 2025-2-25: Add: MMAudio for Video to Sync Audio
- 2025-2-21: Support for Skywork/SkyReels-V1-Hunyuan-T2V/I2V. Need a full update of dependencies! (Thx newgenai79 for int4 transformer)
- 2025-2-15: Add: LoRA support for HunyuanVideo + better preset
- 2025-2-12: Add multi-media prompting via: OmniGen
- 2025-2-10: Update: a-r-r-o-w/LTX-Video-0.9.1-diffusers ZhengPeng7/BiRefNet_HR MiaoshouAI/Florence-2-large-PromptGen-v2.0 New: ostris/Flex.1-alpha Alpha-VLLM/Lumina-Image-2.0 Efficient-Large-Model/Sana_1600M_1024px_diffusers Fix: Frame by frame (SD XL) Remove: Corcelio/mobius
- 2025-1-26: Add: MiniMax Cloud txt/img/subject to video (insert your MiniMax API key in MiniMax_API.txt) and fast FLUX LoRA
- 2025-1-15: FLUX: faster img2img and inpaint
- 2024-11-2: Add: Image Background Removal, Stable Diffusion 3.5 Medium, Fast Flux(t2i)
- 2024-9-19: Add: Image to Video for CogVideoX
- 2024-9-15: Add: LoRA import for Flux
- 2024-9-14: Add: Flux Inpaint & Img2img.
- 2024-9-4: Add: Florence 2 (Image Caption), AudioLDM2-Large, CogVideox-2b, flash_attn on Win.
- 2024-9-2: Add: Vid2vid for CogVideoX-5b and Parler TTS
- 2024-8-28: Make CogVideox-5b run on 6 GB VRAM & Flux on 2 GB VRAM
- 2024-8-27: Add: CogVideoX-5b Remove: Low-quality models
- 2024-8-5: Add: Flux Dev - NB. needs update of dependencies and 24 GB VRAM
- 2024-8-2: Add: Flux Schnell - NB. needs update of dependencies and 24 GB VRAM
- 2024-7-12: Add: Kwai/Kolors (txt2img & img2img)
- 2024-6-13: Add: SD3 - A "Read" token from HuggingFace must be entered, it's free (img2img). Fix: Installation of Dependencies
- 2024-6-6: Add: Stable Audio Open, Frame:-1 will inherit duration.
- 2024-6-1: IP Adapter(When using SDXL): Face (Image or folder), Style (image or folder) New image models: Mobius, OpenVision, Juggernaut X Hyper
- 2024-4-29: Add: PixArt Sigma 2k, PixArt 1024 and RealViz V4
- 2024-2-23: Add: Proteus Lightning and Dreamshaper XL Lightning
- 2024-2-21: Add: SDXL-Lightning 2 Step & Proteus v. 0.3
- 2024-1-02: Add: WhisperSpeech
- 2024-01-01: Fix installation and Bark bugs.
- 2024-01-31: Add OpenDalle, Speed option, SDXL, and LoRA support for Canny and OpenPose, including OpenPose rig images. Prune old models including SD.
- 2023-12-18: Add: Bark audio enhance, Segmind Vega.
- 2023-12-1: Add SD Turbo & MusicGen Medium, MPS device for MacOS.
- 2023-11-30: Add: SVD, SVD-XT, SDXL Turbo
Install Dependencies, and set Sound Notification in the add-on preferences:
Video Sequence Editor > Sidebar > Generative AI:
See SDXL handling most of the styles here: https://stable-diffusion-art.com/sdxl-styles/
- If the image of your renders breaks, use the resolution from the Model Card in the Preferences.
- If the image of your playback stutters, then select a strip > Menu > Strip > Movie Strip > Set Render Size.
- If you get the message that CUDA is out of memory, restart Blender to free up memory and make it stable again.
- New to Blender? Watch this tutorial: https://youtu.be/4_MIaxzjh5Y?feature=shared
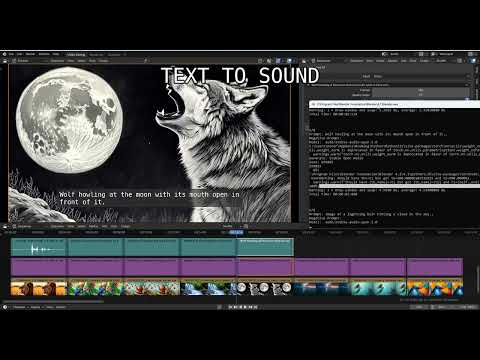
Select multiple strips and hit Generate. When doing this, the file name, and if found the seed value, are automatically inserted into the prompt and seed value. However, in the add-on preferences, this behavior can be switched off.
https://github.com/tin2tin/Pallaidium/assets/1322593/28098eb6-3a93-4bcb-bd6f-53b71faabd8d
Laura, Gary, Jon, Lea, Karen, Rick, Brenda, David, Eileen, Jordan, Mike, Yann, Joy, James, Eric, Lauren, Rose, Will, Jason, Aaron, Naomie, Alisa, Patrick, Jerry, Tina, Jenna, Bill, Tom, Carol, Barbara, Rebecca, Anna, Bruce, Emily
Find Bark documentation here: https://github.com/suno-ai/bark
- [laughter]
- [laughs]
- [sighs]
- [music]
- [gasps]
- [clears throat]
- — or ... for hesitations
- ♪ for song lyrics
- capitalization for emphasis on a word
- MAN/WOMAN: for bias towards the speaker
Speaker Library: https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c
| If the audio breaks up |
|---|
| Try processing longer sentences. |
Use GPT4ALL to generate image prompts or stories:
https://github.com/tin2tin/GPT4BLENDER
Convert text from the Text Editor to strips which can be used as prompts for batch generation.
https://github.com/tin2tin/text_to_strip
Edit, navigate, and i/o text strips.
https://github.com/tin2tin/Subtitle_Editor
For creating a mask on top of a clip in the Sequencer, this add-on can be used to input the clip as background in the Blender Image Editor. The created mask can then be added to the VSE as a strip, and converted to video with the above add-on:
https://github.com/tin2tin/vse_masking_tools
Since the Generative AI add-on can only input images or movie strips, you'll need to convert other strip types to movie-strip. For this purpose, this add-on can be used:
https://github.com/tin2tin/Add_Rendered_Strips
Disable System memory fallback: https://nvidia.custhelp.com/app/answers/detail/a_id/5490/~/system-memory-fallback-for-stable-diffusion
https://github.com/Nerogar/OneTrainer

https://github.com/tin2tin/Pallaidium/assets/1322593/91eb17e4-72d6-4c69-8e5c-a3d38af5a770
https://github.com/tin2tin/Pallaidium/assets/1322593/42eadfd8-3ebf-4747-b8e0-7b79fe8626b6
https://github.com/tin2tin/Pallaidium/assets/1322593/c74a4e38-8b16-423b-be78-aadfbfe284dc
https://github.com/tin2tin/Pallaidium/assets/1322593/b80812b4-e3be-40b0-a73b-bc55b7eeadf7
https://github.com/tin2tin/Pallaidium/assets/1322593/a1e94e09-0147-40ae-b4c2-4ce0671b1289
https://github.com/tin2tin/Pallaidium/assets/1322593/ac9f278e-9fc9-46fc-a4e7-562ff041964f




https://github.com/tin2tin/Generative_AI/assets/1322593/c044a0b0-95c2-4b54-af0b-45bc0c670c89
https://github.com/tin2tin/Generative_AI/assets/1322593/0105cd35-b3b2-49cf-91c1-0633dd484177
https://github.com/tin2tin/Generative_AI/assets/1322593/2dd2d2f1-a1f6-4562-8116-ffce872b79c3
https://github.com/tin2tin/Generative_AI/assets/1322593/7cd69cd0-5842-40f0-b41f-455c77443535
- The team behind Pallaidium does not endorse or take responsibility for third-party use.
- The team behind Pallaidium requires verification or explicit permission for redistribution.
- It is prohibited to use Pallaidium to generate content that is demeaning or harmful to people, their environment, culture, religion, etc.
- It is prohibited to use Pallaidium for pornographic, violent, and bloody content generation.
- It is prohibited to use Pallaidium for error and false information generation.
- It is prohibited to use Pallaidium for commercial misuse or misrepresentation.
- Pallaidium does not include any genAI models(weights). If the user decides to use a model, it is downloaded from HuggingFace.
- In general, the models can only be used for non-commercial purposes and are meant for research purposes.
- Consult the individual models on HuggingFace to read up on their licenses and ex. if they can be used commercially.
- The Diffusers lib makes the following weights accessible through the Pallaidium UI:
- SkyReels-V1-Hunyuan-I2V/T2V
- HunyuanVideo
- Lightricks/LTX-Video
- stabilityai/stable-video-diffusion-img2vid-xt
- stabilityai/stable-video-diffusion-img2vid
- THUDM/CogVideoX-5b
- cerspense/zeroscope_v2_XL
- stabilityai/stable-diffusion-xl-base-1.0
- ByteDance/SDXL-Lightning
- stabilityai/stable-diffusion-3-medium-diffusers
- black-forest-labs/FLUX.1-schnell
- black-forest-labs/FLUX.1-dev
- fluently/Fluently-XL-Final
- shuttleai/shuttle-jaguar
- Tencent-Hunyuan/HunyuanDiT-v1.2-Diffusers
- Kwai-Kolors/Kolors-diffusers
- dataautogpt3/OpenDalleV1.1
- PixArt-alpha/PixArt-Sigma_16bit
- PixArt-alpha/PixArt-Sigma_2k_16bit
- dataautogpt3/ProteusV0.4
- SG161222/RealVisXL_V4.0
- Salesforce/blipdiffusion
- diffusers/controlnet-canny-sdxl-1.0-small
- xinsir/controlnet-openpose-sdxl-1.0
- xinsir/controlnet-scribble-sdxl-1.0
- ZhengPeng7/BiRefNet
- Flex
- Lumina 2
- Sana
- OmniGen
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Pallaidium
Similar Open Source Tools
Pallaidium
Pallaidium is a generative AI movie studio integrated into the Blender video editor. It allows users to AI-generate video, image, and audio from text prompts or existing media files. The tool provides various features such as text to video, text to audio, text to speech, text to image, image to image, image to video, video to video, image to text, and more. It requires a Windows system with a CUDA-supported Nvidia card and at least 6 GB VRAM. Pallaidium offers batch processing capabilities, text to audio conversion using Bark, and various performance optimization tips. Users can install the tool by downloading the add-on and following the installation instructions provided. The tool comes with a set of restrictions on usage, prohibiting the generation of harmful, pornographic, violent, or false content.
comfyui_prompt_assistant
ComfyUI Prompt Assistant is a plugin that enables prompt word translation, expansion, preset tag insertion, image reverse prompt words, and history record functions without adding nodes. It offers features like UI optimization, avoiding scroll bar overlap, tag popup window scrollbar fix, and more. Users can manually install the latest version from the Releases section. The tool supports various functionalities like image reverse, Kontext presets, translation nodes, and custom rules. It also provides features for tag insertion, LLM expansion, translation switching between Baidu and LLM, and history management.
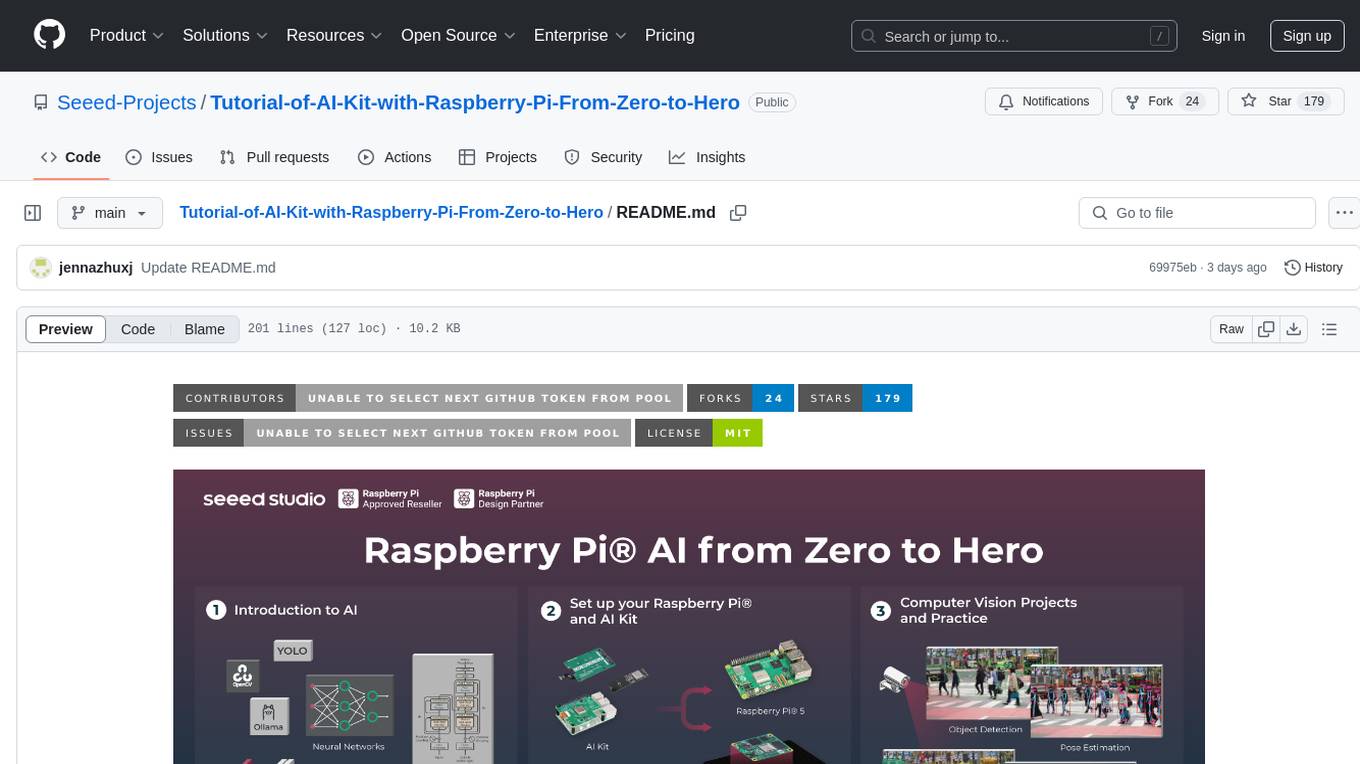
Tutorial-of-AI-Kit-with-Raspberry-Pi-From-Zero-to-Hero
This course is designed to teach you how to harness the power of AI on the Raspberry Pi, with a focus on using an AI kit for computer vision tasks. Learn to integrate AI into IoT applications, from object detection to visual recognition. Suitable for hobbyists, students, and professionals to bring AI-driven solutions to life on resource-constrained devices like the Raspberry Pi.
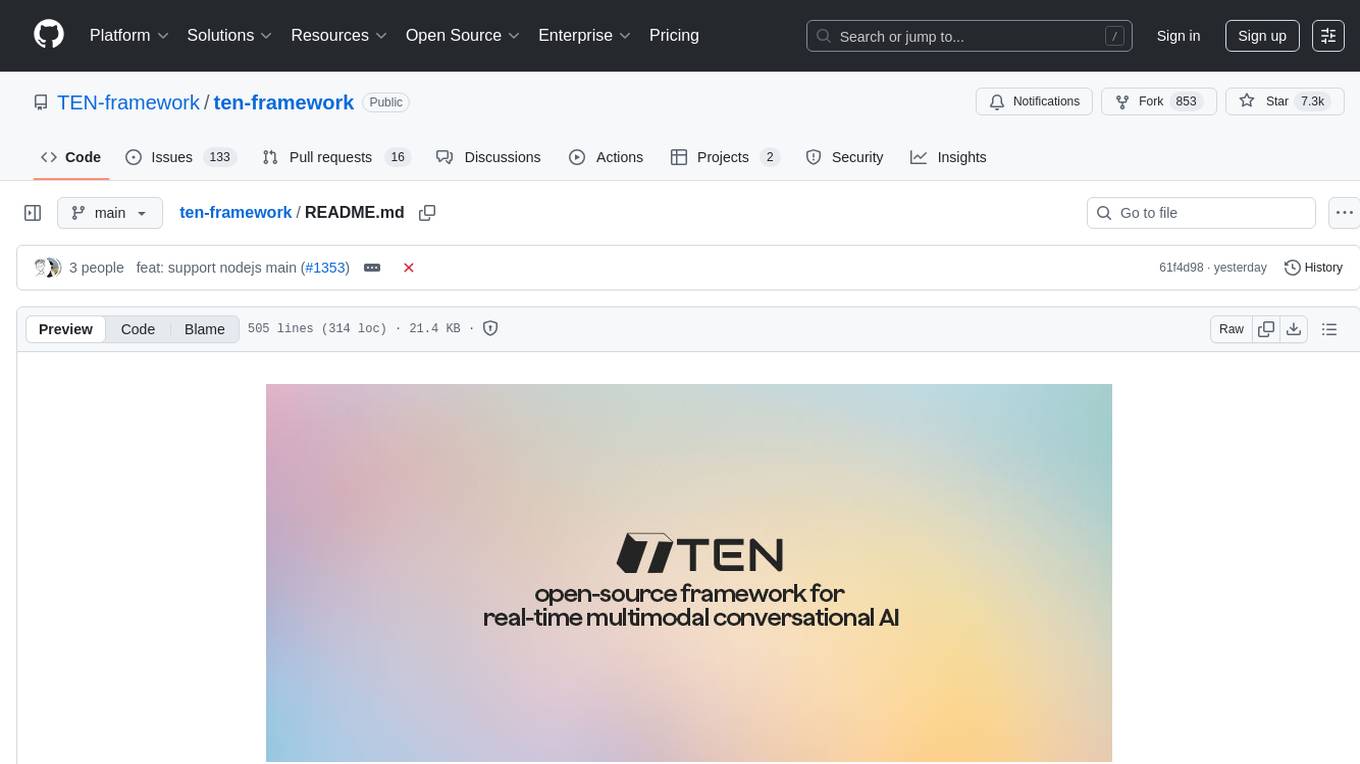
ten-framework
TEN is an open-source ecosystem for creating, customizing, and deploying real-time conversational AI agents with multimodal capabilities including voice, vision, and avatar interactions. It includes various components like TEN Framework, TEN Turn Detection, TEN VAD, TEN Agent, TMAN Designer, and TEN Portal. Users can follow the provided guidelines to set up and customize their agents using TMAN Designer, run them locally or in Codespace, and deploy them with Docker or other cloud services. The ecosystem also offers community channels for developers to connect, contribute, and get support.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.

Open-Sora-Plan
Open-Sora-Plan is a project that aims to create a simple and scalable repo to reproduce Sora (OpenAI, but we prefer to call it "ClosedAI"). The project is still in its early stages, but the team is working hard to improve it and make it more accessible to the open-source community. The project is currently focused on training an unconditional model on a landscape dataset, but the team plans to expand the scope of the project in the future to include text2video experiments, training on video2text datasets, and controlling the model with more conditions.
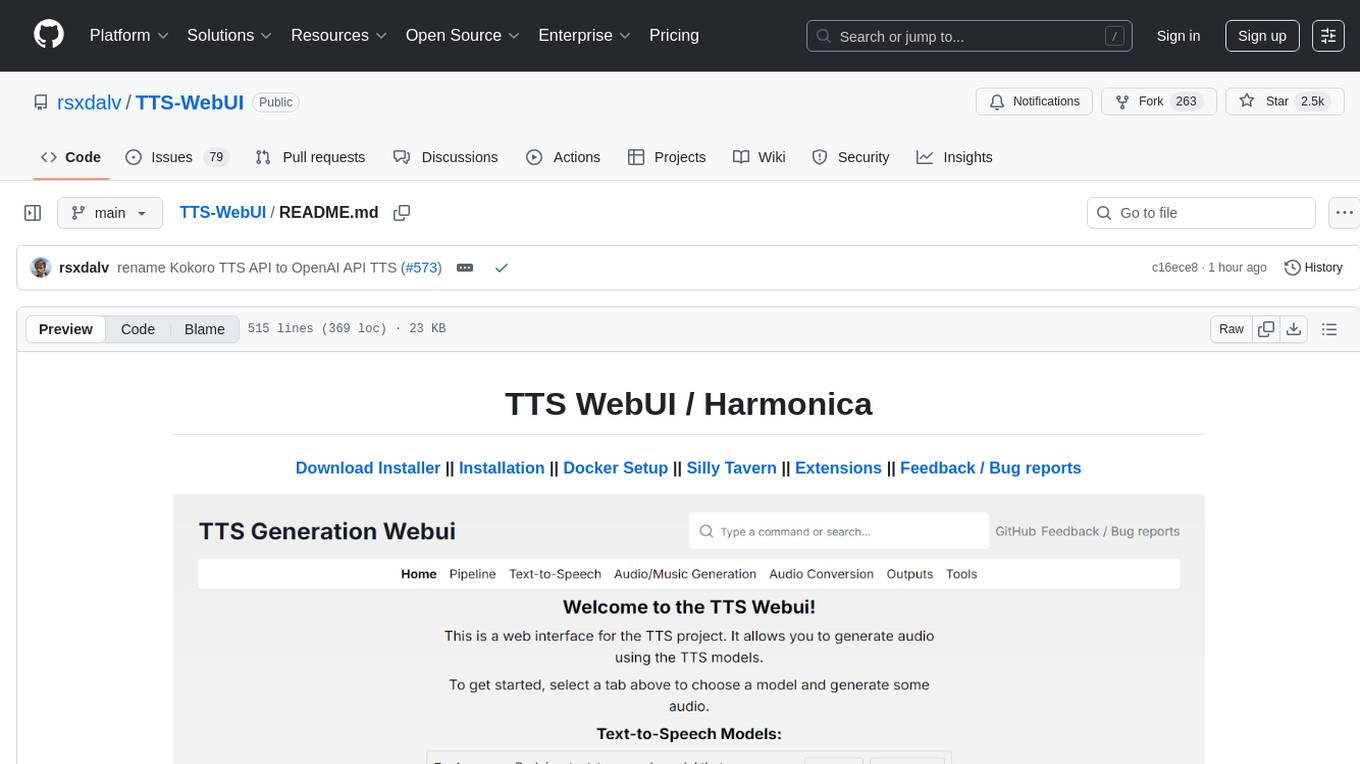
TTS-WebUI
TTS WebUI is a comprehensive tool for text-to-speech synthesis, audio/music generation, and audio conversion. It offers a user-friendly interface for various AI projects related to voice and audio processing. The tool provides a range of models and extensions for different tasks, along with integrations like Silly Tavern and OpenWebUI. With support for Docker setup and compatibility with Linux and Windows, TTS WebUI aims to facilitate creative and responsible use of AI technologies in a user-friendly manner.

LLaVA-pp
This repository, LLaVA++, extends the visual capabilities of the LLaVA 1.5 model by incorporating the latest LLMs, Phi-3 Mini Instruct 3.8B, and LLaMA-3 Instruct 8B. It provides various models for instruction-following LMMS and academic-task-oriented datasets, along with training scripts for Phi-3-V and LLaMA-3-V. The repository also includes installation instructions and acknowledgments to related open-source contributions.
ComfyUI-BRIA_AI-RMBG
ComfyUI-BRIA_AI-RMBG is an unofficial implementation of the BRIA Background Removal v1.4 model for ComfyUI. The tool supports batch processing, including video background removal, and introduces a new mask output feature. Users can install the tool using ComfyUI Manager or manually by cloning the repository. The tool includes nodes for automatically loading the Removal v1.4 model and removing backgrounds. Updates include support for batch processing and the addition of a mask output feature.
ST-LLM
ST-LLM is a temporal-sensitive video large language model that incorporates joint spatial-temporal modeling, dynamic masking strategy, and global-local input module for effective video understanding. It has achieved state-of-the-art results on various video benchmarks. The repository provides code and weights for the model, along with demo scripts for easy usage. Users can train, validate, and use the model for tasks like video description, action identification, and reasoning.

Awesome-LLM
Awesome-LLM is a curated list of resources related to large language models, focusing on papers, projects, frameworks, tools, tutorials, courses, opinions, and other useful resources in the field. It covers trending LLM projects, milestone papers, other papers, open LLM projects, LLM training frameworks, LLM evaluation frameworks, tools for deploying LLM, prompting libraries & tools, tutorials, courses, books, and opinions. The repository provides a comprehensive overview of the latest advancements and resources in the field of large language models.

UMOE-Scaling-Unified-Multimodal-LLMs
Uni-MoE is a MoE-based unified multimodal model that can handle diverse modalities including audio, speech, image, text, and video. The project focuses on scaling Unified Multimodal LLMs with a Mixture of Experts framework. It offers enhanced functionality for training across multiple nodes and GPUs, as well as parallel processing at both the expert and modality levels. The model architecture involves three training stages: building connectors for multimodal understanding, developing modality-specific experts, and incorporating multiple trained experts into LLMs using the LoRA technique on mixed multimodal data. The tool provides instructions for installation, weights organization, inference, training, and evaluation on various datasets.
KB-Builder
KB Builder is an open-source knowledge base generation system based on the LLM large language model. It utilizes the RAG (Retrieval-Augmented Generation) data generation enhancement method to provide users with the ability to enhance knowledge generation and quickly build knowledge bases based on RAG. It aims to be the central hub for knowledge construction in enterprises, offering platform-based intelligent dialogue services and document knowledge base management functionality. Users can upload docx, pdf, txt, and md format documents and generate high-quality knowledge base question-answer pairs by invoking large models through the 'Parse Document' feature.

Folo
Folo is a content organization tool that creates a noise-free timeline for users. It allows sharing lists, exploring collections, and distraction-free browsing. Users can subscribe to feeds, curate favorites, and utilize AI-powered features like translation and summaries. Folo supports various content types such as articles, videos, images, and audio. It introduces an ownership economy with $POWER tipping for creators and fosters a community-driven experience. The tool is under active development, welcoming feedback from users and developers.
TEN-Agent
TEN Agent is an open-source multimodal agent powered by the world’s first real-time multimodal framework, TEN Framework. It offers high-performance real-time multimodal interactions, multi-language and multi-platform support, edge-cloud integration, flexibility beyond model limitations, and real-time agent state management. Users can easily build complex AI applications through drag-and-drop programming, integrating audio-visual tools, databases, RAG, and more.
For similar tasks
ComfyUI-BlenderAI-node
ComfyUI-BlenderAI-node is an addon for Blender that allows users to convert ComfyUI nodes into Blender nodes seamlessly. It offers features such as converting nodes, editing launch arguments, drawing masks with Grease pencil, and more. Users can queue batch processing, use node tree presets, and model preview images. The addon enables users to input or replace 3D models in Blender and output controlnet images using composite. It provides a workflow showcase with presets for camera input, AI-generated mesh import, composite depth channel, character bone editing, and more.
Pallaidium
Pallaidium is a generative AI movie studio integrated into the Blender video editor. It allows users to AI-generate video, image, and audio from text prompts or existing media files. The tool provides various features such as text to video, text to audio, text to speech, text to image, image to image, image to video, video to video, image to text, and more. It requires a Windows system with a CUDA-supported Nvidia card and at least 6 GB VRAM. Pallaidium offers batch processing capabilities, text to audio conversion using Bark, and various performance optimization tips. Users can install the tool by downloading the add-on and following the installation instructions provided. The tool comes with a set of restrictions on usage, prohibiting the generation of harmful, pornographic, violent, or false content.
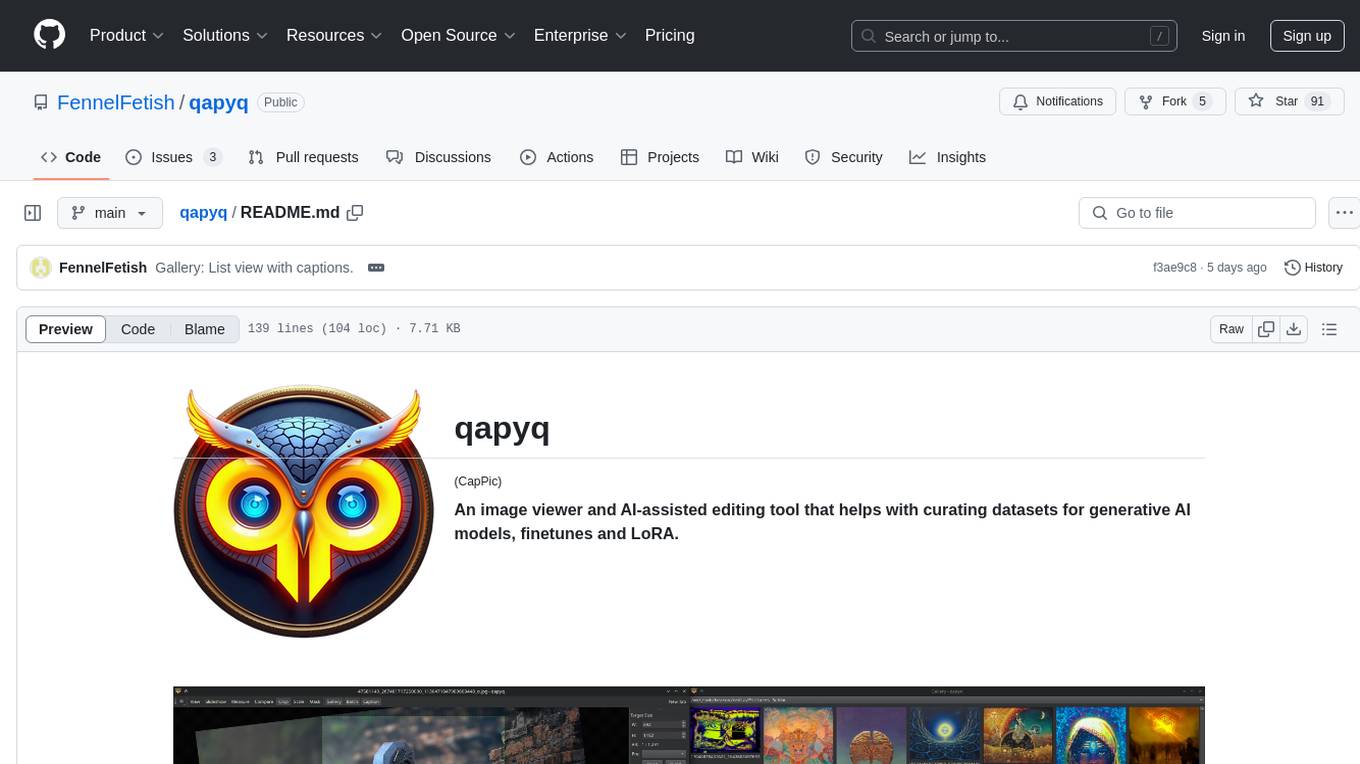
qapyq
qapyq is an image viewer and AI-assisted editing tool designed to help curate datasets for generative AI models. It offers features such as image viewing, editing, captioning, batch processing, and AI assistance. Users can perform tasks like cropping, scaling, editing masks, tagging, and applying sorting and filtering rules. The tool supports state-of-the-art captioning and masking models, with options for model settings, GPU acceleration, and quantization. qapyq aims to streamline the process of preparing images for training AI models by providing a user-friendly interface and advanced functionalities.

wunjo.wladradchenko.ru
Wunjo AI is a comprehensive tool that empowers users to explore the realm of speech synthesis, deepfake animations, video-to-video transformations, and more. Its user-friendly interface and privacy-first approach make it accessible to both beginners and professionals alike. With Wunjo AI, you can effortlessly convert text into human-like speech, clone voices from audio files, create multi-dialogues with distinct voice profiles, and perform real-time speech recognition. Additionally, you can animate faces using just one photo combined with audio, swap faces in videos, GIFs, and photos, and even remove unwanted objects or enhance the quality of your deepfakes using the AI Retouch Tool. Wunjo AI is an all-in-one solution for your voice and visual AI needs, offering endless possibilities for creativity and expression.

airunner
AI Runner is a multi-modal AI interface that allows users to run open-source large language models and AI image generators on their own hardware. The tool provides features such as voice-based chatbot conversations, text-to-speech, speech-to-text, vision-to-text, text generation with large language models, image generation capabilities, image manipulation tools, utility functions, and more. It aims to provide a stable and user-friendly experience with security updates, a new UI, and a streamlined installation process. The application is designed to run offline on users' hardware without relying on a web server, offering a smooth and responsive user experience.
Wechat-AI-Assistant
Wechat AI Assistant is a project that enables multi-modal interaction with ChatGPT AI assistant within WeChat. It allows users to engage in conversations, role-playing, respond to voice messages, analyze images and videos, summarize articles and web links, and search the internet. The project utilizes the WeChatFerry library to control the Windows PC desktop WeChat client and leverages the OpenAI Assistant API for intelligent multi-modal message processing. Users can interact with ChatGPT AI in WeChat through text or voice, access various tools like bing_search, browse_link, image_to_text, text_to_image, text_to_speech, video_analysis, and more. The AI autonomously determines which code interpreter and external tools to use to complete tasks. Future developments include file uploads for AI to reference content, integration with other APIs, and login support for enterprise WeChat and WeChat official accounts.
Generative-AI-Pharmacist
Generative AI Pharmacist is a project showcasing the use of generative AI tools to create an animated avatar named Macy, who delivers medication counseling in a realistic and professional manner. The project utilizes tools like Midjourney for image generation, ChatGPT for text generation, ElevenLabs for text-to-speech conversion, and D-ID for creating a photorealistic talking avatar video. The demo video featuring Macy discussing commonly-prescribed medications demonstrates the potential of generative AI in healthcare communication.
AnyGPT
AnyGPT is a unified multimodal language model that utilizes discrete representations for processing various modalities like speech, text, images, and music. It aligns the modalities for intermodal conversions and text processing. AnyInstruct dataset is constructed for generative models. The model proposes a generative training scheme using Next Token Prediction task for training on a Large Language Model (LLM). It aims to compress vast multimodal data on the internet into a single model for emerging capabilities. The tool supports tasks like text-to-image, image captioning, ASR, TTS, text-to-music, and music captioning.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.