
Awesome-LLM-Reasoning-Openai-o1-Survey
The related works and background techniques about Openai o1
Stars: 184
The repository 'Awesome LLM Reasoning Openai-o1 Survey' provides a collection of survey papers and related works on OpenAI o1, focusing on topics such as LLM reasoning, self-play reinforcement learning, complex logic reasoning, and scaling law. It includes papers from various institutions and researchers, showcasing advancements in reasoning bootstrapping, reasoning scaling law, self-play learning, step-wise and process-based optimization, and applications beyond math. The repository serves as a valuable resource for researchers interested in exploring the intersection of language models and reasoning techniques.
README:



The related works and background techniques about OpenAI o1, including LLM reasoning, self-play reinforcement learning, complex logic reasoning, scaling law, etc.
-
A Survey on Self-play Methods in Reinforcement Learning [Paper] (2024)
- Ruize Zhang, Zelai Xu, Chengdong Ma, Chao Yu, Wei-Wei Tu, Shiyu Huang, Deheng Ye, Wenbo Ding, Yaodong Yang, Yu Wang
- Tencent, Tsinghua
-
Generative Language Modeling for Automated Theorem Proving [Paper] (2020)
- Stanislas Polu, Ilya Sutskever
- OpenAI
-
Hypothesis Search: Inductive Reasoning with Language Models [Paper] (ICLR 2024)
- Ruocheng Wang, Eric Zelikman, Gabriel Poesia, Yewen Pu, Nick Haber, Noah D. Goodman
- Stanford, Autodesk Research
-
Phenomenal Yet Puzzling: Testing Inductive Reasoning Capabilities of Language Models with Hypothesis Refinement [Paper] (ICLR 2024)
- Linlu Qiu, Liwei Jiang, Ximing Lu, Melanie Sclar, Valentina Pyatkin, Chandra Bhagavatula, Bailin Wang, Yoon Kim, Yejin Choi, Nouha Dziri, Xiang Ren
- MIT, Allen AI, UW, USC
-
Training Verifiers to Solve Math Word Problems [Paper] (2021)
- Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, John Schulman
- OpenAI
-
To CoT or not to CoT? Chain-of-thought Helps Mainly on Math and Symbolic Reasoning [Paper] (2024.9)
- Zayne Sprague, Fangcong Yin, Juan Diego Rodriguez, Dongwei Jiang, Manya Wadhwa, Prasann Singhal, Xinyu Zhao, Xi Ye, Kyle Mahowald, Greg Durrett
- The University of Texas at Austin, Johns Hopkins University, Princeton University
-
STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning [Paper] [Github] (NeurIPS 2022)
- Eric Zelikman, Yuhuai Wu, Jesse Mu, Noah D. Goodman
- Stanford, Google
-
Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking [Paper] [Github] (2022)
- Eric Zelikman, Georges Harik, Yijia Shao, Varuna Jayasiri, Nick Haber, Noah D. Goodman
- Stanford, Notbad AI
-
Training Chain-of-thought via Latent-variable Inference [Paper] (NeurIPS 2023)
- Du Phan, Matthew D. Hoffman, David Dohan, Sholto Douglas, Tuan Anh Le, Aaron Parisi, Pavel Sountsov, Charles Sutton, Sharad Vikram, Rif A. Saurous
-
Chain-of-thought Reasoning without Prompting [Paper] (2024)
- Xuezhi Wang, Denny Zhou
- Google DeepMind
-
Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers [Paper] [Github] (2024)
- Zhenting Qi, Mingyuan Ma, Jiahang Xu, Li Lyna Zhang, Fan Yang, Mao Yang
- MSRA, Harvard University
-
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling [Paper] (2024)
- Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V. Le, Christopher Ré, Azalia Mirhoseini
- Stanford, Oxford, Google DeepMind
-
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters [Paper] (2024)
- Charlie Snell, Jaehoon Lee, Kelvin Xu, Aviral Kumar
- UC Berkeley, Google DeepMind
-
An Empirical Analysis of Compute-Optimal Inference for Problem-Solving with Language Models [Paper] (2024)
- Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, Yiming Yang
- Tsinghua, CMU
-
Training Language Models to Self-Correct via Reinforcement Learning [Paper] (2024)
- Evan Wang, Federico Cassano, Catherine Wu, Yunfeng Bai, Will Song, Vaskar Nath, Ziwen Han, Sean Hendryx, Summer Yue, Hugh Zhang
- Google DeepMind
-
From Medprompt to o1: Exploration of Run-Time Strategies for Medical Challenge Problems and Beyond [[https://arxiv.org/abs/2411.03590]] (2024)
- Harsha Nori, Naoto Usuyama, Nicholas King, Scott Mayer McKinney, Xavier Fernandes, Sheng Zhang, Eric Horvitz
- Microsoft, OpenAI
-
Mastering Chess and Shogi by Self-play with a General Reinforcement Learning Algorithm [Paper] (2017)
- David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez,Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy Lillicrap, Karen Simonyan, Demis Hassabis
- Google DeepMind
-
Language Models Can Teach Themselves to Program Better [Paper] [Github] (ICLR 2023)
- Patrick Haluptzok, Matthew Bowers, Adam Tauman Kalai
- Microsoft Research, MIT
-
Large Language Models Can Self-Improve [Paper]
- Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, Jiawei Han
- University of Illinois at Urbana-Champaign, Google
-
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models [Paper] [Github] (ICML 2024)
- Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, Quanquan Gu
- UCLA
-
Self-Play Preference Optimization for Language Model Alignment [Paper] [Github] (2024)
- Yue Wu, Zhiqing Sun, Huizhuo Yuan, Kaixuan Ji, Yiming Yang, Quanquan Gu
- UCLA
-
Scalable Online Planning via Reinforcement Learning Fine-Tuning [Paper] (NeurIPS 2021)
- Arnaud Fickinger, Hengyuan Hu, Brandon Amos, Stuart Russell, Noam Brown
-
Generative Verifiers: Reward Modeling as Next-Token Prediction [Paper] (2024)
- Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, Rishabh Agarwal
- Google DeepMind
-
Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B [Paper] (2024)
- Di Zhang, Xiaoshui Huang, Dongzhan Zhou, Yuqiang Li, Wanli Ouyang
- Fudan University, Shanghai AI Lab
-
Interpretable Contrastive Monte Carlo Tree Search Reasoning [Paper] (2024)
- Zitian Gao, Boye Niu, Xuzheng He, Haotian Xu, Hongzhang Liu, Aiwei Liu, Xuming Hu, Lijie Wen
- The University of Sydney, Peking University, Xiaohongshu, Shanghai AI Lab, Tsinghua, HKUST
-
Solving Math Word Problems with Process-and Outcome-based Feedback [Paper] (2022)
- Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia, Creswell, Geoffrey Irving, Irina Higgins
- Google DeepMind
-
Thinking Fast and Slow With Deep Learning and Tree Search [Paper] (NeurIPS 2017)
- Thomas Anthony, Zheng Tian, David Barber
- University College Londo, Alen
-
Let’s Verify Step by Step [Paper] (2023)
- Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, Karl Cobbe
- OpenAI
-
OVM, Outcome-supervised Value Models for Planning in Mathematical Reasoning [Paper] (Findings of NAACL 2024)
- Fei Yu, Anningzhe Gao, Benyou Wang
- The Chinese University of Hong Kong, Shenzhen (CUHKSZ) & Shenzhen Research Insitute of Big Data (SRIBD)
-
LLM Critics Help Catch LLM Bugs [Paper] (2024)
- Nat McAleese, Rai Michael Pokorny, Juan Felipe Ceron Uribe, Evgenia Nitishinskaya, Maja Trebacz, Jan Leike
- OpenAI
-
Self-critiquing Models for Assisting Human Evaluators [Paper] (2022)
- William Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, Jan Leike
- OpenAI
-
Improve Mathematical Reasoning in Language Models by Automated Process Supervision [Paper] (2024)
- Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, Abhinav Rastogi
- Google DeepMind
-
Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning [Paper] (2024)
- Chaojie Wang, Yanchen Deng, Zhiyi Lyu, Liang Zeng, Jujie He, Shuicheng Yan, Bo An
- Skywork AI, NTU
-
Math-shepherd: Verify and Reinforce LLMs step-by-step without Human Annotations [Paper] (ACL 2024)
- Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, Zhifang Sui
- Peking University, DeepSeek AI, HKU, Tsinghua University, The Ohio State University
-
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs [Paper] (2024)
- Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, Jianye Hou, Benyou Wang
- The Chinese University of Hong Kong, Shenzhen (CUHKSZ)
-
o1-Coder: an o1 Replication for Coding [Paper] (2024)
- Yuxiang Zhang, Shangxi Wu, Yuqi Yang, Jiangming Shu, Jinlin Xiao, Chao Kong, Jitao Sang
- Beijing Jiaotong University
We welcome every researcher who contributes to this repository.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Awesome-LLM-Reasoning-Openai-o1-Survey
Similar Open Source Tools
Awesome-LLM-Reasoning-Openai-o1-Survey
The repository 'Awesome LLM Reasoning Openai-o1 Survey' provides a collection of survey papers and related works on OpenAI o1, focusing on topics such as LLM reasoning, self-play reinforcement learning, complex logic reasoning, and scaling law. It includes papers from various institutions and researchers, showcasing advancements in reasoning bootstrapping, reasoning scaling law, self-play learning, step-wise and process-based optimization, and applications beyond math. The repository serves as a valuable resource for researchers interested in exploring the intersection of language models and reasoning techniques.

Awesome-LLM-Preference-Learning
The repository 'Awesome-LLM-Preference-Learning' is the official repository of a survey paper titled 'Towards a Unified View of Preference Learning for Large Language Models: A Survey'. It contains a curated list of papers related to preference learning for Large Language Models (LLMs). The repository covers various aspects of preference learning, including on-policy and off-policy methods, feedback mechanisms, reward models, algorithms, evaluation techniques, and more. The papers included in the repository explore different approaches to aligning LLMs with human preferences, improving mathematical reasoning in LLMs, enhancing code generation, and optimizing language model performance.
awesome-open-ended
A curated list of open-ended learning AI resources focusing on algorithms that invent new and complex tasks endlessly, inspired by human advancements. The repository includes papers, safety considerations, surveys, perspectives, and blog posts related to open-ended AI research.
Prompt4ReasoningPapers
Prompt4ReasoningPapers is a repository dedicated to reasoning with language model prompting. It provides a comprehensive survey of cutting-edge research on reasoning abilities with language models. The repository includes papers, methods, analysis, resources, and tools related to reasoning tasks. It aims to support various real-world applications such as medical diagnosis, negotiation, etc.
awesome-llm-role-playing-with-persona
Awesome-llm-role-playing-with-persona is a curated list of resources for large language models for role-playing with assigned personas. It includes papers and resources related to persona-based dialogue systems, personalized response generation, psychology of LLMs, biases in LLMs, and more. The repository aims to provide a comprehensive collection of research papers and tools for exploring role-playing abilities of large language models in various contexts.

Awesome-LLM-Reasoning
**Curated collection of papers and resources on how to unlock the reasoning ability of LLMs and MLLMs.** **Description in less than 400 words, no line breaks and quotation marks.** Large Language Models (LLMs) have revolutionized the NLP landscape, showing improved performance and sample efficiency over smaller models. However, increasing model size alone has not proved sufficient for high performance on challenging reasoning tasks, such as solving arithmetic or commonsense problems. This curated collection of papers and resources presents the latest advancements in unlocking the reasoning abilities of LLMs and Multimodal LLMs (MLLMs). It covers various techniques, benchmarks, and applications, providing a comprehensive overview of the field. **5 jobs suitable for this tool, in lowercase letters.** - content writer - researcher - data analyst - software engineer - product manager **Keywords of the tool, in lowercase letters.** - llm - reasoning - multimodal - chain-of-thought - prompt engineering **5 specific tasks user can use this tool to do, in less than 3 words, Verb + noun form, in daily spoken language.** - write a story - answer a question - translate a language - generate code - summarize a document

Awesome-LLM-RAG
This repository, Awesome-LLM-RAG, aims to record advanced papers on Retrieval Augmented Generation (RAG) in Large Language Models (LLMs). It serves as a resource hub for researchers interested in promoting their work related to LLM RAG by updating paper information through pull requests. The repository covers various topics such as workshops, tutorials, papers, surveys, benchmarks, retrieval-enhanced LLMs, RAG instruction tuning, RAG in-context learning, RAG embeddings, RAG simulators, RAG search, RAG long-text and memory, RAG evaluation, RAG optimization, and RAG applications.

llm-self-correction-papers
This repository contains a curated list of papers focusing on the self-correction of large language models (LLMs) during inference. It covers various frameworks for self-correction, including intrinsic self-correction, self-correction with external tools, self-correction with information retrieval, and self-correction with training designed specifically for self-correction. The list includes survey papers, negative results, and frameworks utilizing reinforcement learning and OpenAI o1-like approaches. Contributions are welcome through pull requests following a specific format.

awesome-generative-information-retrieval
This repository contains a curated list of resources on generative information retrieval, including research papers, datasets, tools, and applications. Generative information retrieval is a subfield of information retrieval that uses generative models to generate new documents or passages of text that are relevant to a given query. This can be useful for a variety of tasks, such as question answering, summarization, and document generation. The resources in this repository are intended to help researchers and practitioners stay up-to-date on the latest advances in generative information retrieval.
LLMAgentPapers
LLM Agents Papers is a repository containing must-read papers on Large Language Model Agents. It covers a wide range of topics related to language model agents, including interactive natural language processing, large language model-based autonomous agents, personality traits in large language models, memory enhancements, planning capabilities, tool use, multi-agent communication, and more. The repository also provides resources such as benchmarks, types of tools, and a tool list for building and evaluating language model agents. Contributors are encouraged to add important works to the repository.


awesome-large-audio-models
This repository is a curated list of awesome large AI models in audio signal processing, focusing on the application of large language models to audio tasks. It includes survey papers, popular large audio models, automatic speech recognition, neural speech synthesis, speech translation, other speech applications, large audio models in music, and audio datasets. The repository aims to provide a comprehensive overview of recent advancements and challenges in applying large language models to audio signal processing, showcasing the efficacy of transformer-based architectures in various audio tasks.
For similar tasks
Awesome-LLM-Reasoning-Openai-o1-Survey
The repository 'Awesome LLM Reasoning Openai-o1 Survey' provides a collection of survey papers and related works on OpenAI o1, focusing on topics such as LLM reasoning, self-play reinforcement learning, complex logic reasoning, and scaling law. It includes papers from various institutions and researchers, showcasing advancements in reasoning bootstrapping, reasoning scaling law, self-play learning, step-wise and process-based optimization, and applications beyond math. The repository serves as a valuable resource for researchers interested in exploring the intersection of language models and reasoning techniques.
awesome-rag
Awesome RAG is a curated list of retrieval-augmented generation (RAG) in large language models. It includes papers, surveys, general resources, lectures, talks, tutorials, workshops, tools, and other collections related to retrieval-augmented generation. The repository aims to provide a comprehensive overview of the latest advancements, techniques, and applications in the field of RAG.
MiniCPM
MiniCPM is a series of open-source large models on the client side jointly developed by Face Intelligence and Tsinghua University Natural Language Processing Laboratory. The main language model MiniCPM-2B has only 2.4 billion (2.4B) non-word embedding parameters, with a total of 2.7B parameters. - After SFT, MiniCPM-2B performs similarly to Mistral-7B on public comprehensive evaluation sets (better in Chinese, mathematics, and code capabilities), and outperforms models such as Llama2-13B, MPT-30B, and Falcon-40B overall. - After DPO, MiniCPM-2B also surpasses many representative open-source large models such as Llama2-70B-Chat, Vicuna-33B, Mistral-7B-Instruct-v0.1, and Zephyr-7B-alpha on the current evaluation set MTBench, which is closest to the user experience. - Based on MiniCPM-2B, a multi-modal large model MiniCPM-V 2.0 on the client side is constructed, which achieves the best performance of models below 7B in multiple test benchmarks, and surpasses larger parameter scale models such as Qwen-VL-Chat 9.6B, CogVLM-Chat 17.4B, and Yi-VL 34B on the OpenCompass leaderboard. MiniCPM-V 2.0 also demonstrates leading OCR capabilities, approaching Gemini Pro in scene text recognition capabilities. - After Int4 quantization, MiniCPM can be deployed and inferred on mobile phones, with a streaming output speed slightly higher than human speech speed. MiniCPM-V also directly runs through the deployment of multi-modal large models on mobile phones. - A single 1080/2080 can efficiently fine-tune parameters, and a single 3090/4090 can fully fine-tune parameters. A single machine can continuously train MiniCPM, and the secondary development cost is relatively low.
SemanticKernel.Assistants
This repository contains an assistant proposal for the Semantic Kernel, allowing the usage of assistants without relying on OpenAI Assistant APIs. It runs locally planners and plugins for the assistants, providing scenarios like Assistant with Semantic Kernel plugins, Multi-Assistant conversation, and AutoGen conversation. The Semantic Kernel is a lightweight SDK enabling integration of AI Large Language Models with conventional programming languages, offering functions like semantic functions, native functions, and embeddings-based memory. Users can bring their own model for the assistants and host them locally. The repository includes installation instructions, usage examples, and information on creating new conversation threads with the assistant.
AMchat
AMchat is a large language model that integrates advanced math concepts, exercises, and solutions. The model is based on the InternLM2-Math-7B model and is specifically designed to answer advanced math problems. It provides a comprehensive dataset that combines Math and advanced math exercises and solutions. Users can download the model from ModelScope or OpenXLab, deploy it locally or using Docker, and even retrain it using XTuner for fine-tuning. The tool also supports LMDeploy for quantization, OpenCompass for evaluation, and various other features for model deployment and evaluation. The project contributors have provided detailed documentation and guides for users to utilize the tool effectively.

MathVerse
MathVerse is an all-around visual math benchmark designed to evaluate the capabilities of Multi-modal Large Language Models (MLLMs) in visual math problem-solving. It collects high-quality math problems with diagrams to assess how well MLLMs can understand visual diagrams for mathematical reasoning. The benchmark includes 2,612 problems transformed into six versions each, contributing to 15K test samples. It also introduces a Chain-of-Thought (CoT) Evaluation strategy for fine-grained assessment of output answers.
Self-Iterative-Agent-System-for-Complex-Problem-Solving
The Self-Iterative Agent System for Complex Problem Solving is a solution developed for the Alibaba Mathematical Competition (AI Challenge). It involves multiple LLMs engaging in multi-round 'self-questioning' to iteratively refine the problem-solving process and select optimal solutions. The system consists of main and evaluation models, with a process that includes detailed problem-solving steps, feedback loops, and iterative improvements. The approach emphasizes communication and reasoning between sub-agents, knowledge extraction, and the importance of Agent-like architectures in complex tasks. While effective, there is room for improvement in model capabilities and error prevention mechanisms.
LLM4Opt
LLM4Opt is a collection of references and papers focusing on applying Large Language Models (LLMs) for diverse optimization tasks. The repository includes research papers, tutorials, workshops, competitions, and related collections related to LLMs in optimization. It covers a wide range of topics such as algorithm search, code generation, machine learning, science, industry, and more. The goal is to provide a comprehensive resource for researchers and practitioners interested in leveraging LLMs for optimization tasks.
For similar jobs

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.
NewEraAI-Papers
The NewEraAI-Papers repository provides links to collections of influential and interesting research papers from top AI conferences, along with open-source code to promote reproducibility and provide detailed implementation insights beyond the scope of the article. Users can stay up to date with the latest advances in AI research by exploring this repository. Contributions to improve the completeness of the list are welcomed, and users can create pull requests, open issues, or contact the repository owner via email to enhance the repository further.
cltk
The Classical Language Toolkit (CLTK) is a Python library that provides natural language processing (NLP) capabilities for pre-modern languages. It offers a modular processing pipeline with pre-configured defaults and supports almost 20 languages. Users can install the latest version using pip and access detailed documentation on the official website. The toolkit is designed to meet the unique needs of researchers working with historical languages, filling a void in the NLP landscape that often neglects non-spoken languages and different research goals.
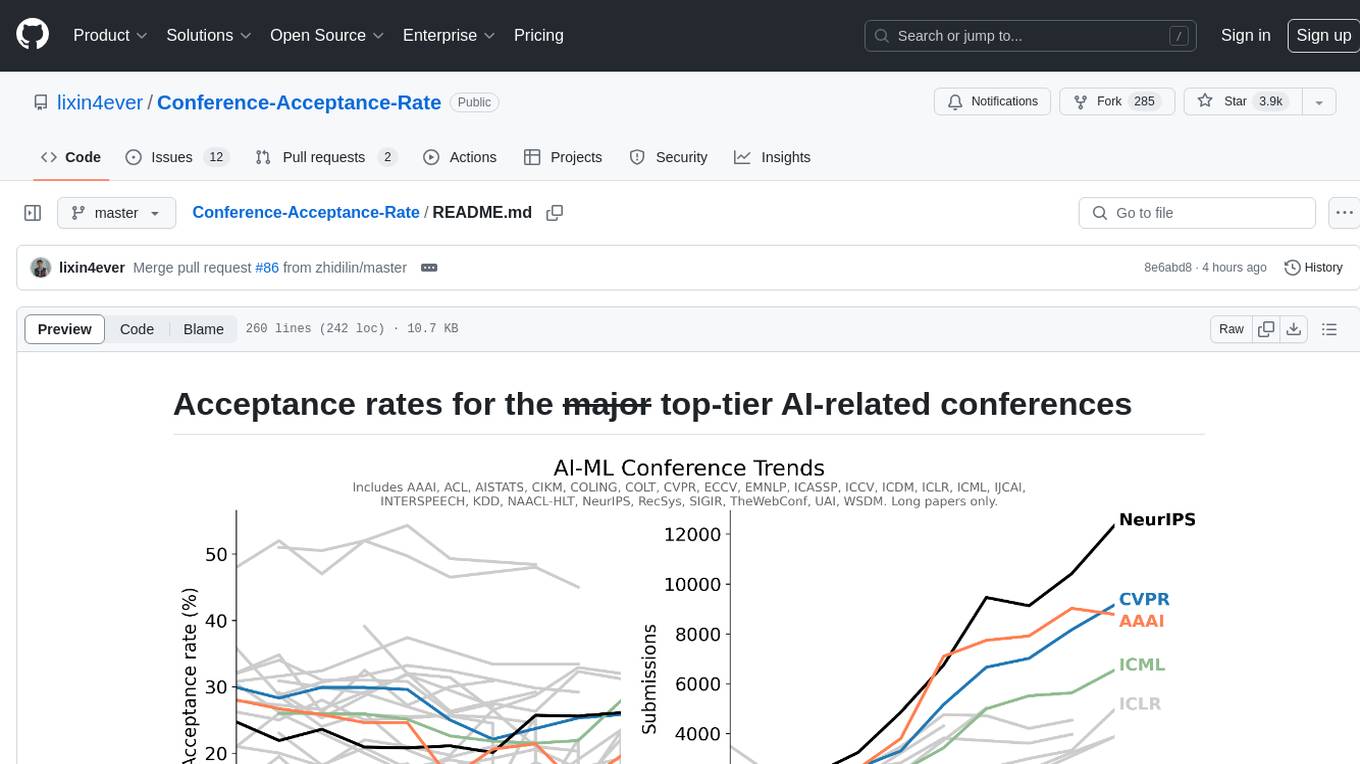
Conference-Acceptance-Rate
The 'Conference-Acceptance-Rate' repository provides acceptance rates for top-tier AI-related conferences in the fields of Natural Language Processing, Computational Linguistics, Computer Vision, Pattern Recognition, Machine Learning, Learning Theory, Artificial Intelligence, Data Mining, Information Retrieval, Speech Processing, and Signal Processing. The data includes acceptance rates for long papers and short papers over several years for each conference, allowing researchers to track trends and make informed decisions about where to submit their work.
pdftochat
PDFToChat is a tool that allows users to chat with their PDF documents in seconds. It is powered by Together AI and Pinecone, utilizing a tech stack including Next.js, Mixtral, M2 Bert, LangChain.js, MongoDB Atlas, Bytescale, Vercel, Clerk, and Tailwind CSS. Users can deploy the tool to Vercel or any other host by setting up Together.ai, MongoDB Atlas database, Bytescale, Clerk, and Vercel. The tool enables users to interact with PDFs through chat, with future tasks including adding features like trash icon for deleting PDFs, exploring different embedding models, implementing auto scrolling, improving replies, benchmarking accuracy, researching chunking and retrieval best practices, adding demo video, upgrading to Next.js 14, adding analytics, customizing tailwind prose, saving chats in postgres DB, compressing large PDFs, implementing custom uploader, session tracking, error handling, and support for images in PDFs.

tods-arxiv-daily-paper
This repository provides a tool for fetching and summarizing daily papers from the arXiv repository. It allows users to stay updated with the latest research in various fields by automatically retrieving and summarizing papers on a daily basis. The tool simplifies the process of accessing and digesting academic papers, making it easier for researchers and enthusiasts to keep track of new developments in their areas of interest.
Awesome-LLM-Strawberry
Awesome LLM Strawberry is a collection of research papers and blogs related to OpenAI Strawberry(o1) and Reasoning. The repository is continuously updated to track the frontier of LLM Reasoning.
Call-for-Reviewers
The `Call-for-Reviewers` repository aims to collect the latest 'call for reviewers' links from various top CS/ML/AI conferences/journals. It provides an opportunity for individuals in the computer/ machine learning/ artificial intelligence fields to gain review experience for applying for NIW/H1B/EB1 or enhancing their CV. The repository helps users stay updated with the latest research trends and engage with the academic community.