
openvino
OpenVINO™ is an open source toolkit for optimizing and deploying AI inference
Stars: 8880

OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.
README:




- Inference Optimization: Boost deep learning performance in computer vision, automatic speech recognition, generative AI, natural language processing with large and small language models, and many other common tasks.
- Flexible Model Support: Use models trained with popular frameworks such as PyTorch, TensorFlow, ONNX, Keras, PaddlePaddle, and JAX/Flax. Directly integrate models built with transformers and diffusers from the Hugging Face Hub using Optimum Intel. Convert and deploy models without original frameworks.
- Broad Platform Compatibility: Reduce resource demands and efficiently deploy on a range of platforms from edge to cloud. OpenVINO™ supports inference on CPU (x86, ARM), GPU (Intel integrated & discrete GPU) and AI accelerators (Intel NPU).
- Community and Ecosystem: Join an active community contributing to the enhancement of deep learning performance across various domains.
Check out the OpenVINO Cheat Sheet and Key Features for a quick reference.
Get your preferred distribution of OpenVINO or use this command for quick installation:
pip install -U openvinoCheck system requirements and supported devices for detailed information.
OpenVINO Quickstart example will walk you through the basics of deploying your first model.
Learn how to optimize and deploy popular models with the OpenVINO Notebooks📚:
- Create an LLM-powered Chatbot using OpenVINO
- YOLOv11 Optimization
- Text-to-Image Generation
- Multimodal assistant with LLaVa and OpenVINO
- Automatic speech recognition using Whisper and OpenVINO
Discover more examples in the OpenVINO Samples (Python & C++) and Notebooks (Python).
Here are easy-to-follow code examples demonstrating how to run PyTorch and TensorFlow model inference using OpenVINO:
PyTorch Model
import openvino as ov
import torch
import torchvision
# load PyTorch model into memory
model = torch.hub.load("pytorch/vision", "shufflenet_v2_x1_0", weights="DEFAULT")
# convert the model into OpenVINO model
example = torch.randn(1, 3, 224, 224)
ov_model = ov.convert_model(model, example_input=(example,))
# compile the model for CPU device
core = ov.Core()
compiled_model = core.compile_model(ov_model, 'CPU')
# infer the model on random data
output = compiled_model({0: example.numpy()})TensorFlow Model
import numpy as np
import openvino as ov
import tensorflow as tf
# load TensorFlow model into memory
model = tf.keras.applications.MobileNetV2(weights='imagenet')
# convert the model into OpenVINO model
ov_model = ov.convert_model(model)
# compile the model for CPU device
core = ov.Core()
compiled_model = core.compile_model(ov_model, 'CPU')
# infer the model on random data
data = np.random.rand(1, 224, 224, 3)
output = compiled_model({0: data})OpenVINO supports the CPU, GPU, and NPU devices and works with models from PyTorch, TensorFlow, ONNX, TensorFlow Lite, PaddlePaddle, and JAX/Flax frameworks. It includes APIs in C++, Python, C, NodeJS, and offers the GenAI API for optimized model pipelines and performance.
Get started with the OpenVINO GenAI installation and refer to the detailed guide to explore the capabilities of Generative AI using OpenVINO.
Learn how to run LLMs and GenAI with Samples in the OpenVINO™ GenAI repo. See GenAI in action with Jupyter notebooks: LLM-powered Chatbot and LLM Instruction-following pipeline.
User documentation contains detailed information about OpenVINO and guides you from installation through optimizing and deploying models for your AI applications.
Developer documentation focuses on the OpenVINO architecture and describes building and contributing processes.
- Neural Network Compression Framework (NNCF) - advanced model optimization techniques including quantization, filter pruning, binarization, and sparsity.
- GenAI Repository and OpenVINO Tokenizers - resources and tools for developing and optimizing Generative AI applications.
- OpenVINO™ Model Server (OVMS) - a scalable, high-performance solution for serving models optimized for Intel architectures.
- Intel® Geti™ - an interactive video and image annotation tool for computer vision use cases.
- 🤗Optimum Intel - grab and use models leveraging OpenVINO within the Hugging Face API.
- Torch.compile - use OpenVINO for Python-native applications by JIT-compiling code into optimized kernels.
- OpenVINO LLMs inference and serving with vLLM - enhance vLLM's fast and easy model serving with the OpenVINO backend.
- OpenVINO Execution Provider for ONNX Runtime - use OpenVINO as a backend with your existing ONNX Runtime code.
- LlamaIndex - build context-augmented GenAI applications with the LlamaIndex framework and enhance runtime performance with OpenVINO.
- LangChain - integrate OpenVINO with the LangChain framework to enhance runtime performance for GenAI applications.
- Keras 3 - Keras 3 is a multi-backend deep learning framework. Users can switch model inference to the OpenVINO backend using the Keras API.
Check out the Awesome OpenVINO repository to discover a collection of community-made AI projects based on OpenVINO!
Explore OpenVINO Performance Benchmarks to discover the optimal hardware configurations and plan your AI deployment based on verified data.
Check out Contribution Guidelines for more details. Read the Good First Issues section, if you're looking for a place to start contributing. We welcome contributions of all kinds!
You can ask questions and get support on:
- GitHub Issues.
- OpenVINO channels on the Intel DevHub Discord server.
- The
openvinotag on Stack Overflow*.
OpenVINO™ collects software performance and usage data for the purpose of improving OpenVINO™ tools. This data is collected directly by OpenVINO™ or through the use of Google Analytics 4. You can opt-out at any time by running the command:
opt_in_out --opt_outMore Information is available at OpenVINO™ Telemetry.
OpenVINO™ Toolkit is licensed under Apache License Version 2.0. By contributing to the project, you agree to the license and copyright terms therein and release your contribution under these terms.
* Other names and brands may be claimed as the property of others.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for openvino
Similar Open Source Tools
openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.
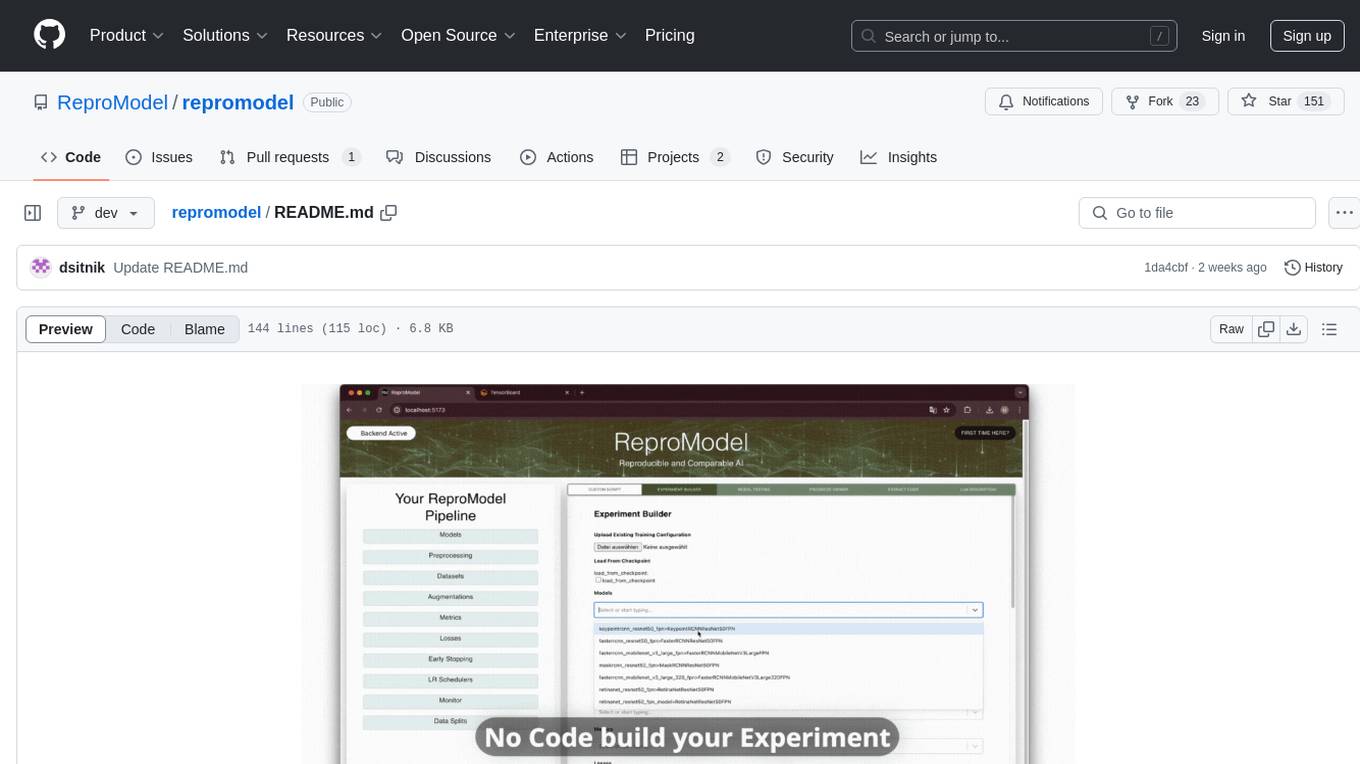
repromodel
ReproModel is an open-source toolbox designed to boost AI research efficiency by enabling researchers to reproduce, compare, train, and test AI models faster. It provides standardized models, dataloaders, and processing procedures, allowing researchers to focus on new datasets and model development. With a no-code solution, users can access benchmark and SOTA models and datasets, utilize training visualizations, extract code for publication, and leverage an LLM-powered automated methodology description writer. The toolbox helps researchers modularize development, compare pipeline performance reproducibly, and reduce time for model development, computation, and writing. Future versions aim to facilitate building upon state-of-the-art research by loading previously published study IDs with verified code, experiments, and results stored in the system.

Genkit
Genkit is an open-source framework for building full-stack AI-powered applications, used in production by Google's Firebase. It provides SDKs for JavaScript/TypeScript (Stable), Go (Beta), and Python (Alpha) with unified interface for integrating AI models from providers like Google, OpenAI, Anthropic, Ollama. Rapidly build chatbots, automations, and recommendation systems using streamlined APIs for multimodal content, structured outputs, tool calling, and agentic workflows. Genkit simplifies AI integration with open-source SDK, unified APIs, and offers text and image generation, structured data generation, tool calling, prompt templating, persisted chat interfaces, AI workflows, and AI-powered data retrieval (RAG).

gptme
GPTMe is a tool that allows users to interact with an LLM assistant directly in their terminal in a chat-style interface. The tool provides features for the assistant to run shell commands, execute code, read/write files, and more, making it suitable for various development and terminal-based tasks. It serves as a local alternative to ChatGPT's 'Code Interpreter,' offering flexibility and privacy when using a local model. GPTMe supports code execution, file manipulation, context passing, self-correction, and works with various AI models like GPT-4. It also includes a GitHub Bot for requesting changes and operates entirely in GitHub Actions. In progress features include handling long contexts intelligently, a web UI and API for conversations, web and desktop vision, and a tree-based conversation structure.

nixtla
Nixtla is a production-ready generative pretrained transformer for time series forecasting and anomaly detection. It can accurately predict various domains such as retail, electricity, finance, and IoT with just a few lines of code. TimeGPT introduces a paradigm shift with its standout performance, efficiency, and simplicity, making it accessible even to users with minimal coding experience. The model is based on self-attention and is independently trained on a vast time series dataset to minimize forecasting error. It offers features like zero-shot inference, fine-tuning, API access, adding exogenous variables, multiple series forecasting, custom loss function, cross-validation, prediction intervals, and handling irregular timestamps.
aistore
AIStore is a lightweight object storage system designed for AI applications. It is highly scalable, reliable, and easy to use. AIStore can be deployed on any commodity hardware, and it can be used to store and manage large datasets for deep learning and other AI applications.

gptme
Personal AI assistant/agent in your terminal, with tools for using the terminal, running code, editing files, browsing the web, using vision, and more. A great coding agent that is general-purpose to assist in all kinds of knowledge work, from a simple but powerful CLI. An unconstrained local alternative to ChatGPT with 'Code Interpreter', Cursor Agent, etc. Not limited by lack of software, internet access, timeouts, or privacy concerns if using local models.
taipy
Taipy is an open-source Python library for easy, end-to-end application development, featuring what-if analyses, smart pipeline execution, built-in scheduling, and deployment tools.
neuro-san-studio
Neuro SAN Studio is an open-source library for building agent networks across various industries. It simplifies the development of collaborative AI systems by enabling users to create sophisticated multi-agent applications using declarative configuration files. The tool offers features like data-driven configuration, adaptive communication protocols, safe data handling, dynamic agent network designer, flexible tool integration, robust traceability, and cloud-agnostic deployment. It has been used in various use-cases such as automated generation of multi-agent configurations, airline policy assistance, banking operations, market analysis in consumer packaged goods, insurance claims processing, intranet knowledge management, retail operations, telco network support, therapy vignette supervision, and more.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.

gpt4all
GPT4All is an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU. Note that your CPU needs to support AVX or AVX2 instructions. Learn more in the documentation. A GPT4All model is a 3GB - 8GB file that you can download and plug into the GPT4All open-source ecosystem software. Nomic AI supports and maintains this software ecosystem to enforce quality and security alongside spearheading the effort to allow any person or enterprise to easily train and deploy their own on-edge large language models.
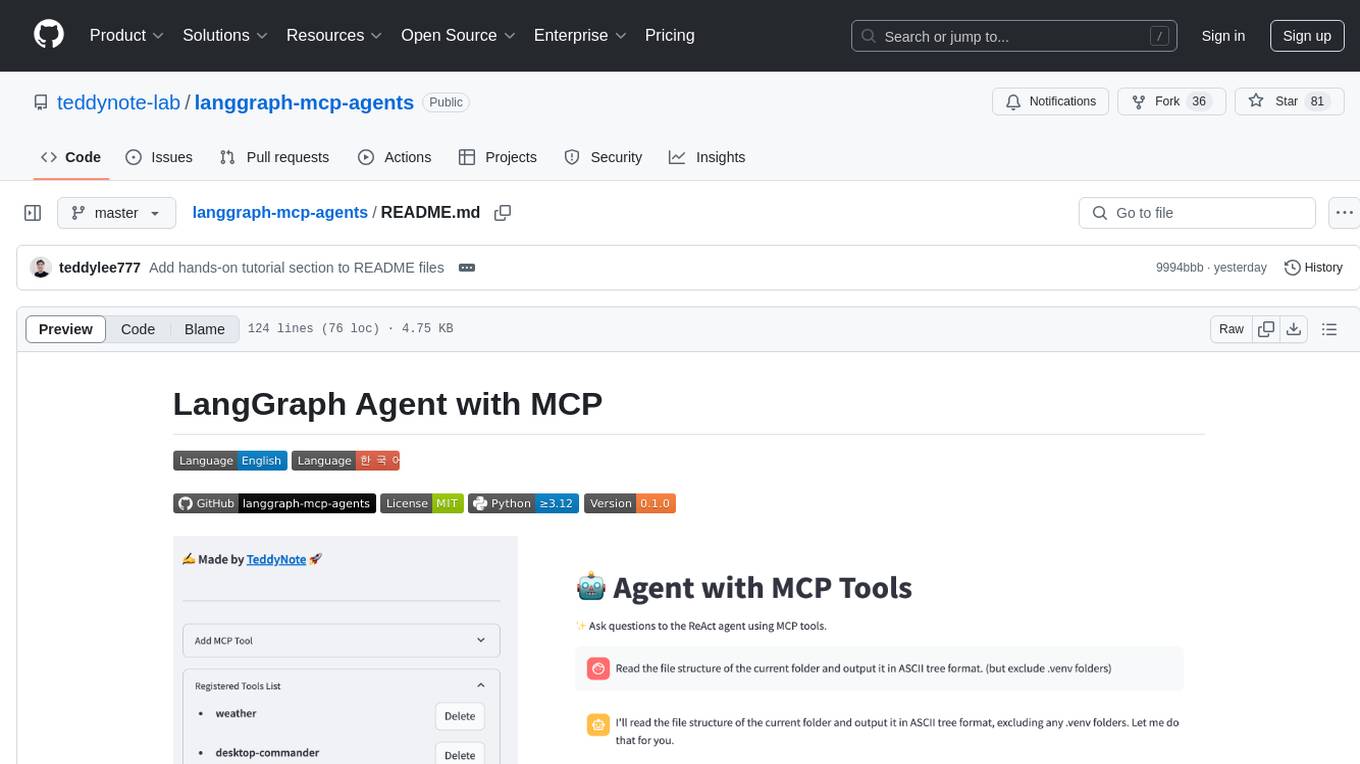
langgraph-mcp-agents
LangGraph Agent with MCP is a toolkit provided by LangChain AI that enables AI agents to interact with external tools and data sources through the Model Context Protocol (MCP). It offers a user-friendly interface for deploying ReAct agents to access various data sources and APIs through MCP tools. The toolkit includes features such as a Streamlit Interface for interaction, Tool Management for adding and configuring MCP tools dynamically, Streaming Responses in real-time, and Conversation History tracking.
geoai
geoai is a Python package designed for utilizing Artificial Intelligence (AI) in the context of geospatial data. It allows users to visualize various types of geospatial data such as vector, raster, and LiDAR data. Additionally, the package offers functionalities for segmenting remote sensing imagery using the Segment Anything Model and classifying remote sensing imagery with deep learning models. With a focus on geospatial AI applications, geoai provides a versatile tool for processing and analyzing spatial data with the power of AI.

clearml
ClearML is a suite of tools designed to streamline the machine learning workflow. It includes an experiment manager, MLOps/LLMOps, data management, and model serving capabilities. ClearML is open-source and offers a free tier hosting option. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm. ClearML provides extensive logging capabilities, including source control info, execution environment, hyper-parameters, and experiment outputs. It also offers automation features, such as remote job execution and pipeline creation. ClearML is designed to be easy to integrate, requiring only two lines of code to add to existing scripts. It aims to improve collaboration, visibility, and data transparency within ML teams.
higress
Higress is an open-source cloud-native API gateway built on the core of Istio and Envoy, based on Alibaba's internal practice of Envoy Gateway. It is designed for AI-native API gateway, serving AI businesses such as Tongyi Qianwen APP, Bailian Big Model API, and Machine Learning PAI platform. Higress provides capabilities to interface with LLM model vendors, AI observability, multi-model load balancing/fallback, AI token flow control, and AI caching. It offers features for AI gateway, Kubernetes Ingress gateway, microservices gateway, and security protection gateway, with advantages in production-level scalability, stream processing, extensibility, and ease of use.
vts
VTS (Vector Transport Service) is an open-source tool developed by Zilliz based on Apache Seatunnel for moving vectors and unstructured data. It addresses data migration needs, supports real-time data streaming and offline import, simplifies unstructured data transformation, and ensures end-to-end data quality. Core capabilities include rich connectors, stream and batch processing, distributed snapshot support, high performance, and real-time monitoring. Future developments include incremental synchronization, advanced data transformation, and enhanced monitoring. VTS supports various connectors for data migration and offers advanced features like Transformers, cluster mode deployment, RESTful API, Docker deployment, and more.
For similar tasks

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.
openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.
djl-demo
The Deep Java Library (DJL) is a framework-agnostic Java API for deep learning. It provides a unified interface to popular deep learning frameworks such as TensorFlow, PyTorch, and MXNet. DJL makes it easy to develop deep learning applications in Java, and it can be used for a variety of tasks, including image classification, object detection, natural language processing, and speech recognition.

kaapana
Kaapana is an open-source toolkit for state-of-the-art platform provisioning in the field of medical data analysis. The applications comprise AI-based workflows and federated learning scenarios with a focus on radiological and radiotherapeutic imaging. Obtaining large amounts of medical data necessary for developing and training modern machine learning methods is an extremely challenging effort that often fails in a multi-center setting, e.g. due to technical, organizational and legal hurdles. A federated approach where the data remains under the authority of the individual institutions and is only processed on-site is, in contrast, a promising approach ideally suited to overcome these difficulties. Following this federated concept, the goal of Kaapana is to provide a framework and a set of tools for sharing data processing algorithms, for standardized workflow design and execution as well as for performing distributed method development. This will facilitate data analysis in a compliant way enabling researchers and clinicians to perform large-scale multi-center studies. By adhering to established standards and by adopting widely used open technologies for private cloud development and containerized data processing, Kaapana integrates seamlessly with the existing clinical IT infrastructure, such as the Picture Archiving and Communication System (PACS), and ensures modularity and easy extensibility.

MONAI
MONAI is a PyTorch-based, open-source framework for deep learning in healthcare imaging. It provides a comprehensive set of tools for medical image analysis, including data preprocessing, model training, and evaluation. MONAI is designed to be flexible and easy to use, making it a valuable resource for researchers and developers in the field of medical imaging.
nnstreamer
NNStreamer is a set of Gstreamer plugins that allow Gstreamer developers to adopt neural network models easily and efficiently and neural network developers to manage neural network pipelines and their filters easily and efficiently.
cortex
Nitro is a high-efficiency C++ inference engine for edge computing, powering Jan. It is lightweight and embeddable, ideal for product integration. The binary of nitro after zipped is only ~3mb in size with none to minimal dependencies (if you use a GPU need CUDA for example) make it desirable for any edge/server deployment.
PyTorch-Tutorial-2nd
The second edition of "PyTorch Practical Tutorial" was completed after 5 years, 4 years, and 2 years. On the basis of the essence of the first edition, rich and detailed deep learning application cases and reasoning deployment frameworks have been added, so that this book can more systematically cover the knowledge involved in deep learning engineers. As the development of artificial intelligence technology continues to emerge, the second edition of "PyTorch Practical Tutorial" is not the end, but the beginning, opening up new technologies, new fields, and new chapters. I hope to continue learning and making progress in artificial intelligence technology with you in the future.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.
VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.