
local-chat
LocalChat is a ChatGPT-like chat that runs on your computer
Stars: 86

LocalChat is a simple, easy-to-set-up, and open-source local AI chat tool that allows users to interact with generative language models on their own computers without transmitting data to a cloud server. It provides a chat-like interface for users to experience ChatGPT-like behavior locally, ensuring GDPR compliance and data privacy. Users can download LocalChat for macOS, Windows, or Linux to chat with open-weight generative language models.
README:
Update Jan 4, 2025: I noticed that LocalChat is gaining in popularity. That's great! However, this year I will have to defend my PhD thesis, so I will have limited time to code, which I will mainly direct towards my main app, Zettlr. This means that LocalChat won't receive many commits from my side. That being said, it is much easier to review & merge pull requests and in case there are PRs that improve the app, I'll happily review and merge, and continue to update the app. However, this will only work if people open PRs. So, if you enjoy the app, please contribute. Regular development on my own side can proceed in early 2026 again.
Chat with generative language models locally on your computer with zero setup. LocalChat is a simple, easy to set-up, and Open Source local AI chat built on top of llama.cpp. It requires no technical knowledge and enables users to experience ChatGPT-like behavior on their own machines — fully GDPR-compliant and without the fear of accidentally leaking information. Download LocalChat for macOS, Windows, or Linux here.
Table of Contents
Overview |
Rationale |
System Requirements |
Quick Start |
Documentation

LocalChat provides a chat-like interface for interacting with generative Large Language Models (LLMs). It looks and feels like any chat conversation, but happens locally on your computer. No data is ever transmitted to some cloud server.
There are already several extremely capable generative language models which look and feel almost like ChatGPT. The major difference is that those models run locally and are open-weight.
[!IMPORTANT] As you probably already know, chatting with an LLM may feel very natural, but the models remain probabilistic: They will generate the next likely word based on what else is in the prompt. LLMs have no sense of time, causality, context, and what linguists call pragmatics. Thus, they tend to invent events that never happened, mix up facts from entirely different events, or tell straight up lies (known as "hallucination"). The same applies to code or calculations that these models can output. This being said:
- Never trust the model. Confirm each and every bit of information they provides with independent research. A quick Google search for many things it outputs will give you more factually correct information.
- Do not blindly run code it generates. The code may seem to work, but may also erase your entire disk.
- Do not trust its calculations.
- Try to keep each conversation on a single topic to increase the quality.
Exercise caution and use this model at your own risk. Keep in mind that it is a toy, not something reliable.
When ChatGPT launched in November 2022, I was extremely excited – but at the same time also cautious. While I was very impressed by GPT-3's capabilities, I was painfully aware of the fact that the model was proprietary, and, even if it wasn't, would be impossible to run locally. As a privacy-aware European citizen, I don't like the thought of being dependent on a multi-billion dollar corporation that can cut-off access at any moment's notice.
Due to this, I couldn't really play around with GPT and decided to wait for the inevitable: the development of smaller and better tools. By now, there are several models that tick all the boxes: They run locally and they feel like ChatGPT. With quantization (which basically reduces the resolution with some quality losses), they can even be run on older hardware.
However, if you don't have any experience with LLMs, it will be hard to run them.
The reason for why this app exists is (a) I wanted to implement this myself to see how it works ergonomically, and (b) I wanted to provide a very simple layer for interacting with these things without having to worry about setting up PyTorch and Transformers locally.
You only install the app, download a model, and off you go.
This app requires a moderately recent computer to be run. However, this app depends on LLMs, which are notoriously power-hungry. Therefore, your computer hardware will dictate which models you can run.
The "regular" sized models likely need a dedicated graphics card with something between 6 and 18 GB of video memory, unless you are willing to wait more than a second per word.
Many models nowadays come in a quantized form, which makes the larger models also available for older or less powerful hardware. Quantization sometimes reduces the system requirements of even too large models quite a lot without too many quality losses (but your mileage may vary from model to model).
[!IMPORTANT] As a large language model, generating responses will take a bit of time. So especially if you have no dedicated GPU in your computer, please be patient, or try out a smaller model.
- Download the app from the releases section of this repository, and install it
- Open the model manager to receive instructions to download a model
- Visit Huggingface.co
- Download a model in GGUF-format
- Place that model file into the app's model directory
- Chat!
[!TIP] You can find the full documentation on the app's website.
The user interface is separated into three major components:
- The sidebar to the left contains a list of your conversations. You will need to create a new conversation to start chatting, By default, this conversation will utilize the first available model. You can change this later. Conversations and chats are persisted across restarts of the app. You can show and hide the sidebar with the small menu button at the top-left.
- The main area is occupied by the chat interface. Here you will see the current conversation's messages, can type a new one, and see how the model is generating a response.
- The status bar at the bottom gives you a few status indications as to how the app and model are doing.
This code is licensed via GNU GPL 3.0. Read more in the LICENSE file.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for local-chat
Similar Open Source Tools
local-chat
LocalChat is a simple, easy-to-set-up, and open-source local AI chat tool that allows users to interact with generative language models on their own computers without transmitting data to a cloud server. It provides a chat-like interface for users to experience ChatGPT-like behavior locally, ensuring GDPR compliance and data privacy. Users can download LocalChat for macOS, Windows, or Linux to chat with open-weight generative language models.
ClipboardConqueror
Clipboard Conqueror is a multi-platform omnipresent copilot alternative. Currently requiring a kobold united or openAI compatible back end, this software brings powerful LLM based tools to any text field, the universal copilot you deserve. It simply works anywhere. No need to sign in, no required key. Provided you are using local AI, CC is a data secure alternative integration provided you trust whatever backend you use. *Special thank you to the creators of KoboldAi, KoboldCPP, llamma, openAi, and the communities that made all this possible to figure out.

chaiNNer
ChaiNNer is a node-based image processing GUI aimed at making chaining image processing tasks easy and customizable. It gives users a high level of control over their processing pipeline and allows them to perform complex tasks by connecting nodes together. ChaiNNer is cross-platform, supporting Windows, MacOS, and Linux. It features an intuitive drag-and-drop interface, making it easy to create and modify processing chains. Additionally, ChaiNNer offers a wide range of nodes for various image processing tasks, including upscaling, denoising, sharpening, and color correction. It also supports batch processing, allowing users to process multiple images or videos at once.

gpdb
Greenplum Database (GPDB) is an advanced, fully featured, open source data warehouse, based on PostgreSQL. It provides powerful and rapid analytics on petabyte scale data volumes. Uniquely geared toward big data analytics, Greenplum Database is powered by the world’s most advanced cost-based query optimizer delivering high analytical query performance on large data volumes.
WeeaBlind
Weeablind is a program that uses modern AI speech synthesis, diarization, language identification, and voice cloning to dub multi-lingual media and anime. It aims to create a pleasant alternative for folks facing accessibility hurdles such as blindness, dyslexia, learning disabilities, or simply those that don't enjoy reading subtitles. The program relies on state-of-the-art technologies such as ffmpeg, pydub, Coqui TTS, speechbrain, and pyannote.audio to analyze and synthesize speech that stays in-line with the source video file. Users have the option of dubbing every subtitle in the video, setting the start and end times, dubbing only foreign-language content, or full-blown multi-speaker dubbing with speaking rate and volume matching.
Web-LLM-Assistant-Llama-cpp
Web-LLM Assistant is a simple web search assistant that leverages a large language model (LLM) running via Llama.cpp to provide informative and context-aware responses to user queries. It combines the power of LLMs with real-time web searching capabilities, allowing it to access up-to-date information and synthesize comprehensive answers. The tool performs web searches, collects and scrapes information from search results, refines search queries, and provides answers based on the acquired information. Users can interact with the tool by asking questions or requesting web searches, making it a valuable resource for obtaining information beyond the LLM's training data.
aiohomekit
aiohomekit is a Python library that implements the HomeKit protocol for controlling HomeKit accessories using asyncio. It is primarily used with Home Assistant, targeting the same versions of Python and following their code standards. The library is still under development and does not offer API guarantees yet. It aims to match the behavior of real HAP controllers, even when not strictly specified, and works around issues like JSON formatting, boolean encoding, header sensitivity, and TCP packet splitting. aiohomekit is primarily tested with Phillips Hue and Eve Extend bridges via Home Assistant, but is known to work with many more devices. It does not support BLE accessories and is intended for client-side use only.
discourse-chatbot
The discourse-chatbot is an original AI chatbot for Discourse forums that allows users to converse with the bot in posts or chat channels. Users can customize the character of the bot, enable RAG mode for expert answers, search Wikipedia, news, and Google, provide market data, perform accurate math calculations, and experiment with vision support. The bot uses cutting-edge Open AI API and supports Azure and proxy server connections. It includes a quota system for access management and can be used in RAG mode or basic bot mode. The setup involves creating embeddings to make the bot aware of forum content and setting up bot access permissions based on trust levels. Users must obtain an API token from Open AI and configure group quotas to interact with the bot. The plugin is extensible to support other cloud bots and content search beyond the provided set.

agno
Agno is a lightweight library for building multi-modal Agents. It is designed with core principles of simplicity, uncompromising performance, and agnosticism, allowing users to create blazing fast agents with minimal memory footprint. Agno supports any model, any provider, and any modality, making it a versatile container for AGI. Users can build agents with lightning-fast agent creation, model agnostic capabilities, native support for text, image, audio, and video inputs and outputs, memory management, knowledge stores, structured outputs, and real-time monitoring. The library enables users to create autonomous programs that use language models to solve problems, improve responses, and achieve tasks with varying levels of agency and autonomy.
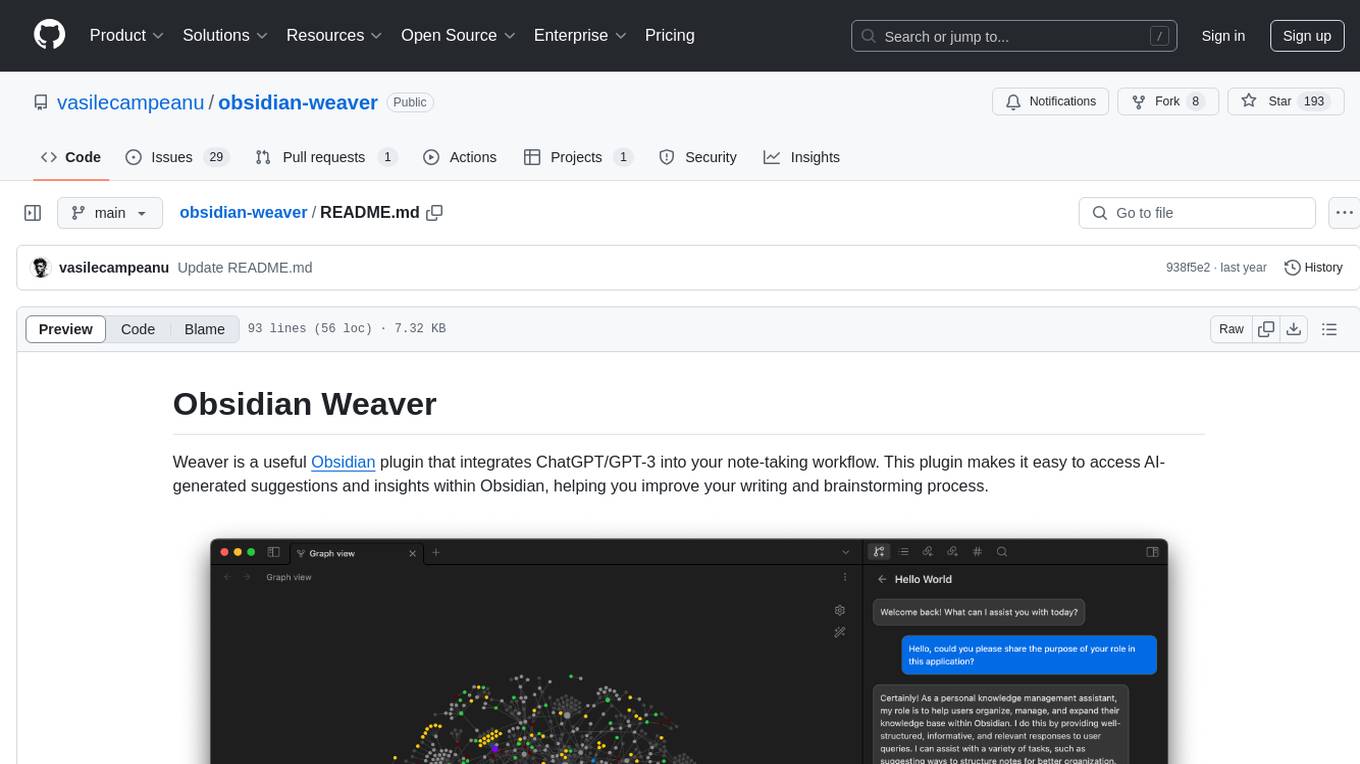
obsidian-weaver
Obsidian Weaver is a plugin that integrates ChatGPT/GPT-3 into the note-taking workflow of Obsidian. It allows users to easily access AI-generated suggestions and insights within Obsidian, enhancing the writing and brainstorming process. The plugin respects Obsidian's philosophy of storing notes locally, ensuring data security and privacy. Weaver offers features like creating new chat sessions with the AI assistant and receiving instant responses, all within the Obsidian environment. It provides a seamless integration with Obsidian's interface, making the writing process efficient and helping users stay focused. The plugin is constantly being improved with new features and updates to enhance the note-taking experience.
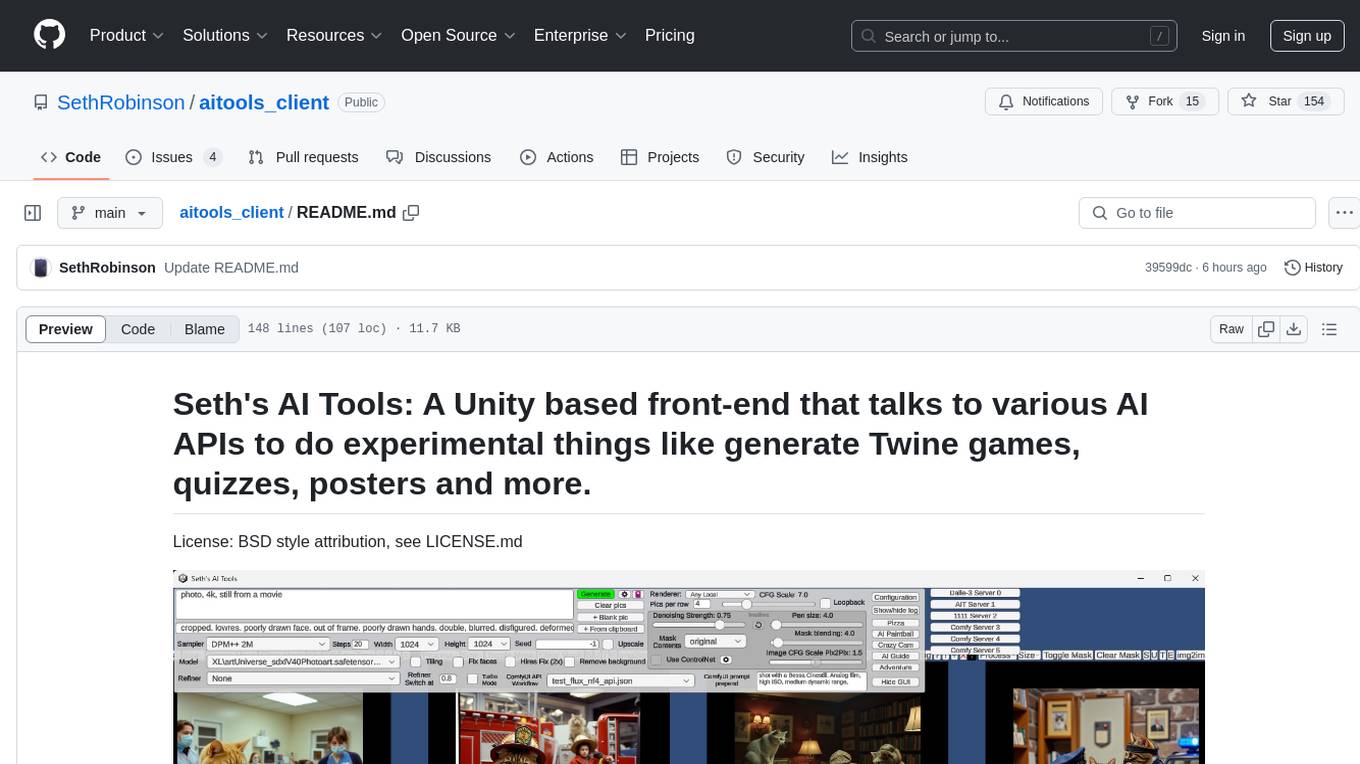
aitools_client
Seth's AI Tools is a Unity-based front-end that interfaces with various AI APIs to perform tasks such as generating Twine games, quizzes, posters, and more. The tool is a native Windows application that supports features like live update integration with image editors, text-to-image conversion, image processing, mask painting, and more. It allows users to connect to multiple servers for fast generation using GPUs and offers a neat workflow for evolving images in real-time. The tool respects user privacy by operating locally and includes built-in games and apps to test AI/SD capabilities. Additionally, it features an AI Guide for creating motivational posters and illustrated stories, as well as an Adventure mode with presets for generating web quizzes and Twine game projects.
ai-agents-masterclass
AI Agents Masterclass is a repository dedicated to teaching developers how to use AI agents to transform businesses and create powerful software. It provides weekly videos with accompanying code folders, guiding users on setting up Python environments, using environment variables, and installing necessary packages to run the code. The focus is on Large Language Models that can interact with the outside world to perform tasks like drafting emails, booking appointments, and managing tasks, enabling users to create innovative applications with minimal coding effort.
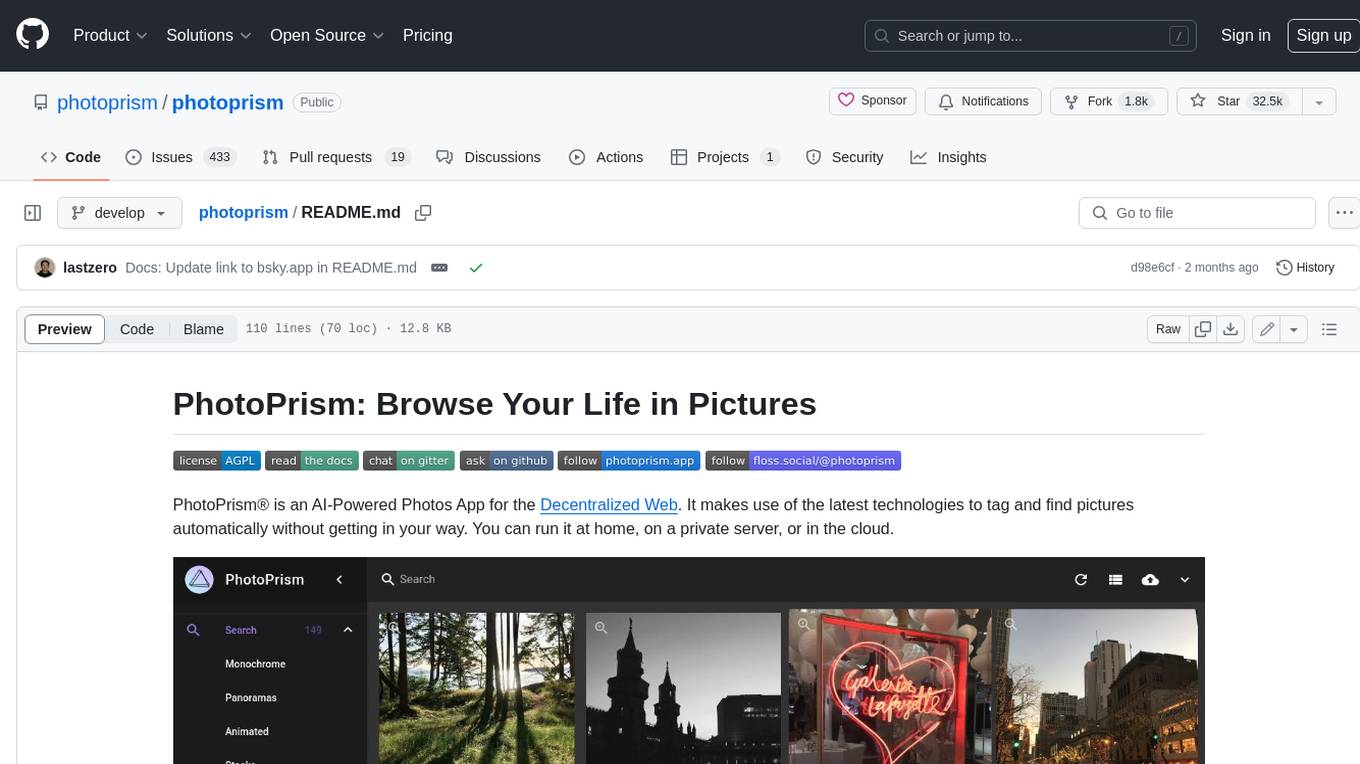
photoprism
PhotoPrism is an AI-powered photos app for the decentralized web. It uses the latest technologies to tag and find pictures automatically without getting in your way. You can run it at home, on a private server, or in the cloud.

modelbench
ModelBench is a tool for running safety benchmarks against AI models and generating detailed reports. It is part of the MLCommons project and is designed as a proof of concept to aggregate measures, relate them to specific harms, create benchmarks, and produce reports. The tool requires LlamaGuard for evaluating responses and a TogetherAI account for running benchmarks. Users can install ModelBench from GitHub or PyPI, run tests using Poetry, and create benchmarks by providing necessary API keys. The tool generates static HTML pages displaying benchmark scores and allows users to dump raw scores and manage cache for faster runs. ModelBench is aimed at enabling users to test their own models and create tests and benchmarks.
skyeye
SkyEye is an AI-powered Ground Controlled Intercept (GCI) bot designed for the flight simulator Digital Combat Simulator (DCS). It serves as an advanced replacement for the in-game E-2, E-3, and A-50 AI aircraft, offering modern voice recognition, natural-sounding voices, real-world brevity and procedures, a wide range of commands, and intelligent battlespace monitoring. The tool uses Speech-To-Text and Text-To-Speech technology, can run locally or on a cloud server, and is production-ready software used by various DCS communities.
obsidian-companion
Companion is an Obsidian plugin that adds an AI-powered autocomplete feature to your note-taking and personal knowledge management platform. With Companion, you can write notes more quickly and easily by receiving suggestions for completing words, phrases, and even entire sentences based on the context of your writing. The autocomplete feature uses OpenAI's state-of-the-art GPT-3 and GPT-3.5, including ChatGPT, and locally hosted Ollama models, among others, to generate smart suggestions that are tailored to your specific writing style and preferences. Support for more models is planned, too.
For similar tasks

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.

serverless-chat-langchainjs
This sample shows how to build a serverless chat experience with Retrieval-Augmented Generation using LangChain.js and Azure. The application is hosted on Azure Static Web Apps and Azure Functions, with Azure Cosmos DB for MongoDB vCore as the vector database. You can use it as a starting point for building more complex AI applications.

react-native-vercel-ai
Run Vercel AI package on React Native, Expo, Web and Universal apps. Currently React Native fetch API does not support streaming which is used as a default on Vercel AI. This package enables you to use AI library on React Native but the best usage is when used on Expo universal native apps. On mobile you get back responses without streaming with the same API of `useChat` and `useCompletion` and on web it will fallback to `ai/react`

LLamaSharp
LLamaSharp is a cross-platform library to run 🦙LLaMA/LLaVA model (and others) on your local device. Based on llama.cpp, inference with LLamaSharp is efficient on both CPU and GPU. With the higher-level APIs and RAG support, it's convenient to deploy LLM (Large Language Model) in your application with LLamaSharp.

gpt4all
GPT4All is an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU. Note that your CPU needs to support AVX or AVX2 instructions. Learn more in the documentation. A GPT4All model is a 3GB - 8GB file that you can download and plug into the GPT4All open-source ecosystem software. Nomic AI supports and maintains this software ecosystem to enforce quality and security alongside spearheading the effort to allow any person or enterprise to easily train and deploy their own on-edge large language models.

ChatGPT-Telegram-Bot
ChatGPT Telegram Bot is a Telegram bot that provides a smooth AI experience. It supports both Azure OpenAI and native OpenAI, and offers real-time (streaming) response to AI, with a faster and smoother experience. The bot also has 15 preset bot identities that can be quickly switched, and supports custom bot identities to meet personalized needs. Additionally, it supports clearing the contents of the chat with a single click, and restarting the conversation at any time. The bot also supports native Telegram bot button support, making it easy and intuitive to implement required functions. User level division is also supported, with different levels enjoying different single session token numbers, context numbers, and session frequencies. The bot supports English and Chinese on UI, and is containerized for easy deployment.

twinny
Twinny is a free and open-source AI code completion plugin for Visual Studio Code and compatible editors. It integrates with various tools and frameworks, including Ollama, llama.cpp, oobabooga/text-generation-webui, LM Studio, LiteLLM, and Open WebUI. Twinny offers features such as fill-in-the-middle code completion, chat with AI about your code, customizable API endpoints, and support for single or multiline fill-in-middle completions. It is easy to install via the Visual Studio Code extensions marketplace and provides a range of customization options. Twinny supports both online and offline operation and conforms to the OpenAI API standard.

agnai
Agnaistic is an AI roleplay chat tool that allows users to interact with personalized characters using their favorite AI services. It supports multiple AI services, persona schema formats, and features such as group conversations, user authentication, and memory/lore books. Agnaistic can be self-hosted or run using Docker, and it provides a range of customization options through its settings.json file. The tool is designed to be user-friendly and accessible, making it suitable for both casual users and developers.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.