
multilspy
multilspy is a lsp client library in Python intended to be used to build applications around language servers.
Stars: 236

Multilspy is a Python library developed for research purposes to facilitate the creation of language server clients for querying and obtaining results of static analyses from various language servers. It simplifies the process by handling server setup, communication, and configuration parameters, providing a common interface for different languages. The library supports features like finding function/class definitions, callers, completions, hover information, and document symbols. It is designed to work with AI systems like Large Language Models (LLMs) for tasks such as Monitor-Guided Decoding to ensure code generation correctness and boost compilability.
README:

This repository hosts multilspy, a library developed as part of research conducted for NeruIPS 2023 paper titled "Monitor-Guided Decoding of Code LMs with Static Analysis of Repository Context" ("Guiding Language Models of Code with Global Context using Monitors" on Arxiv). The paper introduces Monitor-Guided Decoding (MGD) for code generation using Language Models, where a monitor uses static analysis to guide the decoding, ensuring that the generated code follows various correctness properties, like absence of hallucinated symbol names, valid order of method calls, etc. For further details about Monitor-Guided Decoding, please refer to the paper and GitHub repository microsoft/monitors4codegen.
multilspy is a cross-platform library designed to simplify the process of creating language server clients to query and obtain results of various static analyses from a wide variety of language servers that communicate over the Language Server Protocol. It is easily extensible to support any language that has a Language Server and we aim to continuously add support for more language servers and languages.
Language servers are tools that perform a variety of static analyses on code repositories and provide useful information such as type-directed code completion suggestions, symbol definition locations, symbol references, etc., over the Language Server Protocol (LSP). Since LSP is language-agnostic, multilspy can provide the results for static analyses of code in different languages over a common interface.
multilspy intends to ease the process of using language servers, by handling various steps in using a language server:
- Automatically handling the download of platform-specific server binaries, and setup/teardown of language servers
- Handling JSON-RPC based communication between the client and the server
- Maintaining and passing hand-tuned server and language specific configuration parameters
- Providing a simple API to the user, while executing all steps of server-specific protocol steps to execute the query/request.
Some of the analysis results that multilspy can provide are:
- Finding the definition of a function or a class (textDocument/definition)
- Finding the callers of a function or the instantiations of a class (textDocument/references)
- Providing type-based dereference completions (textDocument/completion)
- Getting information displayed when hovering over symbols, like method signature (textDocument/hover)
- Getting list/tree of all symbols defined in a given file, along with symbol type like class, method, etc. (textDocument/documentSymbol)
- Please create an issue/PR to add any other LSP request not listed above
It is ideal to create a new virtual environment with python>=3.10. To create a virtual environment using conda and activate it:
conda create -n multilspy_env python=3.10
conda activate multilspy_env
Further details and instructions on creation of Python virtual environments can be found in the official documentation. Further, we also refer users to Miniconda, as an alternative to the above steps for creation of the virtual environment.
To install multilspy using pip, execute the following command:
pip install multilspy
multilspy currently supports the following languages:
| Code Language | Language Server |
|---|---|
| java | Eclipse JDTLS |
| python | jedi-language-server |
| rust | Rust Analyzer |
| csharp | OmniSharp / RazorSharp |
| typescript | TypeScriptLanguageServer |
| javascript | TypeScriptLanguageServer |
| go | gopls |
| dart | Dart |
| ruby | Solargraph |
Example usage:
from multilspy import SyncLanguageServer
from multilspy.multilspy_config import MultilspyConfig
from multilspy.multilspy_logger import MultilspyLogger
...
config = MultilspyConfig.from_dict({"code_language": "java"}) # Also supports "python", "rust", "csharp", "typescript", "javascript", "go", "dart", "ruby"
logger = MultilspyLogger()
lsp = SyncLanguageServer.create(config, logger, "/abs/path/to/project/root/")
with lsp.start_server():
result = lsp.request_definition(
"relative/path/to/code_file.java", # Filename of location where request is being made
163, # line number of symbol for which request is being made
4 # column number of symbol for which request is being made
)
result2 = lsp.request_completions(
...
)
result3 = lsp.request_references(
...
)
result4 = lsp.request_document_symbols(
...
)
result5 = lsp.request_hover(
...
)
...multilspy also provides an asyncio based API which can be used in async contexts. Example usage (asyncio):
from multilspy import LanguageServer
...
lsp = LanguageServer.create(...)
async with lsp.start_server():
result = await lsp.request_definition(
...
)
...The file src/multilspy/language_server.py provides the multilspy API. Several tests for multilspy present under tests/multilspy/ provide detailed usage examples for multilspy. The tests can be executed by running:
pytest tests/multilspymultilspy provides all the features that language-server-protocol provides to IDEs like VSCode. It is useful to develop toolsets that can interface with AI systems like Large Language Models (LLM).
One such usecase is Monitor-Guided Decoding, where multilspy is used to find results of static analyses like type-directed completions, to guide the token-by-token generation of code using an LLM, ensuring that all generated identifier/method names are valid in the context of the repository, significantly boosting the compilability of generated code. MGD also demonstrates use of multilspy to create monitors that ensure all function calls in LLM generated code receive correct number of arguments, and that functions of an object are called in the right order following a protocol (like not calling "read" before "open" on a file object).
- "Fix the Tests: Augmenting LLMs to Repair Test Cases with Static Collector and Neural Reranker," in 2024 IEEE 35th International Symposium on Software Reliability Engineering (ISSRE)
- Tutorial on obtaining python completions with multilspy
- Gathering and utilizing repository-wide context for repository-level coding agents
If you get the following error:
RuntimeError: Task <Task pending name='Task-2' coro=<_AsyncGeneratorContextManager.__aenter__() running at
python3.8/contextlib.py:171> cb=[_chain_future.<locals>._call_set_state() at
python3.8/asyncio/futures.py:367]> got Future <Future pending> attached to a different loop python3.8/asyncio/locks.py:309: RuntimeError
Please ensure that you create a new environment with Python >=3.10. For further details, please have a look at the StackOverflow Discussion.
If you're using Multilspy in your research or applications, please cite using this BibTeX:
@inproceedings{NEURIPS2023_662b1774,
author = {Agrawal, Lakshya A and Kanade, Aditya and Goyal, Navin and Lahiri, Shuvendu and Rajamani, Sriram},
booktitle = {Advances in Neural Information Processing Systems},
editor = {A. Oh and T. Naumann and A. Globerson and K. Saenko and M. Hardt and S. Levine},
pages = {32270--32298},
publisher = {Curran Associates, Inc.},
title = {Monitor-Guided Decoding of Code LMs with Static Analysis of Repository Context},
url = {https://proceedings.neurips.cc/paper_files/paper/2023/file/662b1774ba8845fc1fa3d1fc0177ceeb-Paper-Conference.pdf},
volume = {36},
year = {2023}
}
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for multilspy
Similar Open Source Tools
multilspy
Multilspy is a Python library developed for research purposes to facilitate the creation of language server clients for querying and obtaining results of static analyses from various language servers. It simplifies the process by handling server setup, communication, and configuration parameters, providing a common interface for different languages. The library supports features like finding function/class definitions, callers, completions, hover information, and document symbols. It is designed to work with AI systems like Large Language Models (LLMs) for tasks such as Monitor-Guided Decoding to ensure code generation correctness and boost compilability.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.
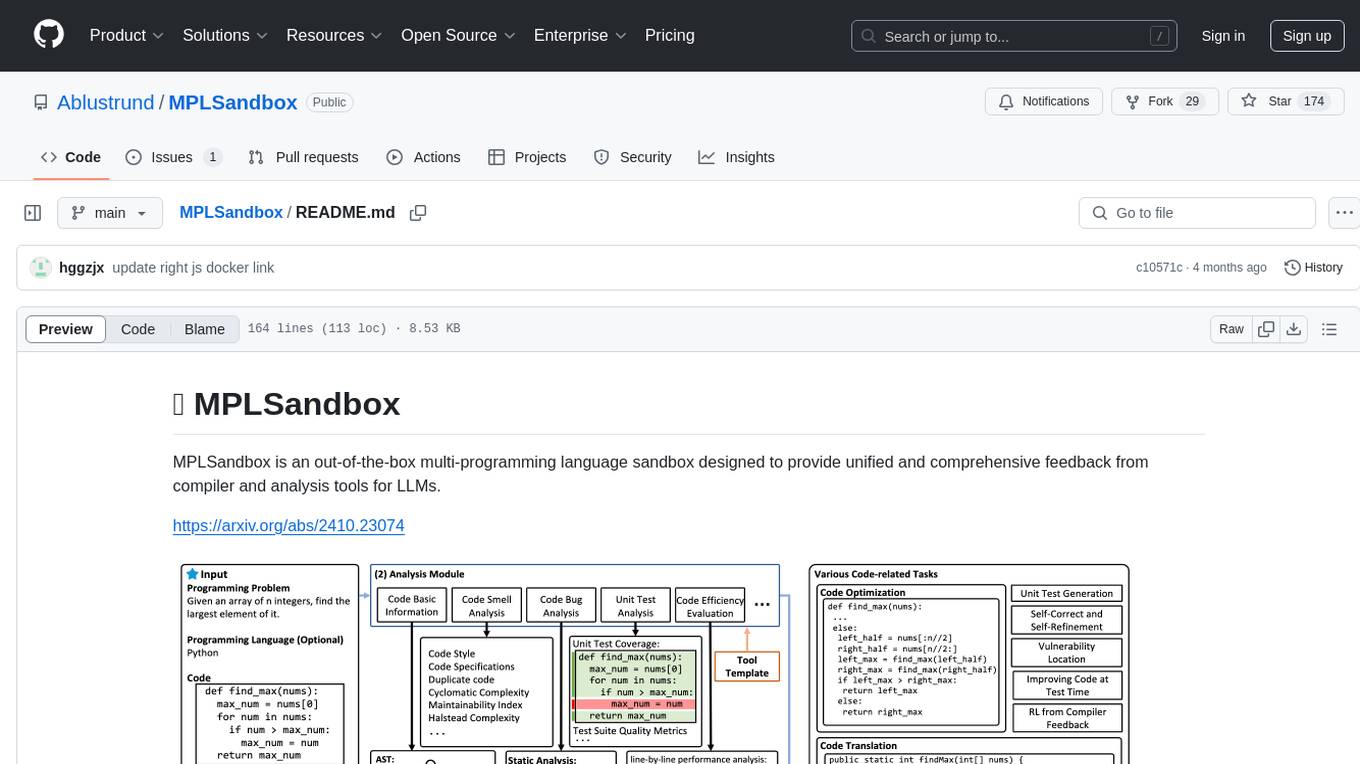
MPLSandbox
MPLSandbox is an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for LLMs. It simplifies code analysis for researchers and can be seamlessly integrated into LLM training and application processes to enhance performance in a range of code-related tasks. The sandbox environment ensures safe code execution, the code analysis module offers comprehensive analysis reports, and the information integration module combines compilation feedback and analysis results for complex code-related tasks.

monitors4codegen
This repository hosts the official code and data artifact for the paper 'Monitor-Guided Decoding of Code LMs with Static Analysis of Repository Context'. It introduces Monitor-Guided Decoding (MGD) for code generation using Language Models, where a monitor uses static analysis to guide the decoding. The repository contains datasets, evaluation scripts, inference results, a language server client 'multilspy' for static analyses, and implementation of various monitors monitoring for different properties in 3 programming languages. The monitors guide Language Models to adhere to properties like valid identifier dereferences, correct number of arguments to method calls, typestate validity of method call sequences, and more.

lotus
LOTUS (LLMs Over Tables of Unstructured and Structured Data) is a query engine that provides a declarative programming model and an optimized query engine for reasoning-based query pipelines over structured and unstructured data. It offers a simple and intuitive Pandas-like API with semantic operators for fast and easy LLM-powered data processing. The tool implements a semantic operator programming model, allowing users to write AI-based pipelines with high-level logic and leaving the rest of the work to the query engine. LOTUS supports various semantic operators like sem_map, sem_filter, sem_extract, sem_agg, sem_topk, sem_join, sem_sim_join, and sem_search, enabling users to perform tasks like mapping records, filtering data, aggregating records, and more. The tool also supports different model classes such as LM, RM, and Reranker for language modeling, retrieval, and reranking tasks respectively.
facet
FACET is an open source library for human-explainable AI that combines model inspection and model-based simulation to provide better explanations for supervised machine learning models. It offers an efficient and transparent machine learning workflow, enhancing scikit-learn's pipelining paradigm with new capabilities for model selection, inspection, and simulation. FACET introduces new algorithms for quantifying dependencies and interactions between features in ML models, as well as for conducting virtual experiments to optimize predicted outcomes. The tool ensures end-to-end traceability of features using an augmented version of scikit-learn with enhanced support for pandas data frames. FACET also provides model inspection methods for scikit-learn estimators, enhancing global metrics like synergy and redundancy to complement the local perspective of SHAP. Additionally, FACET offers model simulation capabilities for conducting univariate uplift simulations based on important features like BMI.
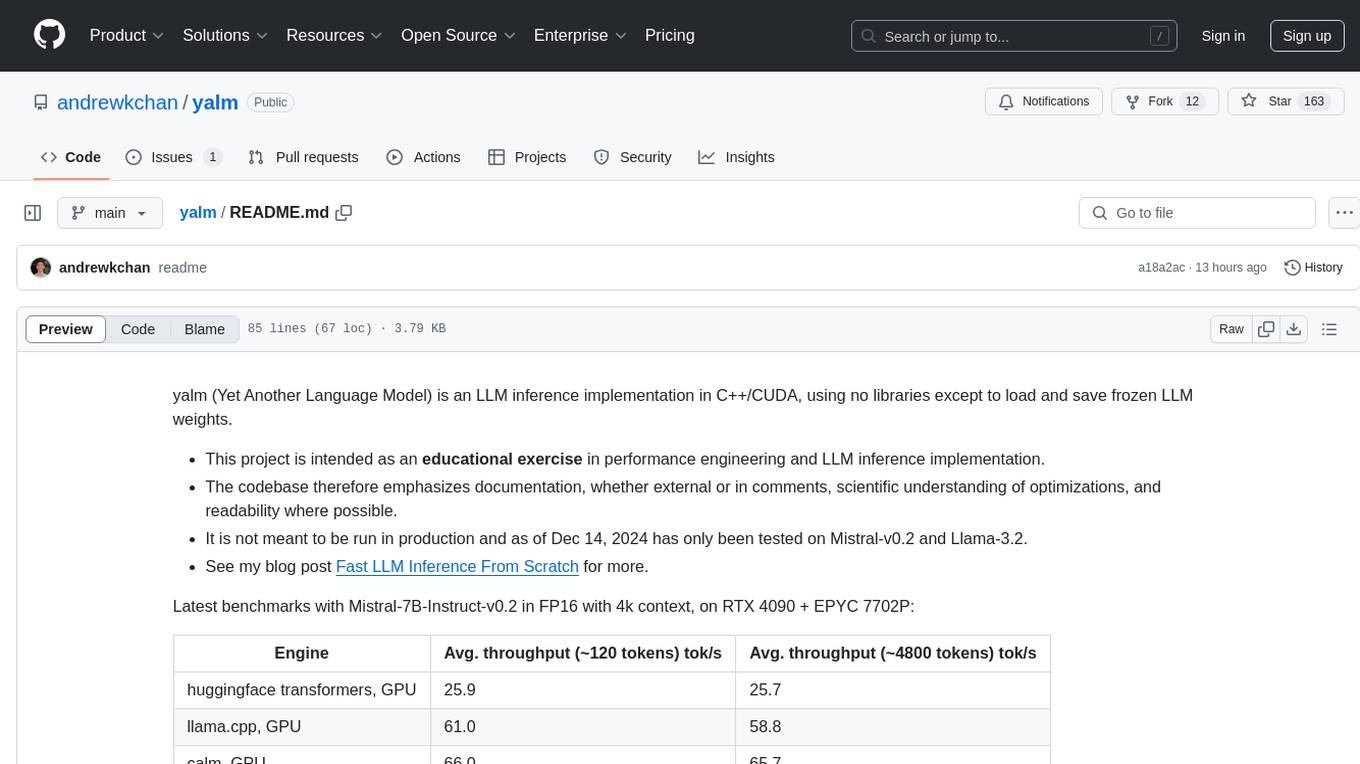
yalm
Yalm (Yet Another Language Model) is an LLM inference implementation in C++/CUDA, emphasizing performance engineering, documentation, scientific optimizations, and readability. It is not for production use and has been tested on Mistral-v0.2 and Llama-3.2. Requires C++20-compatible compiler, CUDA toolkit, and LLM safetensor weights in huggingface format converted to .yalm file.
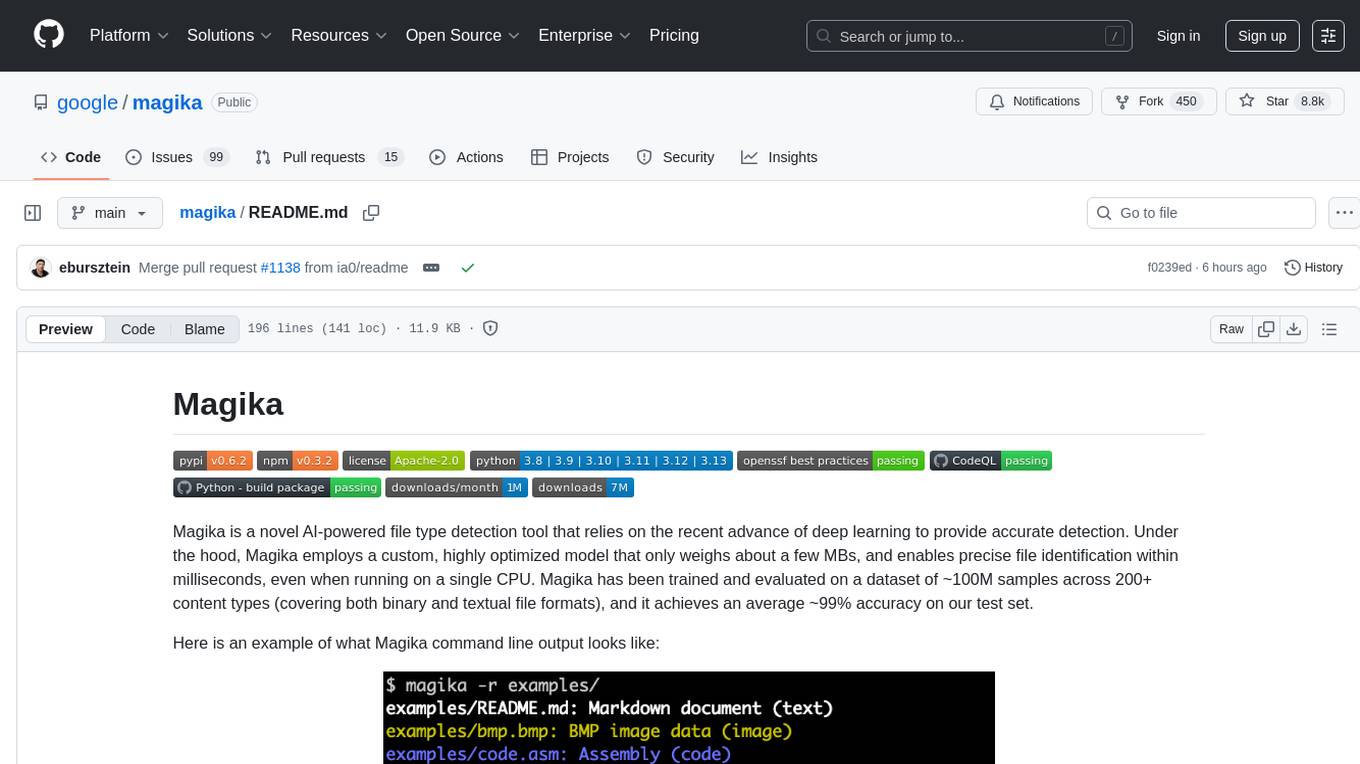
magika
Magika is a novel AI-powered file type detection tool that relies on deep learning to provide accurate detection. It employs a custom, highly optimized model to enable precise file identification within milliseconds. Trained on a dataset of ~100M samples across 200+ content types, achieving an average ~99% accuracy. Used at scale by Google to improve user safety by routing files to security scanners. Available as a command line tool in Rust, Python API, and bindings for Rust, JavaScript/TypeScript, and GoLang.

mscclpp
MSCCL++ is a GPU-driven communication stack for scalable AI applications. It provides a highly efficient and customizable communication stack for distributed GPU applications. MSCCL++ redefines inter-GPU communication interfaces, delivering a highly efficient and customizable communication stack for distributed GPU applications. Its design is specifically tailored to accommodate diverse performance optimization scenarios often encountered in state-of-the-art AI applications. MSCCL++ provides communication abstractions at the lowest level close to hardware and at the highest level close to application API. The lowest level of abstraction is ultra light weight which enables a user to implement logics of data movement for a collective operation such as AllReduce inside a GPU kernel extremely efficiently without worrying about memory ordering of different ops. The modularity of MSCCL++ enables a user to construct the building blocks of MSCCL++ in a high level abstraction in Python and feed them to a CUDA kernel in order to facilitate the user's productivity. MSCCL++ provides fine-grained synchronous and asynchronous 0-copy 1-sided abstracts for communication primitives such as `put()`, `get()`, `signal()`, `flush()`, and `wait()`. The 1-sided abstractions allows a user to asynchronously `put()` their data on the remote GPU as soon as it is ready without requiring the remote side to issue any receive instruction. This enables users to easily implement flexible communication logics, such as overlapping communication with computation, or implementing customized collective communication algorithms without worrying about potential deadlocks. Additionally, the 0-copy capability enables MSCCL++ to directly transfer data between user's buffers without using intermediate internal buffers which saves GPU bandwidth and memory capacity. MSCCL++ provides consistent abstractions regardless of the location of the remote GPU (either on the local node or on a remote node) or the underlying link (either NVLink/xGMI or InfiniBand). This simplifies the code for inter-GPU communication, which is often complex due to memory ordering of GPU/CPU read/writes and therefore, is error-prone.

zshot
Zshot is a highly customizable framework for performing Zero and Few shot named entity and relationships recognition. It can be used for mentions extraction, wikification, zero and few shot named entity recognition, zero and few shot named relationship recognition, and visualization of zero-shot NER and RE extraction. The framework consists of two main components: the mentions extractor and the linker. There are multiple mentions extractors and linkers available, each serving a specific purpose. Zshot also includes a relations extractor and a knowledge extractor for extracting relations among entities and performing entity classification. The tool requires Python 3.6+ and dependencies like spacy, torch, transformers, evaluate, and datasets for evaluation over datasets like OntoNotes. Optional dependencies include flair and blink for additional functionalities. Zshot provides examples, tutorials, and evaluation methods to assess the performance of the components.
zep
Zep is a long-term memory service for AI Assistant apps. With Zep, you can provide AI assistants with the ability to recall past conversations, no matter how distant, while also reducing hallucinations, latency, and cost. Zep persists and recalls chat histories, and automatically generates summaries and other artifacts from these chat histories. It also embeds messages and summaries, enabling you to search Zep for relevant context from past conversations. Zep does all of this asyncronously, ensuring these operations don't impact your user's chat experience. Data is persisted to database, allowing you to scale out when growth demands. Zep also provides a simple, easy to use abstraction for document vector search called Document Collections. This is designed to complement Zep's core memory features, but is not designed to be a general purpose vector database. Zep allows you to be more intentional about constructing your prompt: 1. automatically adding a few recent messages, with the number customized for your app; 2. a summary of recent conversations prior to the messages above; 3. and/or contextually relevant summaries or messages surfaced from the entire chat session. 4. and/or relevant Business data from Zep Document Collections.
Next-Gen-Dialogue
Next Gen Dialogue is a Unity dialogue plugin that combines traditional dialogue design with AI techniques. It features a visual dialogue editor, modular dialogue functions, AIGC support for generating dialogue at runtime, AIGC baking dialogue in Editor, and runtime debugging. The plugin aims to provide an experimental approach to dialogue design using large language models. Users can create dialogue trees, generate dialogue content using AI, and bake dialogue content in advance. The tool also supports localization, VITS speech synthesis, and one-click translation. Users can create dialogue by code using the DialogueSystem and DialogueTree components.
palimpzest
Palimpzest (PZ) is a tool for managing and optimizing workloads, particularly for data processing tasks. It provides a CLI tool and Python demos for users to register datasets, run workloads, and access results. Users can easily initialize their system, register datasets, and manage configurations using the CLI commands provided. Palimpzest also supports caching intermediate results and configuring for parallel execution with remote services like OpenAI and together.ai. The tool aims to streamline the workflow of working with datasets and optimizing performance for data extraction tasks.
falkon
Falkon is a Python implementation of the Falkon algorithm for large-scale, approximate kernel ridge regression. The code is optimized for scalability to large datasets with tens of millions of points and beyond. Full kernel matrices are never computed explicitly so that you will not run out of memory on larger problems. Preconditioned conjugate gradient optimization ensures that only few iterations are necessary to obtain good results. The basic algorithm is a Nyström approximation to kernel ridge regression, which needs only three hyperparameters: 1. The number of centers M - this controls the quality of the approximation: a higher number of centers will produce more accurate results at the expense of more computation time, and higher memory requirements. 2. The penalty term, which controls the amount of regularization. 3. The kernel function. A good default is always the Gaussian (RBF) kernel (`falkon.kernels.GaussianKernel`).

AIF360
The AI Fairness 360 toolkit is an open-source library designed to detect and mitigate bias in machine learning models. It provides a comprehensive set of metrics, explanations, and algorithms for bias mitigation in various domains such as finance, healthcare, and education. The toolkit supports multiple bias mitigation algorithms and fairness metrics, and is available in both Python and R. Users can leverage the toolkit to ensure fairness in AI applications and contribute to its development for extensibility.
For similar tasks
multilspy
Multilspy is a Python library developed for research purposes to facilitate the creation of language server clients for querying and obtaining results of static analyses from various language servers. It simplifies the process by handling server setup, communication, and configuration parameters, providing a common interface for different languages. The library supports features like finding function/class definitions, callers, completions, hover information, and document symbols. It is designed to work with AI systems like Large Language Models (LLMs) for tasks such as Monitor-Guided Decoding to ensure code generation correctness and boost compilability.
pyllms
PyLLMs is a minimal Python library designed to connect to various Language Model Models (LLMs) such as OpenAI, Anthropic, Google, AI21, Cohere, Aleph Alpha, and HuggingfaceHub. It provides a built-in model performance benchmark for fast prototyping and evaluating different models. Users can easily connect to top LLMs, get completions from multiple models simultaneously, and evaluate models on quality, speed, and cost. The library supports asynchronous completion, streaming from compatible models, and multi-model initialization for testing and comparison. Additionally, it offers features like passing chat history, system messages, counting tokens, and benchmarking models based on quality, speed, and cost.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.