
pyOllaMx
Your gateway to both Ollama & Apple MlX models
Stars: 61
PyOllaMx is a chatbot application that serves as a gateway to both Ollama and Apple MlX models. It allows users to chat with these models through a native MacOS interface, eliminating the need for external applications like Bing or Chat-GPT. The tool provides a versatile and user-friendly experience for interacting with different models, enabling tasks such as model discovery, model management, chatting, and web searching. PyOllaMx simplifies the workflow for users who want to leverage Ollama and MlX models on their Mac devices.
README:


Inspired by Ollama, Apple MlX projects and frustrated by the dependencies from external applications like Bing, Chat-GPT etc, I wanted to have my own personal chatbot as a native MacOS application. Sure there are alternatives like streamlit, gradio (which are based, thereby needing a browser) or others like Ollamac, LMStudio, mindmac etc which are good but then restrictive in some means (either by license, or paid or not versatile). Also I wanted to enjoy both Ollama (based on llama.cpp) and Mlx models (which are suitable for image generation, audio generation etc and heck I own a mac with Apple silicon 👨🏻💻) through a single uniform interface.
All these lead to this project (PyOllaMx) and another sister project called PyOMlx.
I'm using these in my day to day workflow and I intend to keep develop these for my use and benefit.
If you find this valuable, feel free to use it and contribute to this project as well. Please ⭐️ this repo to show your support and make my day!
I'm planning on work on next items on this roadmap.md. Feel free to comment your thoughts (if any) and influence my work (if interested)
MacOS DMGs are available in Releases
PyOllaMx : ChatBot application capable of chatting with both Ollama and Apple MlX models. For this app to function, it needs both Ollama & PyOMlx macos app running. These 2 apps will serve their respective models on localhost for PyOllaMx to chat.
PyOMlx : A Macos App capable of discovering, loading & serving Apple MlX models downloaded from Apple MLX Community repo in hugging face 🤗
- Install Ollama Application & use Ollama CLI to download your desired models
ollama pull <model name>
ollama pull mistral
This command will download the Ollama models in a known location to PyOllaMx
[!TIP] As of PyOllaMx v0.0.4, you can download & manage ollama models right within PyOllaMx's ModelHub. Check the v0.0.4 release page for more details
- Install MlX Models from Hugging Face repo.
use hugging-face cli
pip install huggingface_hub hf_transfer
export HF_HUB_ENABLE_HF_TRANSFER=1
huggingface-cli download mlx-community/CodeLlama-7b-Python-4bit-MLX
This command will download the MlX models in a known location to PyOllaMx
- Now simply open the PyOllaMx and start chatting

Now you can download Ollama models right within 🤌🏻 PyOllaMx's Model Hub tab. You can also inspect existing models 🧐, delete models 🗑️ right within PyOllaMx instead of using Ollama CLI. This greatly simplifies the user experience 🤩🤩. And you before you ask, yes I'm working to bring similar functionality for MLX models from huggingface hub. Please stay tuned 😎
- Updated DDGS dependency to fix some of the rate limit issues
Click the release version link above ☝🏻 to view demo gifs explaining the features.
- Dark mode support - Toggle between Dark & Light mode with a click of the icon
- Model settings menu - Brand new settings menu to set the model name and the temperature along with Ollama & MlX model toggle
- Streaming support - Streaming support for both chat & search tasks
- Brand New Status bar - Status bar that displays the selected mode name, model type & model temperature
- Web search enabled for Apple MlX models - Now you can use Apple MlX models to power the web search when choosing the search tab
Click the release version link above ☝🏻 to view demo gifs explaining the features.
- Web search capability (powered by DuckDuckGo search engine via https://github.com/deedy5/duckduckgo_search) a. Web search powered via basic RAG using prompt engineering. More advanced techniques are in pipeline b. Search response will cite clickable sources for easy follow-up / deep dive c. Beneath every search response, search keywords are also shown to verify the search scope d. Easy toggle between chat and search operations
- Clear / Erase history
- Automatic scroll on chat messages for better user experience
- Basic error & exception handling for searches
Limitations:
- Web search only enabled for Ollama models. Use dolphin-mistral:7b model for better results. MlX model support is planned for next release
- Search results aren't deterministic and vary vastly among the chosen models. So play with different models to find your optimum
- Sometimes search results are gibberish. It is due to the fact that search engine RAG is vanilla i.e done via basic prompt engineering without any library support. So re-trigger the same search prompt and see the response once again if the results aren't satisfactory.
Click the release version link above ☝🏻 to view demo gifs explaining the features.
- Auto discover Ollama & MlX models. Simply download the models as you do with respective tools and pyOllaMx would pull the models seamlessly
- Markdown support on chat messages for programming code
- Selectable Text
- Temperature control
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for pyOllaMx
Similar Open Source Tools
pyOllaMx
PyOllaMx is a chatbot application that serves as a gateway to both Ollama and Apple MlX models. It allows users to chat with these models through a native MacOS interface, eliminating the need for external applications like Bing or Chat-GPT. The tool provides a versatile and user-friendly experience for interacting with different models, enabling tasks such as model discovery, model management, chatting, and web searching. PyOllaMx simplifies the workflow for users who want to leverage Ollama and MlX models on their Mac devices.
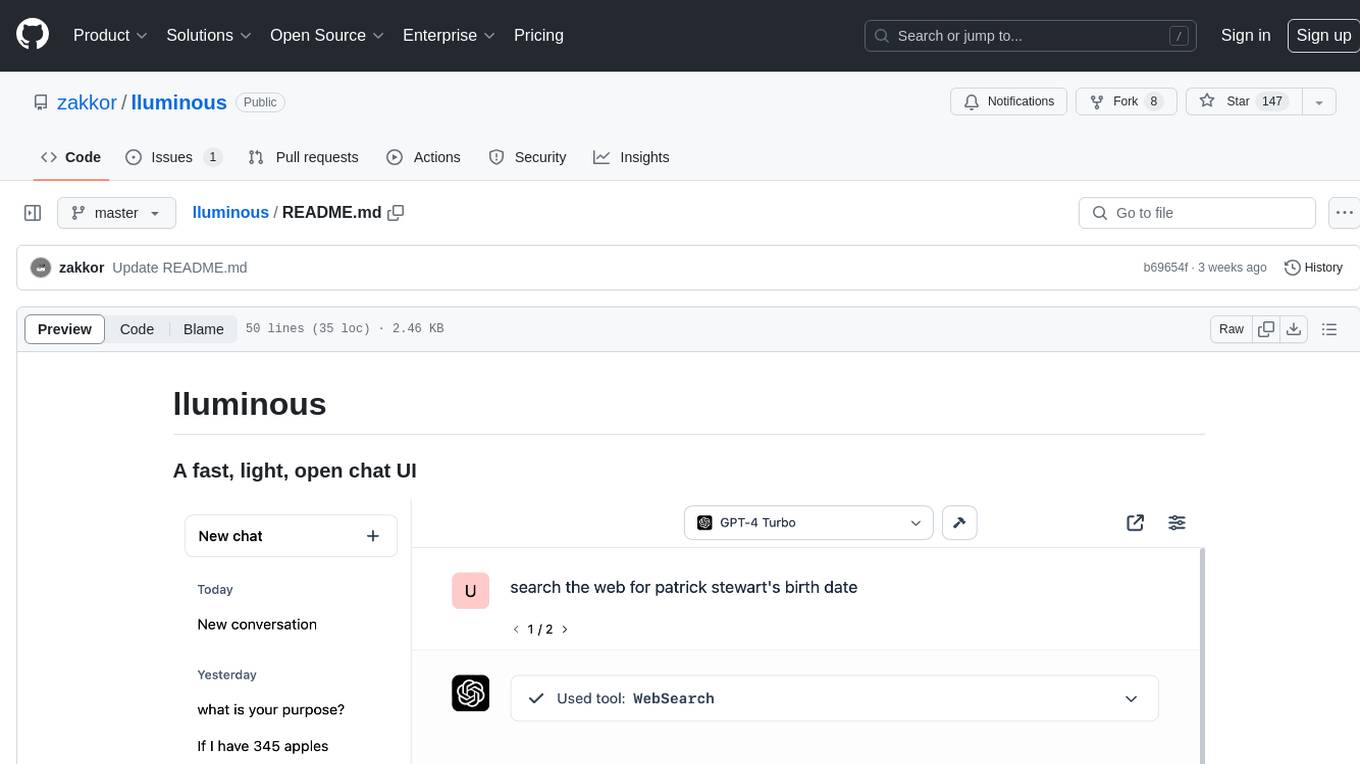
lluminous
lluminous is a fast and light open chat UI that supports multiple providers such as OpenAI, Anthropic, and Groq models. Users can easily plug in their API keys locally to access various models for tasks like multimodal input, image generation, multi-shot prompting, pre-filled responses, and more. The tool ensures privacy by storing all conversation history and keys locally on the user's device. Coming soon features include memory tool, file ingestion/embedding, embeddings-based web search, and prompt templates.
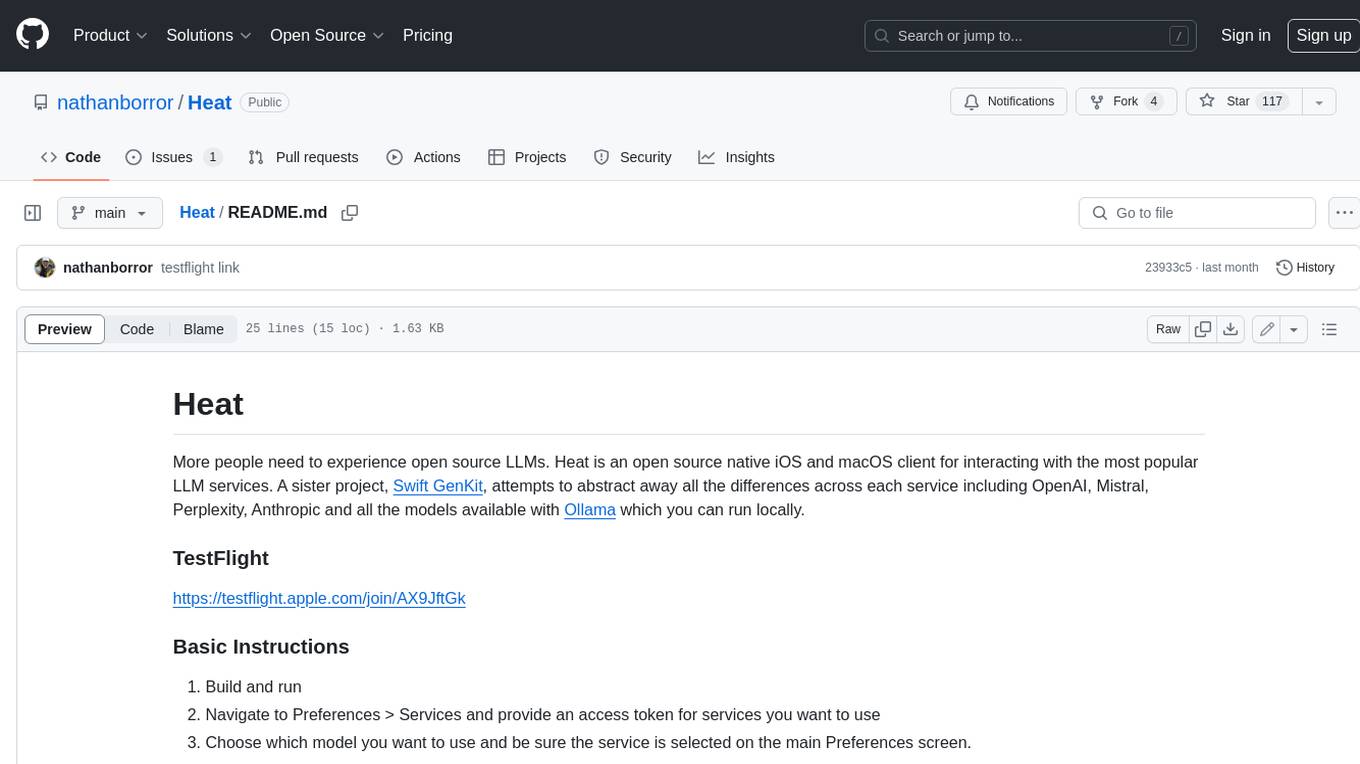
Heat
Heat is an open source native iOS and macOS client for interacting with the most popular LLM services. A sister project, Swift GenKit, attempts to abstract away all the differences across each service including OpenAI, Mistral, Perplexity, Anthropic and all the models available with Ollama which you can run locally.
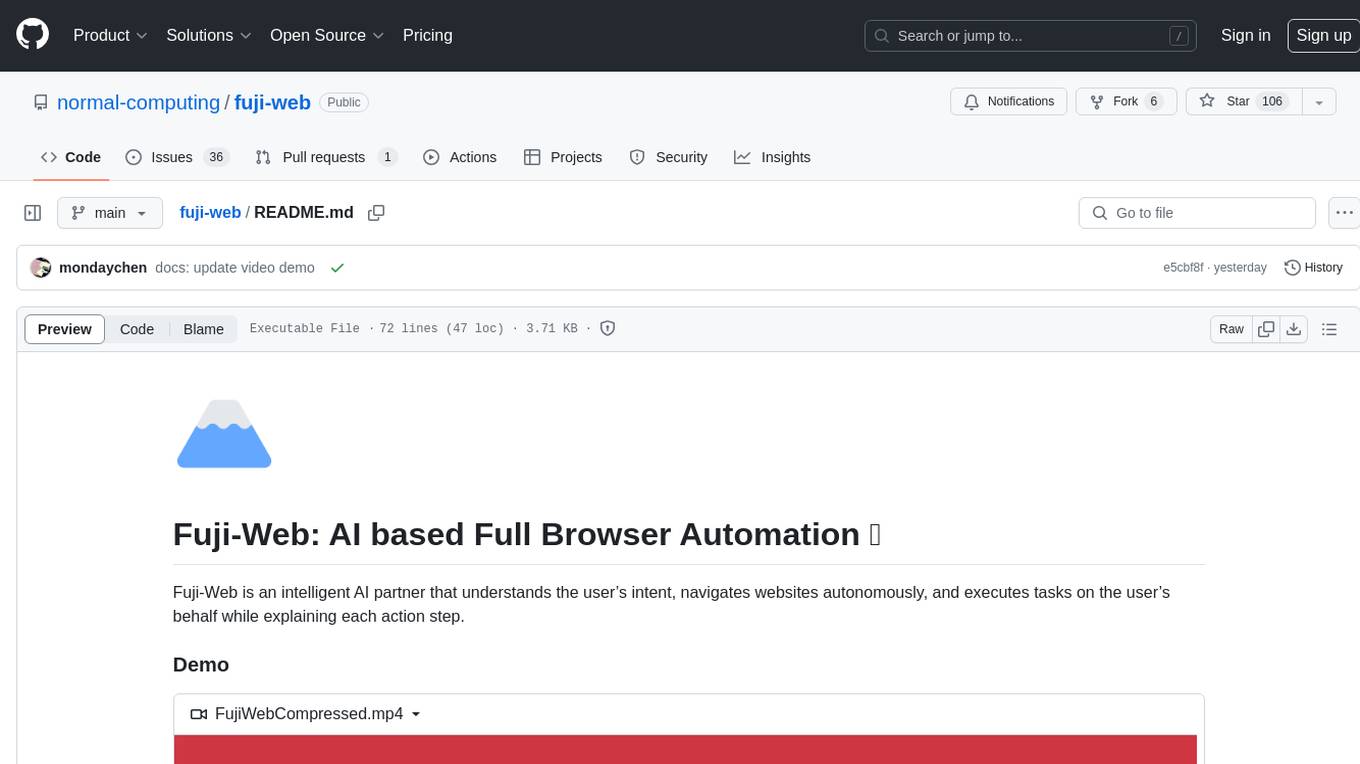
fuji-web
Fuji-Web is an intelligent AI partner designed for full browser automation. It autonomously navigates websites and performs tasks on behalf of the user while providing explanations for each action step. Users can easily install the extension in their browser, access the Fuji icon to input tasks, and interact with the tool to streamline web browsing tasks. The tool aims to enhance user productivity by automating repetitive web actions and providing a seamless browsing experience.
FlowTest
FlowTestAI is the world’s first GenAI powered OpenSource Integrated Development Environment (IDE) designed for crafting, visualizing, and managing API-first workflows. It operates as a desktop app, interacting with the local file system, ensuring privacy and enabling collaboration via version control systems. The platform offers platform-specific binaries for macOS, with versions for Windows and Linux in development. It also features a CLI for running API workflows from the command line interface, facilitating automation and CI/CD processes.

helix
HelixML is a private GenAI platform that allows users to deploy the best of open AI in their own data center or VPC while retaining complete data security and control. It includes support for fine-tuning models with drag-and-drop functionality. HelixML brings the best of open source AI to businesses in an ergonomic and scalable way, optimizing the tradeoff between GPU memory and latency.
dialog
Dialog is an API-focused tool designed to simplify the deployment of Large Language Models (LLMs) for programmers interested in AI. It allows users to deploy any LLM based on the structure provided by dialog-lib, enabling them to spend less time coding and more time training their models. The tool aims to humanize Retrieval-Augmented Generative Models (RAGs) and offers features for better RAG deployment and maintenance. Dialog requires a knowledge base in CSV format and a prompt configuration in TOML format to function effectively. It provides functionalities for loading data into the database, processing conversations, and connecting to the LLM, with options to customize prompts and parameters. The tool also requires specific environment variables for setup and configuration.
TagUI
TagUI is an open-source RPA tool that allows users to automate repetitive tasks on their computer, including tasks on websites, desktop apps, and the command line. It supports multiple languages and offers features like interacting with identifiers, automating data collection, moving data between TagUI and Excel, and sending Telegram notifications. Users can create RPA robots using MS Office Plug-ins or text editors, run TagUI on the cloud, and integrate with other RPA tools. TagUI prioritizes enterprise security by running on users' computers and not storing data. It offers detailed logs, enterprise installation guides, and support for centralised reporting.
bytechef
ByteChef is an open-source, low-code, extendable API integration and workflow automation platform. It provides an intuitive UI Workflow Editor, event-driven & scheduled workflows, multiple flow controls, built-in code editor supporting Java, JavaScript, Python, and Ruby, rich component ecosystem, extendable with custom connectors, AI-ready with built-in AI components, developer-ready to expose workflows as APIs, version control friendly, self-hosted, scalable, and resilient. It allows users to build and visualize workflows, automate tasks across SaaS apps, internal APIs, and databases, and handle millions of workflows with high availability and fault tolerance.

gen-cv
This repository is a rich resource offering examples of synthetic image generation, manipulation, and reasoning using Azure Machine Learning, Computer Vision, OpenAI, and open-source frameworks like Stable Diffusion. It provides practical insights into image processing applications, including content generation, video analysis, avatar creation, and image manipulation with various tools and APIs.
autoMate
autoMate is an AI-powered local automation tool designed to help users automate repetitive tasks and reclaim their time. It leverages AI and RPA technology to operate computer interfaces, understand screen content, make autonomous decisions, and support local deployment for data security. With natural language task descriptions, users can easily automate complex workflows without the need for programming knowledge. The tool aims to transform work by freeing users from mundane activities and allowing them to focus on tasks that truly create value, enhancing efficiency and liberating creativity.

supervisely
Supervisely is a computer vision platform that provides a range of tools and services for developing and deploying computer vision solutions. It includes a data labeling platform, a model training platform, and a marketplace for computer vision apps. Supervisely is used by a variety of organizations, including Fortune 500 companies, research institutions, and government agencies.
chat-with-code
Chat-with-code is a codebase chatbot that enables users to interact with their codebase using the OpenAI Language Model. It provides a user-friendly chat interface where users can ask questions and interact with their code. The tool clones, chunks, and embeds the codebase, allowing for natural language interactions. It is designed to assist users in exploring and understanding their codebase more intuitively.
dewhale
Dewhale is a GitHub-Powered AI tool designed for effortless development. It utilizes prompt engineering techniques under the GPT-4 model to issue commands, allowing users to generate code with lower usage costs and easy customization. The tool seamlessly integrates with GitHub, providing version control, code review, and collaborative features. Users can join discussions on the design philosophy of Dewhale and explore detailed instructions and examples for setting up and using the tool.
aws-bedrock-with-rag-and-react
This solution provides a low-code ReactJS application to prototype and vet business use cases for GenAI using Retrieval Augmented Generation (RAG). It includes a backend Flask application that uses LangChain to provide PDF data as embeddings to a text-gen model via Amazon Bedrock and a vector database with FAISS or Kendra Index. The solution utilizes Amazon Bedrock as the only cost-generating AWS service.
deforum-comfy-nodes
Deforum for ComfyUI is an integration tool designed to enhance the user experience of using ComfyUI. It provides custom nodes that can be added to ComfyUI to improve functionality and workflow. Users can easily install Deforum for ComfyUI by cloning the repository and following the provided instructions. The tool is compatible with Python v3.10 and is recommended to be used within a virtual environment. Contributions to the tool are welcome, and users can join the Discord community for support and discussions.
For similar tasks
elia
Elia is a powerful terminal user interface designed for interacting with large language models. It allows users to chat with models like Claude 3, ChatGPT, Llama 3, Phi 3, Mistral, and Gemma. Conversations are stored locally in a SQLite database, ensuring privacy. Users can run local models through 'ollama' without data leaving their machine. Elia offers easy installation with pipx and supports various environment variables for different models. It provides a quick start to launch chats and manage local models. Configuration options are available to customize default models, system prompts, and add new models. Users can import conversations from ChatGPT and wipe the database when needed. Elia aims to enhance user experience in interacting with language models through a user-friendly interface.

mistral-inference
Mistral Inference repository contains minimal code to run 7B, 8x7B, and 8x22B models. It provides model download links, installation instructions, and usage guidelines for running models via CLI or Python. The repository also includes information on guardrailing, model platforms, deployment, and references. Users can interact with models through commands like mistral-demo, mistral-chat, and mistral-common. Mistral AI models support function calling and chat interactions for tasks like testing models, chatting with models, and using Codestral as a coding assistant. The repository offers detailed documentation and links to blogs for further information.
LLMFlex
LLMFlex is a python package designed for developing AI applications with local Large Language Models (LLMs). It provides classes to load LLM models, embedding models, and vector databases to create AI-powered solutions with prompt engineering and RAG techniques. The package supports multiple LLMs with different generation configurations, embedding toolkits, vector databases, chat memories, prompt templates, custom tools, and a chatbot frontend interface. Users can easily create LLMs, load embeddings toolkit, use tools, chat with models in a Streamlit web app, and serve an OpenAI API with a GGUF model. LLMFlex aims to offer a simple interface for developers to work with LLMs and build private AI solutions using local resources.
minimal-chat
MinimalChat is a minimal and lightweight open-source chat application with full mobile PWA support that allows users to interact with various language models, including GPT-4 Omni, Claude Opus, and various Local/Custom Model Endpoints. It focuses on simplicity in setup and usage while being fully featured and highly responsive. The application supports features like fully voiced conversational interactions, multiple language models, markdown support, code syntax highlighting, DALL-E 3 integration, conversation importing/exporting, and responsive layout for mobile use.
chat-with-mlx
Chat with MLX is an all-in-one Chat Playground using Apple MLX on Apple Silicon Macs. It provides privacy-enhanced AI for secure conversations with various models, easy integration of HuggingFace and MLX Compatible Open-Source Models, and comes with default models like Llama-3, Phi-3, Yi, Qwen, Mistral, Codestral, Mixtral, StableLM. The tool is designed for developers and researchers working with machine learning models on Apple Silicon.

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.
ell
ell is a command-line interface for Language Model Models (LLMs) written in Bash. It allows users to interact with LLMs from the terminal, supports piping, context bringing, and chatting with LLMs. Users can also call functions and use templates. The tool requires bash, jq for JSON parsing, curl for HTTPS requests, and perl for PCRE. Configuration involves setting variables for different LLM models and APIs. Usage examples include asking questions, specifying models, recording input/output, running in interactive mode, and using templates. The tool is lightweight, easy to install, and pipe-friendly, making it suitable for interacting with LLMs in a terminal environment.
Ollama-SwiftUI
Ollama-SwiftUI is a user-friendly interface for Ollama.ai created in Swift. It allows seamless chatting with local Large Language Models on Mac. Users can change models mid-conversation, restart conversations, send system prompts, and use multimodal models with image + text. The app supports managing models, including downloading, deleting, and duplicating them. It offers light and dark mode, multiple conversation tabs, and a localized interface in English and Arabic.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.