
KrillinAI
A video translation and dubbing tool powered by LLMs, offering 99 language translations and one-click full-process deployment. It can generate content optimized for platforms like YouTube,TikTok, and Shorts. AI视频翻译配音工具,99种语言双向翻译,一键部署全流程,可以生成适配抖音,小红书,哔哩哔哩,视频号,TikTok,Youtube Shorts等形态的内容
Stars: 8459
KrillinAI is a video subtitle translation and dubbing tool based on AI large models, featuring speech recognition, intelligent sentence segmentation, professional translation, and one-click deployment of the entire process. It provides a one-stop workflow from video downloading to the final product, empowering cross-language cultural communication with AI. The tool supports multiple languages for input and translation, integrates features like automatic dependency installation, video downloading from platforms like YouTube and Bilibili, high-speed subtitle recognition, intelligent subtitle segmentation and alignment, custom vocabulary replacement, professional-level translation engine, and diverse external service selection for speech and large model services.
README:
Project Introduction (Try the online version now!)
KrillinAI is a versatile audio and video localization and enhancement solution developed by Krillin AI. This minimalist yet powerful tool integrates video translation, dubbing, and voice cloning, supporting both landscape and portrait formats to ensure perfect presentation on all major platforms (Bilibili, Xiaohongshu, Douyin, WeChat Video, Kuaishou, YouTube, TikTok, etc.). With an end-to-end workflow, you can transform raw materials into beautifully ready-to-use cross-platform content with just a few clicks.
🎯 One-click Start: No complex environment configuration required, automatic dependency installation, ready to use immediately, with a new desktop version for easier access!
📥 Video Acquisition: Supports yt-dlp downloads or local file uploads
📜 Accurate Recognition: High-accuracy speech recognition based on Whisper
🧠 Intelligent Segmentation: Subtitle segmentation and alignment using LLM
🔄 Terminology Replacement: One-click replacement of professional vocabulary
🌍 Professional Translation: LLM translation with context to maintain natural semantics
🎙️ Voice Cloning: Offers selected voice tones from CosyVoice or custom voice cloning
🎬 Video Composition: Automatically processes landscape and portrait videos and subtitle layout
💻 Cross-Platform: Supports Windows, Linux, macOS, providing both desktop and server versions
The image below shows the effect of the subtitle file generated after importing a 46-minute local video and executing it with one click, without any manual adjustments. There are no omissions or overlaps, the segmentation is natural, and the translation quality is very high.

All local models in the table below support automatic installation of executable files + model files; you just need to choose, and Klic will prepare everything for you.
| Service Source | Supported Platforms | Model Options | Local/Cloud | Remarks |
|---|---|---|---|---|
| OpenAI Whisper | All Platforms | - | Cloud | Fast speed and good effect |
| FasterWhisper | Windows/Linux |
tiny/medium/large-v2 (recommended medium+) |
Local | Faster speed, no cloud service cost |
| WhisperKit | macOS (M-series only) | large-v2 |
Local | Native optimization for Apple chips |
| WhisperCpp | All Platforms | large-v2 |
Local | Supports all platforms |
| Alibaba Cloud ASR | All Platforms | - | Cloud | Avoids network issues in mainland China |
✅ Compatible with all cloud/local large language model services that comply with OpenAI API specifications, including but not limited to:
- OpenAI
- Gemini
- DeepSeek
- Tongyi Qianwen
- Locally deployed open-source models
- Other API services compatible with OpenAI format
- Alibaba Cloud Voice Service
- OpenAI TTS
Input languages supported: Chinese, English, Japanese, German, Turkish, Korean, Russian, Malay (continuously increasing)
Translation languages supported: English, Chinese, Russian, Spanish, French, and 101 other languages


You can ask questions on the Deepwiki of KrillinAI. It indexes the files in the repository, so you can find answers quickly.
First, download the executable file that matches your device system from the Release, then follow the tutorial below to choose between the desktop version or non-desktop version. Place the software download in an empty folder, as running it will generate some directories, and keeping it in an empty folder will make management easier.
【If it is the desktop version, i.e., the release file with "desktop," see here】 The desktop version is newly released to address the issues of new users struggling to edit configuration files correctly, and there are some bugs that are continuously being updated.
- Double-click the file to start using it (the desktop version also requires configuration within the software)
【If it is the non-desktop version, i.e., the release file without "desktop," see here】 The non-desktop version is the initial version, which has a more complex configuration but is stable in functionality and suitable for server deployment, as it provides a UI in a web format.
- Create a
configfolder within the folder, then create aconfig.tomlfile in theconfigfolder. Copy the contents of theconfig-example.tomlfile from the source code'sconfigdirectory intoconfig.toml, and fill in your configuration information according to the comments. - Double-click or execute the executable file in the terminal to start the service
- Open your browser and enter
http://127.0.0.1:8888to start using it (replace 8888 with the port you specified in the configuration file)
【If it is the desktop version, i.e., the release file with "desktop," see here】 Due to signing issues, the desktop version currently cannot be double-clicked to run or installed via dmg; you need to manually trust the application. The method is as follows:
- Open the terminal in the directory where the executable file (assuming the file name is KrillinAI_1.0.0_desktop_macOS_arm64) is located
- Execute the following commands in order:
sudo xattr -cr ./KrillinAI_1.0.0_desktop_macOS_arm64
sudo chmod +x ./KrillinAI_1.0.0_desktop_macOS_arm64
./KrillinAI_1.0.0_desktop_macOS_arm64
【If it is the non-desktop version, i.e., the release file without "desktop," see here】 This software is not signed, so when running on macOS, after completing the file configuration in the "Basic Steps," you also need to manually trust the application. The method is as follows:
-
Open the terminal in the directory where the executable file (assuming the file name is KrillinAI_1.0.0_macOS_arm64) is located
-
Execute the following commands in order:
sudo xattr -rd com.apple.quarantine ./KrillinAI_1.0.0_macOS_arm64 sudo chmod +x ./KrillinAI_1.0.0_macOS_arm64 ./KrillinAI_1.0.0_macOS_arm64This will start the service
This project supports Docker deployment; please refer to the Docker Deployment Instructions
Based on the provided configuration file, here is the updated "Configuration Help (Must Read)" section for your README file:
The configuration file is divided into several sections: [app], [server], [llm], [transcribe], and [tts]. A task is composed of speech recognition (transcribe) + large model translation (llm) + optional voice services (tts). Understanding this will help you better grasp the configuration file.
Easiest and Quickest Configuration:
For Subtitle Translation Only:
- In the
[transcribe]section, setprovider.nametoopenai. - You will then only need to fill in your OpenAI API key in the
[llm]block to start performing subtitle translations. Theapp.proxy,model, andopenai.base_urlcan be filled in as needed.
Balanced Cost, Speed, and Quality (Using Local Speech Recognition):
- In the
[transcribe]section, setprovider.nametofasterwhisper. - Set
transcribe.fasterwhisper.modeltolarge-v2. - Fill in your large language model configuration in the
[llm]block. - The required local model will be automatically downloaded and installed.
Text-to-Speech (TTS) Configuration (Optional):
- TTS configuration is optional.
- First, set the
provider.nameunder the[tts]section (e.g.,aliyunoropenai). - Then, fill in the corresponding configuration block for the selected provider. For example, if you choose
aliyun, you must fill in the[tts.aliyun]section. - Voice codes in the user interface should be chosen based on the selected provider's documentation.
-
Note: If you plan to use the voice cloning feature, you must select
aliyunas the TTS provider.
Alibaba Cloud Configuration:
- For details on obtaining the necessary
AccessKey,Bucket, andAppKeyfor Alibaba Cloud services, please refer to the Alibaba Cloud Configuration Instructions. The repeated fields for AccessKey, etc., are designed to maintain a clear configuration structure.
Please visit Frequently Asked Questions
- Do not submit useless files, such as .vscode, .idea, etc.; please use .gitignore to filter them out.
- Do not submit config.toml; instead, submit config-example.toml.
- Join our QQ group for questions: 754069680
- Follow our social media accounts, Bilibili, where we share quality content in the AI technology field every day.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for KrillinAI
Similar Open Source Tools
KrillinAI
KrillinAI is a video subtitle translation and dubbing tool based on AI large models, featuring speech recognition, intelligent sentence segmentation, professional translation, and one-click deployment of the entire process. It provides a one-stop workflow from video downloading to the final product, empowering cross-language cultural communication with AI. The tool supports multiple languages for input and translation, integrates features like automatic dependency installation, video downloading from platforms like YouTube and Bilibili, high-speed subtitle recognition, intelligent subtitle segmentation and alignment, custom vocabulary replacement, professional-level translation engine, and diverse external service selection for speech and large model services.

KlicStudio
Klic Studio is a versatile audio and video localization and enhancement solution developed by Krillin AI. This minimalist yet powerful tool integrates video translation, dubbing, and voice cloning, supporting both landscape and portrait formats. With an end-to-end workflow, users can transform raw materials into beautifully ready-to-use cross-platform content with just a few clicks. The tool offers features like video acquisition, accurate speech recognition, intelligent segmentation, terminology replacement, professional translation, voice cloning, video composition, and cross-platform support. It also supports various speech recognition services, large language models, and TTS text-to-speech services. Users can easily deploy the tool using Docker and configure it for different tasks like subtitle translation, large model translation, and optional voice services.

RainbowGPT
RainbowGPT is a versatile tool that offers a range of functionalities, including Stock Analysis for financial decision-making, MySQL Management for database navigation, and integration of AI technologies like GPT-4 and ChatGlm3. It provides a user-friendly interface suitable for all skill levels, ensuring seamless information flow and continuous expansion of emerging technologies. The tool enhances adaptability, creativity, and insight, making it a valuable asset for various projects and tasks.

deep-research
Deep Research is a lightning-fast tool that uses powerful AI models to generate comprehensive research reports in just a few minutes. It leverages advanced 'Thinking' and 'Task' models, combined with an internet connection, to provide fast and insightful analysis on various topics. The tool ensures privacy by processing and storing all data locally. It supports multi-platform deployment, offers support for various large language models, web search functionality, knowledge graph generation, research history preservation, local and server API support, PWA technology, multi-key payload support, multi-language support, and is built with modern technologies like Next.js and Shadcn UI. Deep Research is open-source under the MIT License.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.

atropos
Atropos is a robust and scalable framework for Reinforcement Learning Environments with Large Language Models (LLMs). It provides a flexible platform to accelerate LLM-based RL research across diverse interactive settings. Atropos supports multi-turn and asynchronous RL interactions, integrates with various inference APIs, offers a standardized training interface for experimenting with different RL algorithms, and allows for easy scalability by launching more environment instances. The framework manages diverse environment types concurrently for heterogeneous, multi-modal training.

OpenAdapt
OpenAdapt is an open-source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs). It aims to automate repetitive GUI workflows by leveraging the power of LMMs. OpenAdapt records user input and screenshots, converts them into tokenized format, and generates synthetic input via transformer model completions. It also analyzes recordings to generate task trees and replay synthetic input to complete tasks. OpenAdapt is model agnostic and generates prompts automatically by learning from human demonstration, ensuring that agents are grounded in existing processes and mitigating hallucinations. It works with all types of desktop GUIs, including virtualized and web, and is open source under the MIT license.

ChatDev
ChatDev is a virtual software company powered by intelligent agents like CEO, CPO, CTO, programmer, reviewer, tester, and art designer. These agents collaborate to revolutionize the digital world through programming. The platform offers an easy-to-use, highly customizable, and extendable framework based on large language models, ideal for studying collective intelligence. ChatDev introduces innovative methods like Iterative Experience Refinement and Experiential Co-Learning to enhance software development efficiency. It supports features like incremental development, Docker integration, Git mode, and Human-Agent-Interaction mode. Users can customize ChatChain, Phase, and Role settings, and share their software creations easily. The project is open-source under the Apache 2.0 License and utilizes data licensed under CC BY-NC 4.0.
evidently
Evidently is an open-source Python library designed for evaluating, testing, and monitoring machine learning (ML) and large language model (LLM) powered systems. It offers a wide range of functionalities, including working with tabular, text data, and embeddings, supporting predictive and generative systems, providing over 100 built-in metrics for data drift detection and LLM evaluation, allowing for custom metrics and tests, enabling both offline evaluations and live monitoring, and offering an open architecture for easy data export and integration with existing tools. Users can utilize Evidently for one-off evaluations using Reports or Test Suites in Python, or opt for real-time monitoring through the Dashboard service.
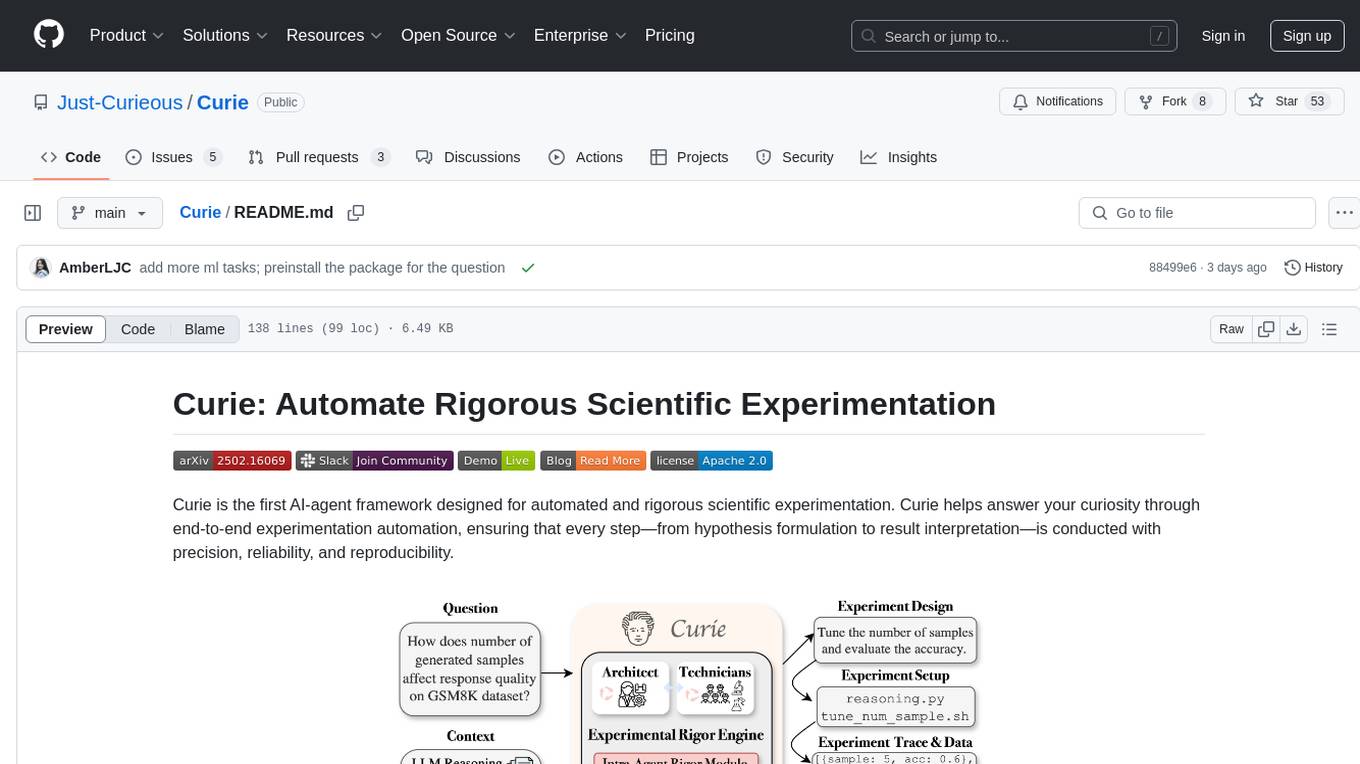
Curie
Curie is an AI-agent framework designed for automated and rigorous scientific experimentation. It automates end-to-end workflow management, ensures methodical procedure, reliability, and interpretability, and supports ML research, system analysis, and scientific discovery. It provides a benchmark with questions from 4 Computer Science domains. Users can customize experiment agents and adapt to their own tasks by configuring base_config.json. Curie is suitable for hyperparameter tuning, algorithm behavior analysis, system performance benchmarking, and automating computational simulations.

giskard
Giskard is an open-source Python library that automatically detects performance, bias & security issues in AI applications. The library covers LLM-based applications such as RAG agents, all the way to traditional ML models for tabular data.
Neurite
Neurite is an innovative project that combines chaos theory and graph theory to create a digital interface that explores hidden patterns and connections for creative thinking. It offers a unique workspace blending fractals with mind mapping techniques, allowing users to navigate the Mandelbrot set in real-time. Nodes in Neurite represent various content types like text, images, videos, code, and AI agents, enabling users to create personalized microcosms of thoughts and inspirations. The tool supports synchronized knowledge management through bi-directional synchronization between mind-mapping and text-based hyperlinking. Neurite also features FractalGPT for modular conversation with AI, local AI capabilities for multi-agent chat networks, and a Neural API for executing code and sequencing animations. The project is actively developed with plans for deeper fractal zoom, advanced control over node placement, and experimental features.
metta
Metta AI is an open-source research project focusing on the emergence of cooperation and alignment in multi-agent AI systems. It explores the impact of social dynamics like kinship and mate selection on learning and cooperative behaviors of AI agents. The project introduces a reward-sharing mechanism mimicking familial bonds and mate selection to observe the evolution of complex social behaviors among AI agents. Metta aims to contribute to the discussion on safe and beneficial AGI by creating an environment where AI agents can develop general intelligence through continuous learning and adaptation.

graphiti
Graphiti is a framework for building and querying temporally-aware knowledge graphs, tailored for AI agents in dynamic environments. It continuously integrates user interactions, structured and unstructured data, and external information into a coherent, queryable graph. The framework supports incremental data updates, efficient retrieval, and precise historical queries without complete graph recomputation, making it suitable for developing interactive, context-aware AI applications.
VideoLingo
VideoLingo is an all-in-one video translation and localization dubbing tool designed to generate Netflix-level high-quality subtitles. It aims to eliminate stiff machine translation, multiple lines of subtitles, and can even add high-quality dubbing, allowing knowledge from around the world to be shared across language barriers. Through an intuitive Streamlit web interface, the entire process from video link to embedded high-quality bilingual subtitles and even dubbing can be completed with just two clicks, easily creating Netflix-quality localized videos. Key features and functions include using yt-dlp to download videos from Youtube links, using WhisperX for word-level timeline subtitle recognition, using NLP and GPT for subtitle segmentation based on sentence meaning, summarizing intelligent term knowledge base with GPT for context-aware translation, three-step direct translation, reflection, and free translation to eliminate strange machine translation, checking single-line subtitle length and translation quality according to Netflix standards, using GPT-SoVITS for high-quality aligned dubbing, and integrating package for one-click startup and one-click output in streamlit.

AIOS
AIOS, a Large Language Model (LLM) Agent operating system, embeds large language model into Operating Systems (OS) as the brain of the OS, enabling an operating system "with soul" -- an important step towards AGI. AIOS is designed to optimize resource allocation, facilitate context switch across agents, enable concurrent execution of agents, provide tool service for agents, maintain access control for agents, and provide a rich set of toolkits for LLM Agent developers.
For similar tasks
KrillinAI
KrillinAI is a video subtitle translation and dubbing tool based on AI large models, featuring speech recognition, intelligent sentence segmentation, professional translation, and one-click deployment of the entire process. It provides a one-stop workflow from video downloading to the final product, empowering cross-language cultural communication with AI. The tool supports multiple languages for input and translation, integrates features like automatic dependency installation, video downloading from platforms like YouTube and Bilibili, high-speed subtitle recognition, intelligent subtitle segmentation and alignment, custom vocabulary replacement, professional-level translation engine, and diverse external service selection for speech and large model services.
Webscout
WebScout is a versatile tool that allows users to search for anything using Google, DuckDuckGo, and phind.com. It contains AI models, can transcribe YouTube videos, generate temporary email and phone numbers, has TTS support, webai (terminal GPT and open interpreter), and offline LLMs. It also supports features like weather forecasting, YT video downloading, temp mail and number generation, text-to-speech, advanced web searches, and more.
DownEdit
DownEdit is a fast and powerful program for downloading and editing videos from platforms like TikTok, Douyin, and Kuaishou. It allows users to effortlessly grab videos, make bulk edits, and utilize advanced AI features for generating videos, images, and sounds in bulk. The tool offers features like video, photo, and sound editing, downloading videos without watermarks, bulk AI generation, and AI editing for content enhancement.

AIO-Video-Downloader
AIO Video Downloader is an open-source Android application built on the robust yt-dlp backend with the help of youtubedl-android. It aims to be the most powerful download manager available, offering a clean and efficient interface while unlocking advanced downloading capabilities with minimal setup. With support for 1000+ sites and virtually any downloadable content across the web, AIO delivers a seamless yet powerful experience that balances speed, flexibility, and simplicity.
Y2A-Auto
Y2A-Auto is an automation tool that transfers YouTube videos to AcFun. It automates the entire process from downloading, translating subtitles, content moderation, intelligent tagging, to partition recommendation and upload. It also includes a web management interface and YouTube monitoring feature. The tool supports features such as downloading videos and covers using yt-dlp, AI translation and embedding of subtitles, AI generation of titles/descriptions/tags, content moderation using Aliyun Green, uploading to AcFun, task management, manual review, and forced upload. It also offers settings for automatic mode, concurrency, proxies, subtitles, login protection, brute force lock, YouTube monitoring, channel/trend capturing, scheduled tasks, history records, optional GPU/hardware acceleration, and Docker deployment or local execution.
Friend
Friend is an open-source AI wearable device that records everything you say, gives you proactive feedback and advice. It has real-time AI audio processing capabilities, low-powered Bluetooth, open-source software, and a wearable design. The device is designed to be affordable and easy to use, with a total cost of less than $20. To get started, you can clone the repo, choose the version of the app you want to install, and follow the instructions for installing the firmware and assembling the device. Friend is still a prototype project and is provided "as is", without warranty of any kind. Use of the device should comply with all local laws and regulations concerning privacy and data protection.

agents
The LiveKit Agent Framework is designed for building real-time, programmable participants that run on servers. Easily tap into LiveKit WebRTC sessions and process or generate audio, video, and data streams. The framework includes plugins for common workflows, such as voice activity detection and speech-to-text. Agents integrates seamlessly with LiveKit server, offloading job queuing and scheduling responsibilities to it. This eliminates the need for additional queuing infrastructure. Agent code developed on your local machine can scale to support thousands of concurrent sessions when deployed to a server in production.

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.