
wordlift-plugin
WordLift brings the power of Artificial Intelligence to beautifully organize content. Attract new readers and get their true attention.
Stars: 102
WordLift is a plugin that helps online content creators organize posts and pages by adding facts, links, and media to build beautifully structured websites for both humans and search engines. It allows users to create, own, and publish their own knowledge graph, and publishes content as Linked Open Data following Tim Berners-Lee's Linked Data Principles. The plugin supports writers by providing trustworthy and contextual facts, enriching content with images, links, and interactive visualizations, keeping readers engaged with relevant content recommendations, and producing content compatible with schema.org markup for better indexing and display on search engines. It also offers features like creating a personal Wikipedia, publishing metadata to share and distribute content, and supporting content tagging for better SEO.
README:
![]()
![]()

WordLift brings the power of Artificial Intelligence to beautifully organize content. Attract new readers and get their true attention.
- Who is WordLift for?
- Why shall I use WordLift?
- How does it work?
- What are the languages supported by WordLift?
- Who owns the structured metadata created with WordLift?
WordLift helps you organize posts and pages adding facts, links and media to build beautifully structured websites, for both humans and search engines.
WordLift lets you create, own and publish your own knowledge graph.
WordLift publishes your content as Linked Open Data following Tim Berners-Lee‘s Linked Data Principles.
WordLift is a plug-in for online content creators to:
- Support your writing process with trustworthy and contextual facts
- Enrich content with images, links and interactive visualizations
- Keep readers engaged with relevant content recommendations
- Produce content compatible with schema.org markup, allowing search engines to best index and display your website.
- Engage readers with relevant content recommendations
- Create your own personal Wikipedia
- Publish metadata to share, sell and distribute content
- The technology to self-organize content using publicly or privately available knowledge graphs
- An easy way to build datasets and full data ownership
- Support for creating web content using contextually relevant information
- Valued and free to use photos and illustrations from the Commons community ranging from maps to astronomical imagery to photographs, artworks and more
- New means to drive business growth with meaningful content discovery paths
- Content tagging for better SEO
WordLift currently supports the following languages: English, 中文 (Chinese), Español (Spanish), Русский (Russian), Português (Portuguese), Deutsch (German), Français (French), Italiano (Italian), Nederlands (Dutch), Svenska (Swedish) and Dansk (Danish).
The Plug-in is built on open source software.
- Upload
wordlift.zipto the/wp-content/plugins/directory - Extract the files in the wordlift subfolder
- Activate the plug-in using a WordLift key. You receive this key from us after purchasing the monthly service from our website. Once you have received the key go to the WordPress administration menu, click on Plugins / Installed Plugins. Then click on Settings on the WordLift plugin and add the key there.
WordLift is for all bloggers, journalists, and content marketers publishing and fighting for readers’ attention on the web.
WordLift democratizes the field, bringing to the hands of all web content creators the technology that web publisher giants such as Google, Facebook and the BBC are using to organize and monetize their content.
WordLift helps you create richer and more engaging content, optimizes it for all search engines and efficiently organizes your content creation process, allowing you to reach and speak directly to your tribe.
Organizing web content around an internal vocabulary rather than traditional web pages helps both users and machines finding and accessing it, improving navigation, content re-use, content repurposing, and search engine rankings.
WordLift organizes content, reducing the complexity of content management and content marketing operations, letting bloggers and site owners focus on stories and communities.
WordLift enriches your content with contextual information, links, and media, from custom vocabularies and/or the wealth of open data available on the web, bringing your user experience to a new level of engagement.
WordLift connects content with cross-media discovery and recommendations widgets, increasing content quality, exposure, trustworthiness and readership engagement.
WordLift optimizes content, complementing the offer of plug-ins such as SEO Ultimate or Yoast, automatically adding schema.org markups to your text, allowing all search engines to properly index your pages and deliver more traffic to your site.
To know more about how WordLift works, please watch the step-by-step video tutorials on our website.
WordLift works in subsequent stages.
-
The first step provides a full text analysis and suggests concepts and relationships found in open vocabularies (such as DBpedia, Wikidata, GeoNames, etc) to help writers classify and enrich their content and structure it for search engines like Google, according to schema.org vocabulary.
-
Writers can then create new entities, to complement the ones suggested automatically, and to be published as part of a proprietary vocabulary, acting both as a reference and a search magnet for their readers, according to the editorial plans.
-
WordLift also assists writers suggesting links, media and providing a set of powerful visualization widgets to connect and recommend alternative content, to boost readers’ engagement.
-
Finally WordLift provides means to record all these relationships in a graph database allowing search queries like “find all contents related to concept_y and relevant for target_z”.
WordLift currently supports 32 languages: Chinese, Danish, German, English, French, Italian, Dutch, Russian, Spanish, Portuguese, Swedish, Turkish, Albanian, Belarusian, Bulgarian, Catalan, Croatian, Czech, Estonian, Finnish, Hungarian, Icelandic, Indonesian, Latvian, Lithuanian, Norwegian, Polish, Romanian, Serbian, Slovak, Slovenian, Ukrainian.
You do! We believe content creators should retain the commercial value of their content and all the data they create and exploit it through new business models based on content syndication, data-as-a-service and a stronger relationship with their audience.
You can open your datasets to the public, attaching to it a free or a commercial licence. Otherwise, use your data to feed chat bots on Facebook Messenger or Telegram, providing live feed updates on your activity and/or automatic customer service in real time.
Find more FAQ in our Wiki.
Are you ready to contribute? Head over our Contributing Guide. Feel free to pop into Gitter wordlift/home if you have any questions for us.
For further info please head to WordLift's web site or to the plugin's documentation.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for wordlift-plugin
Similar Open Source Tools
wordlift-plugin
WordLift is a plugin that helps online content creators organize posts and pages by adding facts, links, and media to build beautifully structured websites for both humans and search engines. It allows users to create, own, and publish their own knowledge graph, and publishes content as Linked Open Data following Tim Berners-Lee's Linked Data Principles. The plugin supports writers by providing trustworthy and contextual facts, enriching content with images, links, and interactive visualizations, keeping readers engaged with relevant content recommendations, and producing content compatible with schema.org markup for better indexing and display on search engines. It also offers features like creating a personal Wikipedia, publishing metadata to share and distribute content, and supporting content tagging for better SEO.
ProjectAirSim
Project AirSim is a simulation platform for drones, robots, and autonomous systems. Leveraging Unreal Engine 5, it provides photo-realistic visuals and a simulation framework for custom physics, controllers, actuators, and sensors. It consists of three main layers: Sim Libs, Plugin, and Client Library. It supports Windows 11 and Ubuntu 22, inviting collaboration and enterprise support. Users can join the community, contribute to the roadmap, and get started with pre-built binaries or building from source. It offers headless running options and references for configuration settings, API, controllers, sensors, scene, physics, and FAQ.

deepdoctection
**deep** doctection is a Python library that orchestrates document extraction and document layout analysis tasks using deep learning models. It does not implement models but enables you to build pipelines using highly acknowledged libraries for object detection, OCR and selected NLP tasks and provides an integrated framework for fine-tuning, evaluating and running models. For more specific text processing tasks use one of the many other great NLP libraries. **deep** doctection focuses on applications and is made for those who want to solve real world problems related to document extraction from PDFs or scans in various image formats. **deep** doctection provides model wrappers of supported libraries for various tasks to be integrated into pipelines. Its core function does not depend on any specific deep learning library. Selected models for the following tasks are currently supported: * Document layout analysis including table recognition in Tensorflow with **Tensorpack**, or PyTorch with **Detectron2**, * OCR with support of **Tesseract**, **DocTr** (Tensorflow and PyTorch implementations available) and a wrapper to an API for a commercial solution, * Text mining for native PDFs with **pdfplumber**, * Language detection with **fastText**, * Deskewing and rotating images with **jdeskew**. * Document and token classification with all LayoutLM models provided by the **Transformer library**. (Yes, you can use any LayoutLM-model with any of the provided OCR-or pdfplumber tools straight away!). * Table detection and table structure recognition with **table-transformer**. * There is a small dataset for token classification available and a lot of new tutorials to show, how to train and evaluate this dataset using LayoutLMv1, LayoutLMv2, LayoutXLM and LayoutLMv3. * Comprehensive configuration of **analyzer** like choosing different models, output parsing, OCR selection. Check this notebook or the docs for more infos. * Document layout analysis and table recognition now runs with **Torchscript** (CPU) as well and **Detectron2** is not required anymore for basic inference. * [**new**] More angle predictors for determining the rotation of a document based on **Tesseract** and **DocTr** (not contained in the built-in Analyzer). * [**new**] Token classification with **LiLT** via **transformers**. We have added a model wrapper for token classification with LiLT and added a some LiLT models to the model catalog that seem to look promising, especially if you want to train a model on non-english data. The training script for LayoutLM can be used for LiLT as well and we will be providing a notebook on how to train a model on a custom dataset soon. **deep** doctection provides on top of that methods for pre-processing inputs to models like cropping or resizing and to post-process results, like validating duplicate outputs, relating words to detected layout segments or ordering words into contiguous text. You will get an output in JSON format that you can customize even further by yourself. Have a look at the **introduction notebook** in the notebook repo for an easy start. Check the **release notes** for recent updates. **deep** doctection or its support libraries provide pre-trained models that are in most of the cases available at the **Hugging Face Model Hub** or that will be automatically downloaded once requested. For instance, you can find pre-trained object detection models from the Tensorpack or Detectron2 framework for coarse layout analysis, table cell detection and table recognition. Training is a substantial part to get pipelines ready on some specific domain, let it be document layout analysis, document classification or NER. **deep** doctection provides training scripts for models that are based on trainers developed from the library that hosts the model code. Moreover, **deep** doctection hosts code to some well established datasets like **Publaynet** that makes it easy to experiment. It also contains mappings from widely used data formats like COCO and it has a dataset framework (akin to **datasets** so that setting up training on a custom dataset becomes very easy. **This notebook** shows you how to do this. **deep** doctection comes equipped with a framework that allows you to evaluate predictions of a single or multiple models in a pipeline against some ground truth. Check again **here** how it is done. Having set up a pipeline it takes you a few lines of code to instantiate the pipeline and after a for loop all pages will be processed through the pipeline.
azure-openai-samples
This repository provides resources to understand and utilize GPT (Generative Pre-trained Transformer) by Azure OpenAI. It includes sample solutions, use cases, and quick start guides. Users can explore various applications of GPT, such as chatbots, customer service, and content generation. The repository also offers Langchain, Semantic Kernel, and Prompt Flow samples, along with Serverless SQL GPT for natural language processing in Azure Synapse Analytics. The samples are based on GPT 3.5, with plans to update for GPT-4. Users are encouraged to contribute to keep the repository updated with the latest technologies and solutions.
llm-resources
llm-resources is a repository providing resources to get started with Large Language Models (LLMs). It includes videos on Neural Networks and LLMs, free courses, prompt engineering guides, explored frameworks, AI assistants, and tips on making RAG work properly. The repository also contains important links and updates related to LLMs, AWS, RAG, agents, model context protocol, and more. It aims to help individuals with a basic understanding of NLP and programming knowledge to explore and utilize LLMs effectively.

product-manager-prompts
A treasure trove of Generative AI prompt engineering tailored for product managers and product owners. It provides prompts for completing tasks, exploring ideas, conducting research, facilitating communication, and jumpstarting templates. Join the community to enrich this collection with insights, prompts, synthetic data, and examples, making it an indispensable resource for product management.

Stake-Crash-Predictor
The Stake Crash Predictor is a demo-focused toolkit that combines statistical analysis, decryption tools, and AI-assisted summaries to help users study rounds on Stake.us. It includes features like real-time prediction accuracy, AI summaries, decryption tools, and demo bot templates. Users can install the tool by downloading the ZIP file, run it in demo mode to explore crash predictor outputs, and use the server seed hash decrypt helper for educational purposes. The tool is designed for Stake.us and focuses on stake mines predictor and stake predictor workflows.
CodeGPT
CodeGPT is an extension for JetBrains IDEs that provides access to state-of-the-art large language models (LLMs) for coding assistance. It offers a range of features to enhance the coding experience, including code completions, a ChatGPT-like interface for instant coding advice, commit message generation, reference file support, name suggestions, and offline development support. CodeGPT is designed to keep privacy in mind, ensuring that user data remains secure and private.

kairon
Kairon is an open-source conversational digital transformation platform that helps build LLM-based digital assistants at scale. It provides a no-coding web interface for adapting, training, testing, and maintaining AI assistants. Kairon focuses on pre-processing data for chatbots, including question augmentation, knowledge graph generation, and post-processing metrics. It offers end-to-end lifecycle management, low-code/no-code interface, secure script injection, telemetry monitoring, chat client designer, analytics module, and real-time struggle analytics. Kairon is suitable for teams and individuals looking for an easy interface to create, train, test, and deploy digital assistants.
BloxAI
Blox AI is a platform that allows users to effortlessly create flowcharts and diagrams, collaborate with teams, and receive explanations from the Google Gemini model. It offers rich text editing, versatile visualizations, secure workspaces, and limited files allotment. Users can install it as an app and use it for wireframes, mind maps, and algorithms. The platform is built using Next.Js, Typescript, ShadCN UI, TailwindCSS, Convex, Kinde, EditorJS, and Excalidraw.

ProxyAI
ProxyAI is an open-source AI copilot for JetBrains, offering advanced code assistance features powered by top-tier language models. Users can customize their coding experience, receive AI-suggested code changes, autocomplete suggestions, and context-aware naming suggestions. The tool also allows users to chat with images, reference project files and folders, web docs, git history, and search the web. ProxyAI prioritizes user privacy by not collecting sensitive information and only gathering anonymous usage data with consent.

vulcan-sql
VulcanSQL is an Analytical Data API Framework for AI agents and data apps. It aims to help data professionals deliver RESTful APIs from databases, data warehouses or data lakes much easier and secure. It turns your SQL into APIs in no time!

latitude-llm
Latitude is an open-source prompt engineering platform that helps developers and product teams build AI features with confidence. It simplifies prompt management, aids in testing AI responses, and provides detailed analytics on request performance. Latitude offers collaborative prompt management, support for advanced features, version control, API and SDKs for integration, observability, evaluations in batch or real-time, and is community-driven. It can be deployed on Latitude Cloud for a managed solution or self-hosted for control and customization.
Roadmap-Docs
This repository provides comprehensive roadmaps for various roles in the Data Analytics, Data Science, and Artificial Intelligence industry. It aims to guide individuals, whether students or professionals, in understanding the required skills and timeline for different roles, helping them focus on learning the necessary skills to secure a job. The repository includes detailed guides for roles such as Data Analyst, Data Engineer, Data Scientist, AI Engineer, Computer Vision Engineer, Generative AI Engineer, Machine Learning Engineer, NLP Engineer, and Domain-Specific ML Topics for Researchers.
AgentPilot
Agent Pilot is an open source desktop app for creating, managing, and chatting with AI agents. It features multi-agent, branching chats with various providers through LiteLLM. Users can combine models from different providers, configure interactions, and run code using the built-in Open Interpreter. The tool allows users to create agents, manage chats, work with multi-agent workflows, branching workflows, context blocks, tools, and plugins. It also supports a code interpreter, scheduler, voice integration, and integration with various AI providers. Contributions to the project are welcome, and users can report known issues for improvement.
ai-workshop
The AI Workshop repository provides a comprehensive guide to utilizing OpenAI's APIs, including Chat Completion, Embedding, and Assistant APIs. It offers hands-on demonstrations and code examples to help users understand the capabilities of these APIs. The workshop covers topics such as creating interactive chatbots, performing semantic search using text embeddings, and building custom assistants with specific data and context. Users can enhance their understanding of AI applications in education, research, and other domains through practical examples and usage notes.
For similar tasks
wordlift-plugin
WordLift is a plugin that helps online content creators organize posts and pages by adding facts, links, and media to build beautifully structured websites for both humans and search engines. It allows users to create, own, and publish their own knowledge graph, and publishes content as Linked Open Data following Tim Berners-Lee's Linked Data Principles. The plugin supports writers by providing trustworthy and contextual facts, enriching content with images, links, and interactive visualizations, keeping readers engaged with relevant content recommendations, and producing content compatible with schema.org markup for better indexing and display on search engines. It also offers features like creating a personal Wikipedia, publishing metadata to share and distribute content, and supporting content tagging for better SEO.
fiction
Fiction is a next-generation CMS and application framework designed to streamline the creation of AI-generated content. The first-of-its-kind platform empowers developers and content creators by integrating cutting-edge AI technologies with a robust content management system.
aws-genai-llm-chatbot
This repository provides code to deploy a chatbot powered by Multi-Model and Multi-RAG using AWS CDK on AWS. Users can experiment with various Large Language Models and Multimodal Language Models from different providers. The solution supports Amazon Bedrock, Amazon SageMaker self-hosted models, and third-party providers via API. It also offers additional resources like AWS Generative AI CDK Constructs and Project Lakechain for building generative AI solutions and document processing. The roadmap and authors are listed, along with contributors. The library is licensed under the MIT-0 License with information on changelog, code of conduct, and contributing guidelines. A legal disclaimer advises users to conduct their own assessment before using the content for production purposes.
udm14
udm14 is a basic website designed to facilitate easy searches on Google with the &udm=14 parameter, ensuring AI-free results without knowledge panels. The tool simplifies access to these specific search results buried within Google's interface, providing a straightforward solution for users seeking this functionality.

copywriterproai-backend
CopywriterProAI is the world's first open-source AI writing platform for SEO and Ad Copy. The backend repository powers the AI capabilities and manages content processing for smooth operation. It provides an AI writing assistant that works behind the scenes to assist users in content creation.

awesome-ai-seo
Awesome-AI-SEO is a curated list of powerful AI tools and platforms designed to transform your SEO strategy. This repository gathers the most effective tools that leverage machine learning and artificial intelligence to automate and enhance key aspects of search engine optimization. Whether you are an SEO professional, digital marketer, or website owner, these tools can help you optimize your site, improve your search rankings, and increase organic traffic with greater precision and efficiency. The list features AI tools covering on-page and off-page optimization, competitor analysis, rank tracking, and advanced SEO analytics. By utilizing cutting-edge technologies, businesses can stay ahead of the competition by uncovering hidden keyword opportunities, optimizing content for better visibility, and automating time-consuming SEO tasks. With frequent updates, Awesome-AI-SEO is your go-to resource for discovering the latest AI-driven innovations in the SEO space.
read-frog
Read-frog is a powerful text analysis tool designed to help users extract valuable insights from text data. It offers a wide range of features including sentiment analysis, keyword extraction, entity recognition, and text summarization. With its user-friendly interface and robust algorithms, Read-frog is suitable for both beginners and advanced users looking to analyze text data for various purposes such as market research, social media monitoring, and content optimization. Whether you are a data scientist, marketer, researcher, or student, Read-frog can streamline your text analysis workflow and provide actionable insights to drive decision-making and enhance productivity.
LLMs-in-science
The 'LLMs-in-science' repository is a collaborative environment for organizing papers related to large language models (LLMs) and autonomous agents in the field of chemistry. The goal is to discuss trend topics, challenges, and the potential for supporting scientific discovery in the context of artificial intelligence. The repository aims to maintain a systematic structure of the field and welcomes contributions from the community to keep the content up-to-date and relevant.
For similar jobs

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.
obsidian-textgenerator-plugin
Text Generator is an open-source AI Assistant Tool that leverages Generative Artificial Intelligence to enhance knowledge creation and organization in Obsidian. It allows users to generate ideas, titles, summaries, outlines, and paragraphs based on their knowledge database, offering endless possibilities. The plugin is free and open source, compatible with Obsidian for a powerful Personal Knowledge Management system. It provides flexible prompts, template engine for repetitive tasks, community templates for shared use cases, and highly flexible configuration with services like Google Generative AI, OpenAI, and HuggingFace.
video2blog
video2blog is an open-source project aimed at converting videos into textual notes. The tool follows a process of extracting video information using yt-dlp, downloading the video, downloading subtitles if available, translating subtitles if not in Chinese, generating Chinese subtitles using whisper if no subtitles exist, converting subtitles to articles using gemini, and manually inserting images from the video into the article. The tool provides a solution for creating blog content from video resources, enhancing accessibility and content creation efficiency.
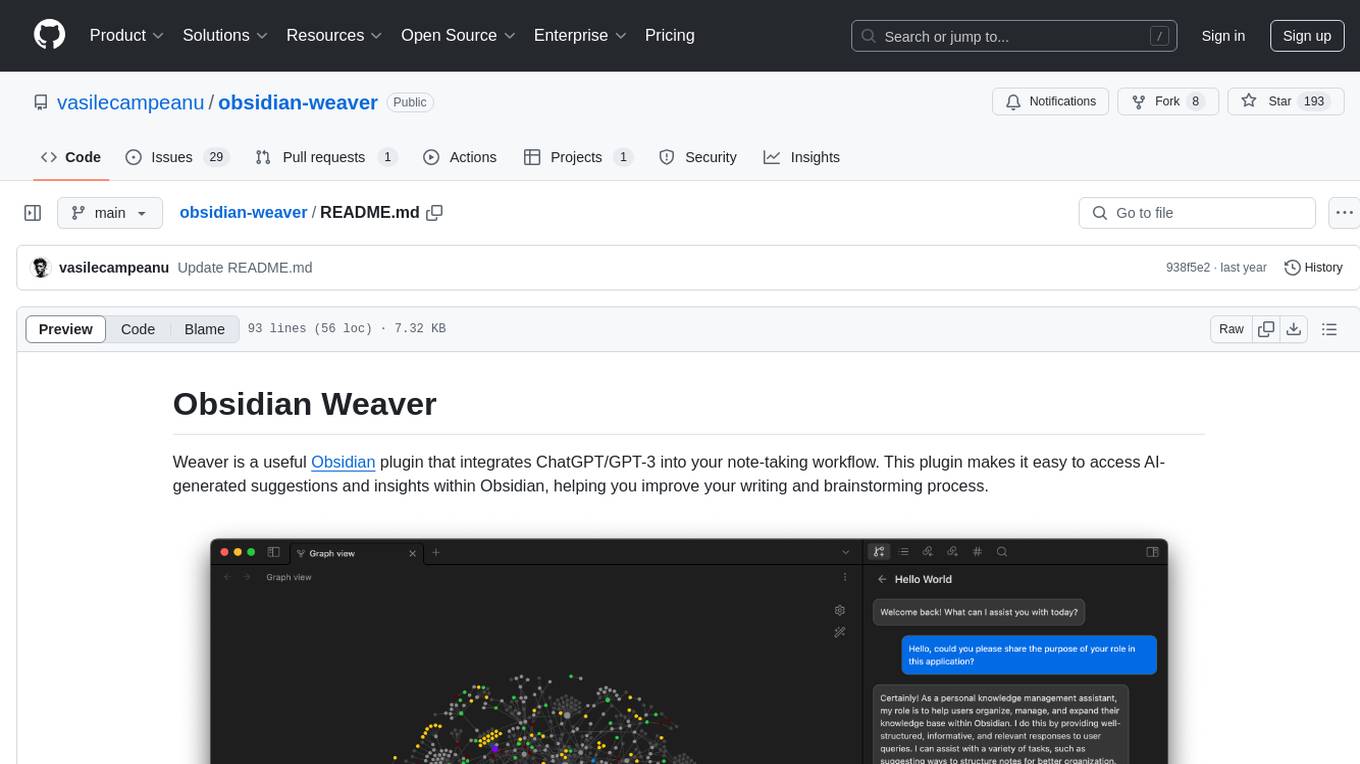
obsidian-weaver
Obsidian Weaver is a plugin that integrates ChatGPT/GPT-3 into the note-taking workflow of Obsidian. It allows users to easily access AI-generated suggestions and insights within Obsidian, enhancing the writing and brainstorming process. The plugin respects Obsidian's philosophy of storing notes locally, ensuring data security and privacy. Weaver offers features like creating new chat sessions with the AI assistant and receiving instant responses, all within the Obsidian environment. It provides a seamless integration with Obsidian's interface, making the writing process efficient and helping users stay focused. The plugin is constantly being improved with new features and updates to enhance the note-taking experience.
wordlift-plugin
WordLift is a plugin that helps online content creators organize posts and pages by adding facts, links, and media to build beautifully structured websites for both humans and search engines. It allows users to create, own, and publish their own knowledge graph, and publishes content as Linked Open Data following Tim Berners-Lee's Linked Data Principles. The plugin supports writers by providing trustworthy and contextual facts, enriching content with images, links, and interactive visualizations, keeping readers engaged with relevant content recommendations, and producing content compatible with schema.org markup for better indexing and display on search engines. It also offers features like creating a personal Wikipedia, publishing metadata to share and distribute content, and supporting content tagging for better SEO.
AI-Writing-Assistant
DeepWrite AI is an AI writing assistant tool created with the help of ChatGPT3. It is designed to generate perfect blog posts with utmost clarity. The tool is currently at version 1.0 with plans for further improvements. It is an open-source project, welcoming contributions. An extension has been developed for using the tool directly in Notepad, currently supported only on Calmly Writer. The tool requires installation and setup, utilizing technologies like React, Next, TailwindCSS, Node, and Express. For support, users can message the creator on Instagram. The creator, Sabir Khan, is an undergraduate student of Computer Science from Mumbai, known for frequently creating innovative projects.
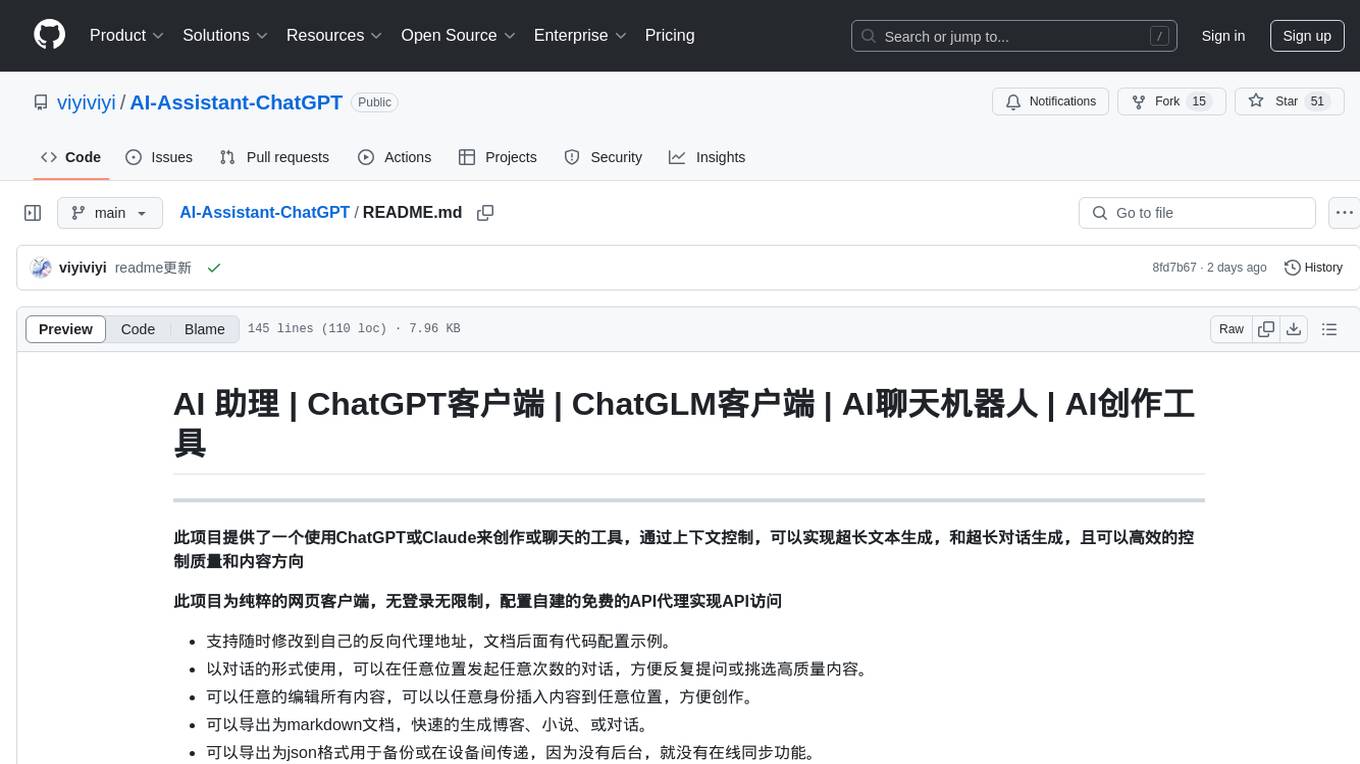
AI-Assistant-ChatGPT
AI Assistant ChatGPT is a web client tool that allows users to create or chat using ChatGPT or Claude. It enables generating long texts and conversations with efficient control over quality and content direction. The tool supports customization of reverse proxy address, conversation management, content editing, markdown document export, JSON backup, context customization, session-topic management, role customization, dynamic content navigation, and more. Users can access the tool directly at https://eaias.com or deploy it independently. It offers features for dialogue management, assistant configuration, session configuration, and more. The tool lacks data cloud storage and synchronization but provides guidelines for independent deployment. It is a frontend project that can be deployed using Cloudflare Pages and customized with backend modifications. The project is open-source under the MIT license.
MarkFlowy
MarkFlowy is a lightweight and feature-rich Markdown editor with built-in AI capabilities. It supports one-click export of conversations, translation of articles, and obtaining article abstracts. Users can leverage large AI models like DeepSeek and Chatgpt as intelligent assistants. The editor provides high availability with multiple editing modes and custom themes. Available for Linux, macOS, and Windows, MarkFlowy aims to offer an efficient, beautiful, and data-safe Markdown editing experience for users.