
speech-trident
Awesome speech/audio LLMs, representation learning, and codec models
Stars: 636
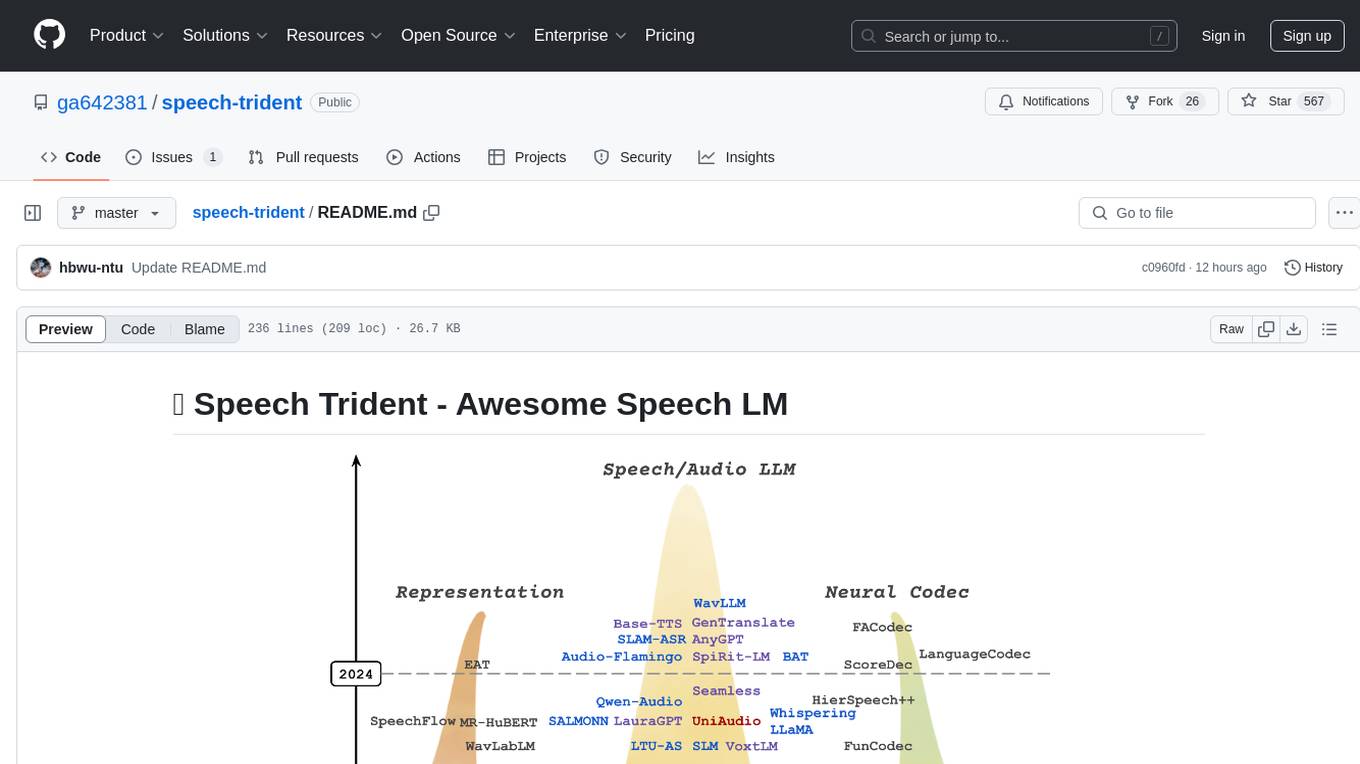
Speech Trident is a repository focusing on speech/audio large language models, covering representation learning, neural codec, and language models. It explores speech representation models, speech neural codec models, and speech large language models. The repository includes contributions from various researchers and provides a comprehensive list of speech/audio language models, representation models, and codec models.
README:

In this repository, we survey three crucial areas: (1) representation learning, (2) neural codec, and (3) language models that contribute to speech/audio large language models.
1.⚡ Speech Representation Models: These models focus on learning structural speech representations, which can then be quantized into discrete speech tokens, often refer to semantic tokens.
2.⚡ Speech Neural Codec Models: These models are designed to learn speech and audio discrete tokens, often referred to as acoustic tokens, while maintaining reconstruction ability and low bitrate.
3.⚡ Speech Large Language Models: These models are trained on top of speech and acoustic tokens in a language modeling approach. They demonstrate proficiency in tasks on speech understanding and speech generation.

Kai-Wei Chang |

Haibin Wu |

Wei-Cheng Tseng |

Kehan Lu |

Chun-Yi Kuan |

Hung-yi Lee |
| Date | Model Name | Paper Title | Link |
|---|---|---|---|
| 2024-09 | Moshi | Moshi: a speech-text foundation model for real-time dialogue | paper |
| 2024-09 | Takin AudioLLM | Takin: A Cohort of Superior Quality Zero-shot Speech Generation Models | paper |
| 2024-09 | FireRedTTS | FireRedTTS: A Foundation Text-To-Speech Framework for Industry-Level Generative Speech Applications | paper |
| 2024-09 | LLaMA-Omni | LLaMA-Omni: Seamless Speech Interaction with Large Language Models | paper |
| 2024-09 | MaskGCT | MaskGCT: Zero-Shot Text-to-Speech with Masked Generative Codec Transformer | paper |
| 2024-09 | SSR-Speech | SSR-Speech: Towards Stable, Safe and Robust Zero-shot Text-based Speech Editing and Synthesis | paper |
| 2024-09 | MoWE-Audio | MoWE-Audio: Multitask AudioLLMs with Mixture of Weak Encoders | paper |
| 2024-08 | Mini-Omni | Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming | paper |
| 2024-08 | Make-A-Voice 2 | Language Model Can Listen While Speaking | paper |
| 2024-08 | LSLM | Make-A-Voice: Revisiting Voice Large Language Models as Scalable Multilingual and Multitask Learner | paper |
| 2024-06 | SimpleSpeech | SimpleSpeech: Towards Simple and Efficient Text-to-Speech with Scalar Latent Transformer Diffusion Models | paper |
| 2024-06 | UniAudio 1.5 | UniAudio 1.5: Large Language Model-driven Audio Codec is A Few-shot Audio Task Learner | paper |
| 2024-06 | VALL-E R | VALL-E R: Robust and Efficient Zero-Shot Text-to-Speech Synthesis via Monotonic Alignment | paper |
| 2024-06 | VALL-E 2 | VALL-E 2: Neural Codec Language Models are Human Parity Zero-Shot Text to Speech Synthesizers | paper |
| 2024-06 | GPST | Generative Pre-trained Speech Language Model with Efficient Hierarchical Transformer | paper |
| 2024-04 | CLaM-TTS | CLaM-TTS: Improving Neural Codec Language Model for Zero-Shot Text-to-Speech | paper |
| 2024-04 | RALL-E | RALL-E: Robust Codec Language Modeling with Chain-of-Thought Prompting for Text-to-Speech Synthesis | paper |
| 2024-04 | WavLLM | WavLLM: Towards Robust and Adaptive Speech Large Language Model | paper |
| 2024-02 | MobileSpeech | MobileSpeech: A Fast and High-Fidelity Framework for Mobile Zero-Shot Text-to-Speech | paper |
| 2024-02 | SLAM-ASR | An Embarrassingly Simple Approach for LLM with Strong ASR Capacity | paper |
| 2024-02 | AnyGPT | AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling | paper |
| 2024-02 | SpiRit-LM | SpiRit-LM: Interleaved Spoken and Written Language Model | paper |
| 2024-02 | USDM | Integrating Paralinguistics in Speech-Empowered Large Language Models for Natural Conversation | paper |
| 2024-02 | BAT | BAT: Learning to Reason about Spatial Sounds with Large Language Models | paper |
| 2024-02 | Audio Flamingo | Audio Flamingo: A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities | paper |
| 2024-02 | Text Description to speech | Natural language guidance of high-fidelity text-to-speech with synthetic annotations | paper |
| 2024-02 | GenTranslate | GenTranslate: Large Language Models are Generative Multilingual Speech and Machine Translators | paper |
| 2024-02 | Base-TTS | BASE TTS: Lessons from building a billion-parameter Text-to-Speech model on 100K hours of data | paper |
| 2024-02 | -- | It's Never Too Late: Fusing Acoustic Information into Large Language Models for Automatic Speech Recognition | paper |
| 2024-01 | -- | Large Language Models are Efficient Learners of Noise-Robust Speech Recognition | paper |
| 2024-01 | ELLA-V | ELLA-V: Stable Neural Codec Language Modeling with Alignment-guided Sequence Reordering | paper |
| 2023-12 | Seamless | Seamless: Multilingual Expressive and Streaming Speech Translation | paper |
| 2023-11 | Qwen-Audio | Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models | paper |
| 2023-10 | LauraGPT | LauraGPT: Listen, Attend, Understand, and Regenerate Audio with GPT | paper |
| 2023-10 | SALMONN | SALMONN: Towards Generic Hearing Abilities for Large Language Models | paper |
| 2023-10 | UniAudio | UniAudio: An Audio Foundation Model Toward Universal Audio Generation | paper |
| 2023-10 | Whispering LLaMA | Whispering LLaMA: A Cross-Modal Generative Error Correction Framework for Speech Recognition | paper |
| 2023-09 | VoxtLM | Voxtlm: unified decoder-only models for consolidating speech recognition/synthesis and speech/text continuation tasks | paper |
| 2023-09 | LTU-AS | Joint Audio and Speech Understanding | paper |
| 2023-09 | SLM | SLM: Bridge the thin gap between speech and text foundation models | paper |
| 2023-09 | -- | Generative Speech Recognition Error Correction with Large Language Models and Task-Activating Prompting | paper |
| 2023-08 | SpeechGen | SpeechGen: Unlocking the Generative Power of Speech Language Models with Prompts | paper |
| 2023-08 | SpeechX | SpeechX: Neural Codec Language Model as a Versatile Speech Transformer | paper |
| 2023-08 | LLaSM | Large Language and Speech Model | paper |
| 2023-08 | SeamlessM4T | Massively Multilingual & Multimodal Machine Translation | paper |
| 2023-07 | Speech-LLaMA | On decoder-only architecture for speech-to-text and large language model integration | paper |
| 2023-07 | LLM-ASR(temp.) | Prompting Large Language Models with Speech Recognition Abilities | paper |
| 2023-06 | AudioPaLM | AudioPaLM: A Large Language Model That Can Speak and Listen | paper |
| 2023-05 | Make-A-Voice | Make-A-Voice: Unified Voice Synthesis With Discrete Representation | paper |
| 2023-05 | Spectron | Spoken Question Answering and Speech Continuation Using Spectrogram-Powered LLM | paper |
| 2023-05 | TWIST | Textually Pretrained Speech Language Models | paper |
| 2023-05 | Pengi | Pengi: An Audio Language Model for Audio Tasks | paper |
| 2023-05 | SoundStorm | Efficient Parallel Audio Generation | paper |
| 2023-05 | LTU | Joint Audio and Speech Understanding | paper |
| 2023-05 | SpeechGPT | Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities | paper |
| 2023-05 | VioLA | Unified Codec Language Models for Speech Recognition, Synthesis, and Translation | paper |
| 2023-05 | X-LLM | X-LLM: Bootstrapping Advanced Large Language Models by Treating Multi-Modalities as Foreign Languages | paper |
| 2023-03 | Google USM | Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages | paper |
| 2023-03 | VALL-E X | Speak Foreign Languages with Your Own Voice: Cross-Lingual Neural Codec Language Modeling | paper |
| 2023-02 | SPEAR-TTS | Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision | paper |
| 2023-01 | VALL-E | Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers | paper |
| 2022-12 | Whisper | Robust Speech Recognition via Large-Scale Weak Supervision | paper |
| 2022-10 | AudioGen | AudioGen: Textually Guided Audio Generation | paper |
| 2022-09 | AudioLM | AudioLM: a Language Modeling Approach to Audio Generation | paper |
| 2022-05 | Wav2Seq | Wav2Seq: Pre-training Speech-to-Text Encoder-Decoder Models Using Pseudo Languages | paper |
| 2022-04 | Unit mBART | Enhanced Direct Speech-to-Speech Translation Using Self-supervised Pre-training and Data Augmentation | paper |
| 2022-03 | d-GSLM | Generative Spoken Dialogue Language Modeling | paper |
| 2021-10 | SLAM | SLAM: A Unified Encoder for Speech and Language Modeling via Speech-Text Joint Pre-Training | paper |
| 2021-09 | p-GSLM | Text-Free Prosody-Aware Generative Spoken Language Modeling | paper |
| 2021-02 | GSLM | Generative Spoken Language Modeling from Raw Audio | paper |
| Date | Model Name | Paper Title | Link |
|---|---|---|---|
| 2024-09 | NEST-RQ | NEST-RQ: Next Token Prediction for Speech Self-Supervised Pre-Training | paper |
| 2024-01 | EAT | Self-Supervised Pre-Training with Efficient Audio Transformer | paper |
| 2023-10 | MR-HuBERT | Multi-resolution HuBERT: Multi-resolution Speech Self-Supervised Learning with Masked Unit Prediction | paper |
| 2023-10 | SpeechFlow | Generative Pre-training for Speech with Flow Matching | paper |
| 2023-09 | WavLabLM | Joint Prediction and Denoising for Large-scale Multilingual Self-supervised Learning | paper |
| 2023-08 | W2v-BERT 2.0 | Massively Multilingual & Multimodal Machine Translation | paper |
| 2023-07 | Whisper-AT | Noise-Robust Automatic Speech Recognizers are Also Strong General Audio Event Taggers | paper |
| 2023-06 | ATST | Self-supervised Audio Teacher-Student Transformer for Both Clip-level and Frame-level Tasks | paper |
| 2023-05 | SPIN | Self-supervised Fine-tuning for Improved Content Representations by Speaker-invariant Clustering | paper |
| 2023-05 | DinoSR | Self-Distillation and Online Clustering for Self-supervised Speech Representation Learning | paper |
| 2023-05 | NFA | Self-supervised neural factor analysis for disentangling utterance-level speech representations | paper |
| 2022-12 | Data2vec 2.0 | Efficient Self-supervised Learning with Contextualized Target Representations for Vision, Speech and Language | paper |
| 2022-12 | BEATs | Audio Pre-Training with Acoustic Tokenizers | paper |
| 2022-11 | MT4SSL | MT4SSL: Boosting Self-Supervised Speech Representation Learning by Integrating Multiple Targets | paper |
| 2022-08 | DINO | Non-contrastive self-supervised learning of utterance-level speech representations | paper |
| 2022-07 | Audio-MAE | Masked Autoencoders that Listen | paper |
| 2022-04 | MAESTRO | Matched Speech Text Representations through Modality Matching | paper |
| 2022-03 | MAE-AST | Masked Autoencoding Audio Spectrogram Transformer | paper |
| 2022-03 | LightHuBERT | Lightweight and Configurable Speech Representation Learning with Once-for-All Hidden-Unit BERT | paper |
| 2022-02 | Data2vec | A General Framework for Self-supervised Learning in Speech, Vision and Language | paper |
| 2021-10 | WavLM | WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing | paper |
| 2021-08 | W2v-BERT | Combining Contrastive Learning and Masked Language Modeling for Self-Supervised Speech Pre-Training | paper |
| 2021-07 | mHuBERT | Direct speech-to-speech translation with discrete units | paper |
| 2021-06 | HuBERT | Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units | paper |
| 2021-03 | BYOL-A | Self-Supervised Learning for General-Purpose Audio Representation | paper |
| 2020-12 | DeCoAR2.0 | DeCoAR 2.0: Deep Contextualized Acoustic Representations with Vector Quantization | paper |
| 2020-07 | TERA | TERA: Self-Supervised Learning of Transformer Encoder Representation for Speech | paper |
| 2020-06 | Wav2vec2.0 | wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations | paper |
| 2019-10 | APC | Generative Pre-Training for Speech with Autoregressive Predictive Coding | paper |
| 2018-07 | CPC | Representation Learning with Contrastive Predictive Coding | paper |
| Date | Model Name | Paper Title | Link |
|---|---|---|---|
| 2024-09 | Mimi | Moshi: a speech-text foundation model for real-time dialogue | paper |
| 2024-09 | NDVQ | NDVQ: Robust Neural Audio Codec with Normal Distribution-Based Vector Quantization | paper |
| 2024-09 | SoCodec | SoCodec: A Semantic-Ordered Multi-Stream Speech Codec for Efficient Language Model Based Text-to-Speech Synthesis | paper |
| 2024-09 | BigCodec | BigCodec: Pushing the Limits of Low-Bitrate Neural Speech Codec | paper |
| 2024-08 | X-Codec | Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model | paper |
| 2024-08 | WavTokenizer | WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling | paper |
| 2024-07 | Super-Codec | SuperCodec: A Neural Speech Codec with Selective Back-Projection Network | paper |
| 2024-06 | Single-Codec | Single-Codec: Single-Codebook Speech Codec towards High-Performance Speech Generation | paper |
| 2024-06 | SQ-Codec | SimpleSpeech: Towards Simple and Efficient Text-to-Speech with Scalar Latent Transformer Diffusion Models | paper |
| 2024-06 | PQ-VAE | Addressing Index Collapse of Large-Codebook Speech Tokenizer with Dual-Decoding Product-Quantized Variational Auto-Encoder | paper |
| 2024-06 | LLM-Codec | UniAudio 1.5: Large Language Model-driven Audio Codec is A Few-shot Audio Task Learner | paper |
| 2024-05 | HILCodec | HILCodec: High Fidelity and Lightweight Neural Audio Codec | paper |
| 2024-04 | SemantiCodec | SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound | paper |
| 2024-04 | PromptCodec | PromptCodec: High-Fidelity Neural Speech Codec using Disentangled Representation Learning based Adaptive Feature-aware Prompt Encoders | paper |
| 2024-04 | ESC | ESC: Efficient Speech Coding with Cross-Scale Residual Vector Quantized Transformers | paper |
| 2024-03 | FACodec | NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models | paper |
| 2024-02 | AP-Codec | APCodec: A Neural Audio Codec with Parallel Amplitude and Phase Spectrum Encoding and Decoding | paper |
| 2024-02 | Language-Codec | Language-Codec: Reducing the Gaps Between Discrete Codec Representation and Speech Language Models | paper |
| 2024-01 | ScoreDec | ScoreDec: A Phase-preserving High-Fidelity Audio Codec with A Generalized Score-based Diffusion Post-filter | paper |
| 2023-11 | HierSpeech++ | HierSpeech++: Bridging the Gap between Semantic and Acoustic Representation of Speech by Hierarchical Variational Inference for Zero-shot Speech Synthesis | paper |
| 2023-10 | TiCodec | FEWER-TOKEN NEURAL SPEECH CODEC WITH TIME-INVARIANT CODES | paper |
| 2023-09 | RepCodec | RepCodec: A Speech Representation Codec for Speech Tokenization | paper |
| 2023-09 | FunCodec | FunCodec: A Fundamental, Reproducible and Integrable Open-source Toolkit for Neural Speech Codec | paper |
| 2023-08 | SpeechTokenizer | Speechtokenizer: Unified speech tokenizer for speech large language models | paper |
| 2023-06 | VOCOS | VOCOS: CLOSING THE GAP BETWEEN TIME-DOMAIN AND FOURIER-BASED NEURAL VOCODERS FOR HIGH-QUALITY AUDIO SYNTHESIS | paper |
| 2023-06 | Descript-audio-codec | High-Fidelity Audio Compression with Improved RVQGAN | paper |
| 2023-05 | AudioDec | Audiodec: An open-source streaming highfidelity neural audio codec | paper |
| 2023-05 | HiFi-Codec | Hifi-codec: Group-residual vector quantization for high fidelity audio codec | paper |
| 2023-03 | LMCodec | LMCodec: A Low Bitrate Speech Codec With Causal Transformer Models | paper |
| 2022-11 | Disen-TF-Codec | Disentangled Feature Learning for Real-Time Neural Speech Coding | paper |
| 2022-10 | EnCodec | High fidelity neural audio compression | paper |
| 2022-07 | S-TFNet | Cross-Scale Vector Quantization for Scalable Neural Speech Coding | paper |
| 2022-01 | TFNet | End-to-End Neural Speech Coding for Real-Time Communications | paper |
| 2021-07 | SoundStream | SoundStream: An End-to-End Neural Audio Codec | paper |
Professor Hung-Yi Lee will be giving a talk as part of the Interspeech 2024 survey talk titled Challenges in Developing Spoken Language Models. The topic will cover nowday's speech/audio large language models.
I (Kai-Wei Chang) will be giving a talk as part of the ICASSP 2024 tutorial titled Parameter-Efficient and Prompt Learning for Speech and Language Foundation Models. The topic will cover nowday's speech/audio large language models.
Tutorial speakers:
- Dr. Huck Yang (NVIDIA)
- Dr. Pin-Yu Chen (IBM Research)
- Prof. Hung-yi Lee (National Taiwan University)
- Kai-Wei Chang (National Taiwan University)
- Cheng-Han Chiang (National Taiwan University)
See you in Seoul!
🔱 Update: The Tutorial was successfully conducted at ICASSP 2024. Thank all attendees for their participation. The slides from my presentation is available at https://kwchang.org/talks/. Please feel free to reach out to me for any discussions.
- https://github.com/liusongxiang/Large-Audio-Models
- https://github.com/kuan2jiu99/Awesome-Speech-Generation
- https://github.com/ga642381/Speech-Prompts-Adapters
- https://github.com/voidful/Codec-SUPERB
- https://github.com/huckiyang/awesome-neural-reprogramming-prompting
If you find this repository useful, please consider citing the following papers.
@article{wu2024codec,
title={Codec-SUPERB: An In-Depth Analysis of Sound Codec Models},
author={Wu, Haibin and Chung, Ho-Lam and Lin, Yi-Cheng and Wu, Yuan-Kuei and Chen, Xuanjun and Pai, Yu-Chi and Wang, Hsiu-Hsuan and Chang, Kai-Wei and Liu, Alexander H and Lee, Hung-yi},
journal={arXiv preprint arXiv:2402.13071},
year={2024}
}
@article{wu2024towards,
title={Towards audio language modeling-an overview},
author={Wu, Haibin and Chen, Xuanjun and Lin, Yi-Cheng and Chang, Kai-wei and Chung, Ho-Lam and Liu, Alexander H and Lee, Hung-yi},
journal={arXiv preprint arXiv:2402.13236},
year={2024}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for speech-trident
Similar Open Source Tools
speech-trident
Speech Trident is a repository focusing on speech/audio large language models, covering representation learning, neural codec, and language models. It explores speech representation models, speech neural codec models, and speech large language models. The repository includes contributions from various researchers and provides a comprehensive list of speech/audio language models, representation models, and codec models.

AudioLLM
AudioLLMs is a curated collection of research papers focusing on developing, implementing, and evaluating language models for audio data. The repository aims to provide researchers and practitioners with a comprehensive resource to explore the latest advancements in AudioLLMs. It includes models for speech interaction, speech recognition, speech translation, audio generation, and more. Additionally, it covers methodologies like multitask audioLLMs and segment-level Q-Former, as well as evaluation benchmarks like AudioBench and AIR-Bench. Adversarial attacks such as VoiceJailbreak are also discussed.
Awesome-Model-Merging-Methods-Theories-Applications
A comprehensive repository focusing on 'Model Merging in LLMs, MLLMs, and Beyond', providing an exhaustive overview of model merging methods, theories, applications, and future research directions. The repository covers various advanced methods, applications in foundation models, different machine learning subfields, and tasks like pre-merging methods, architecture transformation, weight alignment, basic merging methods, and more.

LLM-Agent-Survey
Autonomous agents are designed to achieve specific objectives through self-guided instructions. With the emergence and growth of large language models (LLMs), there is a growing trend in utilizing LLMs as fundamental controllers for these autonomous agents. This repository conducts a comprehensive survey study on the construction, application, and evaluation of LLM-based autonomous agents. It explores essential components of AI agents, application domains in natural sciences, social sciences, and engineering, and evaluation strategies. The survey aims to be a resource for researchers and practitioners in this rapidly evolving field.

Awesome-Resource-Efficient-LLM-Papers
A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.
Awesome-LLM-3D
This repository is a curated list of papers related to 3D tasks empowered by Large Language Models (LLMs). It covers tasks such as 3D understanding, reasoning, generation, and embodied agents. The repository also includes other Foundation Models like CLIP and SAM to provide a comprehensive view of the area. It is actively maintained and updated to showcase the latest advances in the field. Users can find a variety of research papers and projects related to 3D tasks and LLMs in this repository.

LLM-KG4QA
LLM-KG4QA is a repository focused on the integration of Large Language Models (LLMs) and Knowledge Graphs (KGs) for Question Answering (QA). It covers various aspects such as using KGs as background knowledge, reasoning guideline, and refiner/filter. The repository provides detailed information on pre-training, fine-tuning, and Retrieval Augmented Generation (RAG) techniques for enhancing QA performance. It also explores complex QA tasks like Explainable QA, Multi-Modal QA, Multi-Document QA, Multi-Hop QA, Multi-run and Conversational QA, Temporal QA, Multi-domain and Multilingual QA, along with advanced topics like Optimization and Data Management. Additionally, it includes benchmark datasets, industrial and scientific applications, demos, and related surveys in the field.

Awesome-Tabular-LLMs
This repository is a collection of papers on Tabular Large Language Models (LLMs) specialized for processing tabular data. It includes surveys, models, and applications related to table understanding tasks such as Table Question Answering, Table-to-Text, Text-to-SQL, and more. The repository categorizes the papers based on key ideas and provides insights into the advancements in using LLMs for processing diverse tables and fulfilling various tabular tasks based on natural language instructions.

Awesome-LLM-Constrained-Decoding
Awesome-LLM-Constrained-Decoding is a curated list of papers, code, and resources related to constrained decoding of Large Language Models (LLMs). The repository aims to facilitate reliable, controllable, and efficient generation with LLMs by providing a comprehensive collection of materials in this domain.

open-llms
Open LLMs is a repository containing various Large Language Models licensed for commercial use. It includes models like T5, GPT-NeoX, UL2, Bloom, Cerebras-GPT, Pythia, Dolly, and more. These models are designed for tasks such as transfer learning, language understanding, chatbot development, code generation, and more. The repository provides information on release dates, checkpoints, papers/blogs, parameters, context length, and licenses for each model. Contributions to the repository are welcome, and it serves as a resource for exploring the capabilities of different language models.
Cool-GenAI-Fashion-Papers
Cool-GenAI-Fashion-Papers is a curated list of resources related to GenAI-Fashion, including papers, workshops, companies, and products. It covers a wide range of topics such as fashion design synthesis, outfit recommendation, fashion knowledge extraction, trend analysis, and more. The repository provides valuable insights and resources for researchers, industry professionals, and enthusiasts interested in the intersection of AI and fashion.
Github-Ranking-AI
This repository provides a list of the most starred and forked repositories on GitHub. It is updated automatically and includes information such as the project name, number of stars, number of forks, language, number of open issues, description, and last commit date. The repository is divided into two sections: LLM and chatGPT. The LLM section includes repositories related to large language models, while the chatGPT section includes repositories related to the chatGPT chatbot.
LLM4EC
LLM4EC is an interdisciplinary research repository focusing on the intersection of Large Language Models (LLM) and Evolutionary Computation (EC). It provides a comprehensive collection of papers and resources exploring various applications, enhancements, and synergies between LLM and EC. The repository covers topics such as LLM-assisted optimization, EA-based LLM architecture search, and applications in code generation, software engineering, neural architecture search, and other generative tasks. The goal is to facilitate research and development in leveraging LLM and EC for innovative solutions in diverse domains.

Awesome-LLM-Eval
Awesome-LLM-Eval: a curated list of tools, benchmarks, demos, papers for Large Language Models (like ChatGPT, LLaMA, GLM, Baichuan, etc) Evaluation on Language capabilities, Knowledge, Reasoning, Fairness and Safety.
For similar tasks
AnyGPT
AnyGPT is a unified multimodal language model that utilizes discrete representations for processing various modalities like speech, text, images, and music. It aligns the modalities for intermodal conversions and text processing. AnyInstruct dataset is constructed for generative models. The model proposes a generative training scheme using Next Token Prediction task for training on a Large Language Model (LLM). It aims to compress vast multimodal data on the internet into a single model for emerging capabilities. The tool supports tasks like text-to-image, image captioning, ASR, TTS, text-to-music, and music captioning.
speech-trident
Speech Trident is a repository focusing on speech/audio large language models, covering representation learning, neural codec, and language models. It explores speech representation models, speech neural codec models, and speech large language models. The repository includes contributions from various researchers and provides a comprehensive list of speech/audio language models, representation models, and codec models.
AudioLLM
AudioLLMs is a curated collection of research papers focusing on developing, implementing, and evaluating language models for audio data. The repository aims to provide researchers and practitioners with a comprehensive resource to explore the latest advancements in AudioLLMs. It includes models for speech interaction, speech recognition, speech translation, audio generation, and more. Additionally, it covers methodologies like multitask audioLLMs and segment-level Q-Former, as well as evaluation benchmarks like AudioBench and AIR-Bench. Adversarial attacks such as VoiceJailbreak are also discussed.

llm-verified-with-monte-carlo-tree-search
This prototype synthesizes verified code with an LLM using Monte Carlo Tree Search (MCTS). It explores the space of possible generation of a verified program and checks at every step that it's on the right track by calling the verifier. This prototype uses Dafny, Coq, Lean, Scala, or Rust. By using this technique, weaker models that might not even know the generated language all that well can compete with stronger models.

flashinfer
FlashInfer is a library for Language Languages Models that provides high-performance implementation of LLM GPU kernels such as FlashAttention, PageAttention and LoRA. FlashInfer focus on LLM serving and inference, and delivers state-the-art performance across diverse scenarios.

dolma
Dolma is a dataset and toolkit for curating large datasets for (pre)-training ML models. The dataset consists of 3 trillion tokens from a diverse mix of web content, academic publications, code, books, and encyclopedic materials. The toolkit provides high-performance, portable, and extensible tools for processing, tagging, and deduplicating documents. Key features of the toolkit include built-in taggers, fast deduplication, and cloud support.

web-llm
WebLLM is a modular and customizable javascript package that directly brings language model chats directly onto web browsers with hardware acceleration. Everything runs inside the browser with no server support and is accelerated with WebGPU. WebLLM is fully compatible with OpenAI API. That is, you can use the same OpenAI API on any open source models locally, with functionalities including json-mode, function-calling, streaming, etc. We can bring a lot of fun opportunities to build AI assistants for everyone and enable privacy while enjoying GPU acceleration.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.
For similar jobs

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.

bark.cpp
Bark.cpp is a C/C++ implementation of the Bark model, a real-time, multilingual text-to-speech generation model. It supports AVX, AVX2, and AVX512 for x86 architectures, and is compatible with both CPU and GPU backends. Bark.cpp also supports mixed F16/F32 precision and 4-bit, 5-bit, and 8-bit integer quantization. It can be used to generate realistic-sounding audio from text prompts.

NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.

WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.