
unsight.dev
Detect duplicate GitHub issues, areas of concern and more across related repositories.
Stars: 128
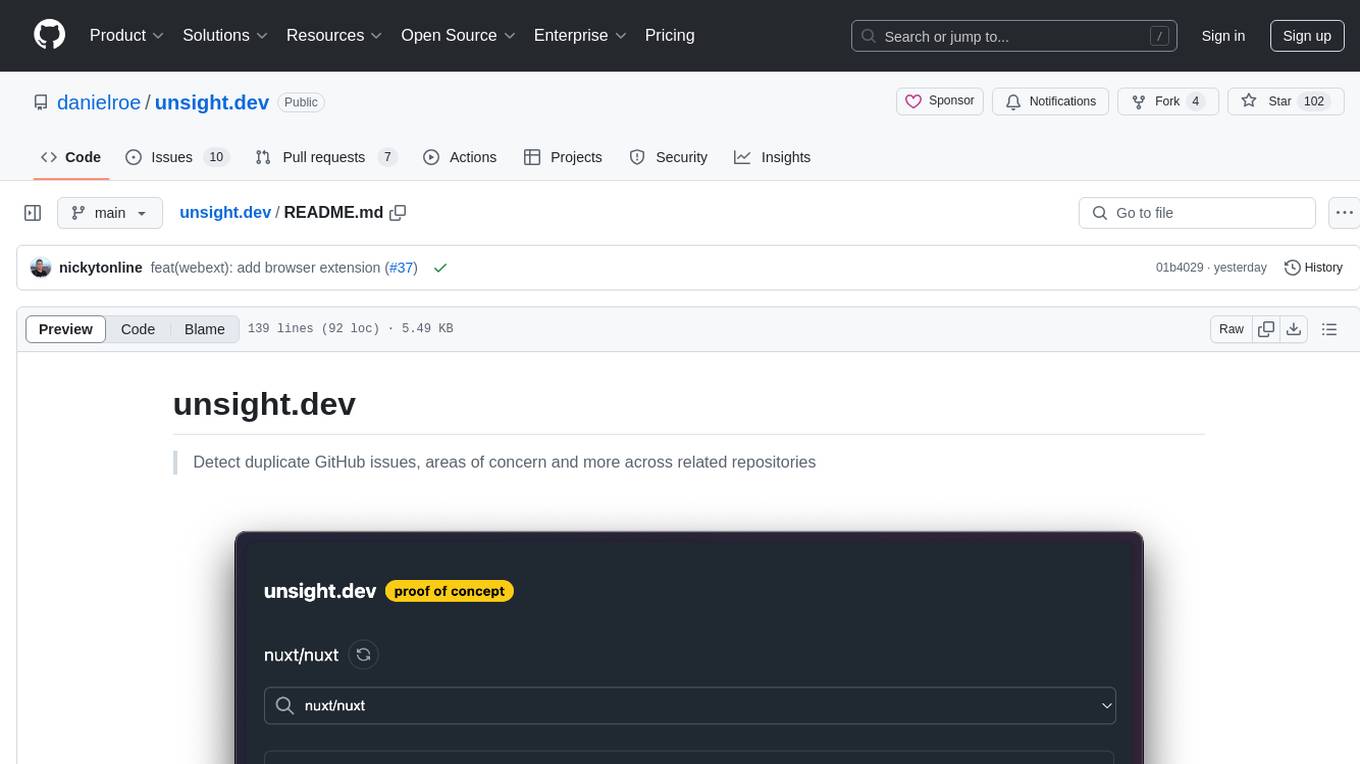
unsight.dev is a tool built on Nuxt that helps detect duplicate GitHub issues and areas of concern across related repositories. It utilizes Nitro server API routes, GitHub API, and a GitHub App, along with UnoCSS. The tool is deployed on Cloudflare with NuxtHub, using Workers AI, Workers KV, and Vectorize. It also offers a browser extension soon to be released. Users can try the app locally for tweaking the UI and setting up a full development environment as a GitHub App.
README:
Detect duplicate GitHub issues, areas of concern and more across related repositories
- Built on Nuxt
- Nitro server API routes
- GitHub API and a GitHub App
- UnoCSS
- Deployed on Cloudflare with NuxtHub, using Workers AI, Workers KV and Vectorize
![]()

![]()

You can try the app out locally (for tweaking the UI) using the deployed API.
corepack enable
pnpm i
pnpm dev --ui-only
This will fire up a dev server but use the remote API to populate it.
Setting up a full development environment takes a little extra effort because unsight.dev is implemented as a GitHub App. Here's how to set things up.
corepack enable
pnpm inpx ngrok http 3000Note the URL under Forwarding. It should look something like https://<GUID>.ngrok-free.app/. We'll use this in the next step.
-
Navigate to the GitHub Apps Settings panel and click 'New GitHub App'.
-
Fill out the form, not changing any defaults:
-
GitHub App name: Pick any name at all. I normally add
[dev]at the end of any apps I'm using in development only. -
Homepage URL: Doesn't matter; just pick a URL:
https://unsight.devwould be fine. -
Setup URL:
http://localhost:3000. Tick the 'Redirect on update' checkbox underneath. -
Webhook URL: Put the URL you got when starting ngrok, plus
/github/webhook:https://<GUID>.ngrok-free.app/github/webhook. For the 'Secret' field underneath the URL, create a random GUID or password and make a note of it. - Repository permissions: Select 'Issues': 'Read-only'.
- Subscribe to events: Select 'Installation target', 'Issues', 'Meta' and 'Repository'.
-
Note down the
App ID:in your GitHub App settings. -
Note the 'slug' of your GitHub App. You should be at a URL that looks something like this
https://github.com/settings/apps/unsight-dev. This last piece (unsight-dev) is your app slug. -
Scroll down to the bottom of the GitHub App setings and click 'Generate a private key'. It should download. Unfortunately this private key is in PKCS#1 format, but we need PKCS#8 in a Cloudflare environment. Run the following command:
openssl pkcs8 -topk8 -inform PEM -outform PEM -nocrypt -in <path to the downloaded file>.pem -out <path to your repo>-unsight-pkcs8.key(This outputs a private key file you'll use in the next step.)
Create a packages/web/.env file with the following content (the private key was generated in the last step and can be multi-line, just add a quote before and after it):
NUXT_WEBHOOK_GITHUB_SECRET_KEY=<random GUID or password you put in the Webhook Secret field when creating your GitHub App>
NUXT_PUBLIC_GITHUB_APP_SLUG=<your app slug you saw in the URL of your GitHub App settings>
NUXT_GITHUB_APP_ID=<GitHub App ID you saw in your GitHub App settings>
NUXT_GITHUB_PRIVATE_KEY="-----BEGIN PRIVATE KEY-----
MIIEvcIBADAEBgkqhkiG9w0BAQEFAASCBKgwggSkAgEAAoABADDbja1oaWVufjdT
...
+qWpvAnlgrGQqvbsuY+XuRnt
-----END PRIVATE KEY-----"We use Workers AI and to do that locally we'll need to hook up to Cloudflare. This project uses NuxtHub to do that. You can get going by creating a free NuxtHub account at https://admin.hub.nuxt.com.
Then run this command in your app directory:
cd packages/web/
npx nuxthub linkYou can select 'Create a new project'. Any storage region should be fine. Your Nuxt dev server should restart, and you'll see a new NUXT_HUB_PROJECT_KEY variable in your packages/web/.env file.
You can now visit http://localhost:3000 and click 'Install as a GitHub app'.
You can now directly visit http://localhost:3000/<your-user-name>/<your-repo> to view your clusters.
By default, in local development, we'll also index nuxt/nuxt and nitrojs/nitro so you don't have to register the GitHub app on any repository in order to see and play around with the cluster algorithm.
If you want to customise this, you can configure the DEV_REPOS_TO_INDEX environment variable.
# disable the feature entirely
DEV_REPOS_TO_INDEX=false
# specify a comma-separated list of repositories
DEV_REPOS_TO_INDEX=unjs/h3,vuejs/coreThese repositories will automatically be indexed when you start your dev server.
[!IMPORTANT] This only has an effect in development mode.
❤️ Thanks to Alvaro Saburido for the lovely logo!
Made with ❤️
Published under MIT License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for unsight.dev
Similar Open Source Tools
unsight.dev
unsight.dev is a tool built on Nuxt that helps detect duplicate GitHub issues and areas of concern across related repositories. It utilizes Nitro server API routes, GitHub API, and a GitHub App, along with UnoCSS. The tool is deployed on Cloudflare with NuxtHub, using Workers AI, Workers KV, and Vectorize. It also offers a browser extension soon to be released. Users can try the app locally for tweaking the UI and setting up a full development environment as a GitHub App.
TerminalGPT
TerminalGPT is a terminal-based ChatGPT personal assistant app that allows users to interact with OpenAI GPT-3.5 and GPT-4 language models. It offers advantages over browser-based apps, such as continuous availability, faster replies, and tailored answers. Users can use TerminalGPT in their IDE terminal, ensuring seamless integration with their workflow. The tool prioritizes user privacy by not using conversation data for model training and storing conversations locally on the user's machine.

airbyte_serverless
AirbyteServerless is a lightweight tool designed to simplify the management of Airbyte connectors. It offers a serverless mode for running connectors, allowing users to easily move data from any source to their data warehouse. Unlike the full Airbyte-Open-Source-Platform, AirbyteServerless focuses solely on the Extract-Load process without a UI, database, or transform layer. It provides a CLI tool, 'abs', for managing connectors, creating connections, running jobs, selecting specific data streams, handling secrets securely, and scheduling remote runs. The tool is scalable, allowing independent deployment of multiple connectors. It aims to streamline the connector management process and provide a more agile alternative to the comprehensive Airbyte platform.
qrev
QRev is an open-source alternative to Salesforce, offering AI agents to scale sales organizations infinitely. It aims to provide digital workers for various sales roles or a superagent named Qai. The tech stack includes TypeScript for frontend, NodeJS for backend, MongoDB for app server database, ChromaDB for vector database, SQLite for AI server SQL relational database, and Langchain for LLM tooling. The tool allows users to run client app, app server, and AI server components. It requires Node.js and MongoDB to be installed, and provides detailed setup instructions in the README file.
vasttools
This repository contains a collection of tools that can be used with vastai. The tools are free to use, modify and distribute. If you find this useful and wish to donate your welcome to send your donations to the following wallets. BTC 15qkQSYXP2BvpqJkbj2qsNFb6nd7FyVcou XMR 897VkA8sG6gh7yvrKrtvWningikPteojfSgGff3JAUs3cu7jxPDjhiAZRdcQSYPE2VGFVHAdirHqRZEpZsWyPiNK6XPQKAg RVN RSgWs9Co8nQeyPqQAAqHkHhc5ykXyoMDUp USDT(ETH ERC20) 0xa5955cf9fe7af53bcaa1d2404e2b17a1f28aac4f Paypal PayPal.Me/cryptolabsZA
aioli
Aioli is a library for running genomics command-line tools in the browser using WebAssembly. It creates a single WebWorker to run all WebAssembly tools, shares a filesystem across modules, and efficiently mounts local files. The tool encapsulates each module for loading, does WebAssembly feature detection, and communicates with the WebWorker using the Comlink library. Users can deploy new releases and versions, and benefit from code reuse by porting existing C/C++/Rust/etc tools to WebAssembly for browser use.

cognita
Cognita is an open-source framework to organize your RAG codebase along with a frontend to play around with different RAG customizations. It provides a simple way to organize your codebase so that it becomes easy to test it locally while also being able to deploy it in a production ready environment. The key issues that arise while productionizing RAG system from a Jupyter Notebook are: 1. **Chunking and Embedding Job** : The chunking and embedding code usually needs to be abstracted out and deployed as a job. Sometimes the job will need to run on a schedule or be trigerred via an event to keep the data updated. 2. **Query Service** : The code that generates the answer from the query needs to be wrapped up in a api server like FastAPI and should be deployed as a service. This service should be able to handle multiple queries at the same time and also autoscale with higher traffic. 3. **LLM / Embedding Model Deployment** : Often times, if we are using open-source models, we load the model in the Jupyter notebook. This will need to be hosted as a separate service in production and model will need to be called as an API. 4. **Vector DB deployment** : Most testing happens on vector DBs in memory or on disk. However, in production, the DBs need to be deployed in a more scalable and reliable way. Cognita makes it really easy to customize and experiment everything about a RAG system and still be able to deploy it in a good way. It also ships with a UI that makes it easier to try out different RAG configurations and see the results in real time. You can use it locally or with/without using any Truefoundry components. However, using Truefoundry components makes it easier to test different models and deploy the system in a scalable way. Cognita allows you to host multiple RAG systems using one app. ### Advantages of using Cognita are: 1. A central reusable repository of parsers, loaders, embedders and retrievers. 2. Ability for non-technical users to play with UI - Upload documents and perform QnA using modules built by the development team. 3. Fully API driven - which allows integration with other systems. > If you use Cognita with Truefoundry AI Gateway, you can get logging, metrics and feedback mechanism for your user queries. ### Features: 1. Support for multiple document retrievers that use `Similarity Search`, `Query Decompostion`, `Document Reranking`, etc 2. Support for SOTA OpenSource embeddings and reranking from `mixedbread-ai` 3. Support for using LLMs using `Ollama` 4. Support for incremental indexing that ingests entire documents in batches (reduces compute burden), keeps track of already indexed documents and prevents re-indexing of those docs.
reai-ghidra
The RevEng.AI Ghidra Plugin by RevEng.ai allows users to interact with their API within Ghidra for Binary Code Similarity analysis to aid in Reverse Engineering stripped binaries. Users can upload binaries, rename functions above a confidence threshold, and view similar functions for a selected function.
Discord-AI-Selfbot
Discord-AI-Selfbot is a Python-based Discord selfbot that uses the `discord.py-self` library to automatically respond to messages mentioning its trigger word using Groq API's Llama-3 model. It functions as a normal Discord bot on a real Discord account, enabling interactions in DMs, servers, and group chats without needing to invite a bot. The selfbot comes with features like custom AI instructions, free LLM model usage, mention and reply recognition, message handling, channel-specific responses, and a psychoanalysis command to analyze user messages for insights on personality.
CLI
Bito CLI provides a command line interface to the Bito AI chat functionality, allowing users to interact with the AI through commands. It supports complex automation and workflows, with features like long prompts and slash commands. Users can install Bito CLI on Mac, Linux, and Windows systems using various methods. The tool also offers configuration options for AI model type, access key management, and output language customization. Bito CLI is designed to enhance user experience in querying AI models and automating tasks through the command line interface.

azure-search-openai-javascript
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access the ChatGPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval.
actions
Sema4.ai Action Server is a tool that allows users to build semantic actions in Python to connect AI agents with real-world applications. It enables users to create custom actions, skills, loaders, and plugins that securely connect any AI Assistant platform to data and applications. The tool automatically creates and exposes an API based on function declaration, type hints, and docstrings by adding '@action' to Python scripts. It provides an end-to-end stack supporting various connections between AI and user's apps and data, offering ease of use, security, and scalability.
ComfyUI-mnemic-nodes
ComfyUI-mnemic-nodes is a repository hosting a collection of nodes developed for ComfyUI, providing useful components to enhance project functionality. The nodes include features like returning file paths, saving text files, downloading images from URLs, tokenizing text, cleaning strings, querying Groq language models, generating negative prompts, and more. Some nodes are experimental and marked with a 'Caution' label. Installation instructions and setup details are provided for each node, along with examples and presets for different tasks.

blinkid-react-native
BlinkID SDK wrapper for React Native provides best-in-class ID scanning software for cross-platform apps built with React Native. It offers complete guidance on installing and linking BlinkID library with iOS and Android apps. The SDK requires a valid license key for scanning, with offline data extraction. It supports React Native v0.71.2 and includes installation and linking instructions for iOS and Android. The repository also contains a script to create a sample React Native project and dependencies. Video tutorials demonstrate using documentVerificationOverlay and CombinedRecognizer for scanning various document types.

vector-vein
VectorVein is a no-code AI workflow software inspired by LangChain and langflow, aiming to combine the powerful capabilities of large language models and enable users to achieve intelligent and automated daily workflows through simple drag-and-drop actions. Users can create powerful workflows without the need for programming, automating all tasks with ease. The software allows users to define inputs, outputs, and processing methods to create customized workflow processes for various tasks such as translation, mind mapping, summarizing web articles, and automatic categorization of customer reviews.

civitai
Civitai is a platform where people can share their stable diffusion models (textual inversions, hypernetworks, aesthetic gradients, VAEs, and any other crazy stuff people do to customize their AI generations), collaborate with others to improve them, and learn from each other's work. The platform allows users to create an account, upload their models, and browse models that have been shared by others. Users can also leave comments and feedback on each other's models to facilitate collaboration and knowledge sharing.
For similar tasks
unsight.dev
unsight.dev is a tool built on Nuxt that helps detect duplicate GitHub issues and areas of concern across related repositories. It utilizes Nitro server API routes, GitHub API, and a GitHub App, along with UnoCSS. The tool is deployed on Cloudflare with NuxtHub, using Workers AI, Workers KV, and Vectorize. It also offers a browser extension soon to be released. Users can try the app locally for tweaking the UI and setting up a full development environment as a GitHub App.
suno-music-generator
Suno Music Generator is an unofficial website based on NextJS for suno.ai music generation. It can generate songs you want in about a minute by using user input prompts. The project reverse engineers suno.ai's song generation API using JavaScript and integrates payment with Lemon Squeezy. It also includes token update and maintenance features to prevent token expiration. Users can deploy the project with Vercel and follow a quick start guide to set up the environment and run the project locally. The project acknowledges Suno AI, NextJS, Clerk, node-postgres, tailwindcss, Lemon Squeezy, and aiwallpaper. Users can contact the developer via Twitter and support the project by buying a coffee.
langroid-examples
Langroid-examples is a repository containing examples of using the Langroid Multi-Agent Programming framework to build LLM applications. It provides a collection of scripts and instructions for setting up the environment, working with local LLMs, using OpenAI LLMs, and running various examples. The repository also includes optional setup instructions for integrating with Qdrant, Redis, Momento, GitHub, and Google Custom Search API. Users can explore different scenarios and functionalities of Langroid through the provided examples and documentation.
LLM-Merging
LLM-Merging is a repository containing starter code for the LLM-Merging competition. It provides a platform for efficiently building LLMs through merging methods. Users can develop new merging methods by creating new files in the specified directory and extending existing classes. The repository includes instructions for setting up the environment, developing new merging methods, testing the methods on specific datasets, and submitting solutions for evaluation. It aims to facilitate the development and evaluation of merging methods for LLMs.
shortest
Shortest is a project for local development that helps set up environment variables and services for a web application. It provides a guide for setting up Node.js and pnpm dependencies, configuring services like Clerk, Vercel Postgres, Anthropic, Stripe, and GitHub OAuth, and running the application and tests locally.
intro-to-llms-365
This repository serves as a resource for the Introduction to Large Language Models (LLMs) course, providing Jupyter notebooks with hands-on examples and exercises to help users learn the basics of Large Language Models. It includes information on installed packages, updates, and setting up a virtual environment for managing packages and running Jupyter notebooks.
perplexity-mcp
Perplexity-mcp is a Model Context Protocol (MCP) server that provides web search functionality using Perplexity AI's API. It works with the Anthropic Claude desktop client. The server allows users to search the web with specific queries and filter results by recency. It implements the perplexity_search_web tool, which takes a query as a required argument and can filter results by day, week, month, or year. Users need to set up environment variables, including the PERPLEXITY_API_KEY, to use the server. The tool can be installed via Smithery and requires UV for installation. It offers various models for different contexts and can be added as an MCP server in Cursor or Claude Desktop configurations.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.