Best AI tools for< Voice Control >
20 - AI tool Sites

Controlla Voice
Controlla Voice is an AI application that allows users to transform vocals into new voices or instruments, swap any song to their own voice in any language, and create unique blended voices. Users can train their own AI singing voice, generate AI cover songs, and create realistic choirs with customizable harmonies. The application provides a vocal toolkit for never-before-heard sounds and offers flexible pricing options to access high-quality AI singing voices. With Controlla Voice, users can enhance their voice, express themselves in their most natural way, and monetize their music with automatic royalties.
OpenVoiceOS
OpenVoiceOS is a community-driven, open-source voice AI platform for creating custom voice-controlled interfaces across devices with NLP, a customizable UI, and a focus on privacy and security. OpenVoiceOS is designed to provide users with a seamless and intuitive voice interface for controlling their smart home devices, playing music, setting reminders, and much more. OpenVoiceOS is open to all developers and contributors wanting to support a specific device or a platform. OpenVoiceOS is the platform to throw your ideas at if you have an experimental feature you want users to experience before landing them into any of the Linux-based open-source voice assistant projects upstream.

Zenen AI
Zenen AI is a cutting-edge AI assistant designed to offer human-like voice conversations, extensive knowledge, and multilingual support. It can help with creative brainstorming, writing content & emails, and serve as a companion for discussions on various topics. Zenen is still under development and may not always provide accurate or comprehensive information, but it excels in imaginative thinking and unconventional solutions.
Speakflow
Speakflow is an online teleprompter that helps creators nail their takes and reduce recording time. It offers features such as voice-controlled scrolling, auto-save, revision history, AI-assisted writing, video recording, team collaboration, and device syncing. Speakflow is compatible with physical teleprompter hardware and works on PC, Mac, Android, and iOS without requiring downloads.

Josh.ai
Josh.ai is an advanced AI control system for the smart home that utilizes natural interfaces like voice and touch to orchestrate technology in all aspects of the home. It aims to inspire, embolden, and delight users by providing an exciting and effortless living experience. Josh.ai is evolving to deliver its supercharged JoshGPT assistant at home and on-the-go, offering seamless integration with connected devices for smart home control and customization. With a focus on privacy, innovation, beauty, peace, comfort, flexibility, simplicity, security, delight, time, wellness, intelligence, and magic, Josh.ai is designed to empower every family member with intuitive control and intelligent assistance.
Fluid
Fluid is a private AI assistant designed for Mac users, specifically those with Apple Silicon and macOS 14 or later. It offers offline capabilities and is powered by the advanced Llama 3 AI by Meta. Fluid ensures unparalleled privacy by keeping all chats and data on the user's Mac, without the need to send sensitive information to third parties. The application features voice control, one-click installation, easy access, security by design, auto-updates, history mode, web search capabilities, context awareness, and memory storage. Users can interact with Fluid by typing or using voice commands, making it a versatile and user-friendly AI tool for various tasks.
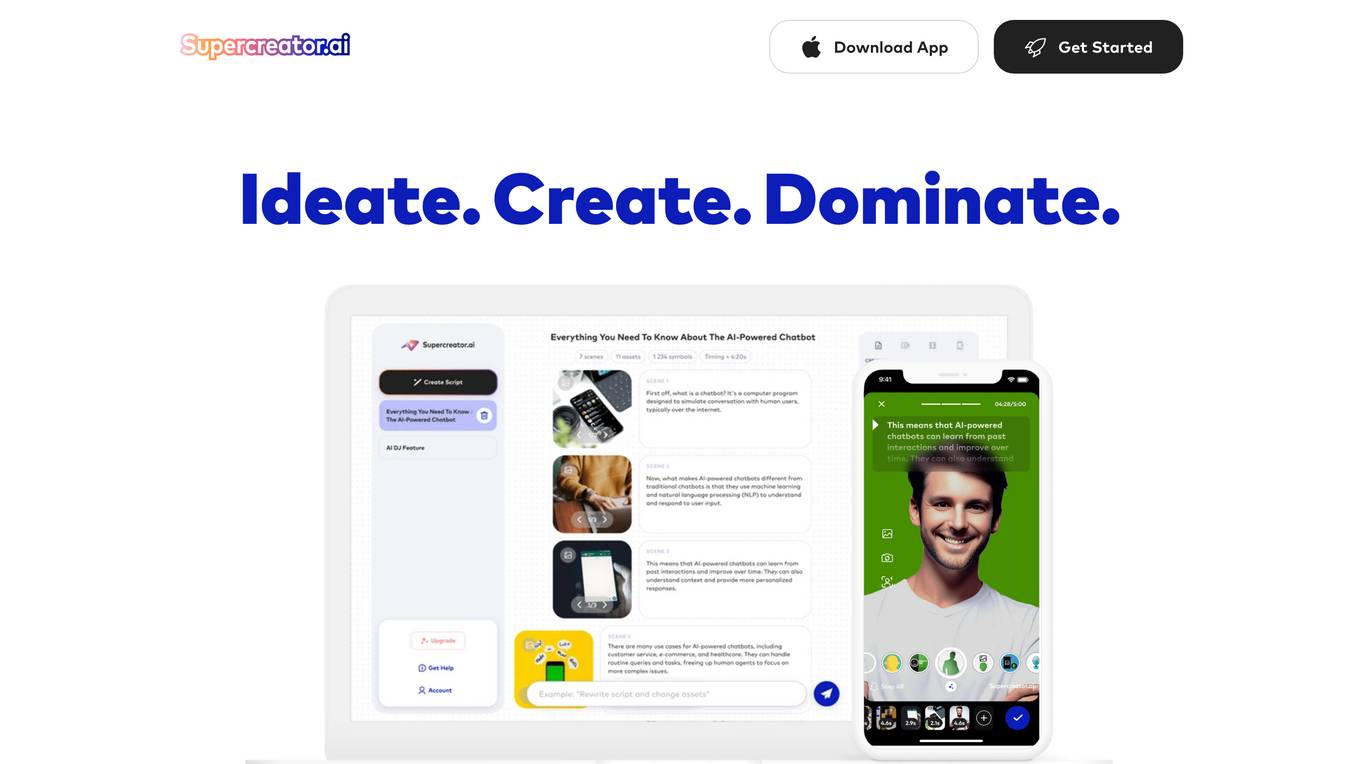
Supercreator
Supercreator is an AI-powered video creation platform that helps users create short-form videos quickly and easily. With a range of features to guide users through every stage of video creation, Supercreator simplifies tasks and makes video creation accessible to everyone. The platform offers features such as converting articles, Twitter threads, and YouTube videos to scripts, as well as providing natural text to script, importing scripts, and creating scripts from scratch. Supercreator also includes advanced editing capabilities such as advanced captions, auto-placement of relevant titles, smart trimming of empty pauses, super editing, adding overlay images and texts, and using fully customizable templates. Additionally, the platform provides a dynamic green screen, AR filters, text-to-filter, voice-controlled camera, HD recording, and audio-only recording options. Supercreator also assists with posting videos by exporting them in various formats to popular platforms and automatically tailoring hashtags, captions, catchy titles, and long posts to improve algorithm performance.
Reason ONE AI
Reason ONE Smart Alarm Clock with Alexa by ZMI USA is an AI-powered smart alarm clock application designed to enhance your morning routine. It integrates with Alexa for voice commands and offers a range of features to help you start your day right. With Reason ONE, you can set alarms, check the weather, play music, and more, all with the power of AI technology. The application provides a seamless user experience and aims to make waking up easier and more enjoyable.
VoiceCanvas
VoiceCanvas is an advanced AI-powered multilingual voice synthesis and voice cloning platform that offers instant text-to-speech in over 40 languages. It utilizes cutting-edge AI technology to provide high-quality voice synthesis with natural intonation and rhythm, along with personalized voice cloning for more human-like AI speech. Users can upload voice samples, have AI analyze voice features, generate personalized AI voice models, input text for conversion, and apply the cloned AI voice model to generate natural voice speech. VoiceCanvas is highly praised by language learners, content creators, teachers, business owners, voice actors, and educators for its exceptional voice quality, multiple language support, and ease of use in creating voiceovers, learning materials, and podcast content.
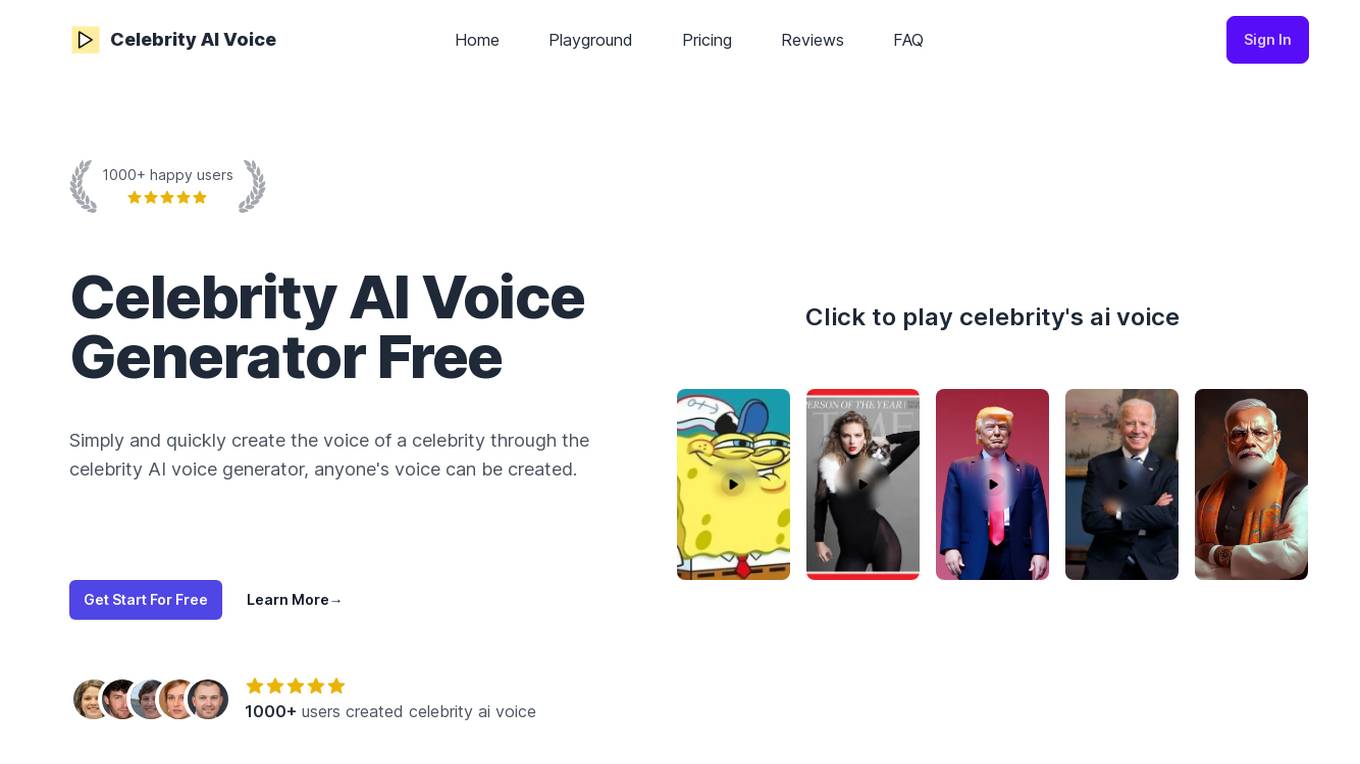
Celebrity AI Voice Generator
Celebrity AI Voice Generator is a free online tool that allows you to create realistic AI-generated voices of celebrities. With just a short audio clip of the person you want to replicate, you can generate voices that sound incredibly real. The tool is easy to use and offers a variety of features, including the ability to control voice styles, emotions, and accents. You can also use the tool to generate voices in different languages. Celebrity AI Voice Generator is a powerful tool that can be used for a variety of purposes, including creating voiceovers, dubbing videos, and developing video games.
Transgate
Transgate is an AI-powered speech-to-text conversion tool that allows users to convert audio/video files to text with high accuracy and efficiency. It offers a pay-as-you-go model, supports over 50 languages, and guarantees 98%+ accuracy. Transgate is designed to boost productivity by minimizing costs and eliminating manual transcription tasks, catering to industries like AI/ML, medical, legal, education, consulting, and market research.
Spoken AI
Spoken AI is an innovative AI tool that enables users to interact with technology through voice commands. It leverages cutting-edge natural language processing and machine learning algorithms to understand and respond to spoken language. With Spoken AI, users can perform various tasks hands-free, such as setting reminders, sending messages, playing music, and getting weather updates. The application aims to enhance user experience by providing a seamless and intuitive way to engage with devices using voice input.

My Voice AI
My Voice AI is an advanced voice identity security infrastructure that provides privacy-preserving, real-time voice authentication and deepfake protection. It is designed to reduce fraud, impersonation, and identity risk in voice-based interactions by offering speaker verification, anti-spoofing, and deepfake detection capabilities. The platform operates as a voice identity layer integrated into existing infrastructure, offering enterprise-grade latency, privacy-first architecture, and deterministic behavior suitable for audits. My Voice AI is purpose-built for regulated environments, such as financial institutions, critical services, and governments, where identity assurance is crucial to mitigate operational risks.
Swift
Swift is an AI-powered voice assistant that utilizes cutting-edge technologies such as Groq, Cartesia, VAD, and Vercel to provide users with a fast and efficient voice interaction experience. With Swift, users can perform various tasks using voice commands, making it a versatile tool for hands-free operation in different settings. The application aims to streamline daily tasks and enhance user productivity through seamless voice recognition capabilities.
Zonos TTS
Zonos TTS is an advanced multilingual text-to-speech tool that utilizes high-quality AI technology to deliver natural and expressive voice generation. With features like zero-shot voice cloning, multilingual support, and emotion control, Zonos TTS offers users the ability to create lifelike speech with customizable settings. The tool is suitable for various applications, from content creation to virtual assistants, audiobooks, gaming, e-learning, and more. Zonos TTS provides fast real-time processing and a user-friendly interface for seamless speech synthesis.
Soopra
Soopra is a platform that allows experts, educators, and influencers to create and engage with AI Personas. These AI Personas can be trained with the user's data and personality, and can then be used to engage with knowledge seekers and fans at scale. Soopra offers a variety of features to help users create and manage their AI Personas, including 24/7 access, robust analytics, and monetization options.
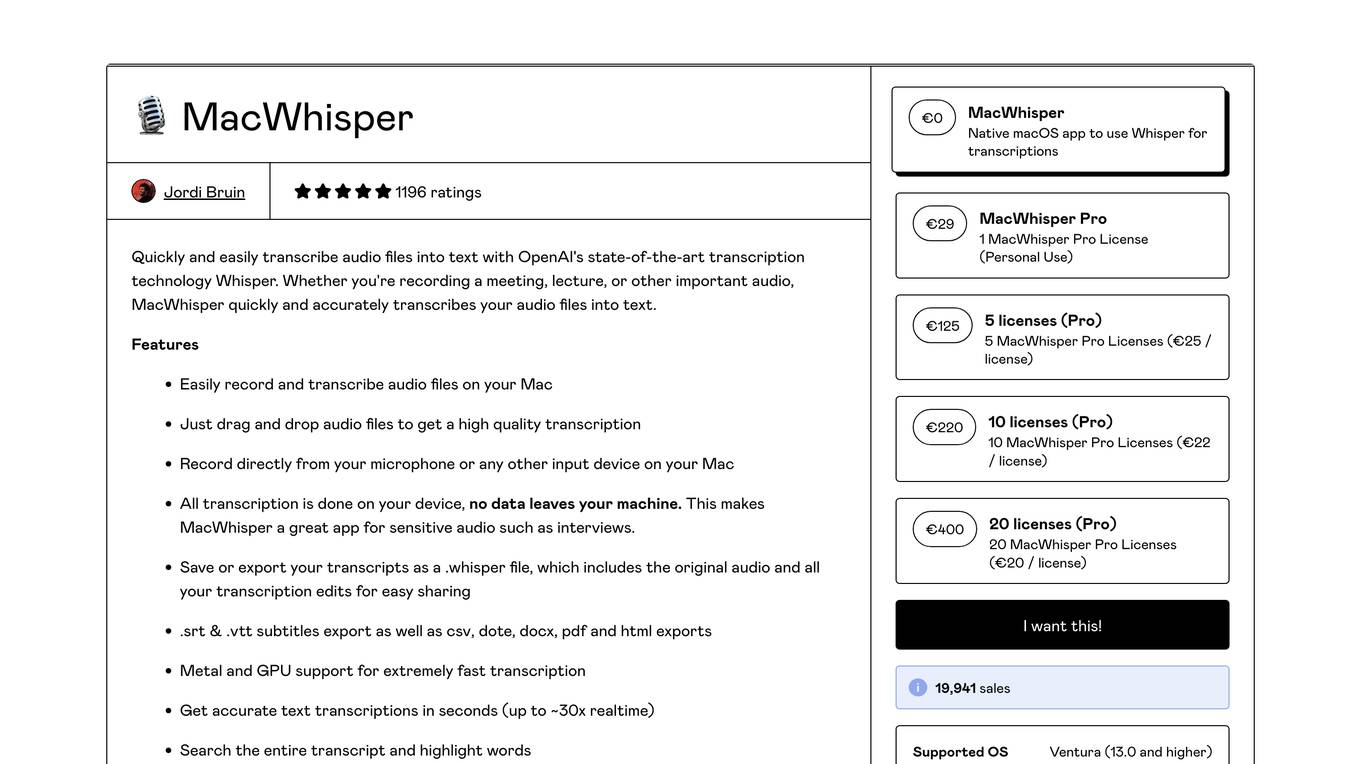
MacWhisper
MacWhisper is a native macOS application that utilizes OpenAI's Whisper technology for transcribing audio files into text. It offers a user-friendly interface for recording, transcribing, and editing audio, making it suitable for various use cases such as transcribing meetings, lectures, interviews, and podcasts. The application is designed to protect user privacy by performing all transcriptions locally on the device, ensuring that no data leaves the user's machine.

Linda
Linda is an AI-powered platform that helps users transform guided conversations into shareable audio memories. It offers a secure and private environment for users to create personalized podcast episodes based on their life stories. Linda uses advanced voice technology to conduct interviews, create podcasts, and provide a seamless user experience. With expertly crafted interviews and memory-driven conversations, Linda aims to help users explore and articulate their memories in a meaningful way. The platform also offers privacy controls, customization options, and themed interviews to capture special moments throughout the year.
Covers.AI
Covers.AI is an AI voice generator and AI song generator platform that allows users to create custom AI voices by uploading voice recordings. It offers a wide range of AI voice models for various categories such as anime, cartoons, streamers, gaming, famous personalities, and more. Users can easily generate AI voices and songs in minutes, making it a game-changing tool for music lovers of all levels of expertise. Covers.AI provides a user-friendly experience, empowering users to control and enhance their voices effortlessly.
LazyBird
LazyBird is an AI Voice-Over Generator that provides realistic voices with natural intonations, offering the best AI voice-over experience to captivate your audience. Users can easily create voice-overs by uploading scripts, selecting voices, editing timing, and exporting the final result. With a wide range of characters, accents, and tones to choose from, LazyBird allows users to find the perfect voice for their content. Additionally, users can sync their video and audio files with AI-generated voice-overs, access a rich library of stock videos and images, and enjoy features like granular word-level control, 60+ natural-sounding voices, 100+ languages and accents, advanced audio timeline, and more.
1 - Open Source AI Tools
tb1
A Telegram bot for accessing Google Gemini, MS Bing, etc. The bot responds to the keywords 'bot' and 'google' to provide information. It can handle voice messages, text files, images, and links. It can generate images based on descriptions, extract text from images, and summarize content. The bot can interact with various AI models and perform tasks like voice control, text-to-speech, and text recognition. It supports long texts, large responses, and file transfers. Users can interact with the bot using voice commands and text. The bot can be customized for different AI providers and has features for both users and administrators.
20 - OpenAI Gpts
🤖 SmartLink Integrator 🌎
Your AI bridge to the Internet of Things! Easily connect, control, and automate your smart devices with voice or text commands. 🏠💎
Anime Voice Match
Anime Voice Match, identifies anime characters similar to the user's voice.
Voice/Style/Tone AI Prompt Snippet Generator
Analyzes your writing and produces a prompt snippet you can use in any other prompt to guide AI in replicating your voice, style, and tone. Just provide the text in the prompt box or in a document (don't use a link or image). You don't need to write any additional prompt language with your text.


Voice Memo
Record your thoughts with ChatGPT Voice Conversations 💡. Get started by clicking the 🎧 icon right to the chat input. Available on mobile only. Ask 'how do you work?' to learn more.
Vedic Voice
A scholar in Hindu literature providing positive, brief insights against negativity.

Skillful Voice
Premier expert in household management, offering unparalleled advice and guidance.


Earth Conscious Voice
Hi ;) Ask me for data & insights gathered from an environmentally aware global community
Bring Your Writing Voice to Every Task
This GPT will help you recreate your writing voice across multiple tasks. All you need is a prior writing sample (email, blog, article, tweet) and a new task.
Passive to Active Voice Text Converter AI
I convert and rewrite passive voice text into active voice tone and language. Simply put your passive voice text below! Perfect for sentences, paragraphs, daily emails, and longer texts.