Best AI tools for< Transcribe Text >
20 - AI tool Sites
Podcastle
Podcastle is an all-in-one podcasting software that empowers creators of all backgrounds and experience levels with an intuitive, AI-powered platform. It offers a wide range of features, including a recording studio, audio editor, video editor, AI-generated voices, and hosting hub, making it easy to create, edit, and publish high-quality podcasts and videos. Podcastle is designed to be user-friendly and accessible, with no prior experience or technical expertise required.
Zeemo AI
Zeemo AI is a powerful caption generator tool that enables users to add subtitles to videos, transcribe video and audio to text, and generate captions using AI technology. It supports multiple languages and provides dynamic visual effects for captions. The tool is designed for content creators, educators, and product sellers to enhance their videos and reach a wider audience across various platforms.
SpeechText.AI
SpeechText.AI is a powerful artificial intelligence software for speech to text conversion and audio transcription. It offers accurate transcriptions of audio and video files using domain-specific speech recognition technology. The application provides various features to transcribe, edit, and export audio content in different formats. With state-of-the-art deep neural network models, SpeechText.AI achieves close to human accuracy in converting audio to text. The tool is widely used for transcription of interviews, medical data, conference calls, podcasts, and more, catering to various industries such as finance, healthcare, legal, and HR.
Rythmex Converter
Rythmex Converter is an AI-powered audio-to-text converter tool that allows users to easily, quickly, and effectively transcribe audio files into text. With support for over 140 languages, Rythmex offers a seamless transcription experience for various industries such as business, education, journalism, law, and more. Users can upload their audio or video files, choose the language, and receive accurate transcriptions within minutes. The tool is designed to save time and effort by providing automated transcription services using machine learning technology.
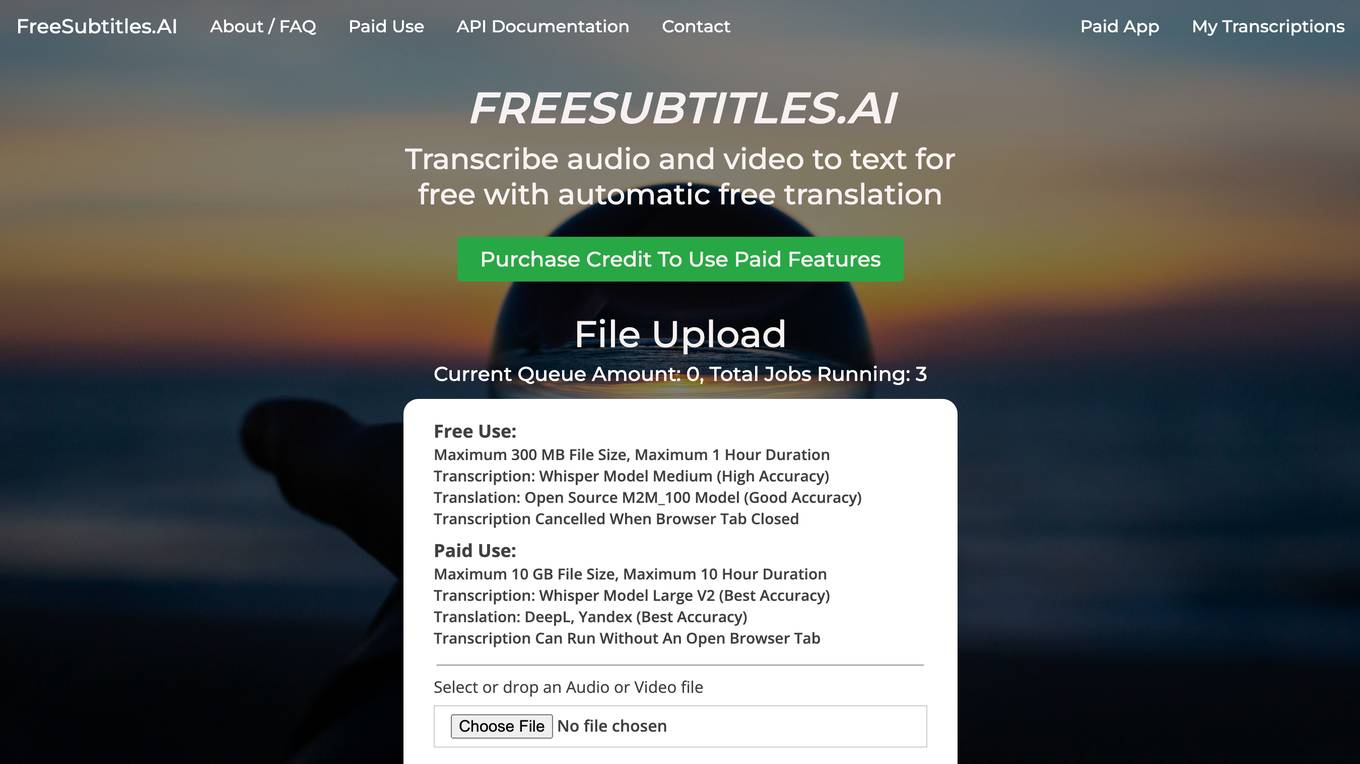
FreeSubtitles.AI
FreeSubtitles.AI is a free online tool that allows users to transcribe audio and video files to text. It supports a wide range of file formats and languages, and offers both free and paid transcription services. The free service allows users to transcribe files up to 300 MB in size and 1 hour in duration, while the paid service offers more advanced features such as larger file size limits, longer transcription durations, and higher accuracy models.
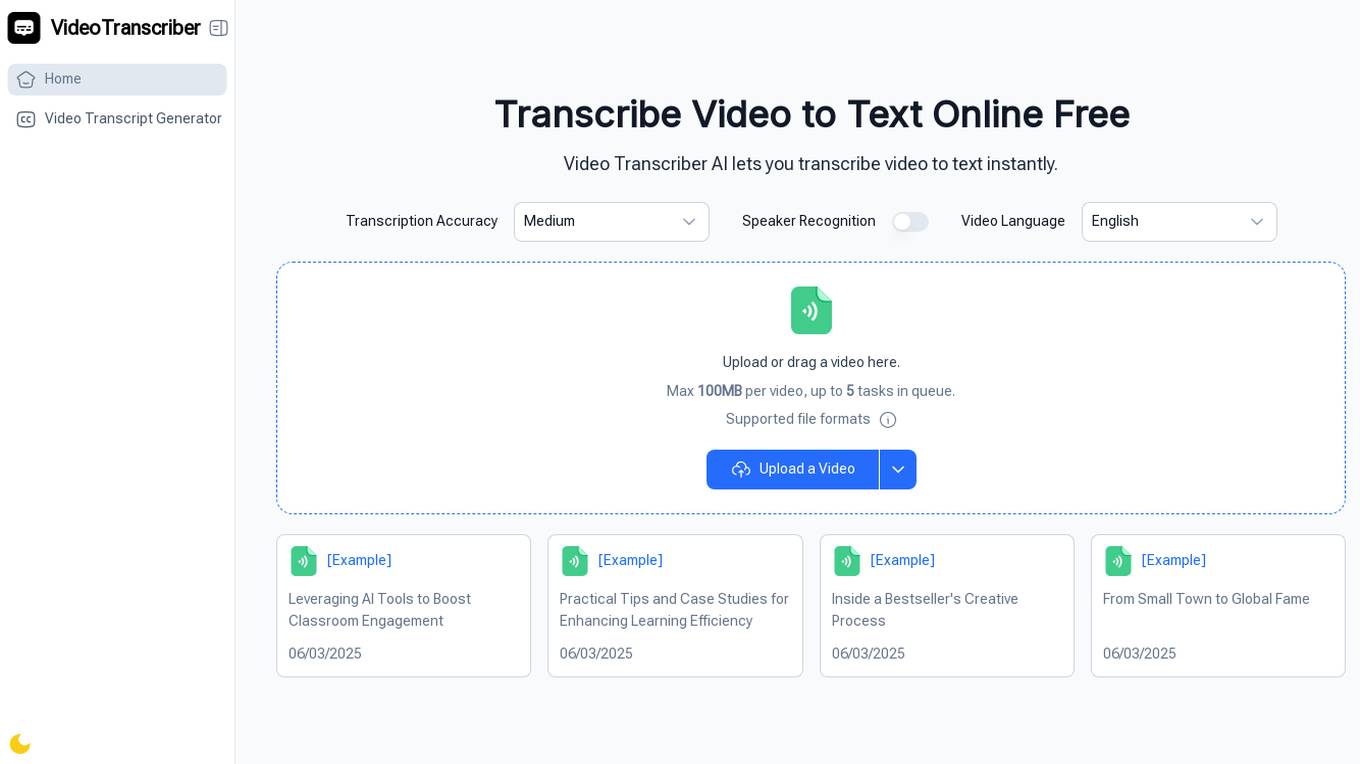
Video Transcriber AI
Video Transcriber AI is an online tool that allows users to transcribe any video into clear, accurate text in seconds. It supports various video formats, speaker recognition, multiple transcription accuracy modes, and works in multiple languages. Users can easily upload videos, let AI transcribe them, and then copy, download, or share the transcripts for study, work, or content creation.
Voice Pen
Voice Pen is a Speech to Text AI application available on the App Store for Apple devices. It allows users to record and transcribe speech into text, which can then be used to create notes, summaries, emails, messages, and blog posts. The app supports more than 50 languages and offers AI options for rewriting and transforming text. Voice Pen enhances productivity by providing features like background audio recording, language autodetection, and the ability to create various types of content. It also prioritizes user privacy by only collecting app usage analytics and not storing any audio or text data on its servers.
Vemo AI
Vemo AI is a cutting-edge voice-to-text application that transforms messy voice notes into publish-ready text in a fraction of the time. With the latest AI technologies, Vemo allows users to effortlessly record their thoughts, ideas, or anything else, and then transcribe them into various types of content such as journal entries, cleaned-up transcripts, and blogs. Users can edit and restyle their notes as they wish, enhancing their productivity and creativity. Vemo AI has received rave reviews for its accuracy, ease of use, and ability to streamline note-taking processes, making it a must-have tool for writers, bloggers, students, and professionals.
AssemblyAI
AssemblyAI is an AI tool that provides AI models for transcribing and understanding speech. Their products include Speech-to-Text Streaming, Speech Understanding, and more. AssemblyAI's research focuses on building new AI systems that can understand human speech with superhuman abilities. They offer industry-leading accuracy, low Word Error Rate (WER), and advanced capabilities like speaker identification and multilingual speech recognition. The platform is designed to be easy to use, scalable, and cost-effective for developers. AssemblyAI is trusted by top Voice AI companies for launching innovative products quickly and efficiently.
Vocaldo
Vocaldo is a revolutionary speech-to-text application that utilizes cutting-edge AI technology to transcribe speech into text in over 100 languages. It offers accurate, fast, and easy-to-use transcription services, allowing users to effortlessly convert audio or video files into text with high precision. Vocaldo supports multiple speakers, various accents, and background noise, making it a versatile tool for content creators, journalists, and businesses worldwide.
Rev
Rev is a leading transcription service provider offering human and AI transcription solutions with high accuracy rates. The platform enables users to transcribe audio and video content efficiently, generate captions and subtitles in multiple languages, and access speech-to-text solutions for various industries such as news organizations, market research, video distribution, and legal services. Rev's AI-powered tools enhance content accessibility, global reach, and audience engagement, making it a versatile and reliable platform for transcription needs.
EdMon.AI
EdMon.AI is an AI-powered application that specializes in audio and video transcription. It consists of two main components - EdMon Producer, a content viewing and video editing tool for post-production teams, and EdMon Transcriber, an AI-powered transcription tool for media managers. The application is designed to revolutionize efficiency in collaborative content creation by managing and utilizing large volumes of video content. Developed by a team with extensive experience in the broadcast and post-production industry, EdMon.AI offers seamless integration with industry-standard software like Avid Media Composer and Adobe Premiere Pro.
AssemblyAI
AssemblyAI is an industry-leading Speech AI tool that offers powerful SpeechAI models for accurate transcription and understanding of speech. It provides breakthrough speech-to-text models, real-time captioning, and advanced speech understanding capabilities. AssemblyAI is designed to help developers build world-class products with unmatched accuracy and transformative audio intelligence.

Vscoped
Vscoped is an AI-powered audio to text transcribing service that provides fast and accurate transcriptions in over 90 languages. It also offers transcription insights and translation services. Vscoped is suitable for various types of audio content, including business meetings, interviews, sales calls, and videos. With its exceptional accuracy, multilingual capabilities, and intuitive user experience, Vscoped helps businesses and individuals boost productivity and gain insights from their audio data.
Ecango
Ecango is an AI-powered audio and video transcription tool that allows users to convert audio and video files into text in over 133 languages. It is easy to use, accurate, and affordable, making it a great choice for businesses and individuals alike.
Wave
Wave is an AI-powered transcription and summarization application designed for iOS and Android devices. It allows users to effortlessly record audio, transcribe it into text, and generate concise summaries. With features like multilingual support, phone call capture, and Siri shortcut compatibility, Wave aims to streamline note-taking during meetings, walk and talks, and other important moments. Users can customize the length and format of summaries, share audio recordings easily, and enjoy unlimited recording capabilities. Wave prioritizes user privacy and offers different pricing plans based on recording needs.
Voicetapp
Voicetapp is a powerful cloud-based artificial intelligence software that helps you automatically convert audio to text with up to 100% accuracy. It supports over 170 languages and dialects, allowing you to quickly and accurately transcribe speech from audio and video files. Voicetapp also offers features such as speaker identification, live transcription, and multiple input formats, making it a versatile tool for various use cases.
MeduzaAi
MeduzaAi is an all-in-one platform that leverages the power of AI to generate text, images, code, chat, and more with multi-lingual abilities. It offers various tools such as AI Text Generator, AI Image Generator, AI Code Generator, AI Chat Bot, and AI Speech To Text to empower users in content creation and communication. The platform aims to help users unleash their creativity, streamline their coding process, transcribe speech into text, and provide human-like chatbot assistance. MeduzaAi caters to digital agencies, product designers, entrepreneurs, copywriters, digital marketers, and developers, offering a range of features to enhance productivity and creativity.
Life Story AI
Life Story AI is an application that utilizes artificial intelligence to assist users in writing their life stories or the life stories of their parents. The app guides users through a series of questions, transcribes their responses, and compiles them into a personalized book of up to 250 pages. Users can customize the cover, edit content, and add photos to create a unique family memoir. With features like voice-to-text transcription, grammar correction, and style formatting, Life Story AI simplifies the process of preserving cherished memories in a beautifully crafted book.
Fineshare
Fineshare is an online AI audio creator tool that offers a wide range of features for voice, music, and sound generation. Users can transform their voice, create AI covers, generate audio from videos, transcribe audio to text, and more. The tool provides advanced AI technology to simplify audio creation and unlock creativity. Fineshare is trusted by over 10 million customers worldwide and offers personalized AI voice and professional-grade video voiceover capabilities.
1 - Open Source AI Tools
simulflow
Simulflow is a Clojure framework for building real-time voice-enabled AI applications using a data-driven, functional approach. It provides a composable pipeline architecture for processing audio, text, and AI interactions with built-in support for major AI providers. The framework uses processors that communicate through specialized frames to create voice-enabled AI agents, allowing for mental multitasking and rational thought. Simulflow offers a flow-based architecture, data-first design, streaming architecture, extensibility, flexible frame system, and built-in services for seamless integration with major AI providers. Users can easily swap components, add new functionality, or debug individual stages without affecting the entire system.
20 - OpenAI Gpts

Pic2Text
Friendly GPT for converting images to text, focusing on user-friendly interactions.




Journal Recognizer OCR
Optimized OCR for Handwritten Notebooks, up to 10 image transcript copy w/1-click. No text prompt necessary. Reads journals, reports, notes. All handwriting transcribed verbatim, then text summarized, graphic image features described. Ask to change any behavior.
CliniType EHR
Voice-to-text, Vision-to-text transcription, Transcript-to-‘Clinical format’ integrated with CDS. Writes clinical notes, referral letter, generate PDF,prepare discharge summary. (Ultimate aid for clinicians)

SpeechGPT User Guide
A guide for using SpeechGPT, focusing on its features, setup, and usage.



DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages
Speech Parody
Create speech transcript parodies. Copyright (C) 2023, Sourceduty - All Rights Reserved.

Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.