Best AI tools for< Transcribe A Speech >
20 - AI tool Sites
Must AI Generator
Must AI Generator is an all-in-one platform that provides AI-powered content creation tools to help businesses and individuals generate high-quality text, images, code, chat responses, and more. With its user-friendly interface and advanced AI technology, Must AI Generator makes it easy to create engaging and effective content for various marketing and communication needs.
Voice Pen
Voice Pen is a Speech to Text AI application available on the App Store for Apple devices. It allows users to record and transcribe speech into text, which can then be used to create notes, summaries, emails, messages, and blog posts. The app supports more than 50 languages and offers AI options for rewriting and transforming text. Voice Pen enhances productivity by providing features like background audio recording, language autodetection, and the ability to create various types of content. It also prioritizes user privacy by only collecting app usage analytics and not storing any audio or text data on its servers.
Deepgram
Deepgram is a speech recognition and transcription service that uses artificial intelligence to convert audio into text. It is designed to be accurate, fast, and easy to use. Deepgram offers a variety of features, including: - Automatic speech recognition - Speaker diarization - Language identification - Custom acoustic models - Real-time transcription - Batch transcription - Webhooks - Integrations with popular platforms such as Zoom, Google Meet, and Microsoft Teams
YobiYoba
YobiYoba is a speech recognition service that offers automatic transcription of audio and video recordings. Users can upload files in any format, specify the language, and receive time-coded transcripts that can be edited. The service identifies speech segments, recognizes languages, and converts speech to text with high accuracy. YobiYoba provides various text and subtitling formats for exporting transcriptions, along with a simple pay-as-you-go pricing scheme.
SpeechFlow
SpeechFlow is a powerful speech-to-text API that transcribes audio and video files into text with high accuracy. It supports 14 languages and offers features such as punctuation, easy deployment, scalability, and fast processing. SpeechFlow is ideal for businesses and individuals who need accurate and timely transcription services.
Rev AI
Rev AI is a leading Speech to Text API and Speech Recognition Service provider, offering high accuracy and a wide range of features for audio and video transcription. Their AI models are trained on a diverse collection of voices, setting the standard for accuracy in video and voice applications. With a focus on accuracy, readability, and security, Rev AI provides a comprehensive solution for speech-to-text and natural language processing needs.
Vocaldo
Vocaldo is a revolutionary speech-to-text application that utilizes cutting-edge AI technology to transcribe speech into text in over 100 languages. It offers accurate, fast, and easy-to-use transcription services, allowing users to effortlessly convert audio or video files into text with high precision. Vocaldo supports multiple speakers, various accents, and background noise, making it a versatile tool for content creators, journalists, and businesses worldwide.

Speech Studio
Speech Studio is a cloud-based speech-to-text and text-to-speech platform that enables developers to add speech capabilities to their applications. With Speech Studio, developers can easily transcribe audio and video files, generate synthetic speech, and build custom speech models. Speech Studio is a powerful tool that can be used to improve the accessibility, efficiency, and user experience of any application.
VoxSigma
Vocapia Research develops leading-edge, multilingual speech processing technologies exploiting AI methods such as machine learning. These technologies enable large vocabulary continuous speech recognition, automatic audio segmentation, language identification, speaker diarization and audio-text synchronization. Vocapia's VoxSigma™ speech-to-text software suite delivers state-of-the-art performance in many languages for a variety of audio data types, including broadcast data, parliamentary hearings and conversational data.
Interpre-X
Interpre-X is a real-time speech translation tool powered by AI. It offers speech-to-speech, speech-to-text, text-to-speech, and text-to-text translation in over 10 languages. Interpre-X is designed to break down language barriers and facilitate communication between people who speak different languages. It is suitable for both personal and professional use, and it can be used in a variety of settings, such as travel, business meetings, and language learning.
Whisper Web
Whisper Web is a free AI speech recognition tool that offers advanced speech recognition powered by machine learning algorithms. Users can transform voice recordings, audio files, and online audio into accurate text transcriptions with complete privacy protection through local processing in the browser. The tool supports multiple input methods, real-time processing, and export options in various formats, making it ideal for journalists, researchers, students, and professionals who require precise voice-to-text conversion.
TakeNote
TakeNote is a cutting-edge speech-to-text AI that transforms audio and video into documents, boosting productivity and enhancing meeting experiences. Its advanced AI models provide exceptional accuracy, approaching human-level robustness and accuracy in English speech recognition. TakeNote AI empowers teams to transcribe meetings into accurate transcripts, generate precise summaries, analyze sentiment, and identify speakers, all while ensuring high levels of security and data protection.
SpeechText.AI
SpeechText.AI is a powerful artificial intelligence software for speech to text conversion and audio transcription. It offers accurate transcriptions of audio and video files using domain-specific speech recognition technology. The application provides various features to transcribe, edit, and export audio content in different formats. With state-of-the-art deep neural network models, SpeechText.AI achieves close to human accuracy in converting audio to text. The tool is widely used for transcription of interviews, medical data, conference calls, podcasts, and more, catering to various industries such as finance, healthcare, legal, and HR.
Transgate
Transgate is an AI-powered speech-to-text conversion tool that allows users to convert audio/video files to text with high accuracy and efficiency. It offers a pay-as-you-go model, supports over 50 languages, and guarantees 98%+ accuracy. Transgate is designed to boost productivity by minimizing costs and eliminating manual transcription tasks, catering to industries like AI/ML, medical, legal, education, consulting, and market research.
Lingvanex
Lingvanex is a cloud-based machine translation and speech recognition platform that provides businesses with a variety of tools to translate text, documents, and speech in over 100 languages. The platform is powered by artificial intelligence (AI) and machine learning (ML) technologies, which enable it to deliver high-quality translations that are both accurate and fluent. Lingvanex also offers a variety of features that make it easy for businesses to integrate translation and speech recognition into their workflows, including APIs, SDKs, and plugins for popular programming languages and platforms.
Podcastle
Podcastle is an all-in-one podcasting software that empowers creators of all backgrounds and experience levels with an intuitive, AI-powered platform. It offers a wide range of features, including a recording studio, audio editor, video editor, AI-generated voices, and hosting hub, making it easy to create, edit, and publish high-quality podcasts and videos. Podcastle is designed to be user-friendly and accessible, with no prior experience or technical expertise required.
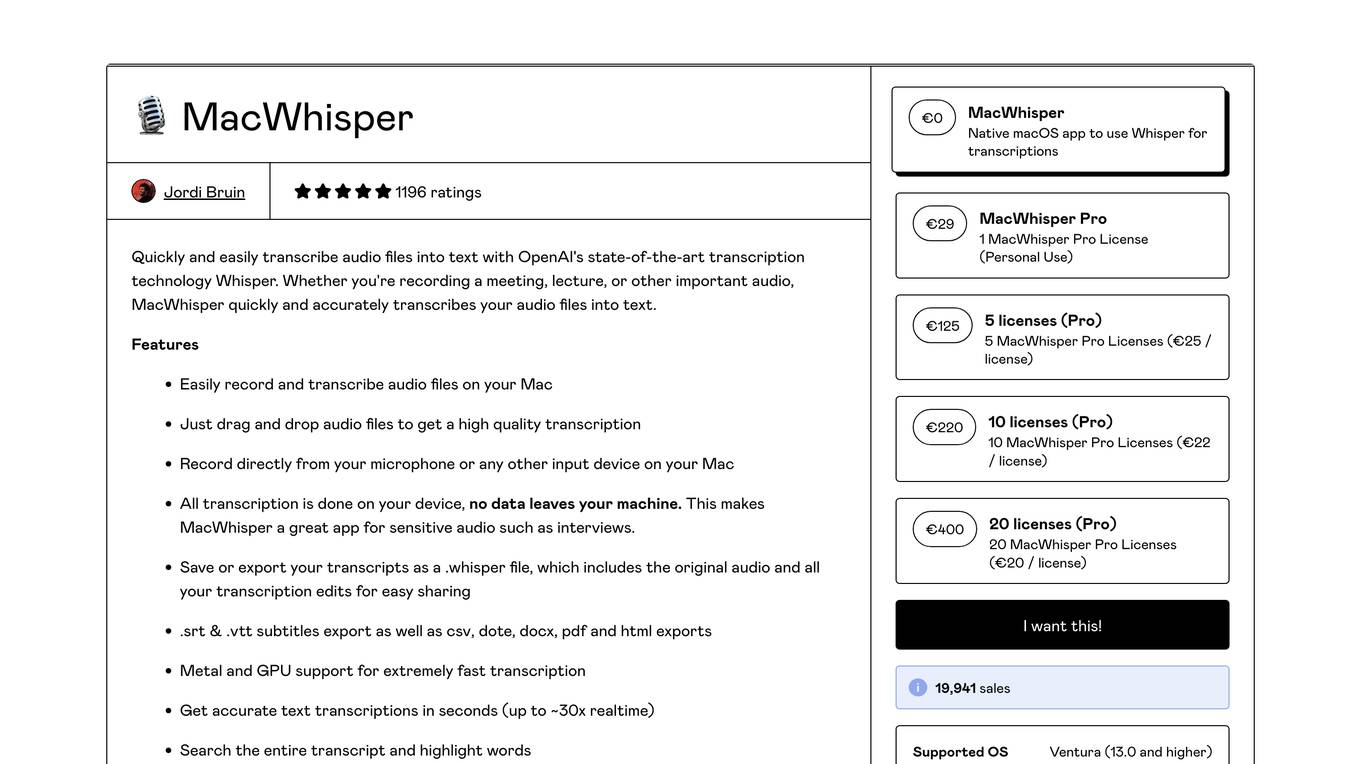
MacWhisper
MacWhisper is a native macOS application that utilizes OpenAI's Whisper technology for transcribing audio files into text. It offers a user-friendly interface for recording, transcribing, and editing audio, making it suitable for various use cases such as transcribing meetings, lectures, interviews, and podcasts. The application is designed to protect user privacy by performing all transcriptions locally on the device, ensuring that no data leaves the user's machine.
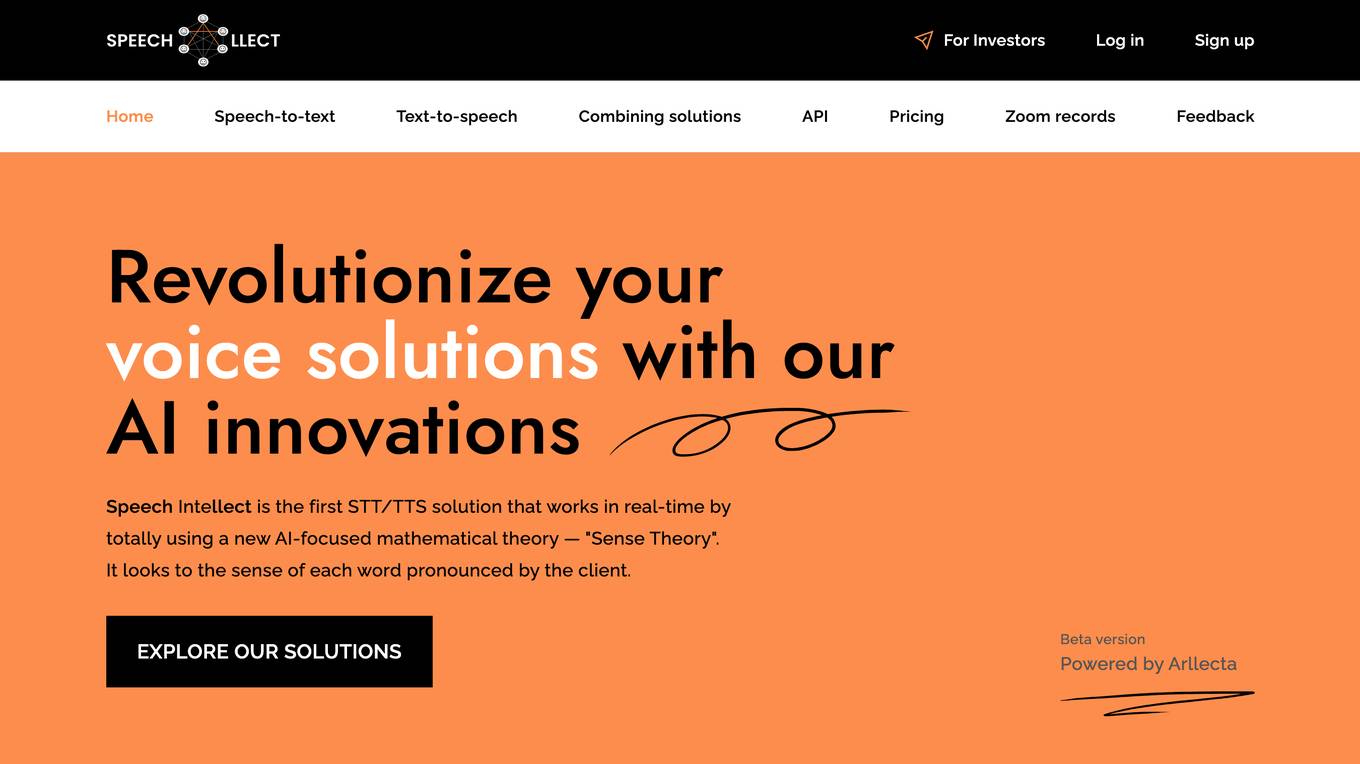
Speech Intellect
Speech Intellect is an AI-powered speech-to-text and text-to-speech solution that provides real-time transcription and voice synthesis with emotional analysis. It utilizes a proprietary "Sense Theory" algorithm to capture the meaning and tone of speech, enabling businesses to automate tasks, improve customer interactions, and create personalized experiences.
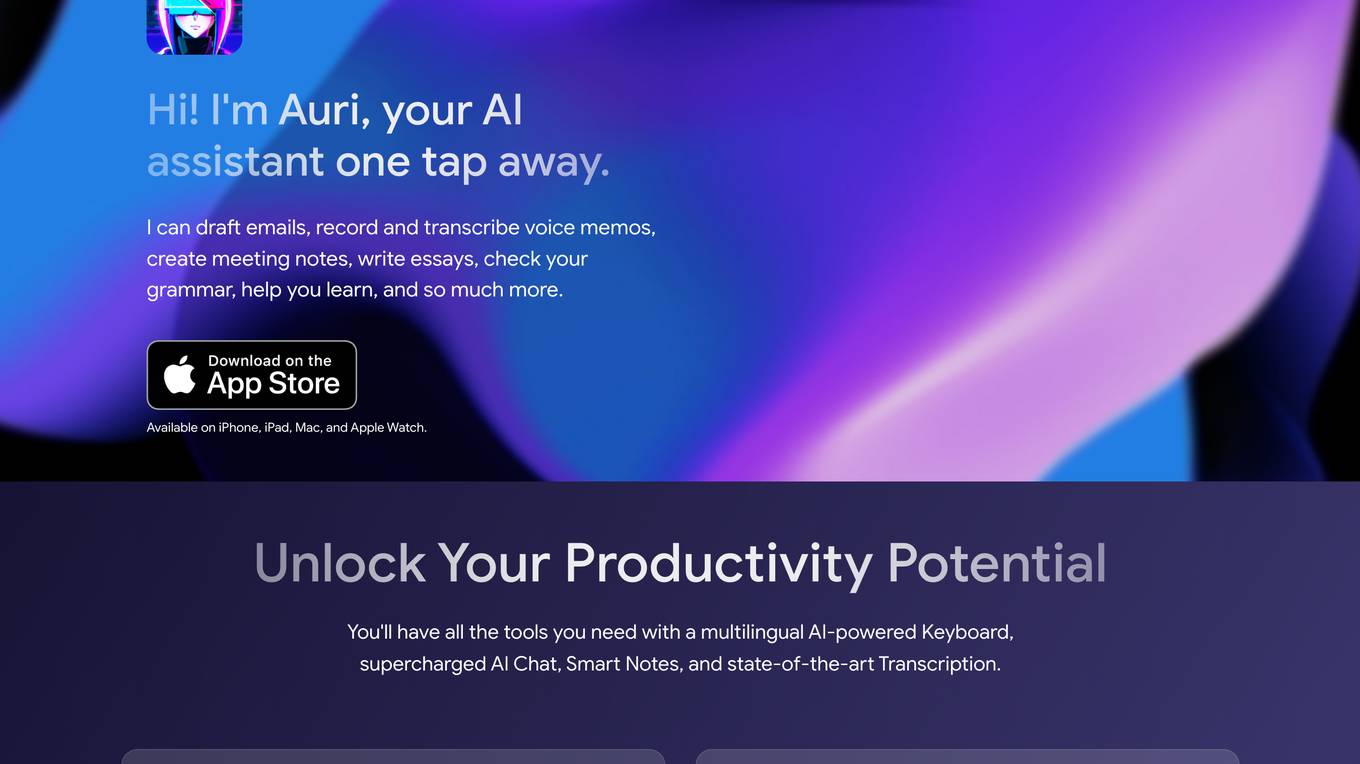
Auri
Auri is an AI assistant that offers a range of writing, communication, and productivity tools. It includes an AI-powered keyboard with features like grammar checking, translation, and paraphrasing, as well as an AI chat, voice recorder and transcriber, and smart notes. Auri is available on iPhone, iPad, Mac, and Apple Watch.
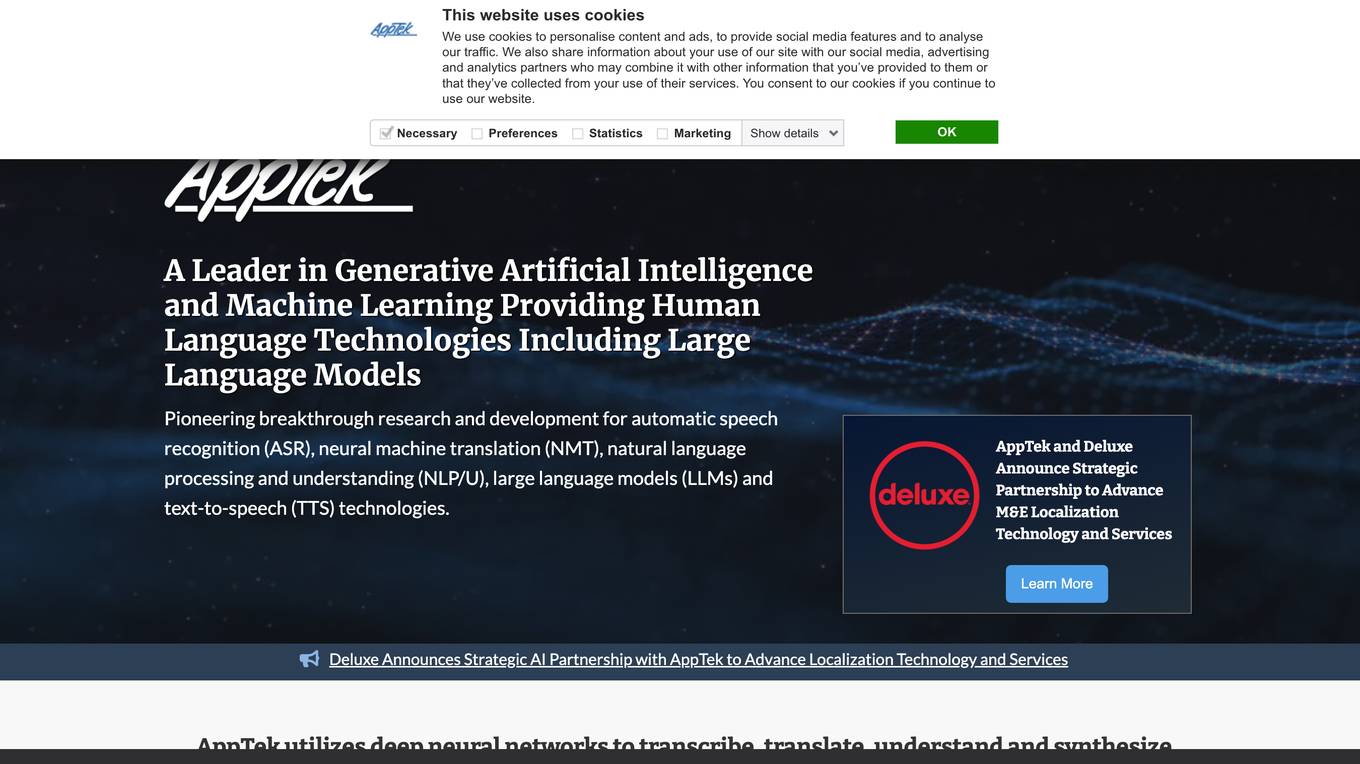
AppTek
AppTek is a global leader in artificial intelligence (AI) and machine learning (ML) technologies for automatic speech recognition (ASR), neural machine translation (NMT), natural language processing/understanding (NLP/U) and text-to-speech (TTS) technologies. The AppTek platform delivers industry-leading solutions for organizations across a breadth of global markets such as media and entertainment, call centers, government, enterprise business, and more. Built by scientists and research engineers who are recognized among the best in the world, AppTek’s solutions cover a wide array of languages/ dialects, channels, domains and demographics.
0 - Open Source AI Tools
20 - OpenAI Gpts
SpeechGPT User Guide
A guide for using SpeechGPT, focusing on its features, setup, and usage.
Speech Parody
Create speech transcript parodies. Copyright (C) 2023, Sourceduty - All Rights Reserved.



User Interview Product Manager
Transforms user interview transcripts into a list of tasks [Asana compatible CSV file]. Send feedback to https://x.com/kireet_agrawal

DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages
Interview GPT
Automated interviews. To get started, type or say "Let's begin". When you ask the GPT to end the interview it will give you a transcript and summary of your conversation. This is a great way of getting thoughts out of your head and onto "paper". Have fun!

Athena Notes AI
I convert transcripts into detailed meeting notes with insights, summaries, and action items, plus a downloadable MS Word file.


LaTeX Picture & Document Transcriber
Convert into usable LaTeX code any pictures of your handwritten notes, documents in any format. Start by uploading what you need to convert.

Journal Recognizer OCR
Optimized OCR for Handwritten Notebooks, up to 10 image transcript copy w/1-click. No text prompt necessary. Reads journals, reports, notes. All handwriting transcribed verbatim, then text summarized, graphic image features described. Ask to change any behavior.
