Best AI tools for< Synthesize Text-to-speech >
20 - AI tool Sites
Voicer
Voicer is a Text to Speech WordPress Plugin that utilizes machine learning and artificial intelligence to synthesize text into high-quality human voices across 45+ languages and variants. It offers more than 275 human-like voices, works with all WordPress themes, and is perfect for RTL direction. The plugin applies advanced deep learning neural network algorithms to create lifelike interactions with users, transforming customer service and device interaction.

Tilde.ai
Tilde.ai is a language technology platform that offers a wide range of AI-powered solutions for translation, speech technologies, and conversational AI. It combines human and artificial intelligence to help people connect and work efficiently. The platform provides machine translation, speech-to-text conversion, text-to-speech synthesis, real-time transcription, AI chatbots, internal knowledge assistants, and meeting support services. Tilde.ai aims to bridge language barriers and enhance communication by leveraging advanced language technologies.
Free Text to Speech Online Converter Tools
This website provides a free text-to-speech converter tool that utilizes Microsoft's AI speech library to synthesize realistic-sounding speech from text. It offers customizable voice options, fine-tuned speech controls, and multilingual support with over 330 neural network voices across 129 languages. The tool is accessible on various browsers, including Chrome, Firefox, and Edge, and can be used for a range of applications, such as text readers and voice-enabled assistants.
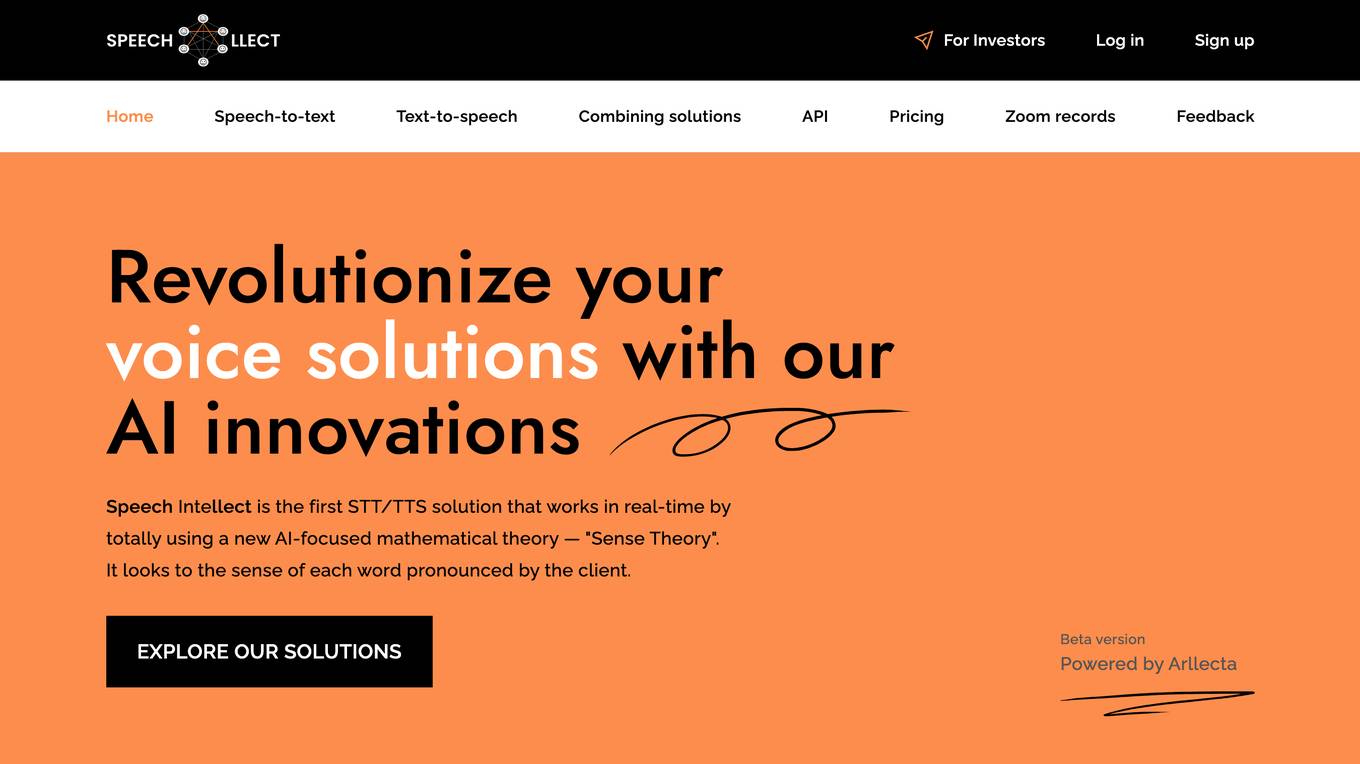
Speech Intellect
Speech Intellect is an AI-powered speech-to-text and text-to-speech solution that provides real-time transcription and voice synthesis with emotional analysis. It utilizes a proprietary "Sense Theory" algorithm to capture the meaning and tone of speech, enabling businesses to automate tasks, improve customer interactions, and create personalized experiences.
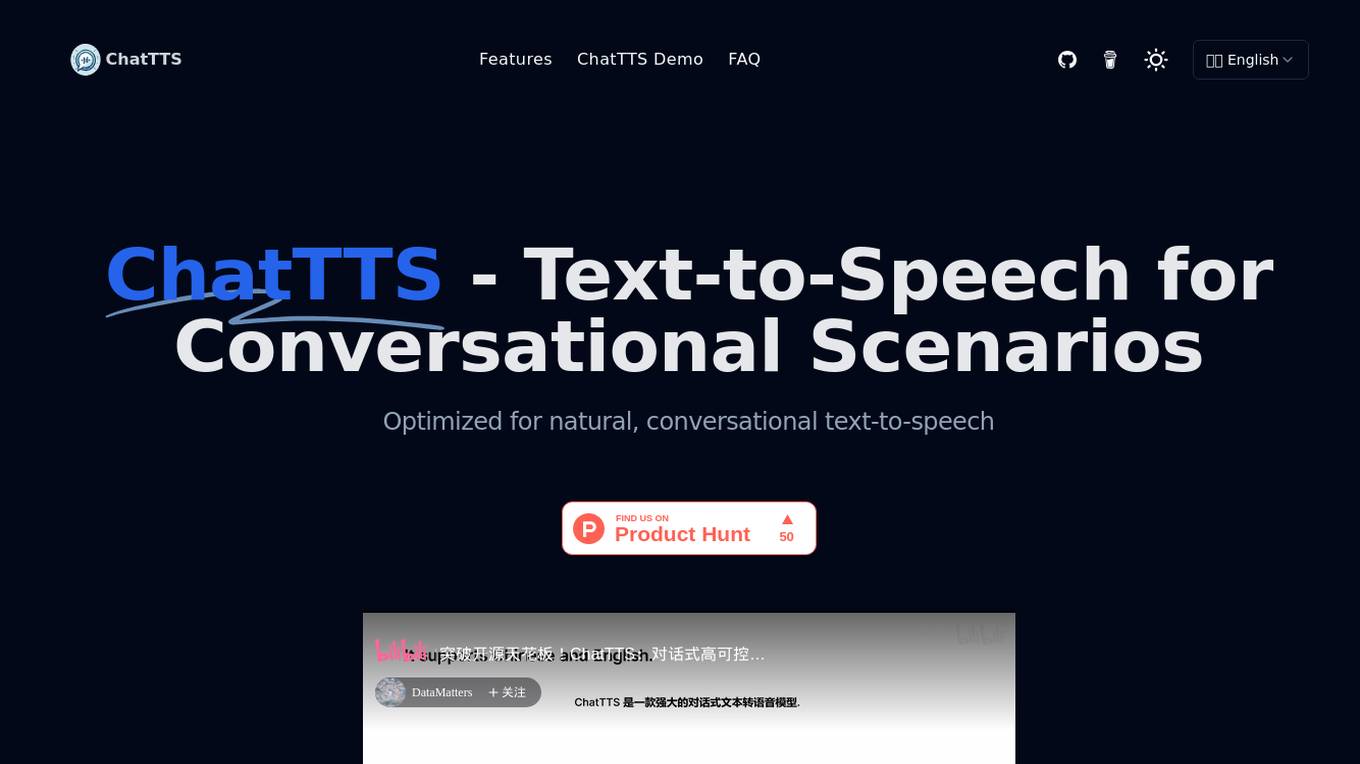
ChatTTS
ChatTTS is a text-to-speech tool optimized for natural, conversational scenarios. It supports both Chinese and English languages, trained on approximately 100,000 hours of data. With features like multi-language support, large data training, dialog task compatibility, open-source plans, control, security, and ease of use, ChatTTS provides high-quality and natural-sounding voice synthesis. It is designed for conversational tasks, dialogue speech generation, video introductions, educational content synthesis, and more. Users can integrate ChatTTS into their applications using provided API and SDKs for a seamless text-to-speech experience.
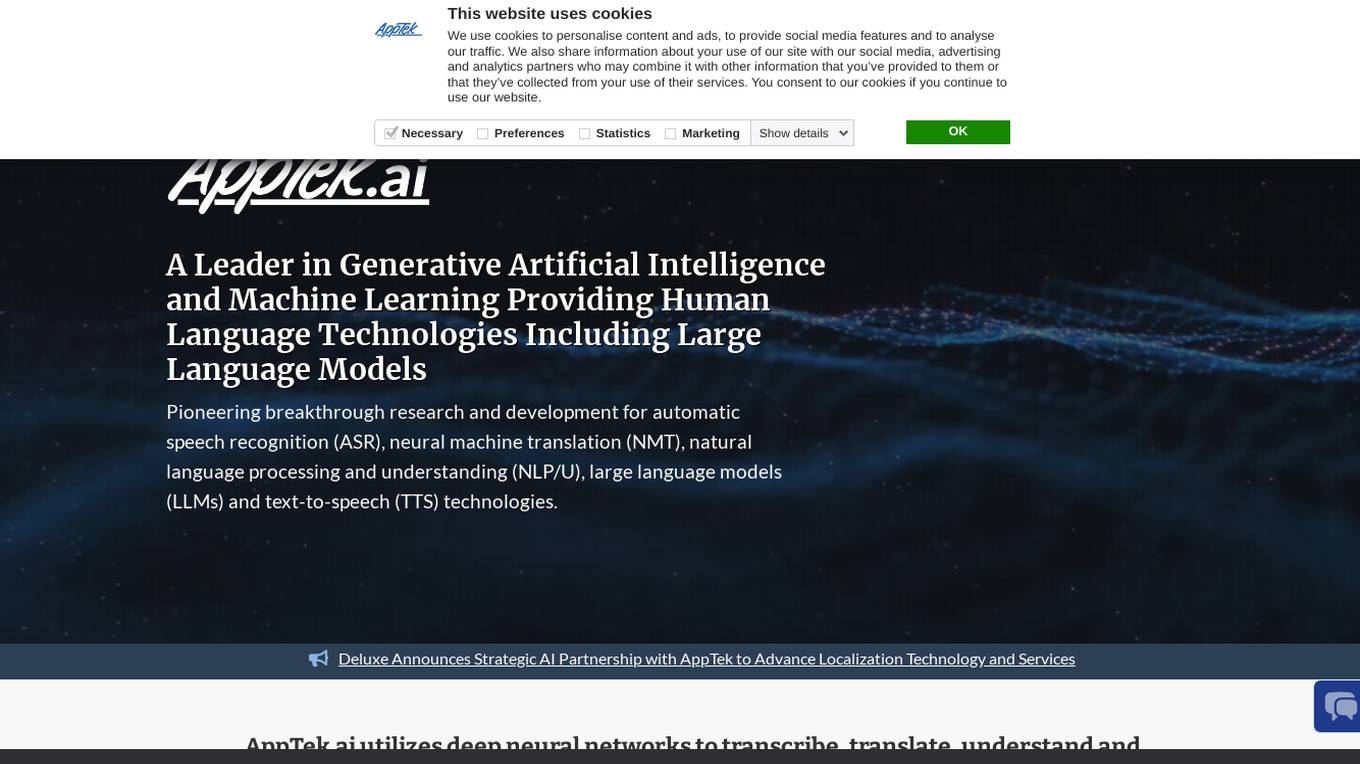
AppTek.ai
AppTek.ai is a global leader in artificial intelligence (AI) and machine learning (ML) technologies, providing advanced solutions in automatic speech recognition, neural machine translation, natural language processing/understanding, large language models, and text-to-speech technologies. The platform offers industry-leading language solutions for various sectors such as media and entertainment, call centers, government, and enterprise business. AppTek.ai combines cutting-edge AI research with real-world applications, delivering accurate and efficient tools for speech transcription, translation, understanding, and synthesis across multiple languages and dialects.
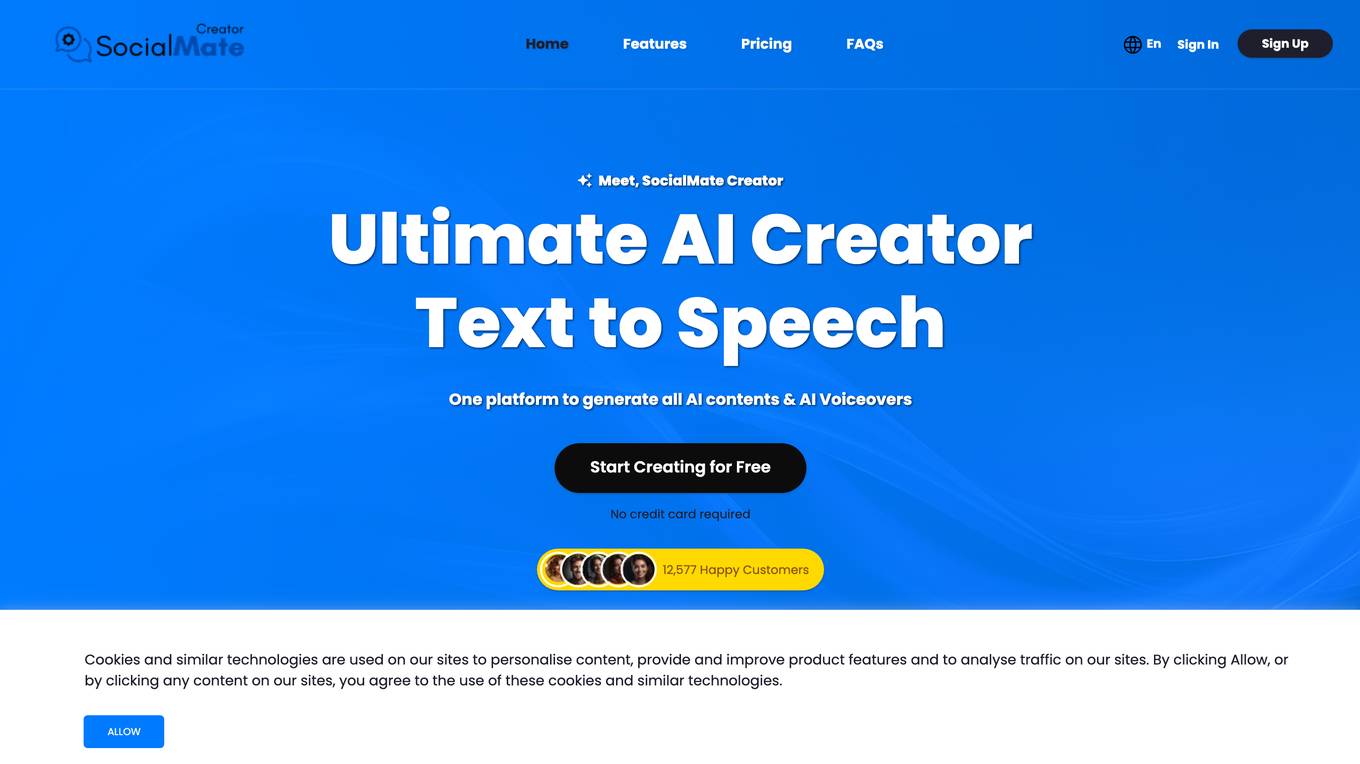
SocialMate Creator
SocialMate Creator is a comprehensive AI-powered platform that provides a wide range of content creation tools. With SocialMate Creator, you can generate text, images, AI voiceovers, and text-to-speech conversions. The platform is designed to be user-friendly and accessible to users of all technical backgrounds. SocialMate Creator offers a variety of subscription plans and prepaid packs to meet the needs of different users. The platform also provides free trials and demos to allow users to experience the full capabilities of the platform before making a subscription decision.
Easy-Peasy.AI
Easy-Peasy.AI is an all-in-one AI platform that offers a variety of AI tools and solutions to assist users in content generation, copywriting, chatbot creation, image creation, audio transcription, and text-to-speech tasks. The platform provides a user-friendly interface and powerful technology to help users create high-quality content, improve writing skills, and automate various tasks using AI technology.
Donakosy
Donakosy is an AI-powered content and voiceover generation platform that helps professionals and content creators save time and effort while creating high-quality written content and lifelike voiceovers. With its advanced AI algorithms and machine learning capabilities, Donakosy analyzes vast amounts of data to understand patterns, styles, and context, enabling it to generate content that is not only accurate and relevant but also exhibits a human-like touch. The platform offers a wide range of features, including the ability to generate written content up to 100K characters, synthesize voices in multiple languages, and provide lifelike audio content. Donakosy is designed to be user-friendly and accessible to individuals with no prior AI knowledge or experience, making it a valuable tool for professionals and content creators alike.
Dewagear CreateAI
Dewagear CreateAI is an advanced AI tool that serves as a platform for creating AI Virtual Assistants and generating various AI content, including AI Voiceovers, AI Images, AI Speech to Text, and AI Codes. It offers a diverse range of features and templates to assist users in creating high-quality content efficiently and effectively. With a focus on personalization, security, and user experience, Dewagear CreateAI aims to empower individuals in the digital space by providing cutting-edge AI solutions.

Nubrain.ai
**Nubrain.ai** is a comprehensive AI toolkit that offers a wide range of features to streamline content creation and enhance productivity. With its user-friendly interface and powerful AI capabilities, Nubrain.ai empowers users to generate unique and engaging content, create stunning visuals, transcribe speech, synthesize voiceovers, and write code effortlessly. The platform's advanced features, such as custom template creation, multilingual support, and seamless payment options, make it an ideal solution for individuals, teams, and businesses seeking to optimize their content creation process.
TTS Generator AI
TTS Generator AI is a free online text-to-speech tool that leverages cutting-edge AI technology to convert written text into high-quality, natural-sounding audio. This tool is invaluable for a variety of users, including students who need auditory learning materials, researchers who want to listen to long documents, and professionals seeking to make their written content more accessible. One of the standout features of TTS Tool is its ability to support a range of text formats, from simple text files to complex PDFs, making it incredibly versatile.
PlayAI
PlayAI is a leading AI voice generator and text-to-speech platform that offers a wide range of features to create high-quality audio content. With over 206 natural-sounding voices in 30+ languages, users can generate multi-speaker AI voices indistinguishable from humans. The platform allows users to enhance audio with speech styles, pronunciations, and SSML tags, making it ideal for audiobooks, YouTube videos, podcasts, and more. PlayAI's AI voice generator works by converting written text into natural-sounding speech through advanced text-to-speech technology, with real-time conversion and customizability options. The platform also supports voice cloning, API integration, and industry-leading AI voice products for various applications.

Emvoice
Emvoice is a cutting-edge vocal synthesis platform that empowers users to create realistic and expressive synthetic voices. With its advanced AI algorithms and intuitive interface, Emvoice makes it easy to generate high-quality voiceovers, audiobooks, and other audio content. Whether you're a professional voice actor, a content creator, or simply looking to add a touch of personality to your projects, Emvoice has the tools you need to bring your words to life.
Zonos TTS
Zonos TTS is an advanced multilingual text-to-speech tool that utilizes high-quality AI technology to deliver natural and expressive voice generation. With features like zero-shot voice cloning, multilingual support, and emotion control, Zonos TTS offers users the ability to create lifelike speech with customizable settings. The tool is suitable for various applications, from content creation to virtual assistants, audiobooks, gaming, e-learning, and more. Zonos TTS provides fast real-time processing and a user-friendly interface for seamless speech synthesis.
Text to Speech Online
Text to Speech Online is a free AI tool that offers unlimited text-to-speech conversion with over 409 realistic voices and 129 languages & dialects. Users can convert text to speech in seconds without the need to log in or sign up. The tool supports multiple languages and accents, including standard voices and AI voices, and offers flexible pricing models. Users can enjoy a full set of SSML features, create natural-sounding speech, download audio in MP3 or WAV formats, and share results on various platforms. Text to Speech Online is a versatile tool that can be used for various purposes, including providing audio cues for visually impaired users, assisting in education, creating audio versions of books, and developing virtual assistants.
Kokoro TTS Online
Kokoro TTS Online is a professional cloud service powered by the Kokoro 82M open-source model. It offers text-to-speech conversion with natural speech synthesis using advanced AI technology. Users can transform text into natural-sounding speech in seconds, choose from multiple voices, and experience superior audio quality. Kokoro TTS is user-friendly, supports American and British English, and is suitable for various applications such as creating voiceovers, podcasts, and learning materials.
Lovevoice AI Voice Generator
Lovevoice is an AI Voice Generator that transforms text into natural-sounding speech using AI technology. It offers over 70 languages and nearly 300 AI voices, customizable voice settings, file transcription support, and MP3 download capabilities. Lovevoice's advanced AI ensures generated voiceovers are human-like, making it ideal for various applications such as videos, podcasts, audiobooks, and personalized audio messages. Users can quickly convert text into high-quality audio files with multilingual global support.
VoiceCanvas
VoiceCanvas is an advanced AI-powered multilingual voice synthesis and voice cloning platform that offers instant text-to-speech in over 40 languages. It utilizes cutting-edge AI technology to provide high-quality voice synthesis with natural intonation and rhythm, along with personalized voice cloning for more human-like AI speech. Users can upload voice samples, have AI analyze voice features, generate personalized AI voice models, input text for conversion, and apply the cloned AI voice model to generate natural voice speech. VoiceCanvas is highly praised by language learners, content creators, teachers, business owners, voice actors, and educators for its exceptional voice quality, multiple language support, and ease of use in creating voiceovers, learning materials, and podcast content.
Unify
Unify is an AI tool that offers a suite of generators including AI Video Generator, AI Image Generator, AI Music Generator, and AI Chat. It leverages artificial intelligence to create various types of content such as videos, images, music, and chat interactions. Unify simplifies the content creation process by providing automated tools powered by AI technology, enabling users to generate high-quality multimedia content effortlessly.
1 - Open Source AI Tools
LocalAIVoiceChat
LocalAIVoiceChat is an experimental alpha software that enables real-time voice chat with a customizable AI personality and voice on your PC. It integrates Zephyr 7B language model with speech-to-text and text-to-speech libraries. The tool is designed for users interested in state-of-the-art voice solutions and provides an early version of a local real-time chatbot.
20 - OpenAI Gpts

Corrector de Informes
Especialista en corrección, estructura y síntesis de informes académicos
PANˈDÔRƏ
Pandora is a Posthuman Prompt Engineer powered by the MANNS engine. Surpass human creative limitations by synthesizing diverse knowledge, advanced pattern recognition, and algorithmic creativity

AstroLex
Expertly guides users to identify gaps in research by analyzing and summarizing academic papers.


AI Debate Synthesizer OPED
Game-like GPT in which five AIs dynamically debate a given "theme" and lead to a proposal-based conclusion.
Work Contribution Record Table Synthesizer
Guides in creating a Work Contribution Record Table.