Best AI tools for< Support Gpus >
20 - AI tool Sites
Lamini
Lamini is an enterprise-level LLM platform that offers precise recall with Memory Tuning, enabling teams to achieve over 95% accuracy even with large amounts of specific data. It guarantees JSON output and delivers massive throughput for inference. Lamini is designed to be deployed anywhere, including air-gapped environments, and supports training and inference on Nvidia or AMD GPUs. The platform is known for its factual LLMs and reengineered decoder that ensures 100% schema accuracy in the JSON output.
404 Error Page
The website displays a 404 error message indicating that the deployment cannot be found. It provides a code and an ID for reference, along with a suggestion to check the documentation for more information and troubleshooting.
Stablematic
Stablematic is a web-based platform that allows users to run Stable Diffusion and other machine learning models without the need for local setup or hardware limitations. It provides a user-friendly interface, pre-installed plugins, and dedicated GPU resources for a seamless and efficient workflow. Users can generate images and videos from text prompts, merge multiple models, train custom models, and access a range of pre-trained models, including Dreambooth and CivitAi models. Stablematic also offers API access for developers and dedicated support for users to explore and utilize the capabilities of Stable Diffusion and other machine learning models.
Nebius AI
Nebius AI is an AI-centric cloud platform designed to handle intensive workloads efficiently. It offers a range of advanced features to support various AI applications and projects. The platform ensures high performance and security for users, enabling them to leverage AI technology effectively in their work. With Nebius AI, users can access cutting-edge AI tools and resources to enhance their projects and streamline their workflows.
TextSynth
TextSynth is an AI tool that provides access to large language models such as Mistral, Llama, Stable Diffusion, Whisper for text-to-image, text-to-speech, and speech-to-text capabilities via a REST API and a playground. It employs custom inference code for faster inference on standard GPUs and CPUs. Founded in 2020, TextSynth was among the first to offer access to the GPT-2 language model. The service is free with rate limitations, but users can opt for unlimited access by paying a small fee per request. All servers are located in France.
Anycores
Anycores is an AI tool designed to optimize the performance of deep neural networks and reduce the cost of running AI models in the cloud. It offers a platform that provides automated solutions for tuning and inference consultation, optimized networks zoo, and platform for reducing AI model cost. Anycores focuses on faster execution, reducing inference time over 10x times, and footprint reduction during model deployment. It is device agnostic, supporting Nvidia, AMD GPUs, Intel, ARM, AMD CPUs, servers, and edge devices. The tool aims to provide highly optimized, low footprint networks tailored to specific deployment scenarios.
GPUX
GPUX is a cloud platform that provides access to GPUs for running AI workloads. It offers a variety of features to make it easy to deploy and run AI models, including a user-friendly interface, pre-built templates, and support for a variety of programming languages. GPUX is also committed to providing a sustainable and ethical platform, and it has partnered with organizations such as the Climate Leadership Council to reduce its carbon footprint.

PoplarML
PoplarML is a platform that enables the deployment of production-ready, scalable ML systems with minimal engineering effort. It offers one-click deploys, real-time inference, and framework agnostic support. With PoplarML, users can seamlessly deploy ML models using a CLI tool to a fleet of GPUs and invoke their models through a REST API endpoint. The platform supports Tensorflow, Pytorch, and JAX models.

vLLM
vLLM is a fast and easy-to-use library for LLM inference and serving. It offers state-of-the-art serving throughput, efficient management of attention key and value memory, continuous batching of incoming requests, fast model execution with CUDA/HIP graph, and various decoding algorithms. The tool is flexible with seamless integration with popular HuggingFace models, high-throughput serving, tensor parallelism support, and streaming outputs. It supports NVIDIA GPUs and AMD GPUs, Prefix caching, and Multi-lora. vLLM is designed to provide fast and efficient LLM serving for everyone.

GrapixAI
GrapixAI is a leading provider of low-cost cloud GPU rental services and AI server solutions. The company's focus on flexibility, scalability, and cutting-edge technology enables a variety of AI applications in both local and cloud environments. GrapixAI offers the lowest prices for on-demand GPUs such as RTX4090, RTX 3090, RTX A6000, RTX A5000, and A40. The platform provides Docker-based container ecosystem for quick software setup, powerful GPU search console, customizable pricing options, various security levels, GUI and CLI interfaces, real-time bidding system, and personalized customer support.

Moreh
Moreh is an AI platform that aims to make hyperscale AI infrastructure more accessible for scaling any AI model and application. It provides a full-stack infrastructure software from PyTorch to GPUs for the LLM era, enabling users to train large language models efficiently and effectively.
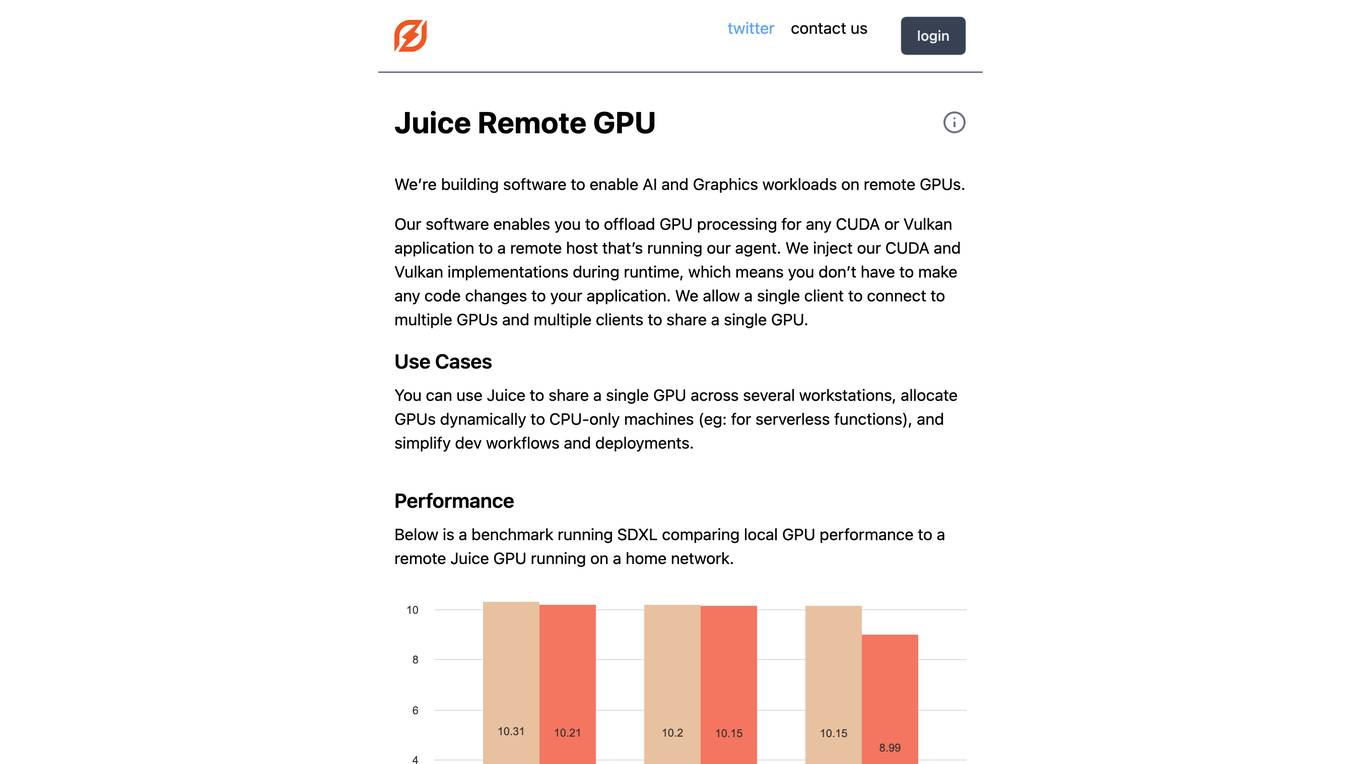
Juice Remote GPU
Juice Remote GPU is a software that enables AI and Graphics workloads on remote GPUs. It allows users to offload GPU processing for any CUDA or Vulkan application to a remote host running the Juice agent. The software injects CUDA and Vulkan implementations during runtime, eliminating the need for code changes in the application. Juice supports multiple clients connecting to multiple GPUs and multiple clients sharing a single GPU. It is useful for sharing a single GPU across multiple workstations, allocating GPUs dynamically to CPU-only machines, and simplifying development workflows and deployments. Juice Remote GPU performs within 5% of a local GPU when running in the same datacenter. It supports various APIs, including CUDA, Vulkan, DirectX, and OpenGL, and is compatible with PyTorch and TensorFlow. The team behind Juice Remote GPU consists of engineers from Meta, Intel, and the gaming industry.
VeroCloud
VeroCloud is a platform offering tailored solutions for AI, HPC, and scalable growth. It provides cost-effective cloud solutions with guaranteed uptime, performance efficiency, and cost-saving models. Users can deploy HPC workloads seamlessly, configure environments as needed, and access optimized environments for GPU Cloud, HPC Compute, and Tally on Cloud. VeroCloud supports globally distributed endpoints, public and private image repos, and deployment of containers on secure cloud. The platform also allows users to create and customize templates for seamless deployment across computing resources.
Modular
Modular is a fast, scalable Gen AI inference platform that offers a comprehensive suite of tools and resources for AI development and deployment. It provides solutions for AI model development, deployment options, AI inference, research, and resources like documentation, models, tutorials, and step-by-step guides. Modular supports GPU and CPU performance, intelligent scaling to any cluster, and offers deployment options for various editions. The platform enables users to build agent workflows, utilize AI retrieval and controlled generation, develop chatbots, engage in code generation, and improve resource utilization through batch processing.
TractoAI
TractoAI is an advanced AI platform that offers deep learning solutions for various industries. It provides Batch Inference with no rate limits, DeepSeek offline inference, and helps in training open source AI models. TractoAI simplifies training infrastructure setup, accelerates workflows with GPUs, and automates deployment and scaling for tasks like ML training and big data processing. The platform supports fine-tuning models, sandboxed code execution, and building custom AI models with distributed training launcher. It is developer-friendly, scalable, and efficient, offering a solution library and expert guidance for AI projects.
Support AI
Support AI is a custom AI chatbot application powered by ChatGPT that allows website owners to create personalized chatbots to provide instant answers to customers, capture leads, and enhance customer support. With Support AI, users can easily integrate AI chatbots on their websites, train them with specific content, and customize their behavior and responses. The application offers features such as capturing leads, providing accurate answers, handling bookings, collecting feedback, and offering product recommendations. Users can choose from different pricing plans based on their message volume and training content needs.
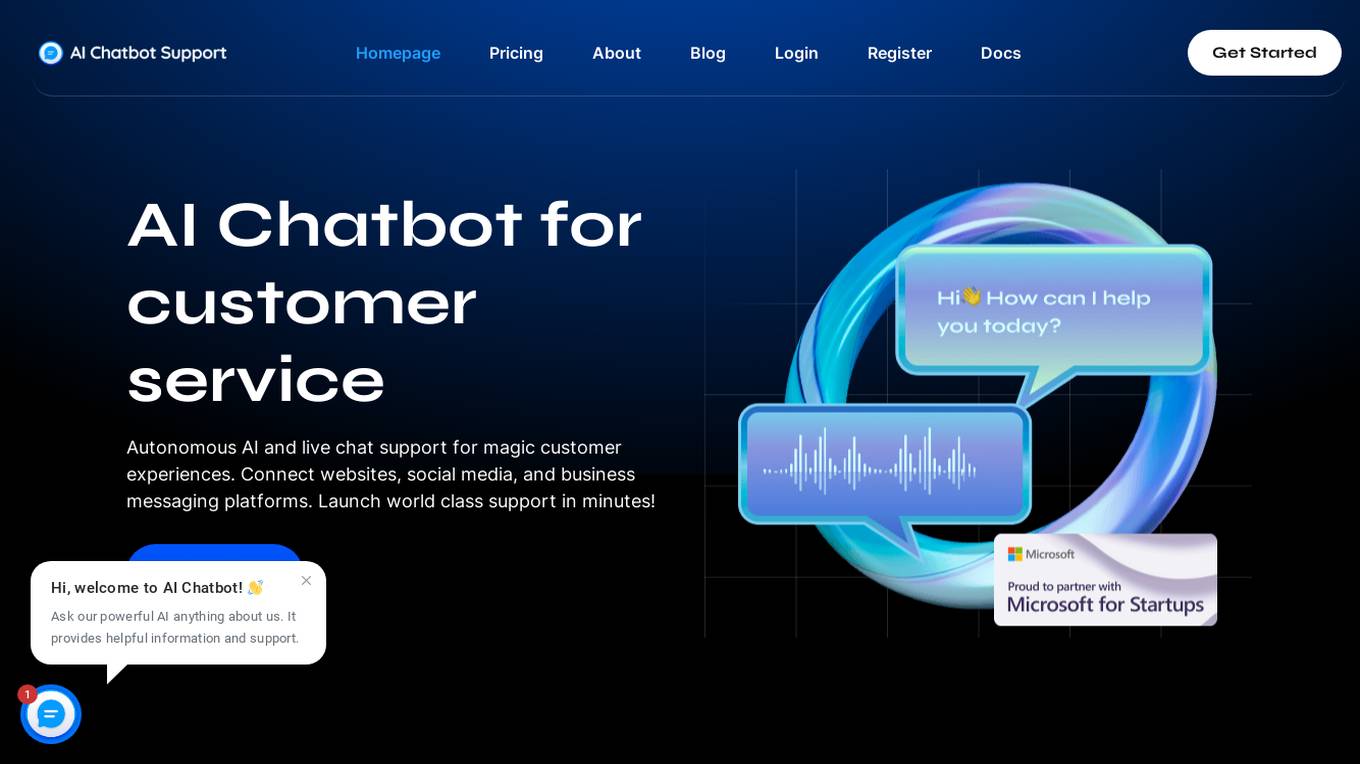
AI Chatbot Support
AI Chatbot Support is an autonomous AI and live chat customer service application that provides magic customer experiences by connecting websites, social media, and business messaging platforms. It offers multi-platform support, auto language translation, rich messaging features, smart-reply suggestions, and platform-agnostic AI assistance. The application is designed to enhance customer engagement, satisfaction, and retention across digital platforms through personalized experiences and swift query resolutions.
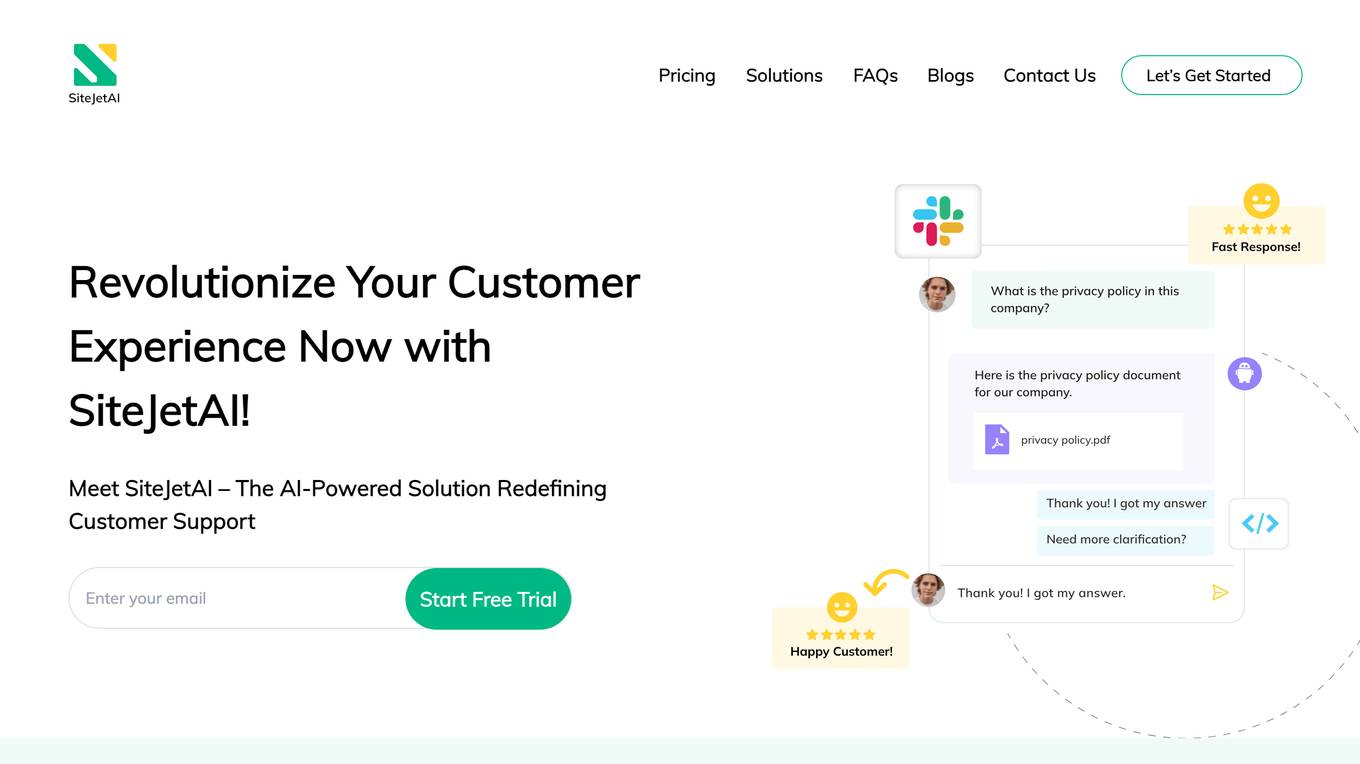
AI-Powered Customer Support Chatbot
This AI-powered customer support chatbot is a cutting-edge tool that transforms customer engagement and drives revenue growth. It leverages advanced natural language processing (NLP) and machine learning algorithms to provide personalized, real-time support to customers across multiple channels. By automating routine inquiries, resolving complex issues, and offering proactive assistance, this chatbot empowers businesses to enhance customer satisfaction, increase conversion rates, and optimize their support operations.

Anthropic
Anthropic is a research and deployment company founded in 2021 by former OpenAI researchers Dario Amodei, Daniela Amodei, and Geoffrey Irving. The company is developing large language models, including Claude, a multimodal AI model that can perform a variety of language-related tasks, such as answering questions, generating text, and translating languages.
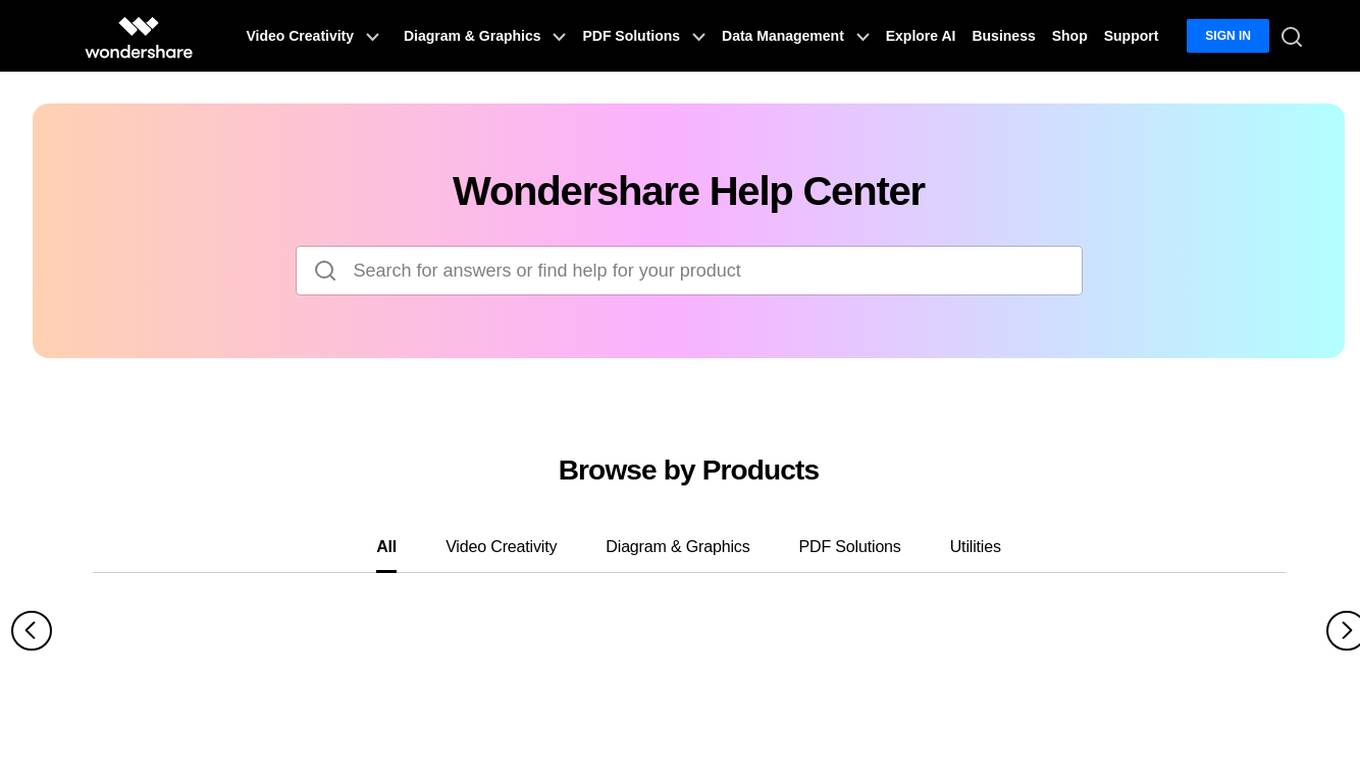
Wondershare Help Center
Wondershare Help Center provides comprehensive support for Wondershare products, including video editing, video creation, diagramming, PDF solutions, and data management. It offers a wide range of resources such as tutorials, FAQs, troubleshooting guides, and access to customer support.
0 - Open Source AI Tools
20 - OpenAI Gpts
Ekko Support Specialist
How to be a master of surprise plays and unconventional strategies in the bot lane as a support role.
Backloger.ai -Support Log Analyzer and Summary
Drop your Support Log Here, Allowing it to automatically generate concise summaries reporting to the tech team.
Tech Support Advisor
From setting up a printer to troubleshooting a device, I’m here to help you step-by-step.

Z Support
Expert in Nissan 370Z & 350Z modifications, offering tailored vehicle upgrade advice.

Emotional Support Copywriter
A creative copywriter you can hang out with and who won't do their timesheets either.
PCT 365 Support Bot
Microsoft 365 support agent, redirects admin-level requests to PCT Support.
Technischer Support Bot
Ein Bot, der grundlegende technische Unterstützung und Fehlerbehebung für gängige Software und Hardware bietet.

Military Support
Supportive and informative guide on military, veterans, and military assistance.
Dror Globerman's GPT Tech Support
Your go-to assistant for everyday tech support and guidance.
Customer Support Assistant
Expert in crafting empathetic, professional emails for customer support.