Best AI tools for< Speech >
20 - AI tool Sites

Speech Studio
Speech Studio is a cloud-based speech-to-text and text-to-speech platform that enables developers to add speech capabilities to their applications. With Speech Studio, developers can easily transcribe audio and video files, generate synthetic speech, and build custom speech models. Speech Studio is a powerful tool that can be used to improve the accessibility, efficiency, and user experience of any application.
SpeechText.AI
SpeechText.AI is a powerful artificial intelligence software for speech to text conversion and audio transcription. It offers accurate transcriptions of audio and video files using domain-specific speech recognition technology. The application provides various features to transcribe, edit, and export audio content in different formats. With state-of-the-art deep neural network models, SpeechText.AI achieves close to human accuracy in converting audio to text. The tool is widely used for transcription of interviews, medical data, conference calls, podcasts, and more, catering to various industries such as finance, healthcare, legal, and HR.
Better Speech Online Speech Therapy
Better Speech Online Speech Therapy is an AI-driven platform that offers convenient, affordable, and effective speech therapy services for children and adults. The platform utilizes cutting-edge artificial intelligence to provide personalized practices and make speech therapy more engaging, convenient, and affordable. With a team of 250+ licensed and experienced therapists, Better Speech aims to help individuals of all ages improve their communication skills from the comfort of their homes. The platform offers unlimited speech practices between sessions, immediate availability, easy scheduling, and effective results comparable to in-person therapy.
SpeechFlow
SpeechFlow is a powerful speech-to-text API that transcribes audio and video files into text with high accuracy. It supports 14 languages and offers features such as punctuation, easy deployment, scalability, and fast processing. SpeechFlow is ideal for businesses and individuals who need accurate and timely transcription services.
Speech Intellect
Speech Intellect is an AI-powered speech-to-text and text-to-speech solution that provides real-time transcription and voice synthesis with emotional analysis. It utilizes a proprietary "Sense Theory" algorithm to capture the meaning and tone of speech, enabling businesses to automate tasks, improve customer interactions, and create personalized experiences.

SpeechForms™
SpeechForms™ is an Early Childhood Support Initiative in New York City that helps families access Early Intervention Program services for children ages 0–3. The platform provides information about developmental milestones, evaluation processes, and available services, along with practical tips for families. SpeechForms™ offers support for families facing speech and development delays, guiding them towards the right path and connecting them quickly to necessary services. The platform also assists families in accessing private speech therapy services for more flexibility and timely support.
SpeechGeneratorAI
SpeechGeneratorAI is a free AI-powered speech generator that helps users create personalized speeches for various occasions in seconds. Users can select the type of speech, input key points, and choose the tone and style to generate a well-structured and engaging speech. The tool is user-friendly, offers instant speech generation, and provides full support to ensure users have more time to focus on delivery rather than drafting.
Speechify
Speechify is the #1 rated AI text to speech app in its category with over 250,000 5 star reviews. It is available as a Chrome extension, iOS app, Android app, Microsoft Edge Add-on, and web app. Speechify can convert any text into natural-sounding AI voice in over 50 languages and accents. It can also read aloud any PDF, doc, or web page. Speechify is used by students, professionals, readers, and those who struggle to read. It can help with reading comprehension, focus, and retention. Speechify is also a great tool for people with disabilities such as dyslexia, ADHD, and dry eyes.
SpeechGen.io
SpeechGen.io is a realistic text-to-speech converter and AI voice generator that allows users to convert text into speech using cutting-edge AI voices with an American English accent. With SpeechGen.io, users can create realistic voiceovers for videos, e-learning materials, advertising, public announcements, podcasts, mobile apps, presentations, and more. The platform offers a wide range of features, including the ability to download converted audio files in MP3, WAV, and OGG formats, support for long texts, commercial use of generated audio, multi-voice editing, custom voice settings, SSML support, and more. SpeechGen.io is accessible in any browser and offers an intuitive interface suitable for beginners. The platform also provides powerful support and is compatible with various editing programs.
Speechelo
Speechelo is a text-to-speech software that allows users to instantly generate human-sounding voiceovers from text. It offers a wide range of features, including over 30 human-sounding voices, the ability to add breathing sounds and pauses, and the ability to generate voiceovers in over 23 languages. Speechelo is easy to use and can be integrated with any video creation software. It is a great tool for creating voiceovers for sales videos, training videos, educational videos, and more.
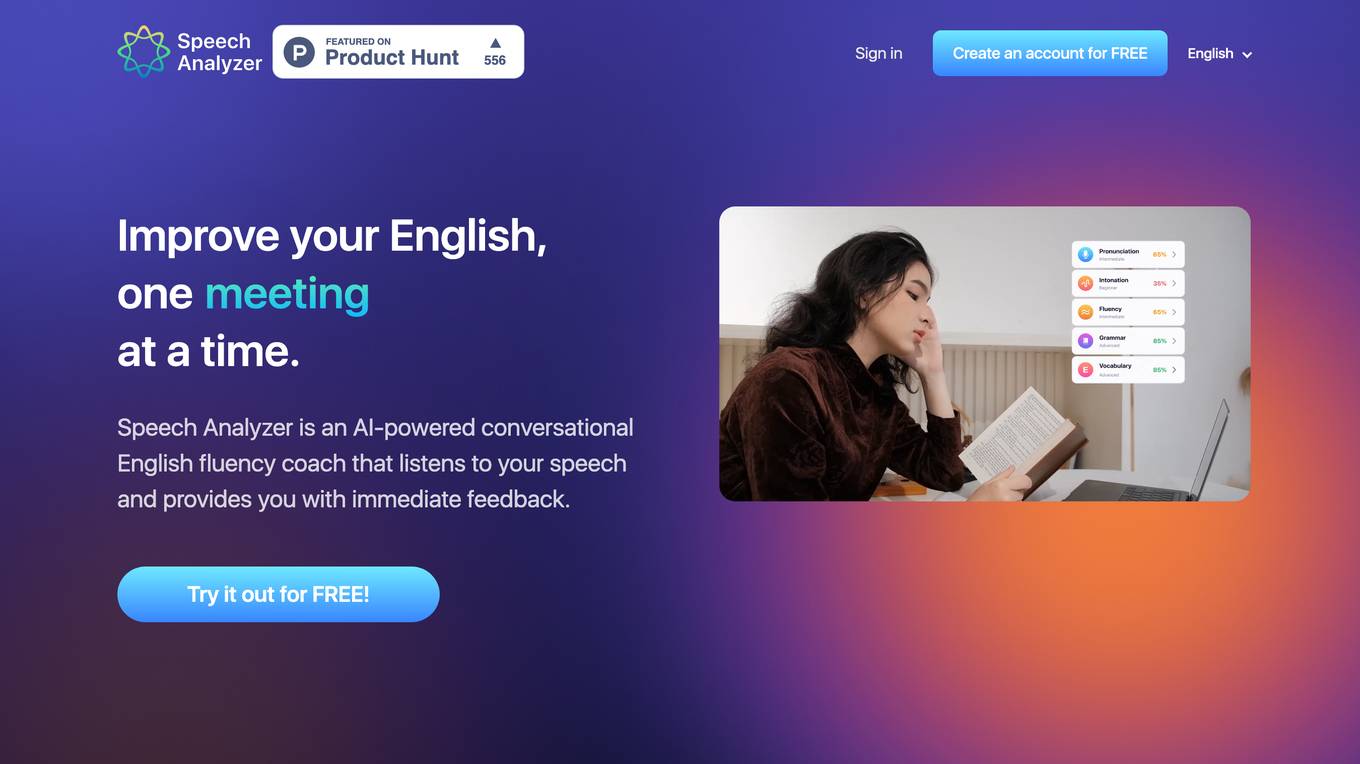
ELSA Speech Analyzer
ELSA Speech Analyzer is an AI-powered conversational English fluency coach that provides instant, personalized feedback on your speech. It helps users improve their pronunciation, intonation, grammar, and vocabulary through real-time analysis. The tool is designed to assist individuals, professionals, students, and organizations in enhancing their English speaking skills and communication abilities.
Speechki
Speechki is an AI Realistic Voice Generator and Text-to-Speech Solution offering over 1,100 voices in 80+ languages. It provides a user-friendly platform for converting text into engaging audio with AI-powered voices. The application is designed to cater to various needs such as audiobook production, content creation, podcasting, and more. With features like real-time proof-listening, chapter-like formatting, streamlined role management, precision pause control, and nuanced speech control, Speechki aims to enhance the user experience and deliver lifelike audio output. The tool also offers global reach with multicast and multilanguage support, making it suitable for a diverse audience.
Speechimo
Speechimo is an AI-powered text-to-speech tool that transforms written content into high-quality audio with human-like voices. It offers a user-friendly interface, premium voices, and efficient voice generation, making it a valuable asset for content creators across various platforms. With Speechimo, users can enhance their videos, audiobooks, podcasts, and e-learning materials, elevating the overall quality of their content creation process.
SpeechEasy
SpeechEasy is a high-quality text-to-speech tool that harnesses the power of AI and machine learning to convert text into natural-sounding audio. With SpeechEasy, you can generate studio-grade synthetic voices that are easy to understand and consume, making it perfect for on-the-go listening, home or office use, and e-learning content.
SpeechMap.AI
SpeechMap.AI is a public research project that explores the boundaries of AI-generated speech. It focuses on testing how language models respond to sensitive and controversial prompts across different providers, countries, and topics. The platform aims to reveal the invisible boundaries of AI speech by analyzing what models avoid, refuse, or shut down. By measuring and comparing AI models' responses, SpeechMap.AI sheds light on the evolving landscape of AI-generated speech and its impact on public expression.
AI Wedding Speech Generator
The AI wedding speech generator is an online tool that allows users to create personalized wedding speeches quickly and effortlessly. Users can select their role and style, input special details, and generate fully structured and emotional speeches within seconds. The tool offers multiple speech styles to match the wedding atmosphere, allows for personalization with shared memories and emotional connections, and provides high-quality customer support. It is a convenient solution for anyone looking to prepare touching and meaningful speeches for weddings.
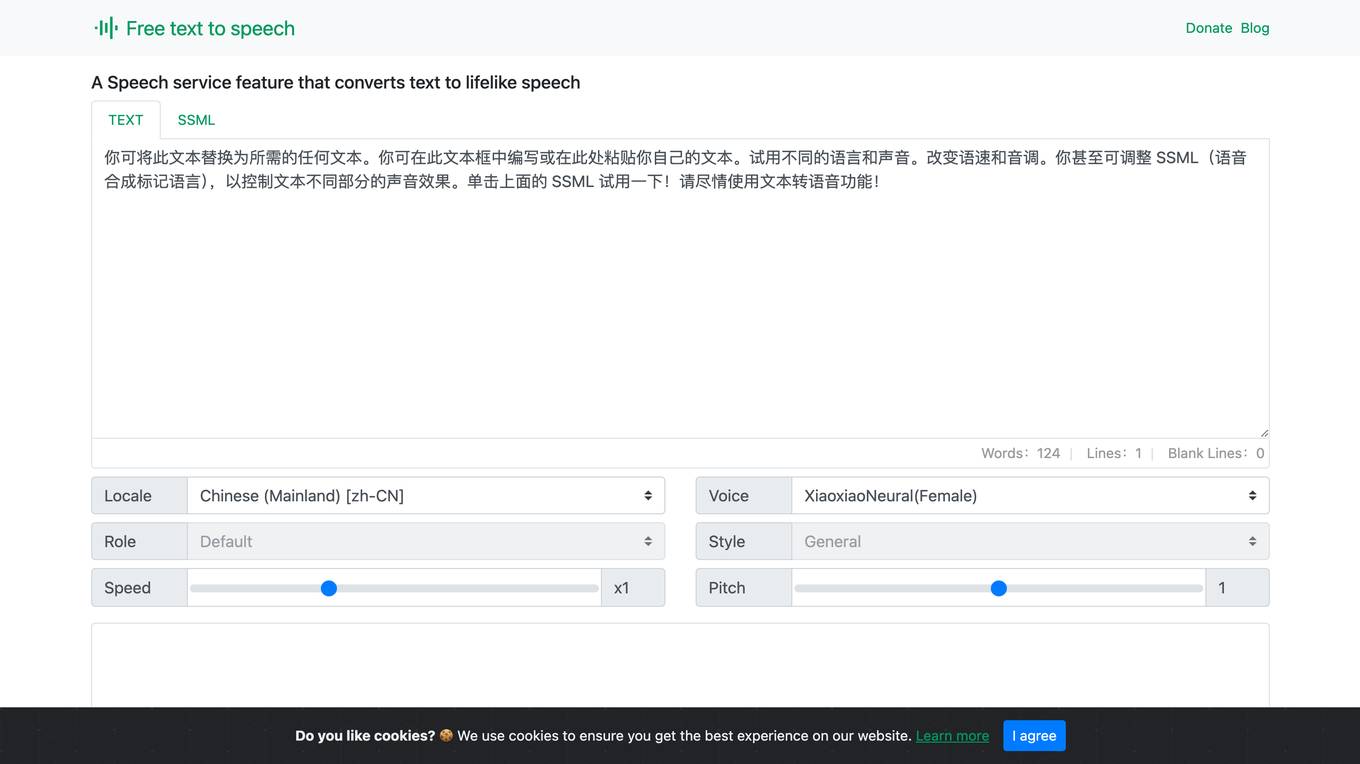
Free Text to Speech Online Converter Tools
This website provides a free text-to-speech converter tool that utilizes Microsoft's AI speech library to synthesize realistic-sounding speech from text. It offers customizable voice options, fine-tuned speech controls, and multilingual support with over 330 neural network voices across 129 languages. The tool is accessible on various browsers, including Chrome, Firefox, and Edge, and can be used for a range of applications, such as text readers and voice-enabled assistants.
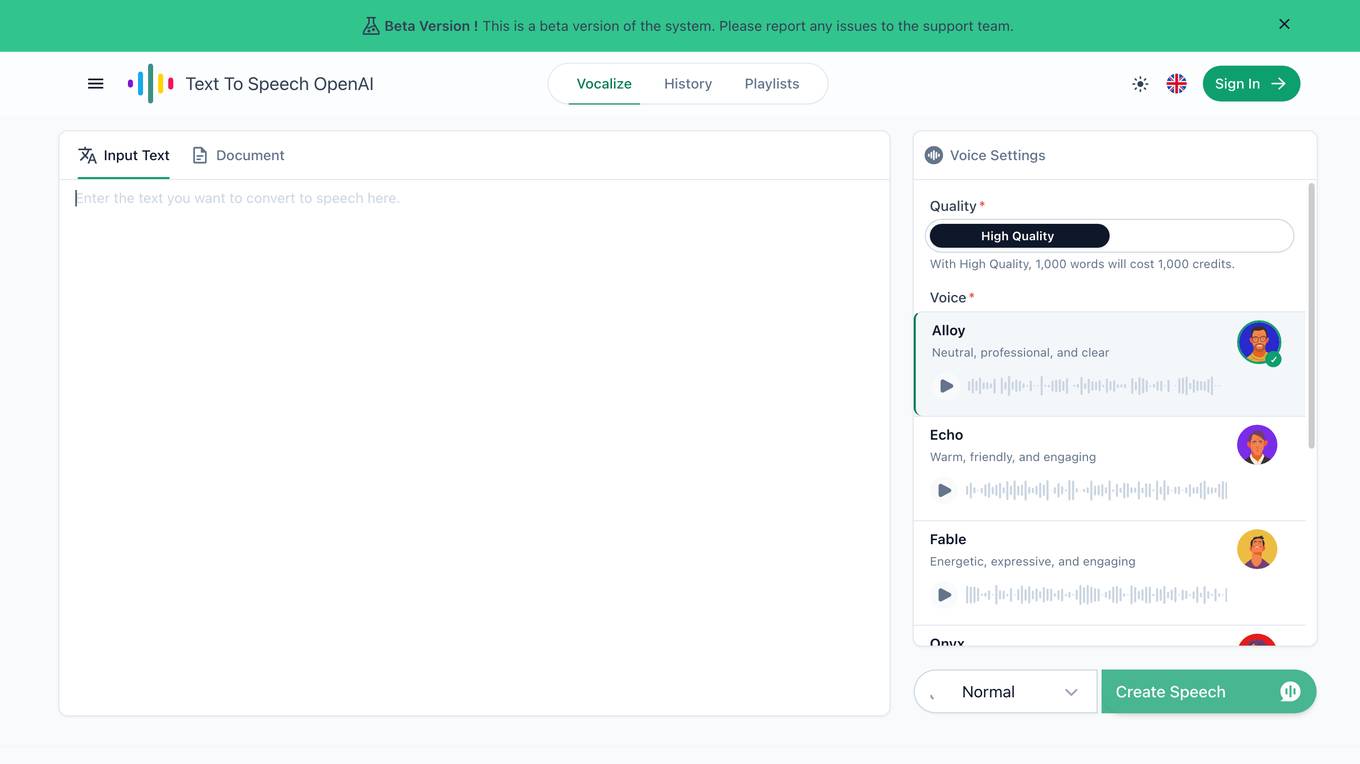
Text-To-Speech OpenAI
Text-To-Speech OpenAI is a professional AI voice generator that allows users to convert text into natural-sounding speech. With advanced AI technology, it offers a wide range of voices, languages, and customization options to create realistic and engaging audio content. Whether you need to create voiceovers for videos, podcasts, e-learning courses, or any other project, Text-To-Speech OpenAI provides a powerful and user-friendly solution.
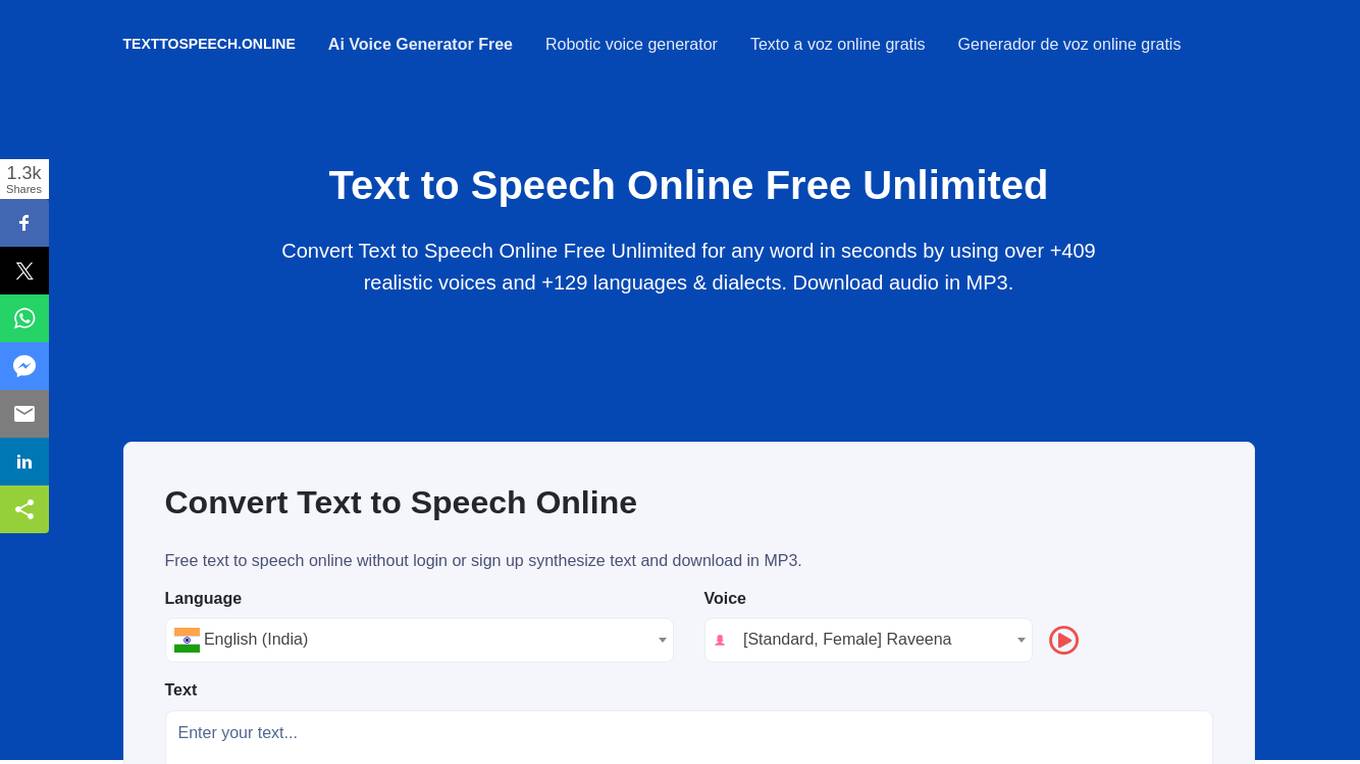
Text to Speech Online
Text to Speech Online is a free AI tool that offers unlimited text-to-speech conversion with over 409 realistic voices and 129 languages & dialects. Users can convert text to speech in seconds without the need to log in or sign up. The tool supports multiple languages and accents, including standard voices and AI voices, and offers flexible pricing models. Users can enjoy a full set of SSML features, create natural-sounding speech, download audio in MP3 or WAV formats, and share results on various platforms. Text to Speech Online is a versatile tool that can be used for various purposes, including providing audio cues for visually impaired users, assisting in education, creating audio versions of books, and developing virtual assistants.
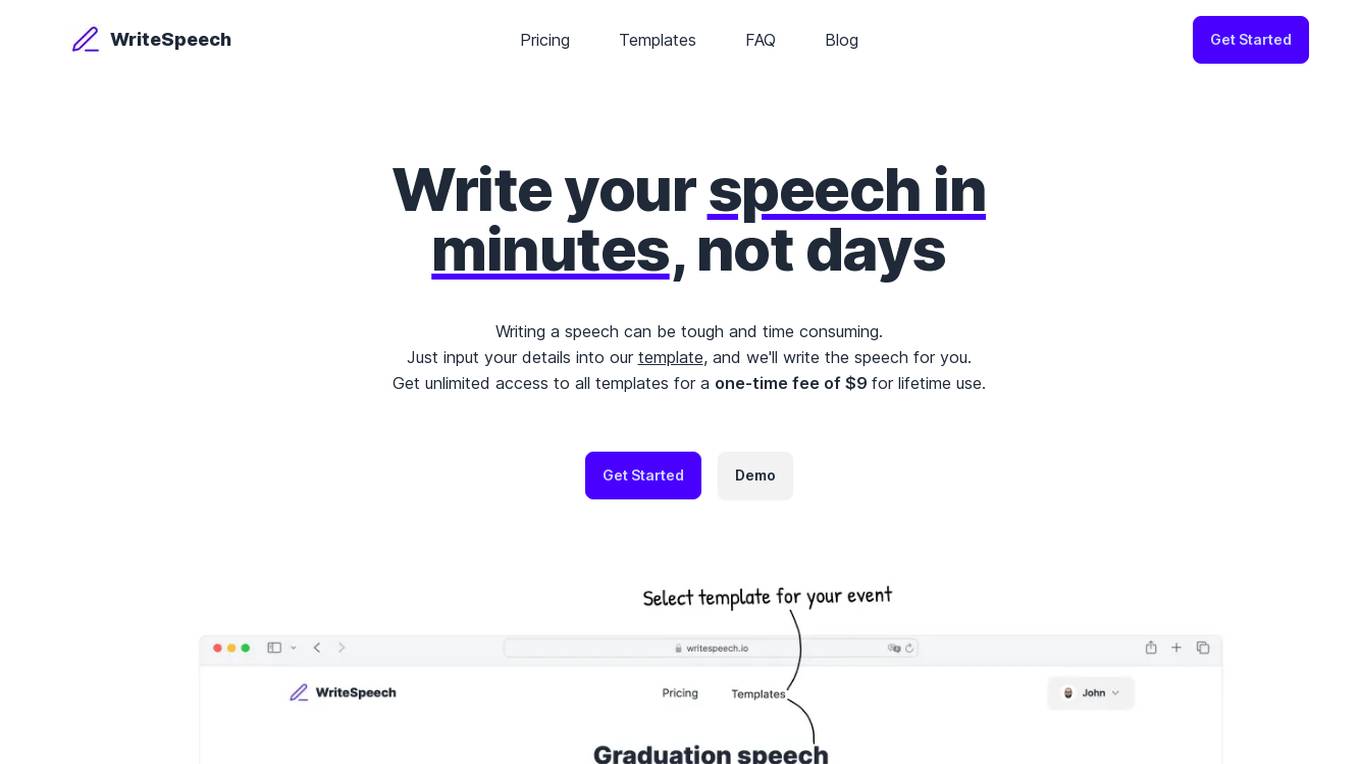
WriteSpeech
WriteSpeech is an AI-powered speech writing tool that helps users create speeches quickly and effortlessly. Users can input their details into templates for various occasions, and the tool generates a personalized speech. With a one-time fee of $9 for lifetime access to all templates, users can save time and effort in crafting speeches for events like weddings, graduations, and eulogies.
0 - Open Source AI Tools
20 - OpenAI Gpts
AI Speech Guide
A helpful coach for speech writing, offering constructive advice and support

SpeechTherapist GPT
Your very own speech therapy assistant. Completely private and confidential.
Dedicated Speech-Language Pathologist
Expert Speech-Language Pathologist offering tailored medical consultations.
Speech Parody
Create speech transcript parodies. Copyright (C) 2023, Sourceduty - All Rights Reserved.

Detailed Speech Drafting Wizard
Crafts speeches from PowerPoint slides and reference materials, adding depth and context.
AI.EX Wedding Speech Consultant
Your partner in crafting perfect wedding speeches. Let me be your guide to writing impactful, memorable speeches for unforgettable moments.
SpeechGPT User Guide
A guide for using SpeechGPT, focusing on its features, setup, and usage.
Motivational Character Speeches
Crafts motivational speeches as TV, anime, movie, and game characters.

AI Phonetics and Reading Coach with Speech
Phonetics and reading coach with interactive voice capabilities, tailored for adult beginners.


Gravitas
A speechwriter that embodies the essence of seriousness and importance in communication.
Cat Translator
Your Feline Language Specialist for translating human speech to cat sounds.