Best AI tools for< Separate Audio Files >
20 - AI tool Sites
MVSEP - Music & Voice Separation
MVSEP is an AI-powered application that specializes in music and voice separation. It offers users the ability to separate audio files into voice and music parts using advanced algorithms and models. Users can easily upload files through drag and drop or remote upload features. The application provides various separation types, HQ models, and output encoding options to cater to different user needs. MVSEP aims to enhance the audio editing experience by providing high-quality results and a user-friendly interface.
Vocal Remover Oak
Vocal Remover Oak is an advanced AI tool designed for music producers, video makers, and karaoke enthusiasts to easily separate vocals and accompaniment in audio files. The website offers a free online vocal remover service that utilizes deep learning technology to provide fast processing, high-quality output, and support for various audio and video formats. Users can upload local files or provide YouTube links to extract vocals, accompaniment, and original music. The tool ensures lossless audio output quality and compatibility with multiple formats, making it suitable for professional music production and personal entertainment projects.
Music Demixer
Music Demixer is an AI-powered online tool that allows users to convert audio files into readable sheet music, MIDI files, and stems. It offers features like separating vocals and instruments, multi-track MIDI conversion, lead and backing vocals split, drum kit breakdown, and more. With a user-friendly interface, Music Demixer caters to musicians and music producers looking to transcribe music, remix tracks, or practice specific instruments. The tool ensures privacy by running most processing tasks in the user's browser and offers a 3-day free trial for users to explore its capabilities.
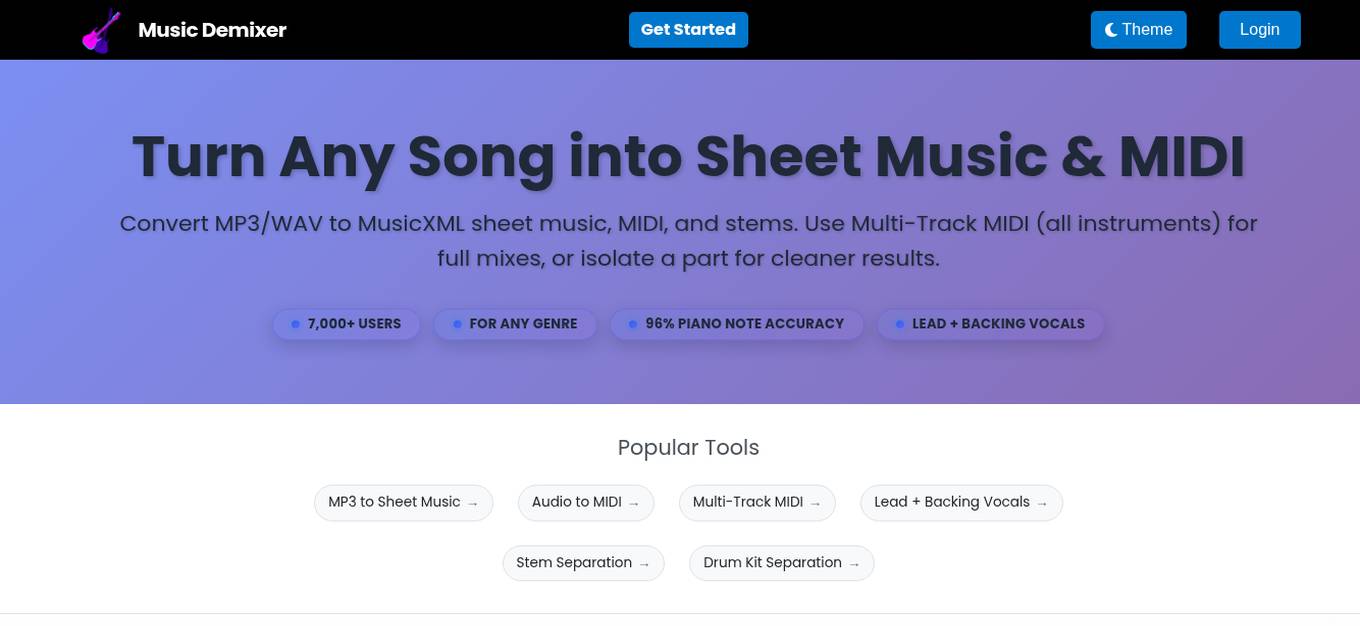
Music Demixer
Music Demixer is an AI-powered tool that allows users to convert MP3/WAV files into MusicXML sheet music, MIDI, and stems. It offers features such as Multi-Track MIDI for full mixes, isolation of specific parts for cleaner results, and stem separation. With a user base of over 7,000 and 96% piano note accuracy, Music Demixer is a popular choice for musicians and content creators looking to manipulate and transcribe music tracks.
VocalRemover.org
VocalRemover.org is a website that offers a tool to remove vocals from music tracks. Users can upload their audio files and the tool will process them to create a version with the vocals removed. The site provides a simple and user-friendly interface for users to easily access this feature. VocalRemover.org aims to provide a convenient solution for music enthusiasts, creators, and DJs who want to create remixes or karaoke versions of songs without vocals.
Samplab
Samplab is an AI-powered audio editing tool that allows users to manipulate audio samples with advanced features such as note editing, chord detection, stem separation, audio to MIDI conversion, and audio warping. It offers a seamless integration with digital audio workstations (DAWs) as a plugin or desktop app, enabling producers to enhance their music production workflow. Samplab's AI technology revolutionizes the way users interact with audio samples, providing unprecedented control over notes, chords, and melodies.
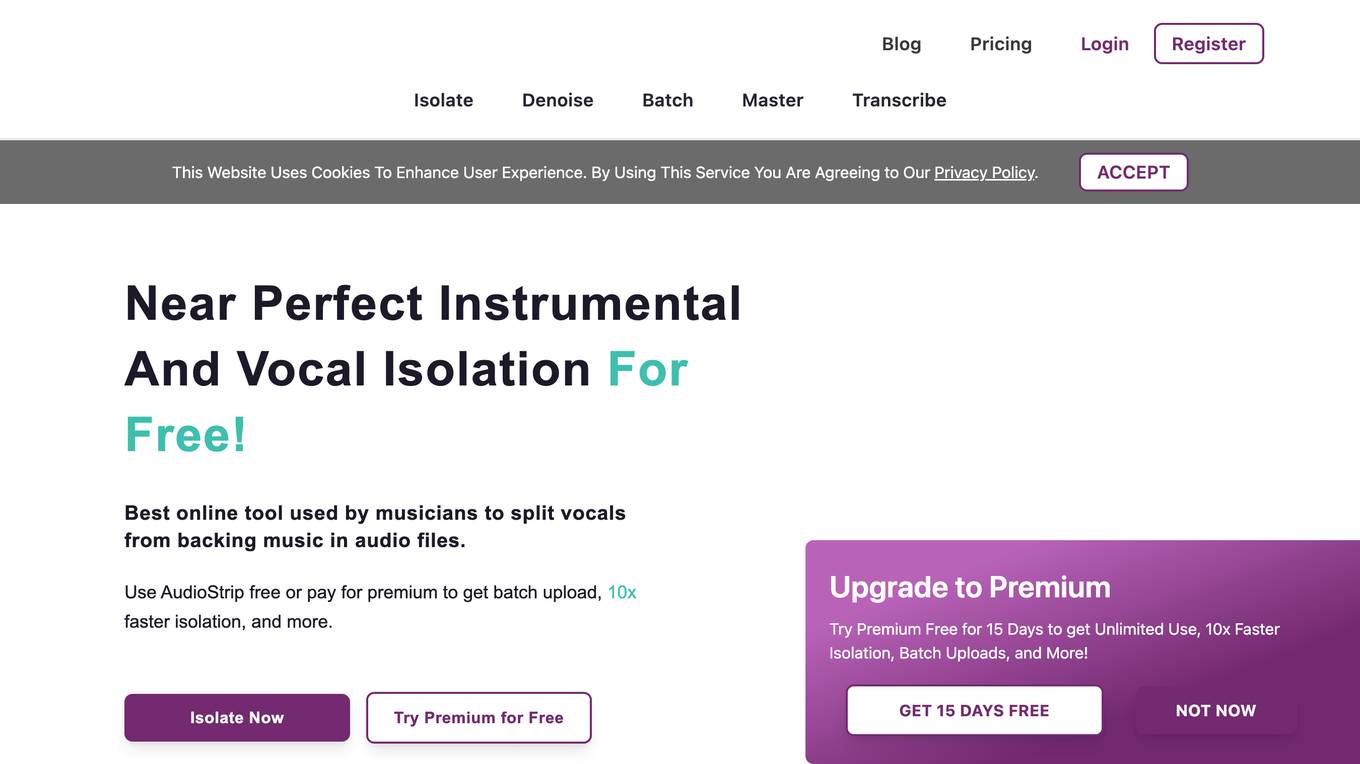
AudioStrip
AudioStrip is a free online vocal isolator that allows you to remove vocals from any song. It uses artificial intelligence to separate the vocals from the music, and it does a surprisingly good job. You can use AudioStrip to create a cappella versions of your favorite songs, or you can use it to isolate the vocals from a song so that you can sing along with them. AudioStrip is easy to use. Just upload a song to the website, and then click the "Extract Vocals" button. AudioStrip will then process the song and create a new file that contains only the vocals. You can then download the new file to your computer.
AudioShake
AudioShake is a cloud-based audio processing platform that uses artificial intelligence (AI) to separate audio into its component parts, such as vocals, music, and effects. This technology can be used for a variety of applications, including mixing and mastering, localization and captioning, interactive audio, and sync licensing.
Riverside
Riverside is an online podcast and video studio that makes recording and editing at the highest quality possible, accessible to anyone. It offers features such as separate audio and video tracks, AI-powered transcription and captioning, and a text-based editor for faster post-production. Riverside is designed for individuals and businesses of all sizes, including podcasters, video creators, producers, and marketers.
Music AI
Music AI is an AI audio platform that offers state-of-the-art ethical AI solutions for audio and music applications. It provides a wide range of tools and modules for tasks such as stem separation, transcription, mixing, mastering, content generation, effects, utilities, classification, enhancement, style transfer, and more. The platform aims to streamline audio processing workflows, enhance creativity, improve accuracy, increase engagement, and save time for music professionals and businesses. Music AI prioritizes data security, privacy, and customization, allowing users to build custom workflows with over 50 AI modules.
Galaxy.ai
Galaxy.ai is an all-in-one AI platform that offers a wide range of AI tools and applications to streamline and enhance various business processes. From data analysis to predictive modeling, Galaxy.ai provides advanced AI solutions to help businesses make data-driven decisions and improve efficiency. With its user-friendly interface and powerful algorithms, Galaxy.ai is designed to cater to the needs of both small businesses and large enterprises, making AI technology accessible and easy to implement.
Moises App
Moises App is a music application powered by AI that provides musicians with a range of tools to enhance their practice and performance. With Moises App, users can separate vocals and instruments in any song, adjust the speed and pitch, and detect chords in real time. The app also includes a smart metronome and audio speed changer, making it an ideal tool for musicians of all levels. Moises App is available as a desktop application, iOS app, and web app, making it accessible to musicians on any device.

Moises
Moises is an AI-powered musician's app that allows users to remove vocals and instruments from any song. With Moises, musicians and music enthusiasts can isolate specific elements of a track for learning, remixing, or practicing purposes. The app utilizes advanced AI algorithms to provide high-quality audio separation, making it a valuable tool for music production and analysis. Moises offers a user-friendly interface and intuitive controls, making it accessible to both beginners and professionals in the music industry.
Melody ML
Melody ML is an AI-powered music processing tool that allows users to separate music tracks using machine learning technology. Users can upload songs, and the tool uses AI algorithms to extract vocals, drums, bass, and other instruments into separate stems. Melody ML offers a user-friendly platform for music enthusiasts, producers, and artists to enhance their music production process.
pyannote AI Speaker Intelligence Platform
The pyannote AI Speaker Intelligence Platform is an advanced AI tool designed for developers to detect, segment, label, and separate speakers in any language. It offers state-of-the-art speaker diarization models that accurately identify speakers in audio recordings, providing valuable insights and improving productivity. With optimized AI models, the platform saves time, effort, and money by delivering top-tier performance. The tool is language agnostic and offers advanced features such as speaker partitioning, identification, overlapping speech detection, voice activity detection, speaker separation, and confidence scoring.
Vocalx
Vocalx is an AI-powered online tool that converts text into natural-sounding speech. It utilizes advanced speech synthesis technology to generate lifelike voices for various applications. Users can easily create audio content from written text, making it ideal for content creators, educators, and businesses looking to enhance their multimedia offerings. With Vocalx, you can customize the voice, tone, and speed of the generated speech to suit your needs. The tool supports multiple languages and accents, providing a versatile solution for voiceover projects, audiobooks, podcasts, and more.

RipX DAW
RipX DAW is an AI-powered digital audio workstation (DAW) that allows users to edit notes in the mix, replace sounds, and separate stems. It is designed to assist musicians and producers in creating and editing music using AI-generated samples and loops. RipX DAW is known for its advanced features such as 6+ stem separation, sound replacement menu, and the ability to edit notes in the mix.
Gaudio Studio
Gaudio Studio is an AI music separation tool designed for creators to unleash their creativity with ease. It allows users to extract background music, separate instruments, and remove vocals from any music content. Powered by GSEP (Gaudio source SEParation), a high-quality and easy-to-use AI stem separation model, Gaudio Studio offers a seamless experience for audio separation. Users can upload their songs in various formats, access the tool from desktop or mobile devices, and enjoy Studio Plans for advanced processing. Additionally, Gaudio Studio can be integrated with cloud APIs and On-device SDKs for business applications, offering a versatile solution for music professionals and enthusiasts.
SplitSong.com
SplitSong.com is an AI-powered tool that allows users to split songs into individual instrument tracks using Artificial Intelligence. Created by @markdoppler_, this tool enables users to upload songs or extract them from YouTube videos and separate them into distinct components such as drums, instrumental, bass, and voice. With a user-friendly interface, SplitSong.com revolutionizes the music editing process by providing a seamless way to isolate specific elements of a song for further customization or analysis.
RE:Create
RE:Create is an AI-powered app that provides endless content ideas and recreates any Instagram/Tiktok video in your style, tone, language, and even your voice! Our application streamlines the content creation process, eliminating the need for extensive planning and strategy. Save time and effort while achieving effective results. No need to hire a separate voiceover artist. Our application offers customizable voice options, ensuring your videos have the perfect audio to complement the visuals. No need to hire a professional scriptwriter. Our platform assists in creating engaging video scripts, guiding you through the process and ensuring your content flows seamlessly.
1 - Open Source AI Tools
NeuroSandboxWebUI
A simple and convenient interface for using various neural network models. Users can interact with LLM using text, voice, and image input to generate images, videos, 3D objects, music, and audio. The tool supports a wide range of models for different tasks such as image generation, video generation, audio file separation, voice conversion, and more. Users can also view files from the outputs directory in a gallery, download models, change application settings, and check system sensors. The goal of the project is to create an easy-to-use application for utilizing neural network models.