Best AI tools for< Scale Inference >
20 - AI tool Sites
d-Matrix
d-Matrix is an AI tool that offers ultra-low latency batched inference for generative AI technology. It introduces Corsair™, the world's most efficient AI inference platform for datacenters, providing high performance, efficiency, and scalability for large-scale inference tasks. The tool aims to transform the economics of AI inference by delivering fast, sustainable, and scalable AI solutions without compromising on speed or usability.
VeroCloud
VeroCloud is a platform offering tailored solutions for AI, HPC, and scalable growth. It provides cost-effective cloud solutions with guaranteed uptime, performance efficiency, and cost-saving models. Users can deploy HPC workloads seamlessly, configure environments as needed, and access optimized environments for GPU Cloud, HPC Compute, and Tally on Cloud. VeroCloud supports globally distributed endpoints, public and private image repos, and deployment of containers on secure cloud. The platform also allows users to create and customize templates for seamless deployment across computing resources.
Salad
Salad is a distributed GPU cloud platform that offers fully managed and massively scalable services for AI applications. It provides the lowest priced AI transcription in the market, with features like image generation, voice AI, computer vision, data collection, and batch processing. Salad democratizes cloud computing by leveraging consumer GPUs to deliver cost-effective AI/ML inference at scale. The platform is trusted by hundreds of machine learning and data science teams for its affordability, scalability, and ease of deployment.
Cast AI
Cast AI is an intelligent Kubernetes automation platform that offers live migration for AWS EKS, enabling users to migrate stateful workloads with zero downtime. The platform provides application performance automation by automating and optimizing the entire application stack, including Kubernetes cluster optimization, security, workload optimization, LLM optimization for AIOps, cost monitoring, and database optimization. Cast AI integrates with various cloud services and tools, offering solutions for migration of stateful workloads, inference at scale, and cutting AI costs without sacrificing scale. The platform helps users improve performance, reduce costs, and boost productivity through end-to-end application performance automation.
FluidStack
FluidStack is a leading GPU cloud platform designed for AI and LLM (Large Language Model) training. It offers unlimited scale for AI training and inference, allowing users to access thousands of fully-interconnected GPUs on demand. Trusted by top AI startups, FluidStack aggregates GPU capacity from data centers worldwide, providing access to over 50,000 GPUs for accelerating training and inference. With 1000+ data centers across 50+ countries, FluidStack ensures reliable and efficient GPU cloud services at competitive prices.

Mystic.ai
Mystic.ai is an AI tool designed to deploy and scale Machine Learning models with ease. It offers a fully managed Kubernetes platform that runs in your own cloud, allowing users to deploy ML models in their own Azure/AWS/GCP account or in a shared GPU cluster. Mystic.ai provides cost optimizations, fast inference, simpler developer experience, and performance optimizations to ensure high-performance AI model serving. With features like pay-as-you-go API, cloud integration with AWS/Azure/GCP, and a beautiful dashboard, Mystic.ai simplifies the deployment and management of ML models for data scientists and AI engineers.
Groq
Groq is a fast AI inference tool that offers GroqCloud™ Platform and GroqRack™ Cluster for developers to build and deploy AI models with ultra-low-latency inference. It provides instant intelligence for openly-available models like Llama 3.1 and is known for its speed and compatibility with other AI providers. Groq powers leading openly-available AI models and has gained recognition in the AI chip industry. The tool has received significant funding and valuation, positioning itself as a strong challenger to established players like Nvidia.
Cerebras API
The Cerebras API is a high-speed inferencing solution for AI model inference powered by Cerebras Wafer-Scale Engines and CS-3 systems. It offers developers access to two models: Meta’s Llama 3.1 8B and 70B models, which are instruction-tuned and suitable for conversational applications. The API provides low-latency solutions and invites developers to explore new possibilities in AI development.
Modular
Modular is a fast, scalable Gen AI inference platform that offers a comprehensive suite of tools and resources for AI development and deployment. It provides solutions for AI model development, deployment options, AI inference, research, and resources like documentation, models, tutorials, and step-by-step guides. Modular supports GPU and CPU performance, intelligent scaling to any cluster, and offers deployment options for various editions. The platform enables users to build agent workflows, utilize AI retrieval and controlled generation, develop chatbots, engage in code generation, and improve resource utilization through batch processing.
Lambda
Lambda is a superintelligence cloud platform that offers on-demand GPU clusters for multi-node training and fine-tuning, private large-scale GPU clusters, seamless management and scaling of AI workloads, inference endpoints and API, and a privacy-first chat app with open source models. It also provides NVIDIA's latest generation infrastructure for enterprise AI. With Lambda, AI teams can access gigawatt-scale AI factories for training and inference, deploy GPU instances, and leverage the latest NVIDIA GPUs for high-performance computing.
Denvr DataWorks AI Cloud
Denvr DataWorks AI Cloud is a cloud-based AI platform that provides end-to-end AI solutions for businesses. It offers a range of features including high-performance GPUs, scalable infrastructure, ultra-efficient workflows, and cost efficiency. Denvr DataWorks is an NVIDIA Elite Partner for Compute, and its platform is used by leading AI companies to develop and deploy innovative AI solutions.
fal.ai
fal.ai is a generative media platform designed for developers to build the next generation of creativity. It offers lightning-fast inference with no compromise on quality, providing access to high-quality generative media models optimized by the fal Inference Engine™. The platform allows developers to fine-tune their own models, leverage real-time infrastructure for new user experiences, and scale to thousands of GPUs as needed. With a focus on developer experience, fal.ai aims to be the fastest AI tool for running diffusion models.
Luxonis
Luxonis is an AI application that offers Visual AI solutions engineered for precision edge inference. The application provides stereo depth cameras with unique features and quality, enabling users to perform advanced vision tasks on-device, reducing latency and bandwidth demands. With open-source DepthAI API, users can create and deploy custom vision solutions that scale with their needs. Luxonis also offers real-world training data for self-improving vision intelligence and operates flawlessly through vibrations, temperature shifts, and extended use. The application integrates advanced sensing capabilities with up to 48MP cameras, wide field of view, IMUs, microphones, ToF, thermal, IR illumination, and active stereo for unparalleled perception.

Wallaroo.AI
Wallaroo.AI is an AI inference platform that offers production-grade AI inference microservices optimized on OpenVINO for cloud and Edge AI application deployments on CPUs and GPUs. It provides hassle-free AI inferencing for any model, any hardware, anywhere, with ultrafast turnkey inference microservices. The platform enables users to deploy, manage, observe, and scale AI models effortlessly, reducing deployment costs and time-to-value significantly.
BentoML
BentoML is a platform for software engineers to build, ship, and scale AI products. It provides a unified AI application framework that makes it easy to manage and version models, create service APIs, and build and run AI applications anywhere. BentoML is used by over 1000 organizations and has a global community of over 3000 members.
TitanML
TitanML is a platform that provides tools and services for deploying and scaling Generative AI applications. Their flagship product, the Titan Takeoff Inference Server, helps machine learning engineers build, deploy, and run Generative AI models in secure environments. TitanML's platform is designed to make it easy for businesses to adopt and use Generative AI, without having to worry about the underlying infrastructure. With TitanML, businesses can focus on building great products and solving real business problems.
Together AI
Together AI is an AI Acceleration Cloud platform that offers fast inference, fine-tuning, and training services. It provides self-service NVIDIA GPUs, model deployment on custom hardware, AI chat app, code execution sandbox, and tools to find the right model for specific use cases. The platform also includes a model library with open-source models, documentation for developers, and resources for advancing open-source AI. Together AI enables users to leverage pre-trained models, fine-tune them, or build custom models from scratch, catering to various generative AI needs.
Inworld
Inworld is an AI framework designed for games and media, offering a production-ready framework for building AI agents with client-side logic and local model inference. It provides tools optimized for real-time data ingestion, low latency, and massive scale, enabling developers to create engaging and immersive experiences for users. Inworld allows for building custom AI agent pipelines, refining agent behavior and performance, and seamlessly transitioning from prototyping to production. With support for C++, Python, and game engines, Inworld aims to future-proof AI development by integrating 3rd-party components and foundational models to avoid vendor lock-in.
NeuReality
NeuReality is an AI-centric solution designed to democratize AI adoption by providing purpose-built tools for deploying and scaling inference workflows. Their innovative AI-centric architecture combines hardware and software components to optimize performance and scalability. The platform offers a one-stop shop for AI inference, addressing barriers to AI adoption and streamlining computational processes. NeuReality's tools enable users to deploy, afford, use, and manage AI more efficiently, making AI easy and accessible for a wide range of applications.
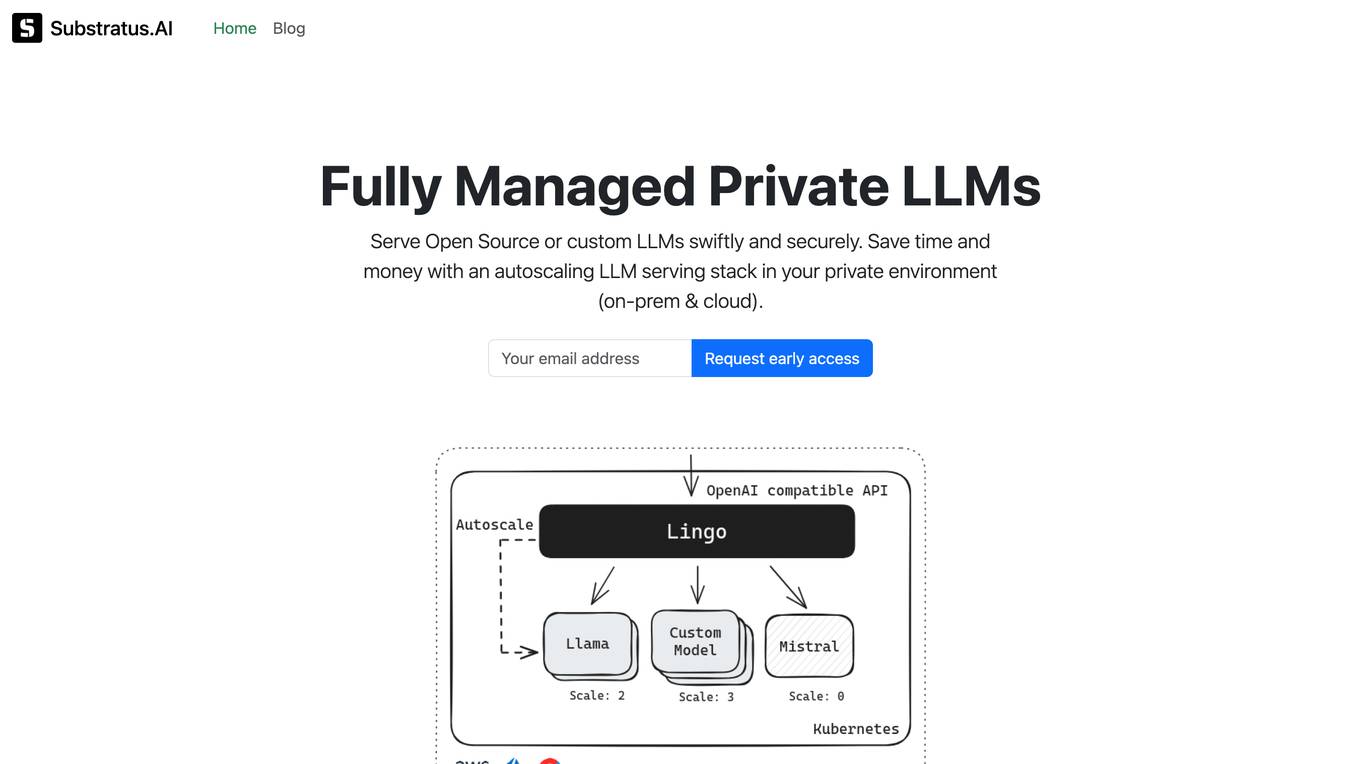
Substratus.AI
Substratus.AI is a fully managed private LLMs platform that allows users to serve LLMs (Llama and Mistral) in their own cloud account. It enables users to keep control of their data while reducing OpenAI costs by up to 10x. With Substratus.AI, users can utilize LLMs in production in hours instead of weeks, making it a convenient and efficient solution for AI model deployment.
2 - Open Source AI Tools

model_server
OpenVINO™ Model Server (OVMS) is a high-performance system for serving models. Implemented in C++ for scalability and optimized for deployment on Intel architectures, the model server uses the same architecture and API as TensorFlow Serving and KServe while applying OpenVINO for inference execution. Inference service is provided via gRPC or REST API, making deploying new algorithms and AI experiments easy.
crossroads
CrossRoads is a small package designed to orchestrate agents in Cloudflare Workers and durable objects. It aims to experiment with durable patterns and the interface between humans and AI. The tool leverages workers to execute tool calls at a large scale and utilizes RxJS for easy graph execution. Examples of applications include inference-time scaling with workers, durable-runner, and durable-search. Please note that this project is a work in progress and may experience issues during development.
20 - OpenAI Gpts

R&D Process Scale-up Advisor
Optimizes production processes for efficient large-scale operations.



CIM Analyst
In-depth CIM analysis with a structured rating scale, offering detailed business evaluations.
ML Engineer GPT
I'm a Python and PyTorch expert with knowledge of ML infrastructure requirements ready to help you build and scale your ML projects.
Business Angel - Startup and Insights PRO
Business Angel provides expert startup guidance: funding, growth hacks, and pitch advice. Navigate the startup ecosystem, from seed to scale. Essential for entrepreneurs aiming for success. Master your strategy and launch with confidence. Your startup journey begins here!
Sysadmin
I help you with all your sysadmin tasks, from setting up your server to scaling your already exsisting one. I can help you with understanding the long list of log files and give you solutions to the problems.
Seabiscuit Launch Lander
Startup Strong Within 180 Days: Tailored advice for launching, promoting, and scaling businesses of all types. It covers all stages from pre-launch to post-launch and develops strategies including market research, branding, promotional tactics, and operational planning unique your business. (v1.8)


Startup Advisor
Startup advisor guiding founders through detailed idea evaluation, product-market-fit, business model, GTM, and scaling.