Best AI tools for< Run With Multiple Gpus >
20 - AI tool Sites
Stablematic
Stablematic is a web-based platform that allows users to run Stable Diffusion and other machine learning models without the need for local setup or hardware limitations. It provides a user-friendly interface, pre-installed plugins, and dedicated GPU resources for a seamless and efficient workflow. Users can generate images and videos from text prompts, merge multiple models, train custom models, and access a range of pre-trained models, including Dreambooth and CivitAi models. Stablematic also offers API access for developers and dedicated support for users to explore and utilize the capabilities of Stable Diffusion and other machine learning models.
Vidura
Vidura is a prompt management system integrated with multiple AI systems, designed to enhance the Generative AI experience. Users can compose, organize, share, and export AI prompts easily. It offers features like categorizing prompts, built-in templates, prompt history, dynamic prompting, and community sharing. Vidura aims to make Generative AI accessible and user-friendly, providing a platform for learning and collaboration in the AI community.
Social Places
Social Places is a leading franchise marketing agency that provides a suite of tools to help businesses with multiple locations manage their online presence. The platform includes tools for managing listings, reputation, social media, ads, and bookings. Social Places also offers a conversational AI chatbot and a custom feedback form builder.
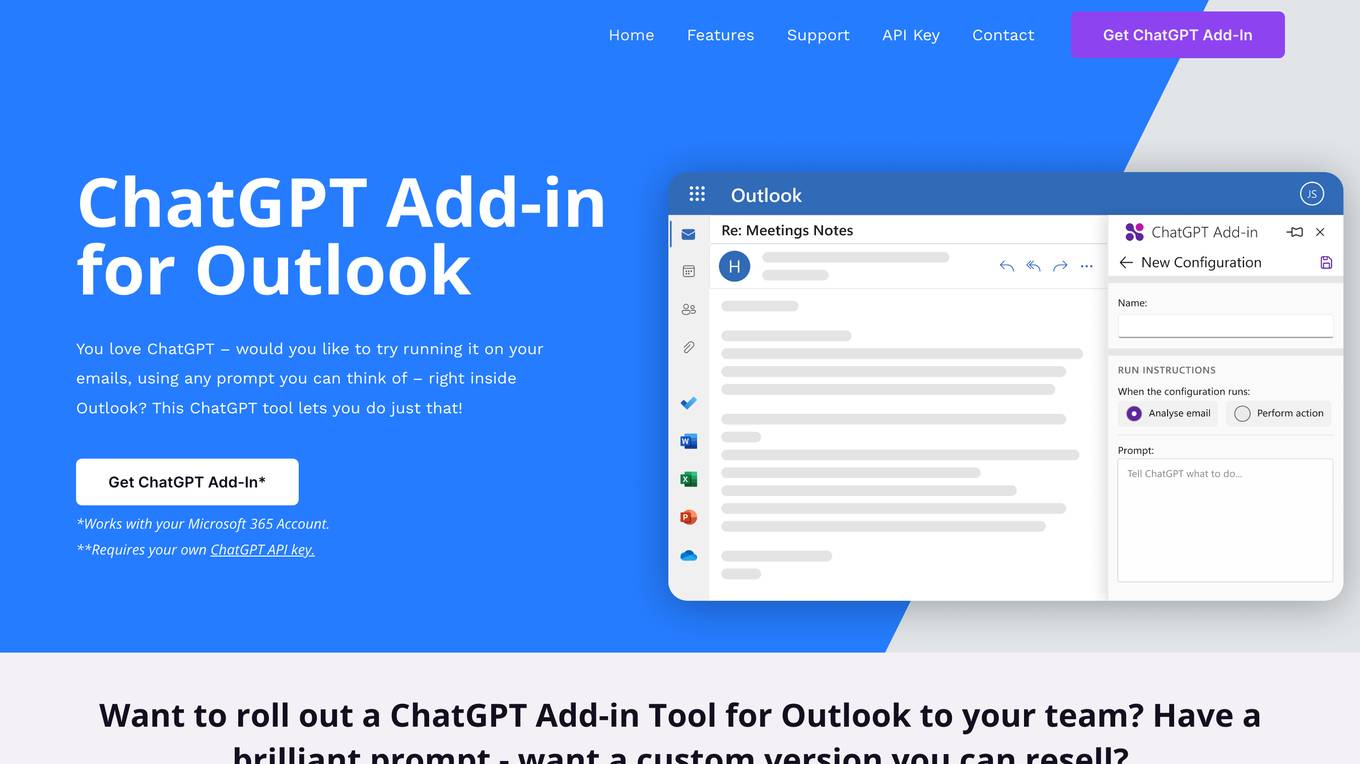
ChatGPT for Outlook
ChatGPT for Outlook is an AI tool that integrates the power of ChatGPT into Microsoft Outlook, allowing users to run ChatGPT on emails to generate summaries, highlights, and important information. Users can create custom prompts, process entire emails or specific parts, manage multiple configurations, and improve email efficiency. Blueberry Consultants, the developer, offers custom versions for businesses and teams, enabling users to resell the tool with unique prompts. The tool enhances productivity and information management within Outlook, leveraging AI technology for email processing and organization.
Deep Space
Deep Space is an all-in-one AI-powered construction management software platform designed for mid-sized commercial builders in Australia and New Zealand. It replaces the need for multiple tools by providing a connected operating system that integrates costings, schedules, site teams, and systems. The platform offers features such as preconstruction, scheduling, procurement, commercial delivery, documentation, HSEQ reporting, and AI assistant solutions. Deep Space aims to streamline project management processes, improve visibility, and enhance coordination across the full project lifecycle.
Replit
Replit is a software creation platform that provides an integrated development environment (IDE), artificial intelligence (AI) assistance, and deployment services. It allows users to build, test, and deploy software projects directly from their browser, without the need for local setup or configuration. Replit offers real-time collaboration, code generation, debugging, and autocompletion features powered by AI. It supports multiple programming languages and frameworks, making it suitable for a wide range of development projects.
GPT Prompt Tuner
GPT Prompt Tuner is an AI tool that leverages AI to enhance ChatGPT prompts and facilitate parallel conversations. It enables users to generate prompt iterations, customize prompts, and run multiple conversations simultaneously. The tool is designed to streamline the process of prompt engineering, offering a flexible and efficient solution for users seeking to optimize their interactions with ChatGPT.
ConversAI
ConversAI is an AI-powered chat assistant designed to enhance online communication. It uses natural language processing and machine learning to understand and respond to messages in a conversational manner. With ConversAI, users can quickly generate personalized responses, summarize long messages, detect the tone of conversations, communicate in multiple languages, and even add GIFs to their replies. It integrates seamlessly with various messaging platforms and tools, making it easy to use and efficient. ConversAI helps users save time, improve their communication skills, and have more engaging conversations online.
MindPal
MindPal is an AI application that offers a platform to build and run AI agents and multi-agent workflows for automating complex processes in businesses. It allows users to create specialized AI agents, connect multiple agents into workflows, and collaborate with humans seamlessly. MindPal integrates with various AI models, existing business tools, and enables users to start automating tasks in minutes. Users can train AI agents with their data, generate on-brand content, and handle multiple tasks simultaneously. The platform also provides AI workflow templates for various business functions.
Botonomous
Botonomous is an AI-powered platform that helps businesses automate their workflows. With Botonomous, you can create advanced automations for any domain, check your flows for potential errors before running them, run multiple nodes concurrently without waiting for the completion of the previous step, create complex, non-linear flows with no-code, and design human interactions to participate in your automations. Botonomous also offers a variety of other features, such as webhooks, scheduled triggers, secure secret management, and a developer community.
Edyt AI
Edyt AI is an AI-powered content optimization tool designed to help users create SEO-optimized content effortlessly. With the ability to generate articles in seconds and run multiple AI iterations on content, Edyt AI streamlines the content creation process. Users can improve existing blogs with just a few clicks, add external and internal links, and optimize content for better rankings. The tool ensures content quality by analyzing thousands of articles and words, making it a valuable asset for content creators and marketers.

Luminal
Luminal is a powerful AI copilot that enables users to clean, transform, and analyze spreadsheets 10x faster. It offers fast and efficient data analysis capabilities, allowing users to perform editing operations, answer complex questions, and run AI-enabled operations using natural language. Luminal simplifies data processing tasks, saving users time and effort. The application supports multiple languages, ensures secure data hosting with encryption, and offers flexible pricing plans to cater to different user needs.
ONNX Runtime
ONNX Runtime is a production-grade AI engine designed to accelerate machine learning training and inferencing in various technology stacks. It supports multiple languages and platforms, optimizing performance for CPU, GPU, and NPU hardware. ONNX Runtime powers AI in Microsoft products and is widely used in cloud, edge, web, and mobile applications. It also enables large model training and on-device training, offering state-of-the-art models for tasks like image synthesis and text generation.
Helium 10
Helium 10 is an AI-powered platform designed for everyday sellers on Amazon, Walmart, and TikTok. It offers a suite of tools to help sellers analyze product potential, optimize listings, manage inventory, and run advertising campaigns. The platform empowers sellers with AI-driven insights to increase profits and expand their brand presence across multiple marketplaces.
Windows Central
Windows Central is a website that provides news, reviews, and help on Windows 10, Windows 11, Xbox, and more. It covers a wide range of topics, including hardware, software, gaming, and accessories. The website also has a forum where users can ask questions and discuss topics related to Windows and Xbox.
ryme.ai
ryme.ai is an AI-driven influencer marketing platform based in India. It simplifies the process of influencer marketing by providing a platform to discover AI-matched creators, launch campaigns quickly, and track ROI efficiently. The platform offers features such as AI-powered creator discovery, streamlined workflow for content approval, data-driven insights for performance tracking, and the ability to run campaigns with full cost control. ryme.ai aims to empower brands and creators to connect through innovative influencer marketing solutions, ultimately transforming marketing strategies and achieving impactful results.
LM Studio
LM Studio is an AI tool designed for discovering, downloading, and running local LLMs (Large Language Models). Users can run LLMs on their laptops offline, use models through an in-app Chat UI or a local server, download compatible model files from HuggingFace repositories, and discover new LLMs. The tool ensures privacy by not collecting data or monitoring user actions, making it suitable for personal and business use. LM Studio supports various models like ggml Llama, MPT, and StarCoder on Hugging Face, with minimum hardware/software requirements specified for different platforms.
Breeze.ai
Breeze.ai is an AI-powered platform that helps businesses create professional-looking product photography, social media content, and marketing collateral in a fraction of the time and cost of traditional methods. With Breeze.ai, businesses can generate thousands of custom content in days, not weeks, at 50% of the monthly cost of traditional methods. Breeze.ai is trusted by companies globally and has helped thousands of users create content with AI.
TraqCheck
TraqCheck is an AI-powered agent for background checks that offers simple, fast, and reliable verifications verified by human experts. It brings inhuman speed and transparency to the verification process, enabling quick hiring decisions at scale. TraqCheck supports various types of checks, including ID, criminal, education, employment history, and more. The platform helps in managing hiring smartly by tracking progress, running analytics, and generating reports on-the-fly. With powerful features like HRMS integration, AI-powered insights, API integration, and more, TraqCheck enhances the hiring process and boosts efficiency and scalability.
Respell
Respell is an AI-powered platform that enables businesses to run their operations with agentic AI workflows. It offers advanced AI automation capabilities for various tasks such as lead generation, email marketing, user research, project management, customer support, and data management. Respell leverages cutting-edge AI models from OpenAI, Anthropic, Cohere, and other open-source providers to provide prompt assistance and custom-built agents for research, phone calls, integrations, and more. The platform ensures enterprise security with SOC II compliance, compliant models, and advanced PII & Prompt Injection Prevention. Users can create custom spells, automate workflows, integrate with popular platforms, and leverage AI to analyze and act on data for smarter decision-making.
1 - Open Source AI Tools
AI-Horde-Worker
AI-Horde-Worker is a repository containing the original reference implementation for a worker that turns your graphics card(s) into a worker for the AI Horde. It allows users to generate or alchemize images for others. The repository provides instructions for setting up the worker on Windows and Linux, updating the worker code, running with multiple GPUs, and stopping the worker. Users can configure the worker using a WebUI to connect to the horde with their username and API key. The repository also includes information on model usage and running the Docker container with specified environment variables.
20 - OpenAI Gpts
Restaurant Startup Guide
Meet the Restaurant Startup Guide GPT: your friendly guide in the restaurant biz. It offers casual, approachable advice to help you start and run your own restaurant with ease.
Unix Shell Simulator with Visuals
UNIX terminal responses with OS process visuals. (on or off) [off] by default until GPT-4 behaves better... Bash profiles and advanced memory system for realistic bash simulation. V1 (beta)



Design Sprint Coach (beta)
A helpful coach for guiding teams through Design Sprints with a touch of sass.


Product Coach
Guiding your product journey with expert insights. Made by the team behind kraftful.com
Dungeon Master Assistant
Enhance D&D campaigns with Roll20 setup and custom token creation.
Social Media Marketer
Expert social media marketing advisor with up-to-date insights and strategies.

ChatEUC
Your expert guide for all things EUC, with a focus on battery safety, maintenance, and protective gear.

DungeonRules
DungeonRules GPT demystifies D&D and RPG rules, providing clear explanations with examples.

Ad Guru
Expert in Google's ad campaigns and digital marketing, hip and cool in style. In touch with the social web.