Best AI tools for< Provide Speech Therapy >
20 - AI tool Sites
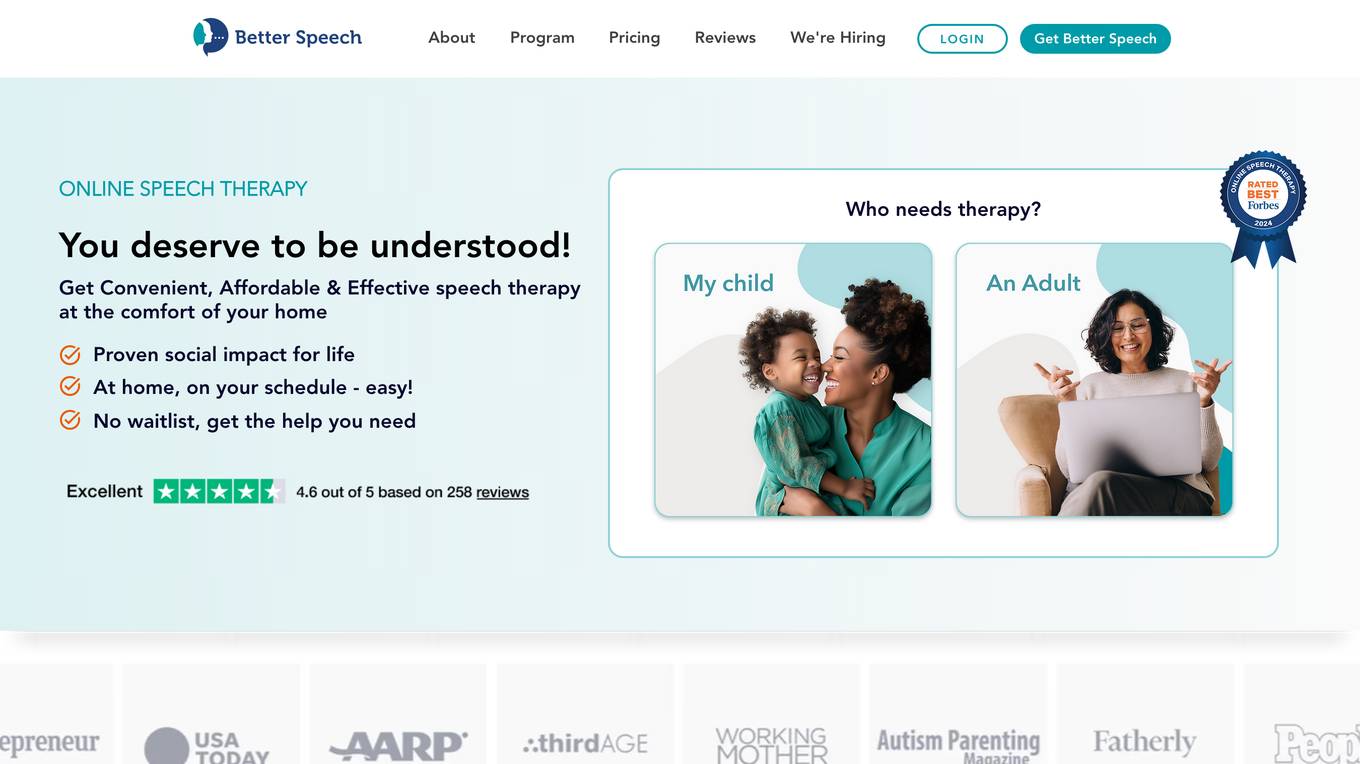
Better Speech Online Speech Therapy
Better Speech Online Speech Therapy is an AI-driven platform that offers convenient, affordable, and effective speech therapy services for children and adults. The platform utilizes cutting-edge artificial intelligence to provide personalized practices and make speech therapy more engaging, convenient, and affordable. With a team of 250+ licensed and experienced therapists, Better Speech aims to help individuals of all ages improve their communication skills from the comfort of their homes. The platform offers unlimited speech practices between sessions, immediate availability, easy scheduling, and effective results comparable to in-person therapy.

SpeechForms™
SpeechForms™ is an Early Childhood Support Initiative in New York City that helps families access Early Intervention Program services for children ages 0–3. The platform provides information about developmental milestones, evaluation processes, and available services, along with practical tips for families. SpeechForms™ offers support for families facing speech and development delays, guiding them towards the right path and connecting them quickly to necessary services. The platform also assists families in accessing private speech therapy services for more flexibility and timely support.
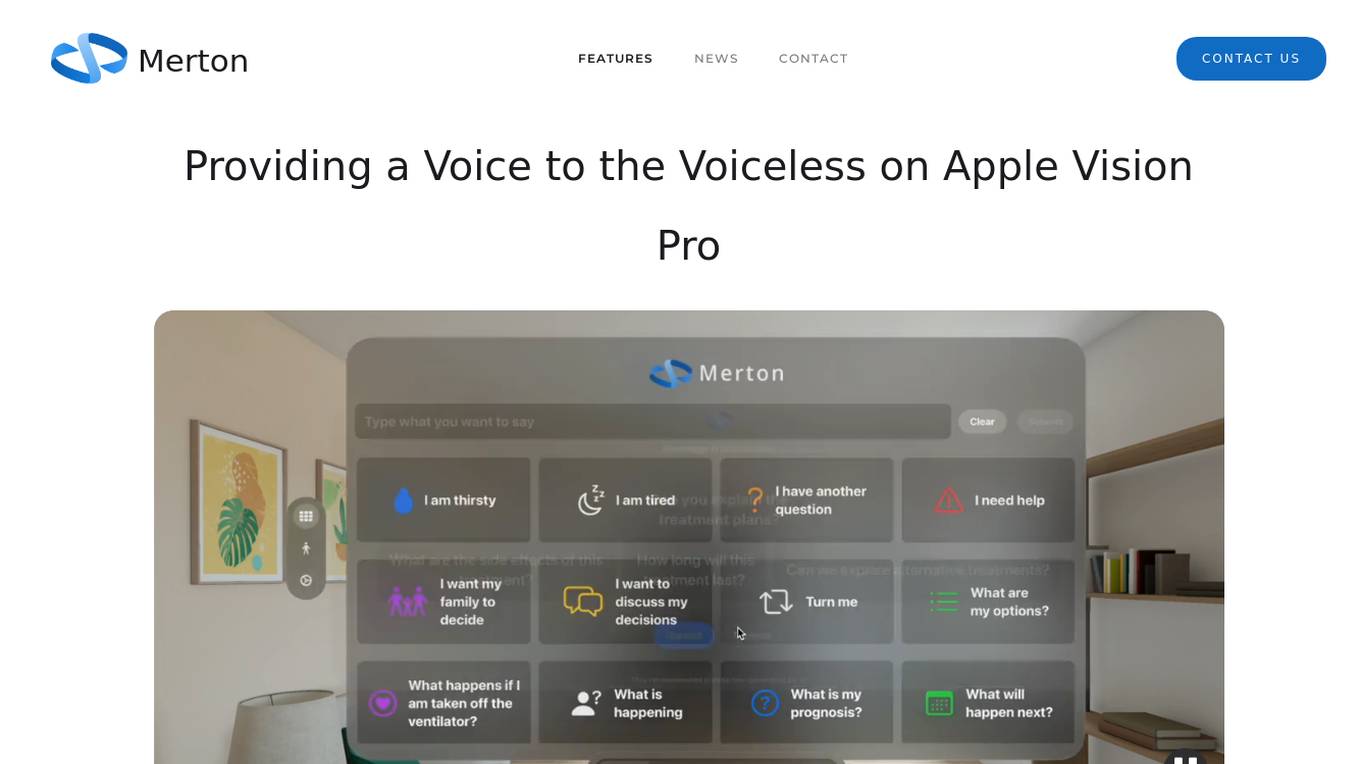
Merton
Merton is an AI-powered communication tool designed to provide a voice to the voiceless. It enables voice-impaired users to express their needs, thoughts, and feelings naturally and swiftly through a user-friendly interface. The application features an AI-powered Communication Board that predicts users' next phrases, a Pain Tracker for pinpointing areas of pain using eye movements, and prioritizes user privacy. Merton significantly enhances communication for individuals with limited or no motor functions, improving caregiving processes and response times.

Pronounce
Pronounce is an AI-powered English speech checker designed for professionals, educators, language learners, and speech therapists. It offers instant feedback and multiple drills to help users master speaking skills, understand specific communication challenges, and track therapy progress. With features like AI-powered speech feedback, English speaking partner, confident communication tips, pronunciation correction, and vocabulary enhancement, Pronounce aims to improve users' English pronunciation, grammar, and fluency. The application provides a user-friendly interface and visually appealing experience, making it suitable for beginners and advanced speakers alike.

Vocalo
Vocalo is an AI-powered language learning platform that helps users become fluent English speakers through personalized, interactive conversations with AI-powered virtual assistants. The platform uses advanced speech recognition and natural language processing technologies to provide real-time feedback and personalized learning experiences. Vocalo offers a variety of features to help users improve their English skills, including interactive lessons, personalized feedback, and a speech recognition engine that helps users improve their pronunciation.
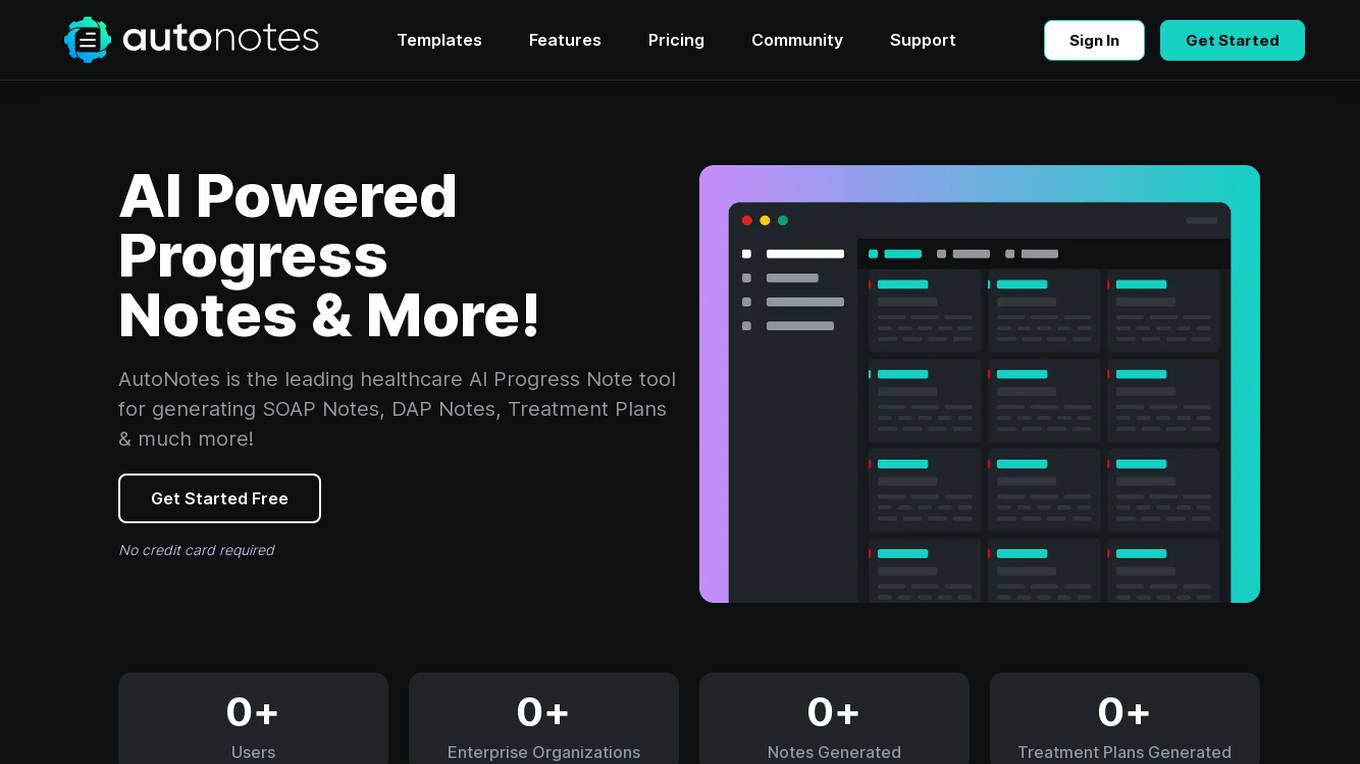
AutoNotes
AutoNotes is a leading healthcare AI Progress Note tool that offers AI-powered clinical documentation templates for generating SOAP Notes, DAP Notes, Treatment Plans, and more. It provides a user-friendly interface for therapists and healthcare professionals to create detailed and customizable clinical notes efficiently. With features like summarizing sessions, editing and downloading notes, and simple pricing plans, AutoNotes aims to streamline the documentation process in healthcare settings. The platform also offers advanced features like template customization, secure document storage, and dictation for voice-to-text conversion. Users can benefit from the platform's customization options, seamless integration with workflows, and responsive customer support.
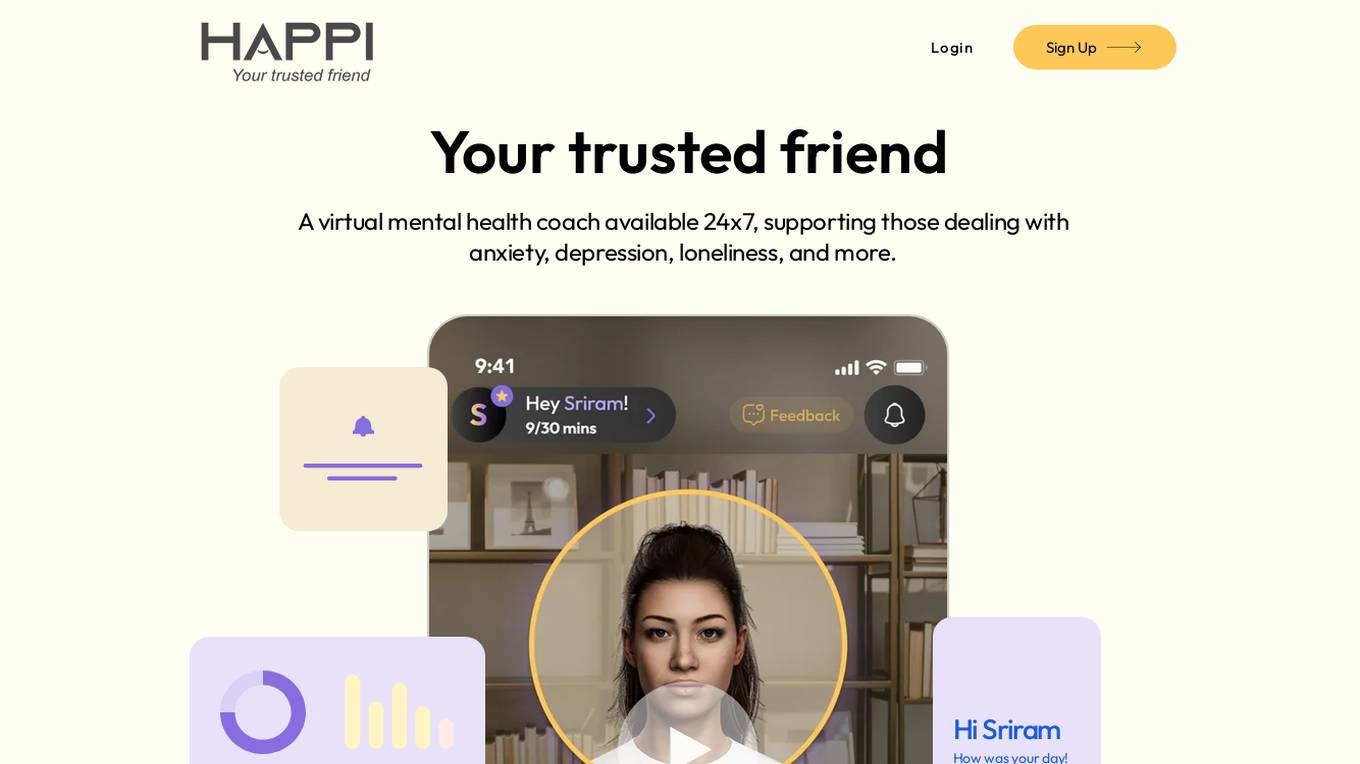
Happi.ai
Happi.ai is a virtual mental health coach application that provides 24/7 support for individuals dealing with anxiety, depression, and loneliness. The AI companion, Olivia, offers personalized assistance, compassionate listening, and non-judgmental support. The platform prioritizes user privacy with top-tier encryption and offers expert insights and proactive suggestions for emotional well-being. Happi analyzes facial expressions, voice patterns, and speech content to identify moments of stress and provide real-time feedback to manage stress and improve emotional health.

Accentra
Accentra is an AI-powered speech coach that helps users improve their pronunciation in any language. It provides real-time feedback and personalized exercises tailored to the user's native tongue. Accentra's advanced technology analyzes speech patterns and offers tailored advice to help users retrain the way they move their mouths to make sounds. With Accentra, users can hear native speakers pronounce words and receive instant pronunciation analysis to correct and redefine their skills.

Tilde.ai
Tilde.ai is a language technology platform that offers a wide range of AI-powered solutions for translation, speech technologies, and conversational AI. It combines human and artificial intelligence to help people connect and work efficiently. The platform provides machine translation, speech-to-text conversion, text-to-speech synthesis, real-time transcription, AI chatbots, internal knowledge assistants, and meeting support services. Tilde.ai aims to bridge language barriers and enhance communication by leveraging advanced language technologies.
BookHero
BookHero is an online platform that provides parents with a library of over 100 books to read to their children. Parents can also create their own books in just minutes using BookHero's WordPics illustrations. WordPics are beautiful illustrations that help children improve their vocabulary and spelling.
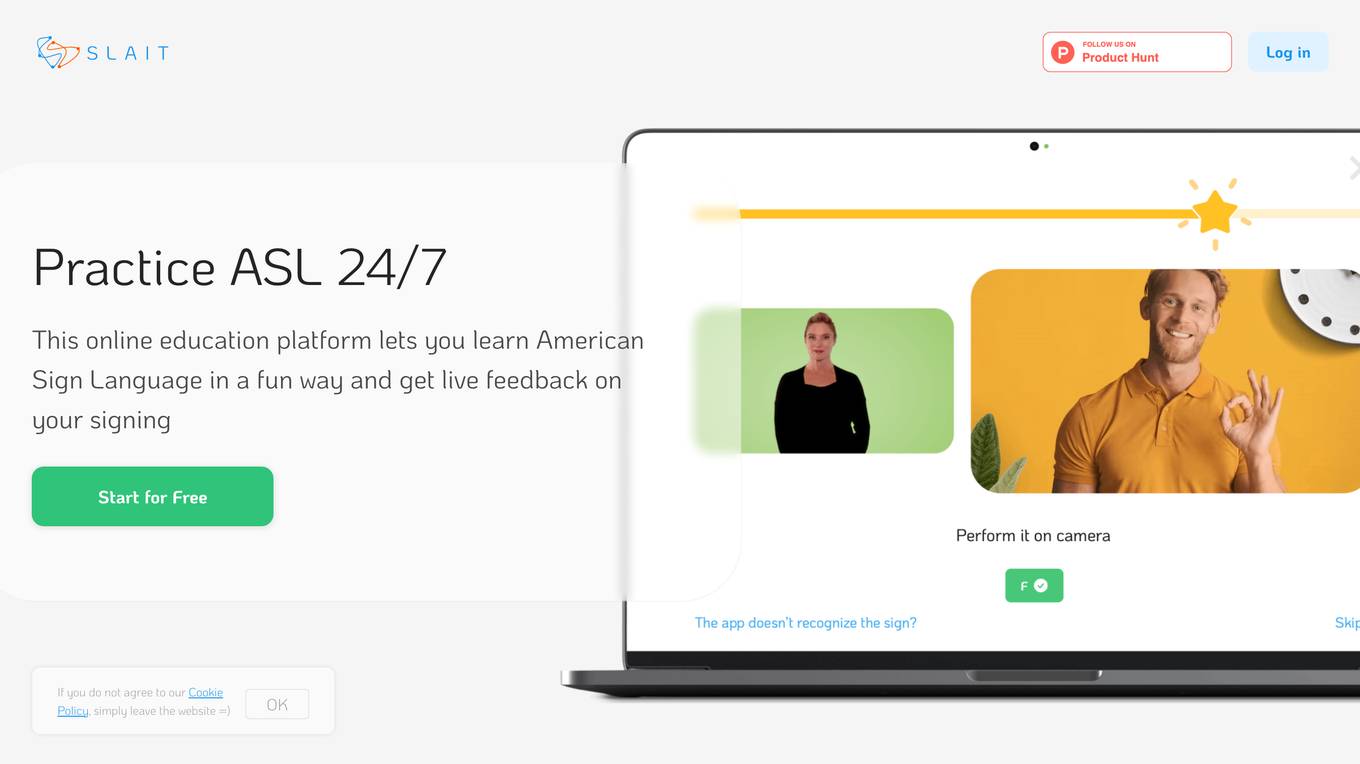
SLAIT School
SLAIT School is an online education platform that offers the opportunity to learn American Sign Language in an interactive and engaging manner. Users can practice ASL 24/7, receive live feedback on their signing, participate in cool quizzes, and take interactive tests to improve their skills. The platform also provides free lessons, premium subscription options, and a full curriculum for comprehensive learning.
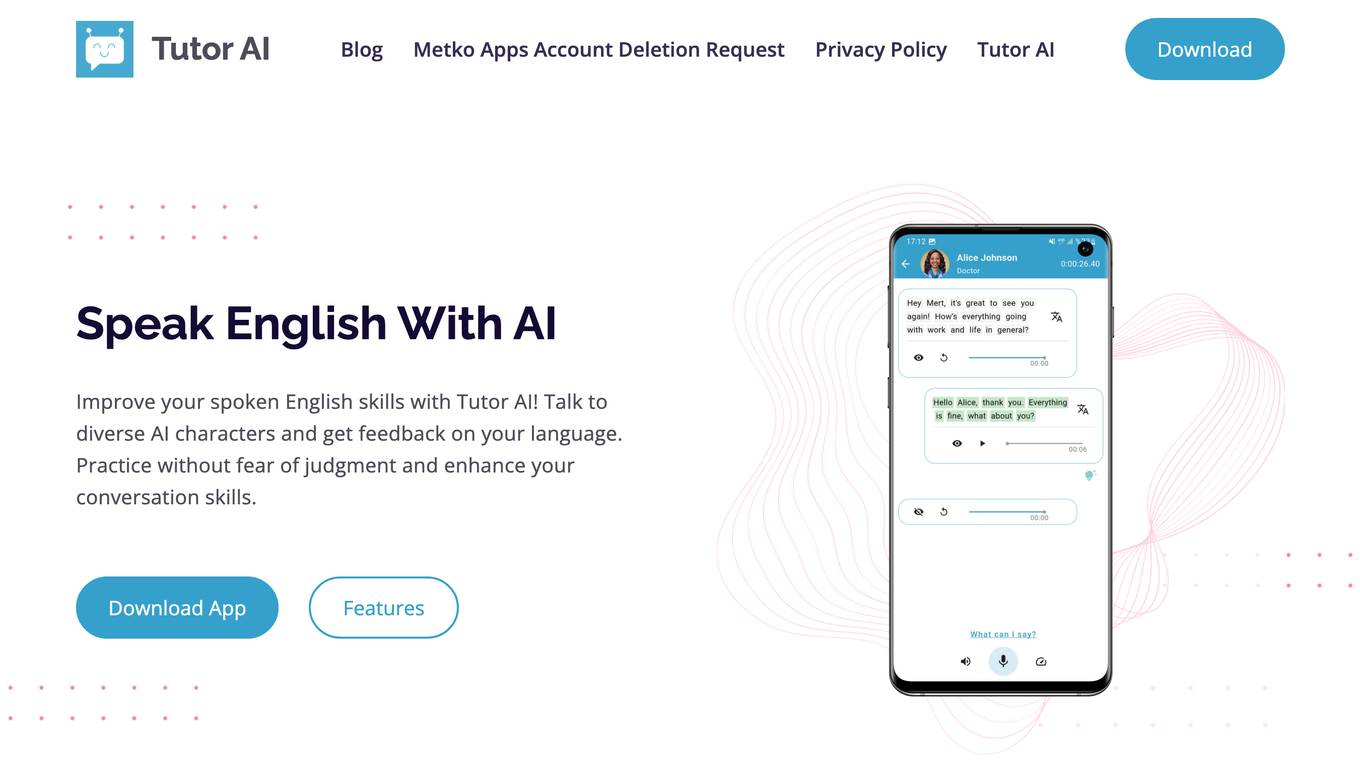
Tutor AI
Tutor AI is an AI English-speaking application designed to assist individuals in practicing their spoken English skills with the aid of an artificial intelligence chatbot. The app offers a safe and judgment-free environment for users to engage in free-flowing, natural conversations with diverse AI characters. It provides real-time feedback, suggests better ways to express oneself, and offers adjustable features to enhance the learning experience. Tutor AI aims to improve users' spoken English skills confidently and effectively through personalized lessons and interactive learning.
Synthesis
Synthesis is a web-based application that allows users to create realistic-sounding synthetic speech from text. The application uses a variety of AI techniques, including natural language processing and machine learning, to generate speech that is both natural-sounding and easy to understand. Synthesis can be used for a variety of purposes, including creating voiceovers for videos, podcasts, and presentations.
Beepbooply
Beepbooply is a text-to-speech tool that uses artificial intelligence to generate realistic and natural-sounding speech. With over 900 voices to choose from, you can create audio content for any purpose, including videos, podcasts, and customer service. Beepbooply is easy to use and affordable, making it a great option for anyone who needs to create high-quality audio content.
Lingvanex
Lingvanex is a cloud-based machine translation and speech recognition platform that provides businesses with a variety of tools to translate text, documents, and speech in over 100 languages. The platform is powered by artificial intelligence (AI) and machine learning (ML) technologies, which enable it to deliver high-quality translations that are both accurate and fluent. Lingvanex also offers a variety of features that make it easy for businesses to integrate translation and speech recognition into their workflows, including APIs, SDKs, and plugins for popular programming languages and platforms.

Error 404 Not Found
The website displays a '404: NOT_FOUND' error message indicating that the deployment cannot be found. It provides a code 'DEPLOYMENT_NOT_FOUND' and an ID 'sin1::t6mdp-1736442717535-3a5d4eeaf597'. Users are directed to refer to the documentation for further information and troubleshooting.
AudioCodes VoiceAI Connect
AudioCodes VoiceAI Connect is a cloud-based platform that enables developers to build and deploy voicebots. It provides a range of features, including connectivity to any contact center or SIP trunk, support for any speech engine or bot framework, and the ability to reduce the cost of speech services by up to 40%. VoiceAI Connect is available as a fully managed service (Enterprise edition) and as a self-service SaaS solution (AudioCodes Live Hub) to support any deployment, integration, or regulatory needs.
VoiceCanvas
VoiceCanvas is an advanced AI-powered multilingual voice synthesis and voice cloning platform that offers instant text-to-speech in over 40 languages. It utilizes cutting-edge AI technology to provide high-quality voice synthesis with natural intonation and rhythm, along with personalized voice cloning for more human-like AI speech. Users can upload voice samples, have AI analyze voice features, generate personalized AI voice models, input text for conversion, and apply the cloned AI voice model to generate natural voice speech. VoiceCanvas is highly praised by language learners, content creators, teachers, business owners, voice actors, and educators for its exceptional voice quality, multiple language support, and ease of use in creating voiceovers, learning materials, and podcast content.
OneAudio
OneAudio is an AI-powered tool that allows users to summarize, transcribe, and convert audio files into notes. With features like recording, summarization, and language selection, OneAudio helps users organize and transform their ideas efficiently. The tool leverages OpenAI GPT-4 and GPT-4o models to provide accurate transcriptions and summaries. Users can choose from different pricing plans based on their needs, from a free tier to a premium plan with unlimited features. OneAudio is designed to streamline the process of converting audio content into written notes, making it ideal for students, professionals, and anyone looking to enhance their productivity.
Seasalt.ai
Seasalt.ai is a conversation experience platform that uses generative AI and speech recognition to help businesses communicate with their customers more effectively. It offers a range of products, including SeaX, SeaChat, SeaMeet, and SeaVoice, which can be used for a variety of purposes, such as marketing campaigns, customer service, and sales. Seasalt.ai's mission is to help businesses capture, generate, and understand all text and voice conversations for their business.
0 - Open Source AI Tools
20 - OpenAI Gpts
Dedicated Speech-Language Pathologist
Expert Speech-Language Pathologist offering tailored medical consultations.




Child Literacy Booster
Aids in developing literacy in children with engaging reading activities, storytelling techniques, and parental guidance.

Bilingual Storyteller
I narrate bilingual stories for young children, focusing on language and cognitive skills.

Chat with GPT 4o ("Omni") Assistant
Try the new AI chat model: GPT 4o ("Omni") Assistant. It's faster and better than regular GPT. Plus it will incorporate speech-to-text, intelligence, and speech-to-text capabilities with extra low latency.
GPTrump
the best, the greatest replies from honestly one of the best leaders the world has ever seen
ModiGPT
GPT, drawing inspiration from Narendra Modi, delves into the myriad of government initiatives led by him, alongside insights into his personal journey.