Best AI tools for< Process Text Data >
20 - AI tool Sites
Datasaur
Datasaur is an advanced text and audio data labeling platform that offers customizable solutions for various industries such as LegalTech, Healthcare, Financial, Media, e-Commerce, and Government. It provides features like configurable annotation, quality control automation, and workforce management to enhance the efficiency of NLP and LLM projects. Datasaur prioritizes data security with military-grade practices and offers seamless integrations with AWS and other technologies. The platform aims to streamline the data labeling process, allowing engineers to focus on creating high-quality models.
Taylor
Taylor is a deterministic AI tool that empowers Business & Engineering teams to enhance data at scale through bulk classification. It offers a Control Panel for Text Enrichment, enabling users to structure freeform text, enrich metadata, and customize enrichments according to their needs. Taylor's high impact, easy-to-use platform allows for total control over classification and extraction models, driving business impact from day one. With powerful integrations and the ability to integrate with various tools, Taylor simplifies the process of wrangling unstructured text data.

AI2Page
AI2Page is an advanced AI tool that allows users to easily convert text into structured JSON objects. With its intuitive interface and powerful algorithms, AI2Page simplifies the process of analyzing and extracting information from text data. Users can simply input text, and AI2Page will automatically generate structured JSON output, making it ideal for data extraction, content analysis, and information retrieval tasks. The tool is designed to be user-friendly and efficient, catering to both beginners and experienced users in the field of data analysis and AI applications.
expert.ai
expert.ai is an AI platform that offers natural language technologies and responsible AI integrations across various industries such as insurance, banking, publishing, and more. The platform helps streamline operations, extract critical data, drive revelations, ensure compliance, and deliver key information for businesses. With a focus on responsible AI, expert.ai provides solutions for insurers, pharmaceuticals, publishers, and financial services companies to reduce errors, save time, lower costs, and accelerate intelligent process automation.
Galaxy.ai
Galaxy.ai is an all-in-one AI platform that offers a wide range of AI tools and applications to streamline and enhance various business processes. From data analysis to predictive modeling, Galaxy.ai provides advanced AI solutions to help businesses make data-driven decisions and improve efficiency. With its user-friendly interface and powerful algorithms, Galaxy.ai is designed to cater to the needs of both small businesses and large enterprises, making AI technology accessible and easy to implement.
Innovatiana
Innovatiana is a data labeling outsourcing platform that offers high-quality datasets for artificial intelligence models. They specialize in image, audio/video, and text data labeling tasks, providing ethical outsourcing with a focus on impact and transparency. Innovatiana recruits and trains their own team in Madagascar, ensuring fair pay and good working conditions. They offer competitive rates, secure data handling, and high-quality labeled data to feed AI models. The platform supports various AI tasks such as Computer Vision, Data Collection, Data Moderation, Documents Processing, and Natural Language Processing.
Honeybear.ai
Honeybear.ai is an AI tool designed to simplify document reading tasks. It utilizes advanced algorithms to extract and analyze text from various documents, making it easier for users to access and comprehend information. With Honeybear.ai, users can streamline their document processing workflows and enhance productivity.
PyAI
PyAI is an advanced AI tool designed for developers and data scientists to streamline their workflow and enhance productivity. It offers a wide range of AI capabilities, including machine learning algorithms, natural language processing, computer vision, and more. With PyAI, users can easily build, train, and deploy AI models for various applications, such as predictive analytics, image recognition, and text classification. The tool provides a user-friendly interface and comprehensive documentation to support users at every stage of their AI projects.
BabblerAI
BabblerAI is an advanced artificial intelligence tool designed to assist businesses in analyzing and extracting valuable insights from large volumes of text data. The application utilizes natural language processing and machine learning algorithms to provide users with actionable intelligence and automate the process of information extraction. With BabblerAI, users can streamline their data analysis workflows, uncover trends and patterns, and make data-driven decisions with confidence. The tool is user-friendly and offers a range of features to enhance productivity and efficiency in data analysis tasks.

RegexBot
RegexBot is an AI-powered Regex Builder that allows users to test and convert natural language into powerful regular expressions effortlessly. It leverages the power of AI to help users master regular expressions by providing tools to match specific patterns like URLs, email addresses, ZIP codes, and words containing only uppercase letters. With a user-friendly interface, RegexBot simplifies the process of creating and validating regular expressions, making it a valuable tool for developers, data analysts, and anyone working with text data.
Isomeric
Isomeric is an AI tool that utilizes artificial intelligence to semantically understand unstructured text and extract specific data. It transforms messy, unstructured text into machine-readable JSON, enabling users to extract insights, process data, deliver results, and more. From web scraping to browser extensions to general information extraction, Isomeric helps users scale their data gathering pipeline efficiently.
Enwrite
Enwrite is an AI-powered writing tool that helps you create high-quality content quickly and easily. With Enwrite, you can generate articles, blog posts, social media posts, and more, in just a few clicks. Enwrite's AI engine is trained on a massive dataset of text, so it can generate content that is both informative and engaging.
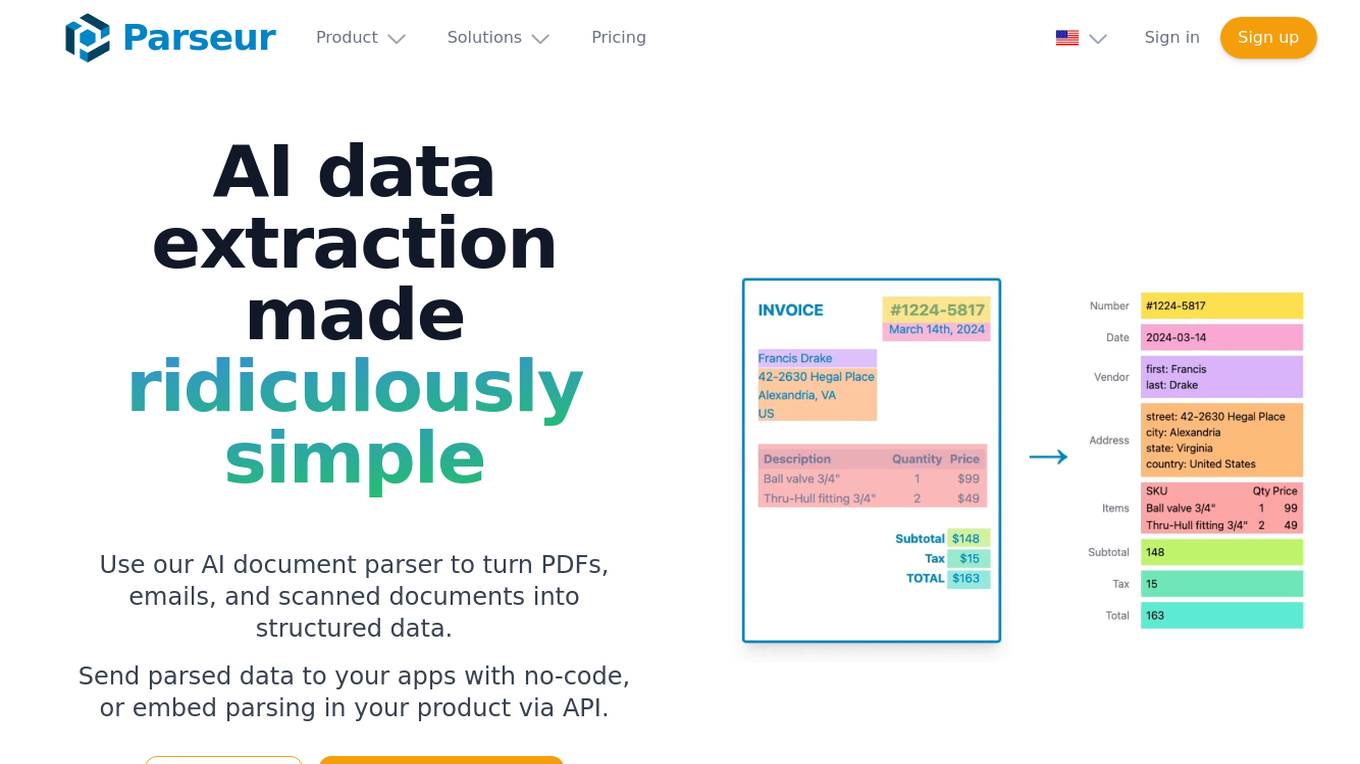
Parseur
Parseur is an AI data extraction software that uses artificial intelligence to extract structured data from various types of documents such as PDFs, emails, and scanned documents. It offers features like template-based data extraction, OCR software for character recognition, and dynamic OCR for extracting fields that move or change size. Parseur is trusted by businesses in finance, tech, logistics, healthcare, real estate, e-commerce, marketing, and human resources industries to automate data extraction processes, saving time and reducing manual errors.
Picture to Text Converter
Picture to Text Converter is an online tool that uses Optical Character Recognition (OCR) technology to extract text from images. It can process various image formats like JPG, PNG, GIF, scanned documents (PDFs), and even photos taken with your phone's camera. The extracted text can be copied to the clipboard or downloaded as a TXT file. Picture to Text Converter is free to use and does not require any registration or installation. It is a convenient and efficient way to convert images into editable text.
UBIAI
UBIAI is a powerful text annotation tool that helps businesses accelerate their data labeling process. With UBIAI, businesses can annotate any type of document, including PDFs, images, and text. UBIAI also offers a variety of features to make the annotation process easier and more efficient, such as auto-labeling, multi-lingual annotation, and team collaboration. With UBIAI, businesses can save time and money on their data labeling projects.
Crustdata Watcher API
Crustdata Watcher API is a real-time B2B data broker providing live signals on key people and accounts. It offers the freshest and most trusted data to power any product or sales process. The platform delivers real-time company and people data for commercial and internal platforms, enabling users to keep their CRM, investment platform, or ATS up to date. Additionally, it provides live alerts on changes to people and companies, empowering AI platforms and agents with specialized data tailored for the future.
Prosetta
Prosetta is an advanced AI tool designed to assist users in analyzing and extracting insights from large datasets. It utilizes cutting-edge machine learning algorithms to provide accurate predictions and recommendations. With Prosetta, users can streamline their data analysis process, uncover hidden patterns, and make data-driven decisions with confidence. The tool offers a user-friendly interface, making it accessible to both data experts and beginners. Prosetta is a versatile solution suitable for various industries, including finance, healthcare, marketing, and more.
CopyClick
CopyClick is an AI tool designed to simplify the process of copying and pasting text from websites and apps. It allows users to easily extract text from any website or app in plain format, making it convenient for use in ChatGPT or Claude. With CopyClick, users can quickly transfer text without any formatting issues, enhancing their workflow efficiency.
Picovoice
Picovoice is an on-device Voice AI and local LLM platform designed for enterprises. It offers a range of voice AI and LLM solutions, including speech-to-text, noise suppression, speaker recognition, speech-to-index, wake word detection, and more. Picovoice empowers developers to build virtual assistants and AI-powered products with compliance, reliability, and scalability in mind. The platform allows enterprises to process data locally without relying on third-party remote servers, ensuring data privacy and security. With a focus on cutting-edge AI technology, Picovoice enables users to stay ahead of the curve and adapt quickly to changing customer needs.
Token Counter
Token Counter is an AI tool designed to convert text input into tokens for various AI models. It helps users accurately determine the token count and associated costs when working with AI models. By providing insights into tokenization strategies and cost structures, Token Counter streamlines the process of utilizing advanced technologies.
2 - Open Source AI Tools

LlamaIndexTS
LlamaIndex.TS is a data framework for your LLM application. Use your own data with large language models (LLMs, OpenAI ChatGPT and others) in Typescript and Javascript.
llmstxt-generator
llms.txt Generator is a tool designed for LLM (Legal Language Model) training and inference. It crawls websites to combine content into consolidated text files, offering both standard and full versions. Users can access the tool through a web interface or API without requiring an API key. Powered by Firecrawl for web crawling and GPT-4-mini for text processing.
20 - OpenAI Gpts
QCM
ce GPT va recevoir des images dans lesquelles il y a des questions QCM codingame ou Problem Solving sur les sujets : Java, Hibernate, Angular, Spring Boot, SQL. Il doit extraire le texte depuis l'image et répondre au question QCM le plus rapidement possible.

kz image 2 typescript 2 image
Generate a Structured description in typescript format from the image and generate an image from that description. and OCR
Notes Master
With this bot process of making notes will be easier. Send your text and wait for the result

Volkseigene GPT
Ich beantworte Anfragen, Anträge und Eingaben von Bürgerinnen und Bürgern der DDR.
Whitehead's Concept of Nature
A scholarly guide to Whitehead's early work in 'The Concept of Nature'.
Process Map Optimizer
Upload your process map and I will analyse and suggest improvements
Process Engineering Advisor
Optimizes production processes for improved efficiency and quality.
Customer Service Process Improvement Advisor
Optimizes business operations through process enhancements.

R&D Process Scale-up Advisor
Optimizes production processes for efficient large-scale operations.
Process Optimization Advisor
Improves operational efficiency by optimizing processes and reducing waste.


Manufacturing Process Development Advisor
Optimizes manufacturing processes for efficiency and quality.
