Best AI tools for< Partition Gpus >
1 - AI tool Sites
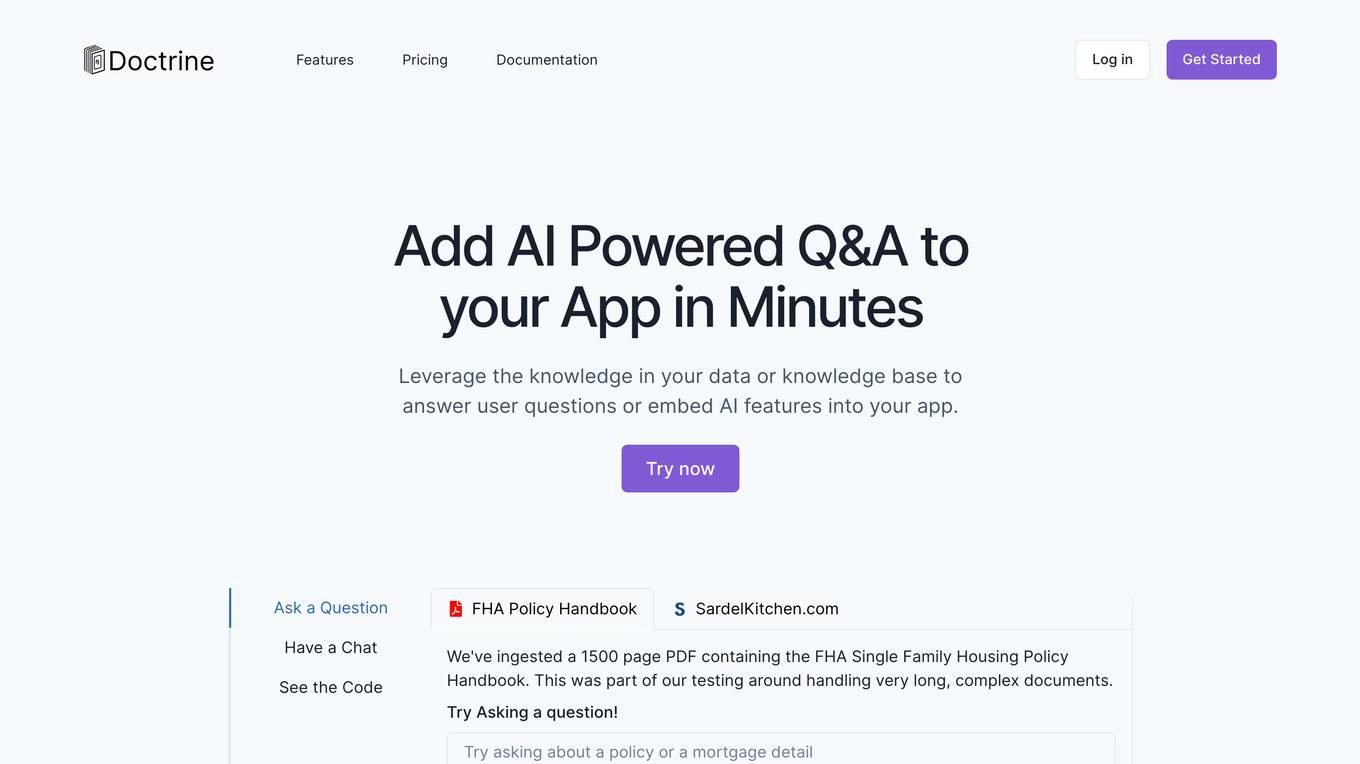
Doctrine
Doctrine is an AI-powered application that allows users to add AI-powered Q&A features to their apps in minutes. It leverages knowledge from data or knowledge bases to answer user questions or embed AI features. With the ability to ingest content from various sources like websites, documents, and images, Doctrine simplifies the process of knowledge extraction and enables seamless integration of AI capabilities into applications.
1 - Open Source AI Tools
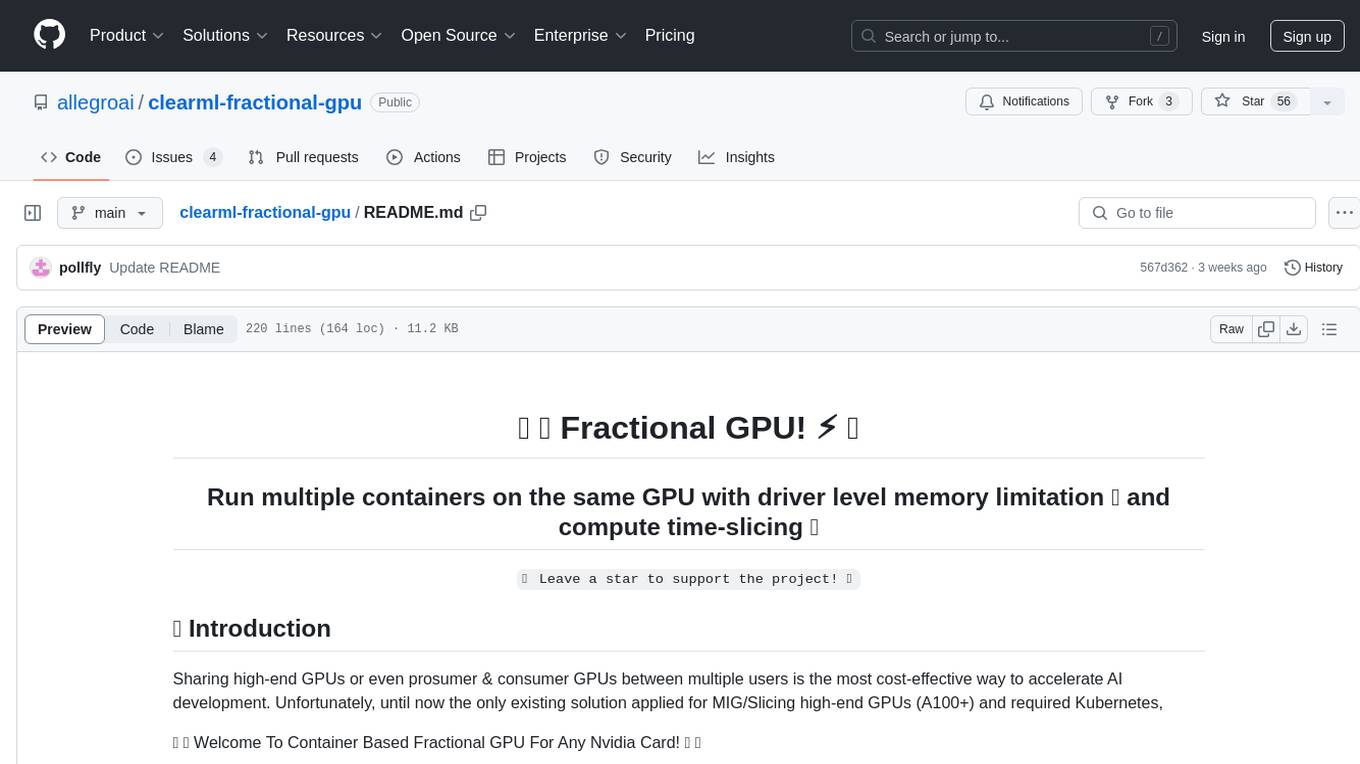
clearml-fractional-gpu
ClearML Fractional GPU is a tool designed to optimize GPU resource utilization by allowing multiple containers to run on the same GPU with driver-level memory limitation and compute time-slicing. It supports CUDA 11.x & CUDA 12.x, preventing greedy processes from grabbing the entire GPU memory. The tool offers options like Dynamic GPU Slicing, Container-based Memory Limits, and Kubernetes-based Static MIG Slicing to enhance hardware utilization and workload performance for AI development.