Best AI tools for< Parse Pdf >
20 - AI tool Sites
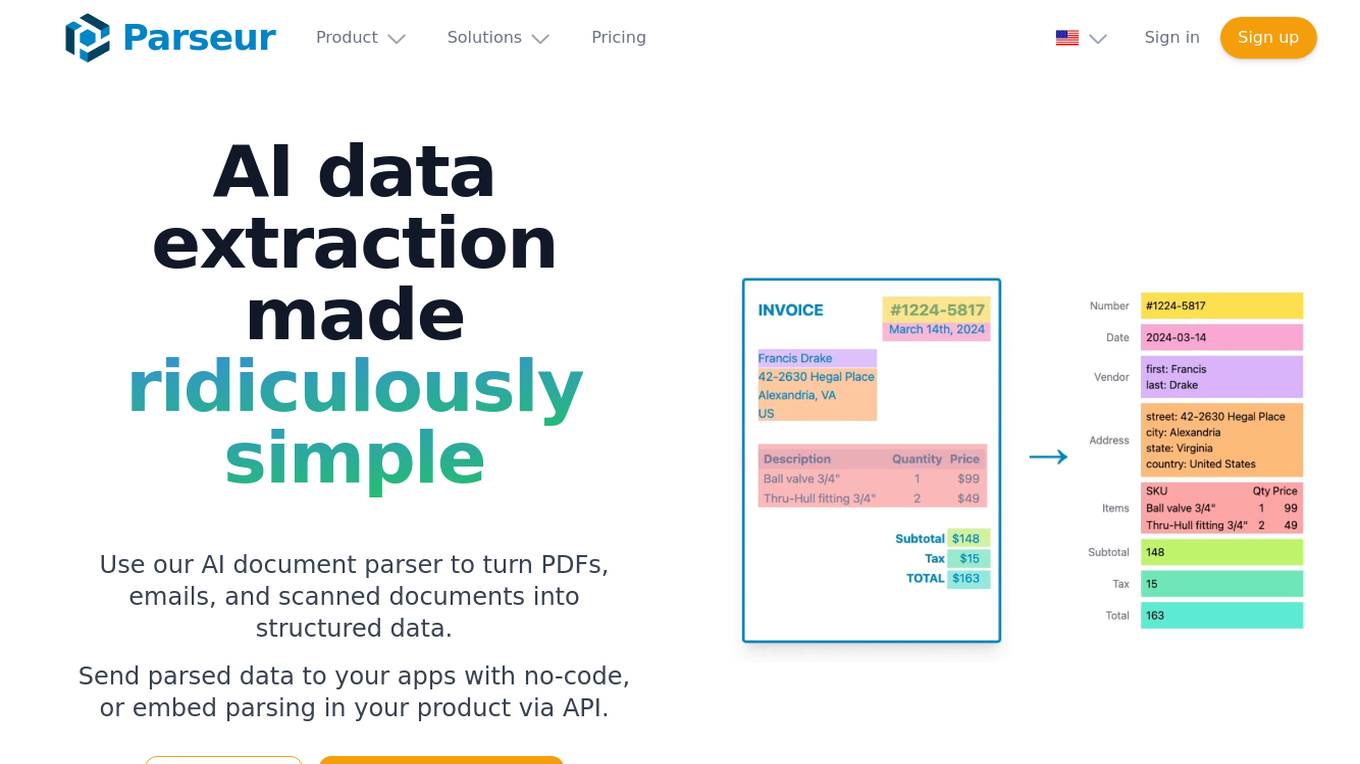
Parseur
Parseur is an AI data extraction software that uses artificial intelligence to extract structured data from various types of documents such as PDFs, emails, and scanned documents. It offers features like template-based data extraction, OCR software for character recognition, and dynamic OCR for extracting fields that move or change size. Parseur is trusted by businesses in finance, tech, logistics, healthcare, real estate, e-commerce, marketing, and human resources industries to automate data extraction processes, saving time and reducing manual errors.
AI Resume Tailor
AI Resume Tailor is an AI-powered application designed to help job seekers create customized resumes tailored to each job description. It offers features such as resume parsing, AI-powered resume building, PDF formatting, privacy protection, and ATS-friendly templates. The platform ensures that users can easily create professional resumes that stand out to potential employers, increasing their chances of getting hired.
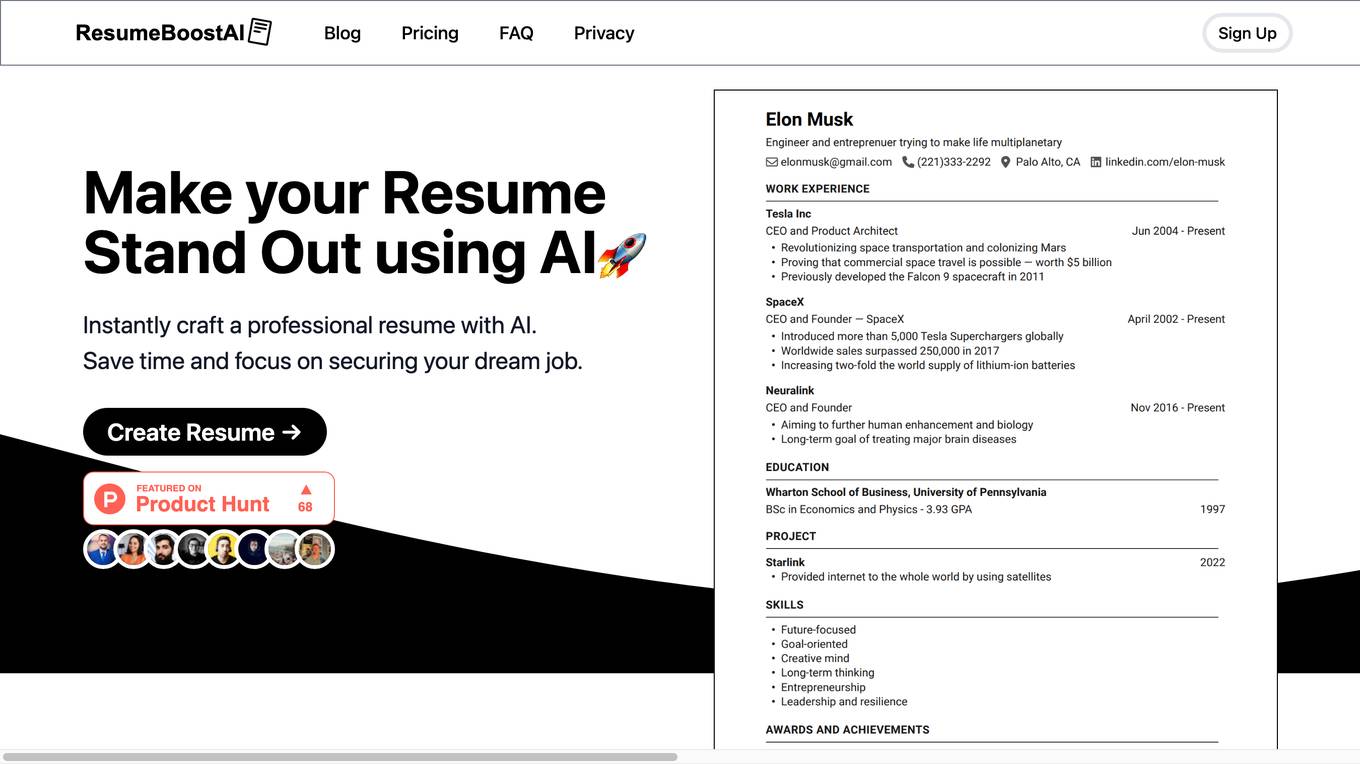
ResumeBoostAI
ResumeBoostAI is a free AI resume builder that helps job seekers create professional resumes and cover letters quickly and efficiently. With AI-powered features like resume summary generator, bullet point generator, cover letter generator, and ATS-friendly templates, users can save time and land their dream jobs. The platform offers privacy-first services, PDF format downloads, resume parsing, and compatibility with Applicant Tracking Systems (ATS). ResumeBoostAI is trusted by top professionals and loved by over 22,000 job seekers for its intuitive interface and time-saving capabilities.
Airparser
Airparser is an AI-powered email and document parser tool that revolutionizes data extraction by utilizing the GPT parser engine. It allows users to automate the extraction of structured data from various sources such as emails, PDFs, documents, and handwritten texts. With features like automatic extraction, export to multiple platforms, and support for multiple languages, Airparser simplifies data extraction processes for individuals and businesses. The tool ensures data security and offers seamless integration with other applications through APIs and webhooks.
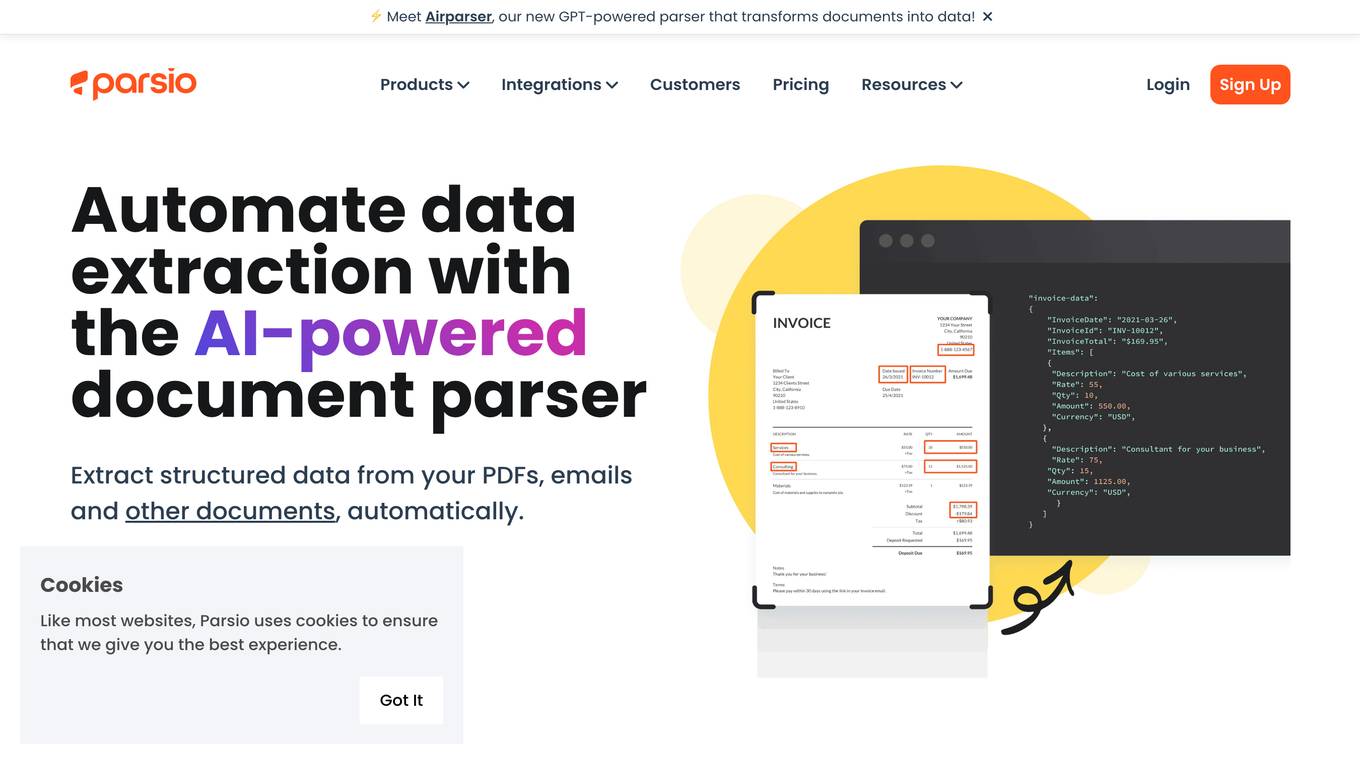
Parsio
Parsio is an AI-powered document parser that can extract structured data from PDFs, emails, and other documents. It uses natural language processing to understand the context of the document and identify the relevant data points. Parsio can be used to automate a variety of tasks, such as extracting data from invoices, receipts, and emails.

Daxtra
Daxtra is an AI-powered recruitment technology tool designed to help staffing and recruiting professionals find, parse, match, and engage the best candidates quickly and efficiently. The tool offers a suite of products that seamlessly integrate with existing ATS or CRM systems, automating various recruitment processes such as candidate data loading, CV/resume formatting, information extraction, and job matching. Daxtra's solutions cater to corporates, vendors, job boards, and social media partners, providing a comprehensive set of developer components to enhance recruitment workflows.
Extracta.ai
Extracta.ai is an AI data extraction tool for documents and images that automates data extraction processes with easy integration. It allows users to define custom templates for extracting structured data without the need for training. The platform can extract data from various document types, including invoices, resumes, contracts, receipts, and more, providing accurate and efficient results. Extracta.ai ensures data security, encryption, and GDPR compliance, making it a reliable solution for businesses looking to streamline document processing.
HrFlow.ai
HrFlow.ai is an API-first company and the leading AI-powered HR data automation platform. The company helps +1000 customers (HR software vendors, Staffing agencies, large employers, and headhunting firms) to thrive in a high-volume and high-frequency labor market. The platform provides a complete and fully integrated suite of HR data processing products based on the analysis of hundreds of millions of career paths worldwide -- such as Parsing API, Tagging API, Embedding API, Searching API, Scoring API, and Upskilling API. It also offers a catalog of +200 connectors to build custom scenarios that can automate any business logic.
Recrew AI
Recrew AI is an AI-powered recruitment tool that revolutionizes the hiring process by leveraging artificial intelligence to parse resumes, match candidates, and build a diverse candidate pipeline in minutes. It helps recruiters overcome challenges such as sorting profiles, extracting accurate data, reducing lean time, identifying top talent, expanding talent pools, and making data-driven hiring decisions. Recrew AI aims to streamline recruitment processes, eliminate manual errors, reduce bias, and enhance overall efficiency in the recruitment industry.

Robo Rat
Robo Rat is an AI-powered tool designed for business document digitization. It offers a smart and affordable resume parsing API that supports over 50 languages, enabling quick conversion of resumes into actionable data. The tool aims to simplify the hiring process by providing speed and accuracy in parsing resumes. With advanced AI capabilities, Robo Rat delivers highly accurate and intelligent resume parsing solutions, making it a valuable asset for businesses of all sizes.

NLTK
NLTK (Natural Language Toolkit) is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum. Thanks to a hands-on guide introducing programming fundamentals alongside topics in computational linguistics, plus comprehensive API documentation, NLTK is suitable for linguists, engineers, students, educators, researchers, and industry users alike.
Bind AI
Bind AI is an advanced AI tool that enables users to generate code, scripts, and applications using a variety of AI models. It offers a platform with a built-in code editor and supports over 72 programming languages, including popular ones like Python, Java, and JavaScript. Users can create front-end web applications, parse JSON, write SQL queries, and automate tasks using the AI Code Editor. Bind AI also provides integration with Github and Google Drive, allowing users to sync their codebase and files for collaboration and development.
JADBio
JADBio is an automated machine learning (AutoML) platform designed to accelerate biomarker discovery and drug development processes. It offers a no-code solution that automates the discovery of biomarkers and interprets their role based on research needs. JADBio can parse multi-omics data, including genomics, transcriptome, metagenome, proteome, metabolome, phenotype/clinical data, and images, enabling users to efficiently discover insights for various conditions such as cancer, immune system disorders, chronic diseases, infectious diseases, and mental health. The platform is trusted by partners in precision health and medicine and is continuously evolving to disrupt drug discovery times and costs at all stages.

Whitetable
Whitetable is an AI tool that simplifies the hiring process by providing intelligent AI APIs for ultra-fast and optimal hiring. It offers features such as Resume Parsing API, Question API, Ranking API, and Evaluation API to streamline the recruitment process. Whitetable also provides a free AI-powered job search platform and an AI-powered ATS to help companies find the right candidates faster. With a focus on eliminating bias and improving efficiency, Whitetable is shaping the AI-driven future of hiring.
Explosion
Explosion is a software company specializing in developer tools and tailored solutions for AI, Machine Learning, and Natural Language Processing (NLP). They are the makers of spaCy, one of the leading open-source libraries for advanced NLP. The company offers consulting services and builds developer tools for various AI-related tasks, such as coreference resolution, dependency parsing, image classification, named entity recognition, and more.
FormX.ai
FormX.ai is an AI-powered data extraction and conversion tool that automates the process of extracting data from physical documents and converting it into digital formats. It supports a wide range of document types, including invoices, receipts, purchase orders, bank statements, contracts, HR forms, shipping orders, loyalty member applications, annual reports, business certificates, personnel licenses, and more. FormX.ai's pre-configured data extraction models and effortless API integration make it easy for businesses to integrate data extraction into their existing systems and workflows. With FormX.ai, businesses can save time and money on manual data entry and improve the accuracy and efficiency of their data processing.
FileGPT
FileGPT is a powerful GPT-AI application designed to enhance your workflow by providing quick and accurate responses to your queries across various file formats. It allows users to interact with different types of files, extract text from handwritten documents, and analyze audio and video content. With FileGPT, users can say goodbye to endless scrolling and searching, and hello to a smarter, more intuitive way of working with their documents.
Imaginary Programming
Imaginary Programming is an AI tool that allows frontend developers to leverage OpenAI's GPT engine to add human-like intelligence to their code effortlessly. By defining function prototypes in TypeScript, developers can access GPT's capabilities without the need for AI model training. The tool enables users to extract structured data, generate text, classify data based on intent or emotion, and parse unstructured language. Imaginary Programming is designed to help developers tackle new challenges and enhance their projects with AI intelligence.
Rgx.tools
Rgx.tools is an AI-powered text-to-regex generator that helps users create regular expressions quickly and easily. It is a wrapper around OpenAI's gpt-3.5-chat model, which generates clean, readable, and efficient regular expressions based on user input. Rgx.tools is designed to make the process of writing regular expressions less painful and more accessible, even for those with limited experience.
Invofox API
Invofox API is a Document Parsing API designed for developers to validate fields, autocomplete data, and catch errors beyond OCR. It turns unstructured documents into clean JSON using advanced AI models and proprietary algorithms. The API provides built-in schemas for major documents and supports custom formats, allowing users to parse any document with a single API call without templates or post-processing. Invofox is used for expense management, accounts payable, logistics & supply chain, HR automation, sustainability & consumption tracking, and custom document parsing.
1 - Open Source AI Tools
e2m
E2M is a Python library that can parse and convert various file types into Markdown format. It supports the conversion of multiple file formats, including doc, docx, epub, html, htm, url, pdf, ppt, pptx, mp3, and m4a. The ultimate goal of the E2M project is to provide high-quality data for Retrieval-Augmented Generation (RAG) and model training or fine-tuning. The core architecture consists of a Parser responsible for parsing various file types into text or image data, and a Converter responsible for converting text or image data into Markdown format.
20 - OpenAI Gpts
Japanese Hiragana Advisor
This GPT is able to parse a sentence, provide an appropriate translation of the input text and be able to provide a response explaining the structure of a sentence in japanese.
Changelog Assistant
Turns any software update info into structured changelogs in imperative tense.
Quick Code Snippet Generator
Generates concise, copy-paste code snippets quickly no unnecessary text.

BioinformaticsManual
Compile instructions from the web and github for bioinformatics applications. Receive line-by-line instructions and commands to get started

Table to JSON
我們經常在看 REST API 參考文件,文件中呈現 Request/Response 參數通常都是用表格的形式,開發人員都要手動轉換成 JSON 結構,有點小麻煩,但透過這個 GPT 只要上傳截圖就可以自動產生 JSON 範例與 JSON Schema 結構。
JSON Outputter
Takes all input into consideration and creates a JSON-appropriate response. Also useful for creating templates.

GASGPT
Soy un experto en Google Apps Script que ayuda a los principiantes, hablo principalmente español.
Idea To Code GPT
Generates a full & complete Python codebase, after clarifying questions, by following a structured section pattern.



RegExp Builder
This GPT lets you build PCRE Regular Expressions (for use the RegExp constructor).
Bot Psycho - Le pervers narcissique.
Je te parle des pervers narcissique. Je t'informe de leurs traits et de leur comportement. Je t'aide à reconnaitre les signes d'une relation toxique.