Best AI tools for< Optimize Llm Configurations >
20 - AI tool Sites

Confident AI
Confident AI is an open-source evaluation infrastructure for Large Language Models (LLMs). It provides a centralized platform to judge LLM applications, ensuring substantial benefits and addressing any weaknesses in LLM implementation. With Confident AI, companies can define ground truths to ensure their LLM is behaving as expected, evaluate performance against expected outputs to pinpoint areas for iterations, and utilize advanced diff tracking to guide towards the optimal LLM stack. The platform offers comprehensive analytics to identify areas of focus and features such as A/B testing, evaluation, output classification, reporting dashboard, dataset generation, and detailed monitoring to help productionize LLMs with confidence.
deepset
deepset is an AI platform that offers enterprise-level products and solutions for AI teams. It provides deepset Cloud, a platform built with Haystack, enabling fast and accurate prototyping, building, and launching of advanced AI applications. The platform streamlines the AI application development lifecycle, offering processes, tools, and expertise to move from prototype to production efficiently. With deepset Cloud, users can optimize solution accuracy, performance, and cost, and deploy AI applications at any scale with one click. The platform also allows users to explore new models and configurations without limits, extending their team with access to world-class AI engineers for guidance and support.
Future AGI
Future AGI is a revolutionary AI data management platform that aims to achieve 99% accuracy in AI applications across software and hardware. It provides a comprehensive evaluation and optimization platform for enterprises to enhance the performance of their AI models. Future AGI offers features such as creating trustworthy, accurate, and responsible AI, 10x faster processing, generating and managing diverse synthetic datasets, testing and analyzing agentic workflow configurations, assessing agent performance, enhancing LLM application performance, monitoring and protecting applications in production, and evaluating AI across different modalities.
RagaAI Catalyst
RagaAI Catalyst is a sophisticated AI observability, monitoring, and evaluation platform designed to help users observe, evaluate, and debug AI agents at all stages of Agentic AI workflows. It offers features like visualizing trace data, instrumenting and monitoring tools and agents, enhancing AI performance, agentic testing, comprehensive trace logging, evaluation for each step of the agent, enterprise-grade experiment management, secure and reliable LLM outputs, finetuning with human feedback integration, defining custom evaluation logic, generating synthetic data, and optimizing LLM testing with speed and precision. The platform is trusted by AI leaders globally and provides a comprehensive suite of tools for AI developers and enterprises.
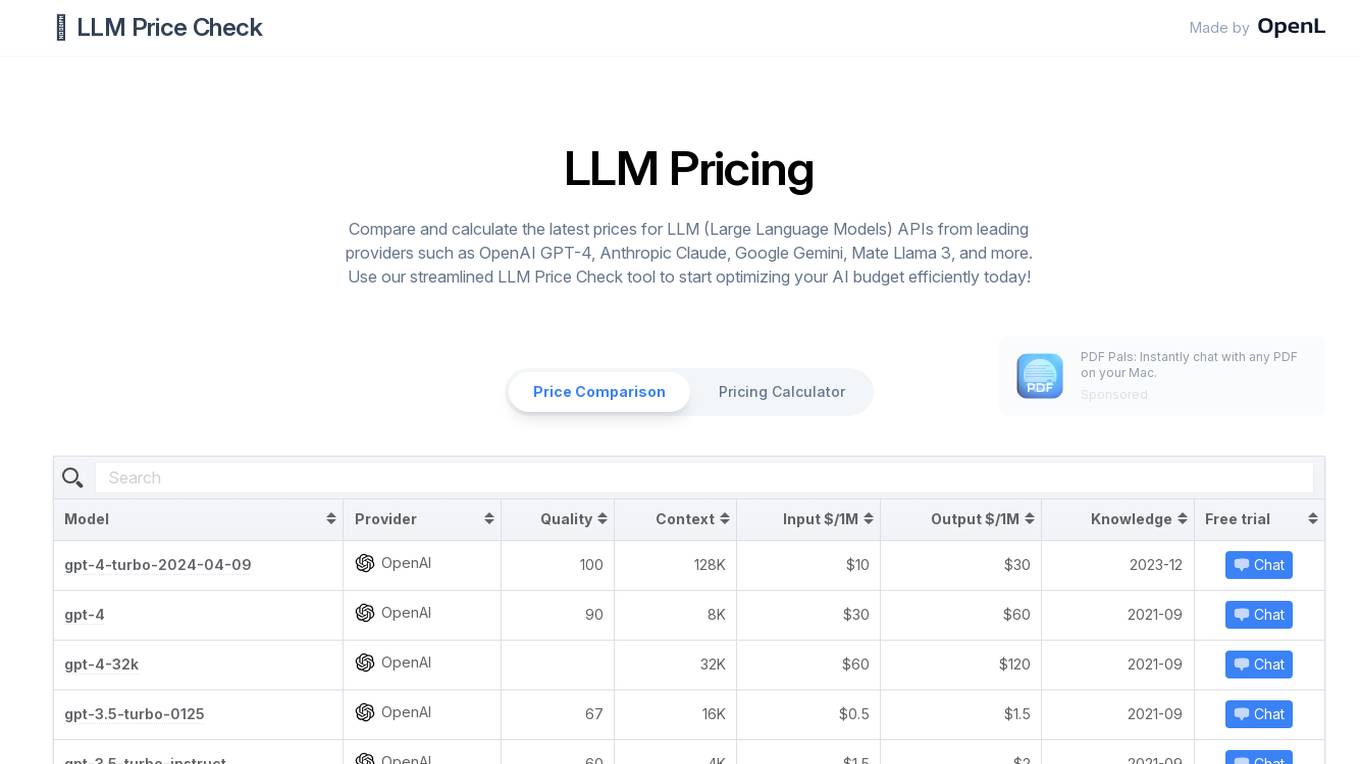
LLM Price Check
LLM Price Check is an AI tool designed to compare and calculate the latest prices for Large Language Models (LLM) APIs from leading providers such as OpenAI, Anthropic, Google, and more. Users can use the streamlined tool to optimize their AI budget efficiently by comparing pricing, sorting by various parameters, and searching for specific models. The tool provides a comprehensive overview of pricing information to help users make informed decisions when selecting an LLM API provider.
Promptech
Promptech is an AI teamspace designed to streamline workflows and enhance productivity. It offers a range of features including AI assistants, a collaborative teamspace, and access to large language models (LLMs). Promptech is suitable for businesses of all sizes and can be used for a variety of tasks such as streamlining tasks, enhancing collaboration, and safeguarding IP. It is a valuable resource for technology leaders and provides a cost-effective AI solution for smaller teams and startups.
Egaki.ai
Egaki.ai is an AI tool designed to enhance visibility in search engines and recommendations. It utilizes advanced algorithms to optimize content for better search rankings and personalized recommendations. By leveraging AI technology, Egaki.ai helps businesses and individuals increase their online presence and reach a wider audience. With its user-friendly interface and powerful features, Egaki.ai is a valuable tool for improving digital marketing strategies and maximizing online visibility.
prompter.engineer
prompter.engineer is a domain that is currently parked for free, courtesy of GoDaddy.com. The website does not provide any specific content or services at the moment, as it is not associated with any particular company, product, or service. It primarily serves as a placeholder domain registered with GoDaddy, LLC, and does not imply any endorsement or association with third-party advertisers.
Lucid Engine
Lucid Engine is an AI tool designed to optimize digital presence for better visibility in AI-generated answers. It helps users track their citations across AI search engines, benchmark competitors, and prioritize actions to improve recommendations. The tool offers features such as Visibility Audit, Competitor Radar, and Action Backlog to enhance AI visibility and competitiveness. Lucid Engine provides real-time monitoring of strategic prompts across multiple AI engines, enabling users to stay ahead of competitors and model shifts.
Weavel
Weavel is an AI tool designed to revolutionize prompt engineering for large language models (LLMs). It offers features such as tracing, dataset curation, batch testing, and evaluations to enhance the performance of LLM applications. Weavel enables users to continuously optimize prompts using real-world data, prevent performance regression with CI/CD integration, and engage in human-in-the-loop interactions for scoring and feedback. Ape, the AI prompt engineer, outperforms competitors on benchmark tests and ensures seamless integration and continuous improvement specific to each user's use case. With Weavel, users can effortlessly evaluate LLM applications without the need for pre-existing datasets, streamlining the assessment process and enhancing overall performance.
Notification Harbor
Notification Harbor is an email marketing platform that uses Large Language Models (LLMs) to help businesses create and send more effective email campaigns. With Notification Harbor, businesses can use LLMs to generate personalized email content, optimize subject lines, and even create entire email campaigns from scratch. Notification Harbor is designed to make email marketing easier and more effective for businesses of all sizes.

Unify
Unify is an AI tool that offers a unified platform for accessing and comparing various Language Models (LLMs) from different providers. It allows users to combine models for faster, cheaper, and better responses, optimizing for quality, speed, and cost-efficiency. Unify simplifies the complex task of selecting the best LLM by providing transparent benchmarks, personalized routing, and performance optimization tools.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.
Grit Brokerage
Grit Brokerage is a domain and website brokerage platform that facilitates the buying and selling of domains. The platform allows users to inquire about domain prices, submit offers, and connect with domain brokers. With a focus on domain transactions, Grit Brokerage provides a seamless experience for individuals and businesses looking to acquire or sell domain names.
Dr. Randal S. Olson
Dr. Randal S. Olson is an AI Researcher & Builder known for turning ambitious AI ideas into business wins by bridging the gap between technical promise and real-world impact. His work encompasses data science, AI engineering, and executive strategy. He has worked on various projects in AI, data science, and technology leadership, including the development of the Truesight Expert-grounded AI evaluation platform and the AutoML Tool TPOT. Dr. Olson's focus is on building privacy-first AI solutions that prioritize ethical AI development and user-centric design.
FineTuneAIs.com
FineTuneAIs.com is a platform that specializes in custom AI model fine-tuning. Users can fine-tune their AI models to achieve better performance and accuracy. The platform requires JavaScript to be enabled for optimal functionality.
Respan
Respan is an AI observability platform designed to trace, evaluate, optimize, deploy, and monitor AI agents. It provides self-driving observability and evaluations for agents, allowing users to surface issues automatically, fix problems faster, and ensure that AI behaves as intended. The platform offers features such as tracing agent behavior, evaluating system performance, optimizing prompts and tools, deploying through a single gateway, and monitoring production shifts. Respan is loved by world-class founders, engineers, and product teams for its user-friendly interface and real-time observability capabilities.
LLMWise
LLMWise is a multi-model LLM API tool that allows users to compare, blend, and route AI models simultaneously. It offers 5 modes - Chat, Compare, Blend, Judge, and Failover - to help users make informed decisions based on model outputs. With 31+ available models, LLMWise provides a user-friendly platform for orchestrating AI models, ensuring reliability, and optimizing costs. The tool is designed to streamline the integration of various AI models through one API call, offering features like real-time responses, per-model metrics, and failover routing.
Tovie AI
Tovie AI is a platform offering Generative AI and on-prem LLM solutions for enterprise applications. It provides a range of AI tools such as GenAI Agents, Data Agent, Data Mask, AI Bots, Voice Bots, Chatbots, and Sector-specific Assistants. Tovie AI aims to enhance customer service, boost employee engagement, and improve business operations through its tailored AI solutions. The platform also offers consulting services to help businesses leverage Generative AI for business optimization and growth.

Cantian AI
Cantian AI is an AI tool designed for the intelligent era. It offers advanced capabilities that require JavaScript to be enabled for optimal performance. The tool leverages artificial intelligence to provide users with intelligent solutions and insights.
0 - Open Source AI Tools
20 - OpenAI Gpts

Prompt Peerless - Complete Prompt Optimization
Premier AI Prompt Engineer for Advanced LLM Optimization, Enhancing AI-to-AI Interaction and Comprehension. Create -> Optimize -> Revise iteratively
Agent Prompt Generator for LLM's
This GPT generates the best possible LLM-agents for your system prompts. You can also specify the model size, like 3B, 33B, 70B, etc.
PyRefactor
Refactor python code. Python expert with proficiency in data science, machine learning (including LLM apps), and both OOP and functional programming.

CV & Resume ATS Optimize + 🔴Match-JOB🔴
Professional Resume & CV Assistant 📝 Optimize for ATS 🤖 Tailor to Job Descriptions 🎯 Compelling Content ✨ Interview Tips 💡



Website Conversion by B12
I'll help you optimize your website for more conversions, and compare your site's CRO potential to competitors’.

Thermodynamics Advisor
Advises on thermodynamics processes to optimize system efficiency.

Cloud Architecture Advisor
Guides cloud strategy and architecture to optimize business operations.

International Tax Advisor
Advises on international tax matters to optimize company's global tax position.
Investment Management Advisor
Provides strategic financial guidance for investment behavior to optimize organization's wealth.
ESG Strategy Navigator 🌱🧭
Optimize your business with sustainable practices! ESG Strategy Navigator helps integrate Environmental, Social, Governance (ESG) factors into corporate strategy, ensuring compliance, ethical impact, and value creation. 🌟
Floor Plan Optimization Assistant
Help optimize floor plan, for better experience, please visit collov.ai
AI Business Transformer
Top AI for business automation, data analytics, content creation. Optimize efficiency, gain insights, and innovate with AI Business Transformer.
Business Pricing Strategies & Plans Toolkit
A variety of business pricing tools and strategies! Optimize your price strategy and tactics with AI-driven insights. Critical pricing tools for businesses of all sizes looking to strategically navigate the market.