Best AI tools for< Ocr Text Recognition >
20 - AI tool Sites
VoiceGPT
VoiceGPT is an Android app that provides a voice-based interface to interact with AI language models like ChatGPT, Bing AI, and Bard. It offers features such as unlimited free messages, voice input and output in 67+ languages, a floating bubble for easy switching between apps, OCR text recognition, code execution, image generation with DALL-E 2, and support for ChatGPT Plus accounts. VoiceGPT is designed to be accessible for users with visual impairments, dyslexia, or other conditions, and it can be set as the default assistant to be activated hands-free with a custom hotword.
Reedr
Reedr is an AI-powered browser automation tool that simplifies scraping at scale. It offers features such as text recognition (OCR), custom headers, CAPTCHA solver, and proxying for efficient data extraction. With Reedr, users can automate tasks, generate reports, and monitor running tasks in real-time. The tool utilizes AI capabilities to convert visible text and images on web pages into formatted data, supporting various data processing needs. Additionally, Reedr provides customized real-time reporting with API endpoints for different reporting teams, enabling data export in formats like CSV, XLSX, JSON, and YAML. The tool prioritizes industry-leading compliance, adhering to data protection laws and privacy regulations like GDPR.
Base64.ai
Base64.ai is an AI-powered document intelligence platform that offers a comprehensive solution for document processing and data extraction. It leverages advanced AI technology to streamline workflows, improve accuracy, and drive digital transformation for organizations. With features like Generative AI agents, workflow automation, and data intelligence, Base64.ai enables users to extract insights from structured and unstructured documents with ease. The platform is designed to enhance efficiency, reduce processing time, and increase productivity by eliminating manual document processing tasks.
Pen2txt
Pen2txt is an AI-powered tool that converts handwritten notes and sketches into digital text and images. It uses advanced image recognition and natural language processing to accurately transcribe handwriting, making it easy to digitize and share your notes. Pen2txt is designed to be user-friendly and accessible, with a simple interface and a variety of features to help you get the most out of your notes.
AI Image Translator
AI Image Translator is an advanced tool that utilizes AI-powered OCR technology to translate images while retaining original text formats. It supports over 130 languages and offers features such as format preservation, background restoration, multi-language translation, intelligent text placement, and high-quality image export. The tool is ideal for tasks like e-commerce product image translation, app and software screenshot translation, marketing and advertisement translation, technical document translation, and educational content translation.
GrabText
GrabText is an online OCR tool that allows users to convert handwritten or printed text from photos, graphics, or documents into editable text. It uses ChatGPT to automatically correct spelling, grammar, and other illegal writings. The tool also supports math equations and offers flexible output options such as txt, latex, doc, and pdf.
TextUnbox
TextUnbox is an AI-powered tool that allows users to extract text from images, generate images from text descriptions, translate text, remove image backgrounds, and more. It supports over 20 languages and can be used in the browser or integrated into custom solutions using its REST API.
Picture to Text Converter
Picture to Text Converter is an online tool that uses Optical Character Recognition (OCR) technology to extract text from images. It can process various image formats like JPG, PNG, GIF, scanned documents (PDFs), and even photos taken with your phone's camera. The extracted text can be copied to the clipboard or downloaded as a TXT file. Picture to Text Converter is free to use and does not require any registration or installation. It is a convenient and efficient way to convert images into editable text.
Be My Eyes
Be My Eyes is a free mobile app that connects blind and low-vision people with sighted volunteers and AI-powered assistance. With Be My Eyes, blind and low-vision people can access visual information, get help with everyday tasks, and connect with others in the community. Be My Eyes is available in over 180 languages and has over 6 million volunteers worldwide.
GetSearchablePDF
GetSearchablePDF is an online tool that allows users to convert scanned or image-based PDF documents into searchable PDFs. With its advanced OCR (Optical Character Recognition) technology, the tool accurately extracts text from images, making the resulting PDFs easy to search, edit, and share. The process is simple and straightforward: users simply connect their Dropbox or OneDrive account, drag and drop their PDF files into the designated folder, and the tool automatically converts them into searchable PDFs.
Woy AI Tools
Woy AI Tools is an online tool that offers free image to text conversion with over 99% accuracy and automatic recognition of more than 100 languages. Users can easily upload an image and receive the textual information contained within it. The tool supports multiple languages, prioritizes user privacy and data protection, has a simple and user-friendly interface, and is available for free usage. It utilizes advanced machine learning and OCR technology to continuously optimize recognition algorithms for clear and high-resolution images.
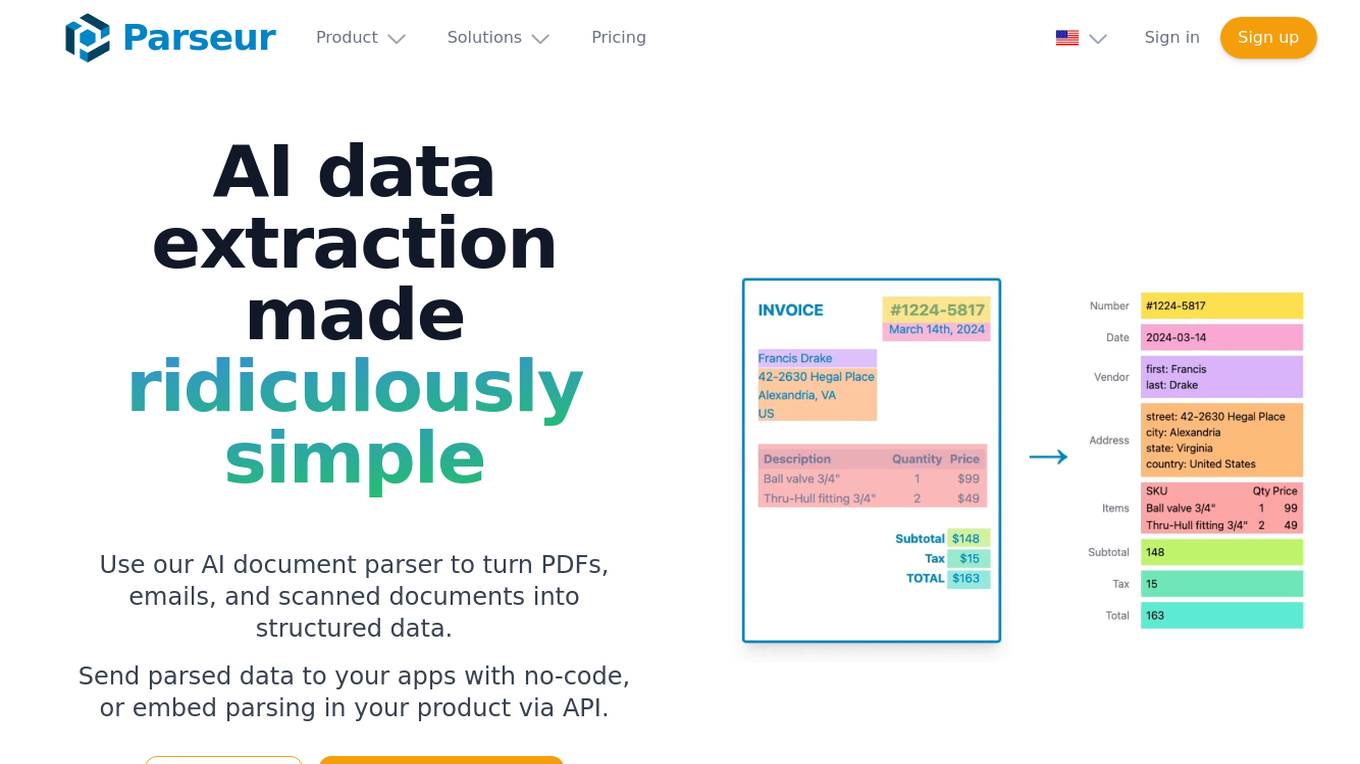
Parseur
Parseur is an AI data extraction software that uses artificial intelligence to extract structured data from various types of documents such as PDFs, emails, and scanned documents. It offers features like template-based data extraction, OCR software for character recognition, and dynamic OCR for extracting fields that move or change size. Parseur is trusted by businesses in finance, tech, logistics, healthcare, real estate, e-commerce, marketing, and human resources industries to automate data extraction processes, saving time and reducing manual errors.

PicNotes
PicNotes is a web-based image-to-text converter that can convert messy images into summaries, text, or explanations. It supports handwritten papers, medical reports, and other types of images. The tool is easy to use: simply upload an image and choose the desired output format. PicNotes will then process the image and return the results within seconds.
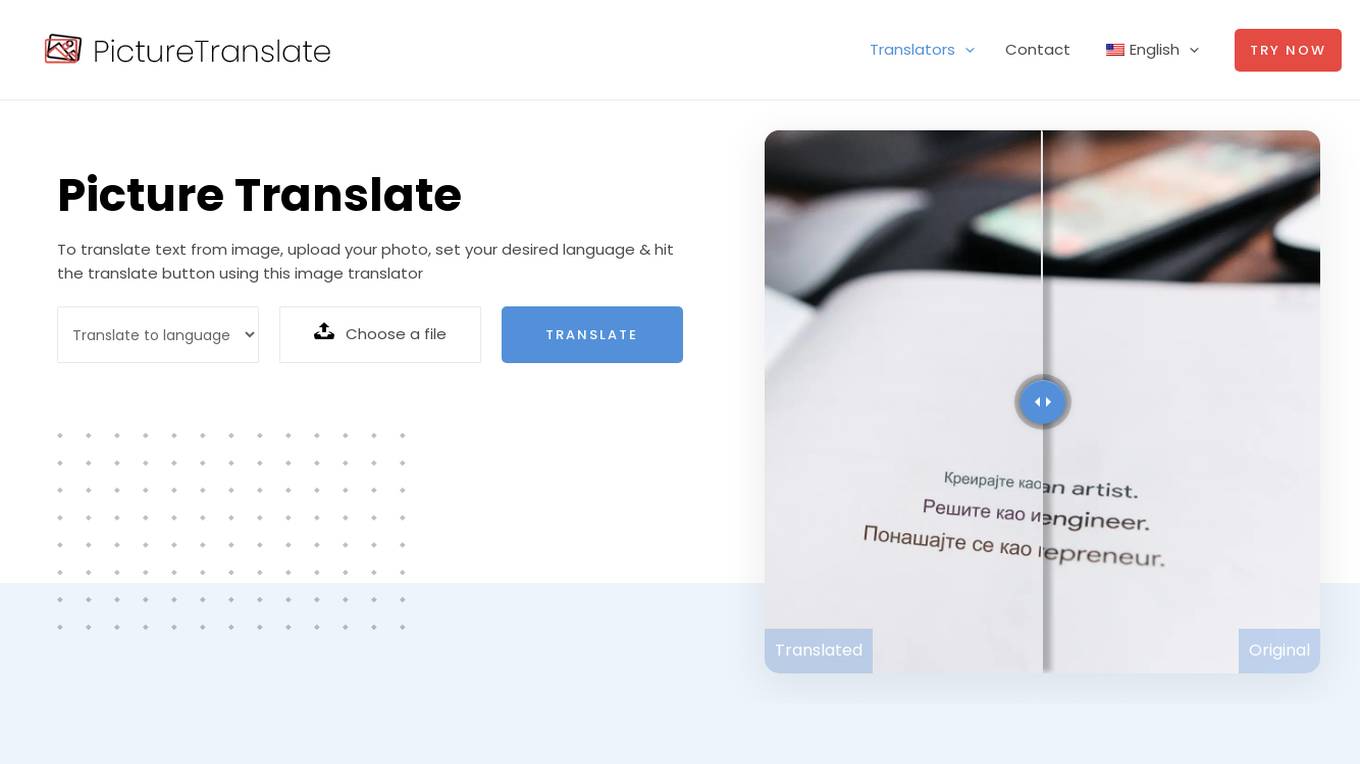
Picture Translate
Picture Translate is an online tool that allows users to translate text from images for free. It leverages advanced Optical Character Recognition (OCR) technology to accurately identify and translate text from images, including low-resolution images and handwritten notes. The tool supports multilingual translation, real-time results, and cross-platform compatibility, making it ideal for various applications such as travel, education, business, healthcare, and more. Picture Translate aims to break down language barriers and provide a user-friendly experience for seamless image translation.
SourceNext
SourceNext is a Japanese company that provides a wide range of software and services, including AI-powered tools. The company's website offers a variety of products, including OCR (optical character recognition) software, DTP (desktop publishing) software, photo and video editing software, and AI-powered tools for tasks such as text summarization and language translation. SourceNext's products are designed to be easy to use and affordable, and they are used by a wide range of customers, from individuals to businesses.
Winston AI
Winston AI is a leading AI content detection tool designed to help users identify AI-generated text from ChatGPT, GPT-4, Google Bard, and other large language models. It offers a range of features, including AI content detection, plagiarism checking, readability scoring, and OCR (Optical Character Recognition) technology for extracting text from scanned documents or pictures. Winston AI is committed to providing accurate and reliable AI detection, with a 99.98% accuracy rate and continuous updates to keep up with the latest advancements in AI writing tools.
PDF2Quiz
PDF2Quiz is an AI-powered tool that allows users to convert PDF documents into interactive quizzes. Users can upload a PDF, specify the number of questions, select the language, and set the difficulty level to transform the PDF into an engaging quiz. The tool utilizes Optical Character Recognition (OCR) to create quizzes from PDFs with non-selectable text, making it easy for users to assess their knowledge and share quizzes with others. With multilingual quiz conversion capabilities, PDF2Quiz caters to users from various linguistic backgrounds. The tool also offers features such as reviewing scores and answers, challenging users with automatically generated multiple-choice questions, and enabling offline use by saving quizzes and answers as PDFs.
FileDrop
FileDrop is a file or document manager that allows you to drag and drop files into a document with automatic linking and save them to Google Drive. It also offers features like OCR, translation, and AI integration. With FileDrop, you can easily insert, save, and link files in Google Sheets cells, Docs, and Slides.
AI Manga Translate
AI Manga Translate is an AI-powered manga translation tool that offers fast, accurate, and multilingual OCR services. It allows users to understand the original manga content in seconds and translates it into various languages while preserving context and layout. The tool supports over 50 languages with a high translation accuracy rate. Users can upload images or PDFs, choose the target language and model, and review/download the translated content easily. AI Manga Translate provides a full-stack AIGC solution for manga translation, combining offline and cloud language models to ensure high-fidelity output and controllable layout.
AI Bank Statement Converter
The AI Bank Statement Converter is an industry-leading tool designed for accountants and bookkeepers to extract data from financial documents using artificial intelligence technology. It offers features such as automated data extraction, integration with accounting software, enhanced security, streamlined workflow, and multi-format conversion capabilities. The tool revolutionizes financial document processing by providing high-precision data extraction, tailored for accounting businesses, and ensuring data security through bank-level encryption. It also offers Intelligent Document Processing (IDP) using AI and machine learning techniques to process structured, semi-structured, and unstructured documents.
1 - Open Source AI Tools
AutoNode
AutoNode is a self-operating computer system designed to automate web interactions and data extraction processes. It leverages advanced technologies like OCR (Optical Character Recognition), YOLO (You Only Look Once) models for object detection, and a custom site-graph to navigate and interact with web pages programmatically. Users can define objectives, create site-graphs, and utilize AutoNode via API to automate tasks on websites. The tool also supports training custom YOLO models for object detection and OCR for text recognition on web pages. AutoNode can be used for tasks such as extracting product details, automating web interactions, and more.
18 - OpenAI Gpts


Journal Recognizer OCR
Optimized OCR for Handwritten Notebooks, up to 10 image transcript copy w/1-click. No text prompt necessary. Reads journals, reports, notes. All handwriting transcribed verbatim, then text summarized, graphic image features described. Ask to change any behavior.
kz image 2 typescript 2 image
Generate a Structured description in typescript format from the image and generate an image from that description. and OCR


DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages
Assistente Codificação TUSS Exames com OCR
Portuguese OCR for medical test coding, outputs in table format.
Photo of a business card 2 Contacts
Wizard to business card photos to CSV files for Google Contacts.
Lector de recetas médicas
Ayuda a descifrar la indescifrable caligrafía de las recetas de los médicos