Best AI tools for< Normalize Text >
1 - AI tool Sites
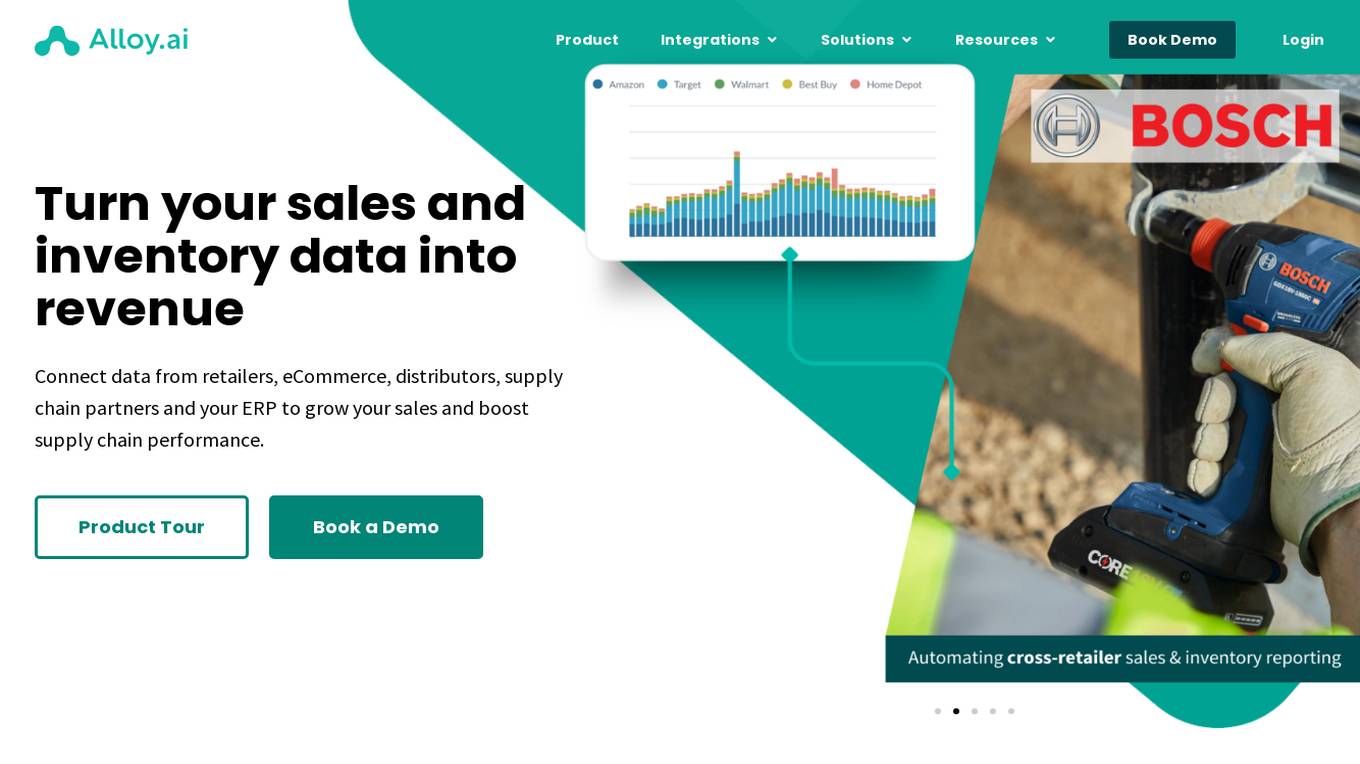
Alloy.ai
Alloy.ai is an omnichannel revenue intelligence platform for consumer brands that helps visualize and analyze sales, supply chain, and forecasting data with full visibility into consumer demand and inventory. The platform connects real-time POS and inventory data from hundreds of retailers, providing a single view of sales and inventory. Alloy.ai uses AI and ML to identify new sales opportunities and potential problems, offering a normalized view of business data for better decision-making.
1 - Open Source AI Tools
ChatTTS-Forge
ChatTTS-Forge is a powerful text-to-speech generation tool that supports generating rich audio long texts using a SSML-like syntax and provides comprehensive API services, suitable for various scenarios. It offers features such as batch generation, support for generating super long texts, style prompt injection, full API services, user-friendly debugging GUI, OpenAI-style API, Google-style API, support for SSML-like syntax, speaker management, style management, independent refine API, text normalization optimized for ChatTTS, and automatic detection and processing of markdown format text. The tool can be experienced and deployed online through HuggingFace Spaces, launched with one click on Colab, deployed using containers, or locally deployed after cloning the project, preparing models, and installing necessary dependencies.
3 - OpenAI Gpts
Text to DB Schema
Convert application descriptions to consumable DB schemas or create-table SQL statements

Heroes Bounty Draftsman
I turn vague tasks into clear, formal bounties, asking for clarification when needed.