Best AI tools for< Judge Dog Show >
7 - AI tool Sites
AI Judge
AI Judge is an online platform that helps to generate a verdict and resolve disputes in a fair and impartial manner. It allows both parties involved in a dispute to present their arguments and evidence, after which the AI system analyzes the information and generates a clear and concise verdict. The platform aims to provide an additional perspective for the contending parties to consider during the dispute resolution process, ensuring impartial decisions based on the merits of each case.

Confident AI
Confident AI is an open-source evaluation infrastructure for Large Language Models (LLMs). It provides a centralized platform to judge LLM applications, ensuring substantial benefits and addressing any weaknesses in LLM implementation. With Confident AI, companies can define ground truths to ensure their LLM is behaving as expected, evaluate performance against expected outputs to pinpoint areas for iterations, and utilize advanced diff tracking to guide towards the optimal LLM stack. The platform offers comprehensive analytics to identify areas of focus and features such as A/B testing, evaluation, output classification, reporting dashboard, dataset generation, and detailed monitoring to help productionize LLMs with confidence.
Debatia
Debatia is a free, real-time debate platform that allows users to debate anyone, worldwide, in text or voice, in their own language. Debatia's AI Judging System uses ChatGPT to deliver fair judgment in debates, offering a novel and engaging experience. Users are paired based on their debate skill level by Debatia's algorithm.

Flow AI
Flow AI is an advanced AI tool designed for evaluating and improving Large Language Model (LLM) applications. It offers a unique system for creating custom evaluators, deploying them with an API, and developing specialized LMs tailored to specific use cases. The tool aims to revolutionize AI evaluation and model development by providing transparent, cost-effective, and controllable solutions for AI teams across various domains.
Lex Machina
Lex Machina is a Legal Analytics platform that provides comprehensive insights into litigation track records of parties across the United States. It offers accurate and transparent analytic data, exclusive outcome analytics, and valuable insights to help law firms and companies craft successful strategies, assess cases, and set litigation strategies. The platform uses a unique combination of machine learning and in-house legal experts to compile, clean, and enhance data, providing unmatched insights on courts, judges, lawyers, law firms, and parties.
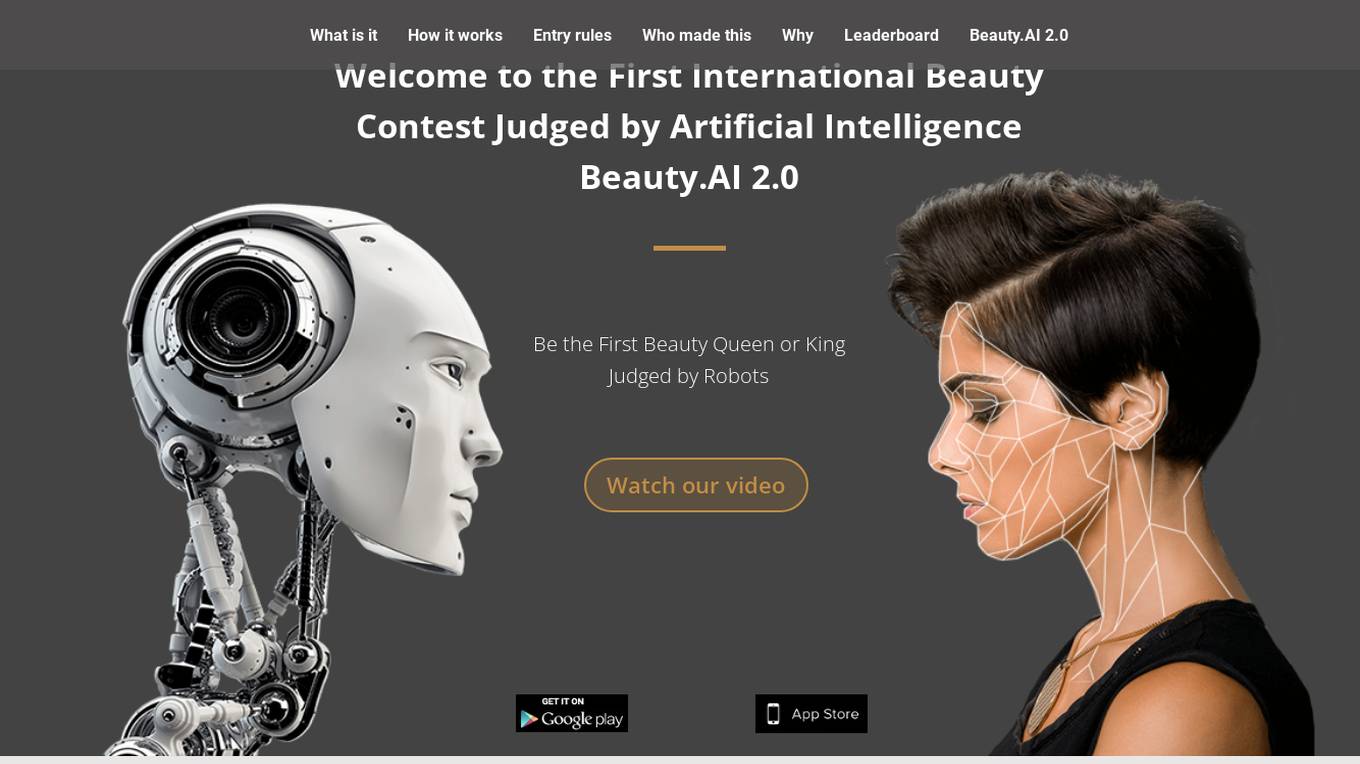
Beauty.AI
Beauty.AI is an AI application that hosts an international beauty contest judged by artificial intelligence. The app allows humans to submit selfies for evaluation by AI algorithms that assess criteria linked to human beauty and health. The platform aims to challenge biases in perception and promote healthy aging through the use of deep learning and semantic analysis. Beauty.AI offers a unique opportunity for individuals to participate in a groundbreaking competition that combines technology and beauty standards.
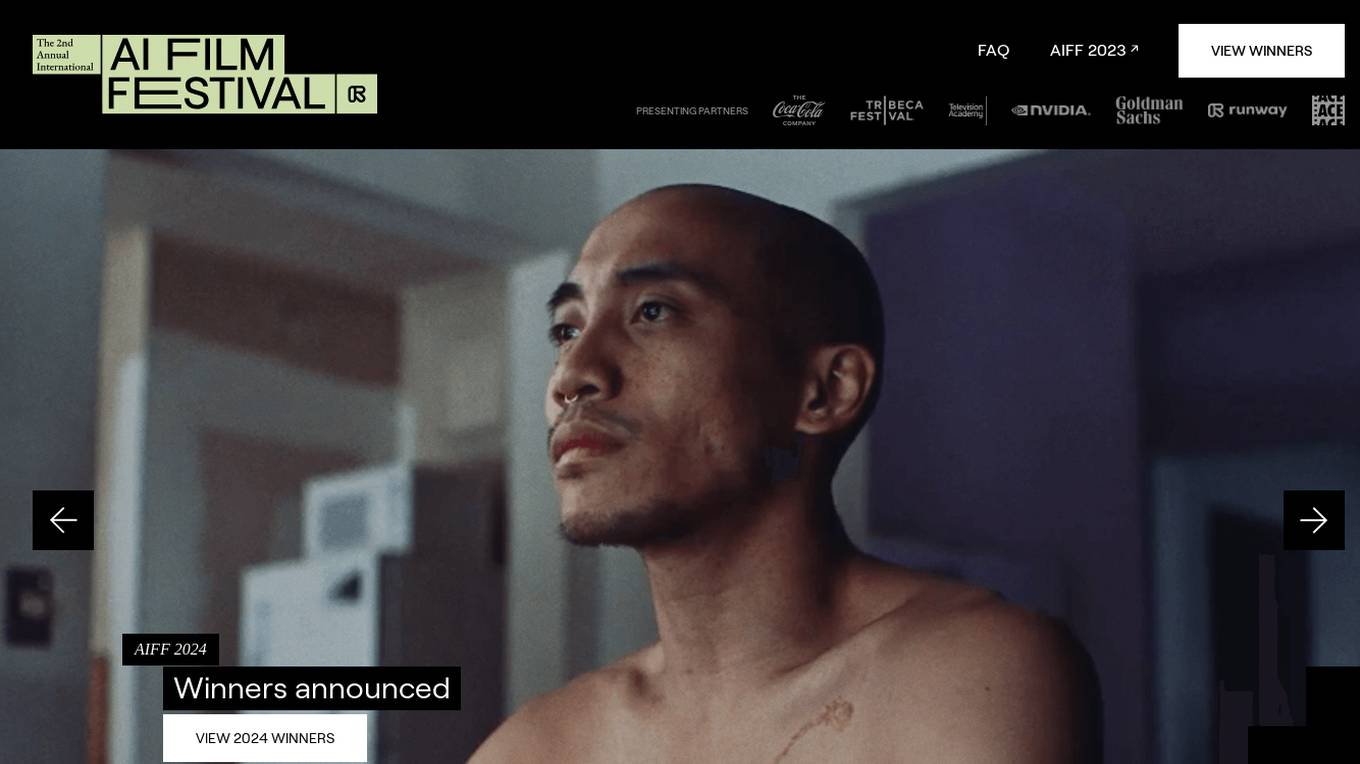
Runway AI Film Festival
Runway AI Film Festival is an annual celebration of art and artists embracing new and emerging AI techniques for filmmaking. Established in 2022, the festival showcases works that offer a glimpse into a new creative era empowered by the tools of tomorrow. The festival features gala screenings in NYC and LA, where 10 finalists are selected and winners are chosen by esteemed judges. With over $60,000 in total prizes, the festival aims to fund the continued creation of AI filmmaking.
0 - Open Source AI Tools
20 - OpenAI Gpts
Pawsome Judge
Playful guide for a virtual dog show, creating and presenting imaginative dog breeds.
West Coast Choppers
A virtual judge for West Coast Choppers, rating and discussing custom bikes.
What does MBTI say? (MBTI怎么说)
Let's judge his/her MBTI by giving specific scenarios and what specific people say.(让我们通过具体的场景和对方说的话来判断他的 MBTI吧!)
JUEZ GPT
JUEZ GPT es una herramienta diseñada para arbitrar conflictos y tomar decisiones de manera pragmática, justa y lógica, proporcionando veredictos claros

Court Simulator
Examine and simulate any level of courtroom etiquette and procedures in any country. Copyright (C) 2024, Sourceduty - All Rights Reserved.
The Great Bakeoff Master
Magical baking game host & with the 4 judges to help you become the master baker and chef
Código de Processo Civil
Robô treinado para esclarecer dúvidas sobre o Código de Processo Civil brasileiro

ConstitutiX
Asesor en derecho constitucional chileno. Te explicaré las diferencias entre la Constitución Vigente y la Propuesta Constitucional 2023.

Case Digests on Demand (a Jurisage experiment)
Upload a court judgment and get back a collection of topical case digests based on the case. Oh - don't trust the "Topic 2210" or similar number, it's random. Also, probably best you not fully trust the output either. We're just playing with the GPT maker. More about us at Jurisage.com.