Best AI tools for< Integrate Audio >
20 - AI tool Sites
Seedance 2.0
Seedance 2.0 is an AI video model and generator that allows users to create cinematic videos from text prompts and reference images. It offers high-quality motion and optional native audio, with a wide range of AI video effects to enhance creativity. The platform enables users to turn any image into a cinematic clip in seconds, with features like AI kissing and hugging generators. Seedance 2.0 provides a seamless experience for content creation, catering to both personal and commercial use cases.
Suno API
Suno API is a professional AI music generation service that offers a powerful API for seamless integration of custom audio generation into products and services. The advanced AI music generation service provides unparalleled flexibility and quality for developers and businesses, with reliable API performance, flexible integration options, customizable output, and scalable solutions. Suno API is optimized for efficiency, allowing rapid music generation for various applications.
Audio Writer
Audio Writer is a voice-to-text transcription app that uses AI to refine and rewrite transcripts. It can also be used for journaling, content creation, and more. The app is available for iOS and macOS, and it offers a one-time payment option with no subscription required.
Ai-SPY
Ai-SPY is an advanced AI audio detection tool that helps users identify whether speech is human or AI-generated. It offers detailed reports, easy integration with API access, and expert human insights for accurate analysis. Ai-SPY leverages a proprietary neural network to provide unparalleled audio authenticity insights, making it a valuable tool for content verification and manipulation detection.
Gladia
Gladia provides a fast and accurate way to turn unstructured audio data into valuable business knowledge. Its Audio Intelligence API helps capture, enrich, and leverage hidden insights in audio data, powered by optimized Whisper ASR. Key features include highly accurate audio and video transcription, speech-to-text translation in 99 languages, in-depth insights with add-ons, and secure hosting options. Gladia's AI transcription and multilingual audio intelligence features enhance user experience and boost retention in various industries, including content and media, virtual meetings, workspace collaboration, and call centers. Developers can easily integrate cutting-edge AI into their products without AI expertise or setup costs.
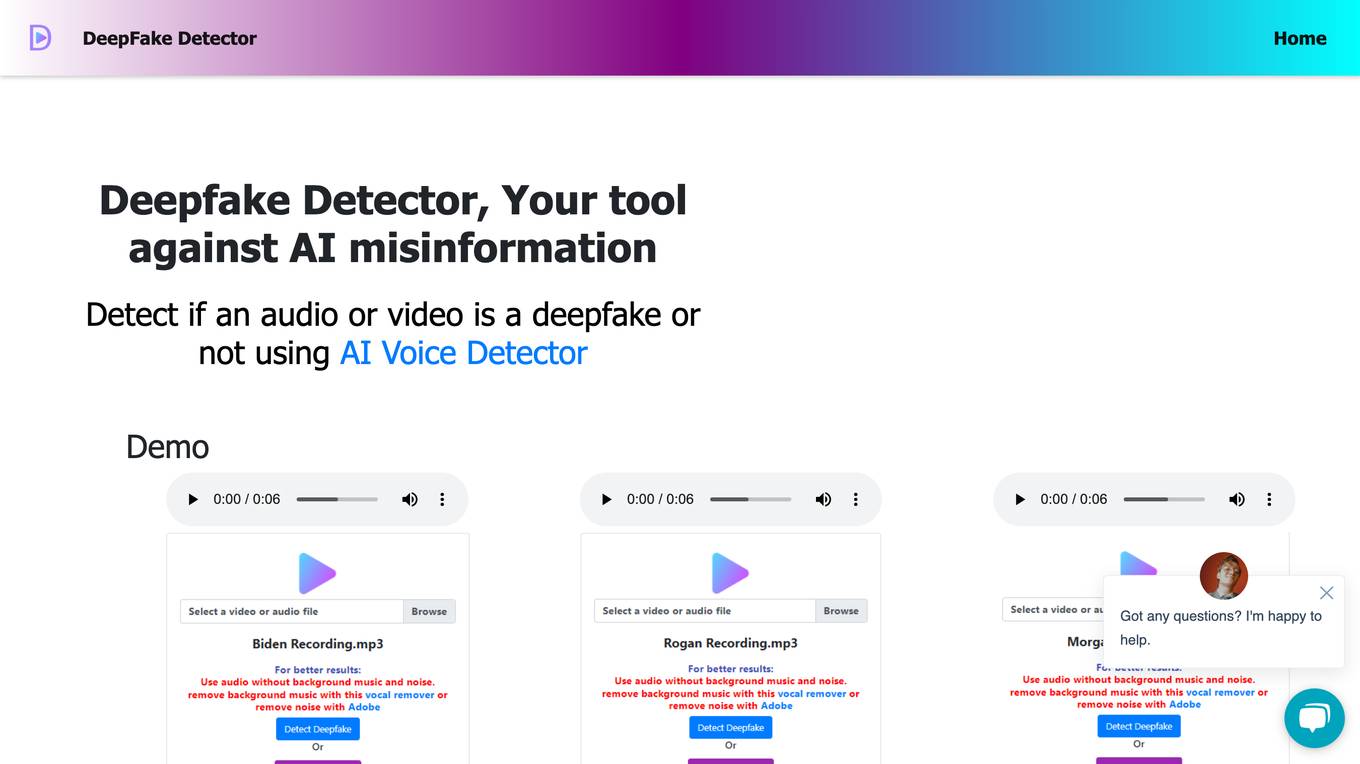
Deepfake Detector
Deepfake Detector is an AI tool designed to identify deepfakes in audio and video files. It offers features such as background noise and music removal, audio and video file analysis, and browser extension integration. The tool helps individuals and businesses protect themselves against deepfake scams by providing accurate detection and filtering of AI-generated content. With a focus on authenticity and reliability, Deepfake Detector aims to prevent financial losses and fraudulent activities caused by deepfake technology.
Mastermallow
Mastermallow.com is currently experiencing a web server error with code 521, which is preventing the website from displaying. Visitors are advised to try accessing the site again in a few minutes, while the website owner is recommended to contact their hosting provider for assistance. The error message suggests that the issue may be related to the web server not responding, and additional troubleshooting information is available. Cloudflare is mentioned as the service provider, indicating a potential partnership or reliance on their services for performance and security.
ChatTTS
ChatTTS is an open-source text-to-speech model designed for dialogue scenarios, supporting both English and Chinese speech generation. Trained on approximately 100,000 hours of Chinese and English data, it delivers speech quality comparable to human dialogue. The tool is particularly suitable for tasks involving large language model assistants and creating dialogue-based audio and video introductions. It provides developers with a powerful and easy-to-use tool based on open-source natural language processing and speech synthesis technologies.
Respeecher
Respeecher is an AI tool that combines technology and magic to deliver authentic voices across various industries. It uses cutting-edge public models and proprietary technology to provide high-quality voice solutions. The team of dedicated sound professionals at Respeecher ensures ethical use of synthetic media, making it a trusted choice for voice cloning and voice conversion services.
ChatTTS
ChatTTS is a text-to-speech tool optimized for natural, conversational scenarios. It supports both Chinese and English languages, trained on approximately 100,000 hours of data. With features like multi-language support, large data training, dialog task compatibility, open-source plans, control, security, and ease of use, ChatTTS provides high-quality and natural-sounding voice synthesis. It is designed for conversational tasks, dialogue speech generation, video introductions, educational content synthesis, and more. Users can integrate ChatTTS into their applications using provided API and SDKs for a seamless text-to-speech experience.
Seedance 2.0 API
Seedance 2.0 API is a powerful AI video generation tool that allows users to create cinematic videos using text-to-video and image-to-video capabilities. With support for multi-shot storytelling and native audio generation, Seedance 2.0 API offers high-quality video outputs suitable for various applications such as e-commerce, short drama, and marketing. The tool provides a RESTful API with clean endpoints and JSON format, making it easy to integrate with existing workflows. Users can access the API on a pay-as-you-go basis, with no subscription required, and benefit from features like multi-modal input support, enterprise readiness, and fast generation times.
Supertranslate
Supertranslate.ai is a powerful AI tool designed for media professionals to transform audio and video content with accurate speech-to-text, subtitles, and translations. It supports over 125 languages and offers advanced features like noise reduction, speaker identification, custom dictionaries, team collaboration, and integrations with popular services. The platform provides a streamlined process from uploading media to final delivery, making it perfect for reaching global audiences and enhancing transcription and translation workflows.
sync.labs
sync.labs is an AI lipsync tool designed for video content creators. It offers an API for realtime lip-sync to animate people to speak any language in any video. The tool allows users to create, modify, and animate humans in video content, making it versatile for various applications such as movies, podcasts, games, and animations. sync.labs aims to simplify the process of syncing audio with video content, providing a seamless experience for content creators.
Read AI
Read AI is an AI-powered application that enhances productivity by generating summaries, transcripts, and highlights for meetings, emails, and messages. It offers features like real-time meeting summaries, smart scheduler, speaker coach insights, and multi-language support. Read AI helps users save time, improve communication, and stay organized across various platforms. With a focus on security and actionable accountability, it aims to streamline workflows and maximize productivity for knowledge workers.
Read AI
Read AI is an AI-powered application that enhances productivity by generating summaries, transcripts, and highlights for meetings, emails, and messages. It offers features like playback, coaching, smart scheduling, and integrations with various platforms. With multi-language support and secure handling of data, Read AI aims to streamline communication and collaboration for users across different languages and industries.
AI Startup Builder
The website offers an AI startup builder tool that allows users to create AI applications in hours by leveraging customizable demo apps and boilerplate code. It provides a Next.js AI starter kit with various features such as full-stack web app development, styling and design with TailwindCSS, state-of-the-art AI models from OpenAI, subscriptions and payments with LemonSqueezy, and more. Users can save time on coding and infrastructure setup, focusing on building their product instead.

Recall.ai
Recall.ai is an AI tool that provides an API for meeting recording. It offers solutions for getting transcripts, recordings, and metadata from meetings. The platform is used by over 1000 customers and processes billions of minutes annually. Recall.ai helps in saving engineering time, integrating with meeting platforms, and building AI applications like Notetaker. It offers meeting bot API, desktop recording SDK, and mobile recording SDK for seamless recording experiences.
LMNT
LMNT is an ultrafast lifelike AI speech pricing API that offers low latency streaming for conversational apps, agents, and games. It provides lifelike voices through studio-quality voice clones and instant voice clones. Engineered by an ex-Google team, LMNT ensures reliable performance under pressure with consistent low latency and high availability. The platform enables real-time conversation, content creation at scale, and product marketing through captivating voiceovers. With a user-friendly interface and developer API, LMNT simplifies voice cloning and synthesis for both beginners and professionals.
SOAPNoteAI
SOAPNoteAI is an AI-powered SOAP note generator designed for healthcare professionals to streamline the documentation process. The tool allows users to finish SOAP notes in minutes by converting shorthand, dictation, telehealth sessions, and recordings into polished, HIPAA-compliant notes. With features like text to auto note, AI scribe recording, audio dictation, telehealth integration, and audio uploads, SOAPNoteAI helps healthcare providers save time and improve the quality of their clinical notes. The platform maintains the highest standards of professional practice and transparency, catering to various healthcare specialties. Users can choose from flexible pricing plans, subscribe monthly, or opt for pay-as-you-go options. Trusted by over 1,000 healthcare providers, SOAPNoteAI is a game-changer in the healthcare documentation landscape.
Cadenza
Cadenza is an AI-powered music production tool that helps users create professional-grade chord progressions effortlessly. By simply describing the chords or the vibe they want, users can generate midi chord progressions with smooth transitions. The tool allows users to prompt the AI with specific chord types or song descriptions, generate the midi file in real-time, and seamlessly integrate the created chords into their preferred DAW for further music production. Cadenza simplifies the music creation process by leveraging state-of-the-art AI algorithms to cater to both beginners and advanced music producers.
1 - Open Source AI Tools
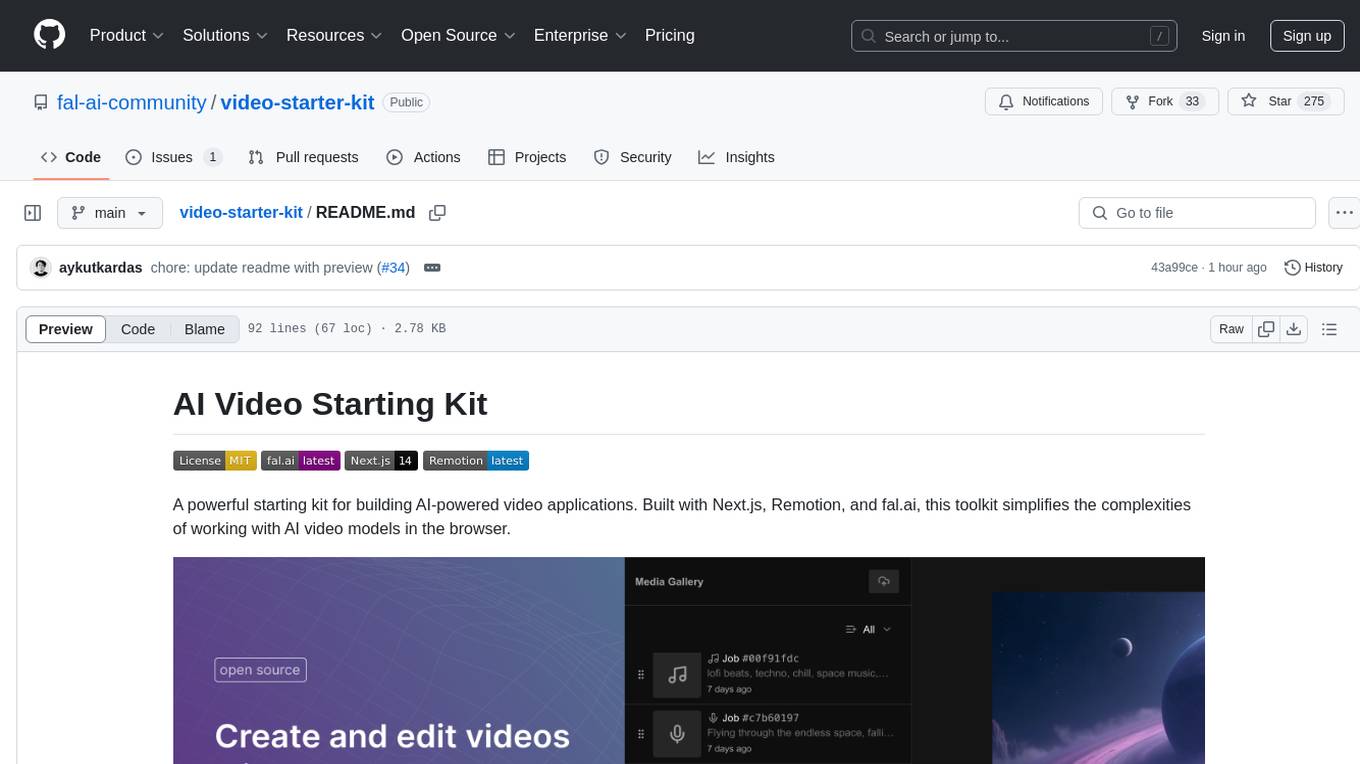
video-starter-kit
A powerful starting kit for building AI-powered video applications. This toolkit simplifies the complexities of working with AI video models in the browser. It offers browser-native video processing, AI model integration, advanced media capabilities, and developer utilities. The tech stack includes fal.ai for AI model infrastructure, Next.js for React framework, Remotion for video processing, IndexedDB for browser-based storage, Vercel for deployment platform, and UploadThing for file upload. The kit provides features like seamless video handling, multi-clip composition, audio track integration, voiceover support, metadata encoding, and ready-to-use UI components.
20 - OpenAI Gpts
CliniType EHR
Voice-to-text, Vision-to-text transcription, Transcript-to-‘Clinical format’ integrated with CDS. Writes clinical notes, referral letter, generate PDF,prepare discharge summary. (Ultimate aid for clinicians)
Payment Integrity
Detailed coding analyst with a focus on overpayment detection and references.
Home Automation Consultant
Helps integrate smart devices into home environments, ensuring ease of use and energy efficiency.
Missing Cluster Identification Program
I analyze and integrate missing clusters in data for coherent structuring.

Kafka Expert
I will help you to integrate the popular distributed event streaming platform Apache Kafka into your own cloud solutions.

ESG Strategy Navigator 🌱🧭
Optimize your business with sustainable practices! ESG Strategy Navigator helps integrate Environmental, Social, Governance (ESG) factors into corporate strategy, ensuring compliance, ethical impact, and value creation. 🌟
Consistent Image Generator
Geneate an image ➡ Request modifications. This GPT supports generating consistent and continuous images with Dalle. It also offers the ability to restore or integrate photos you upload. ✔️Where to use: Wordpress Blog Post, Youtube thumbnail, AI profile, facebook, X, threads feed, Instagram reels

SEO InLink Optimizer
GPT created by Max Del Rosso for SEO optimization, specialized in identifying internal linking opportunities. Through the review of existing content, it suggests targeted changes to integrate effective anchor texts, contributing to improving SERP rankings and user experience.
Quick QR Art - QR Code AI Art Generator
Create, Customize, and Track Stunning QR Codes Art with Our Free QR Code AI Art Generator. Seamlessly integrate these artistic codes into your marketing materials, packaging, and digital platforms.
Flashcard Maker, Research, Learn and Send to Anki
Creates educational flashcards and integrates with Anki.
System Sync
Expert in AiOS integration, technical troubleshooting, and IP rights management.

DevSecOps Guides
Comprehensive resource for integrating security into the software development lifecycle.