Best AI tools for< Information Extraction >
20 - AI tool Sites
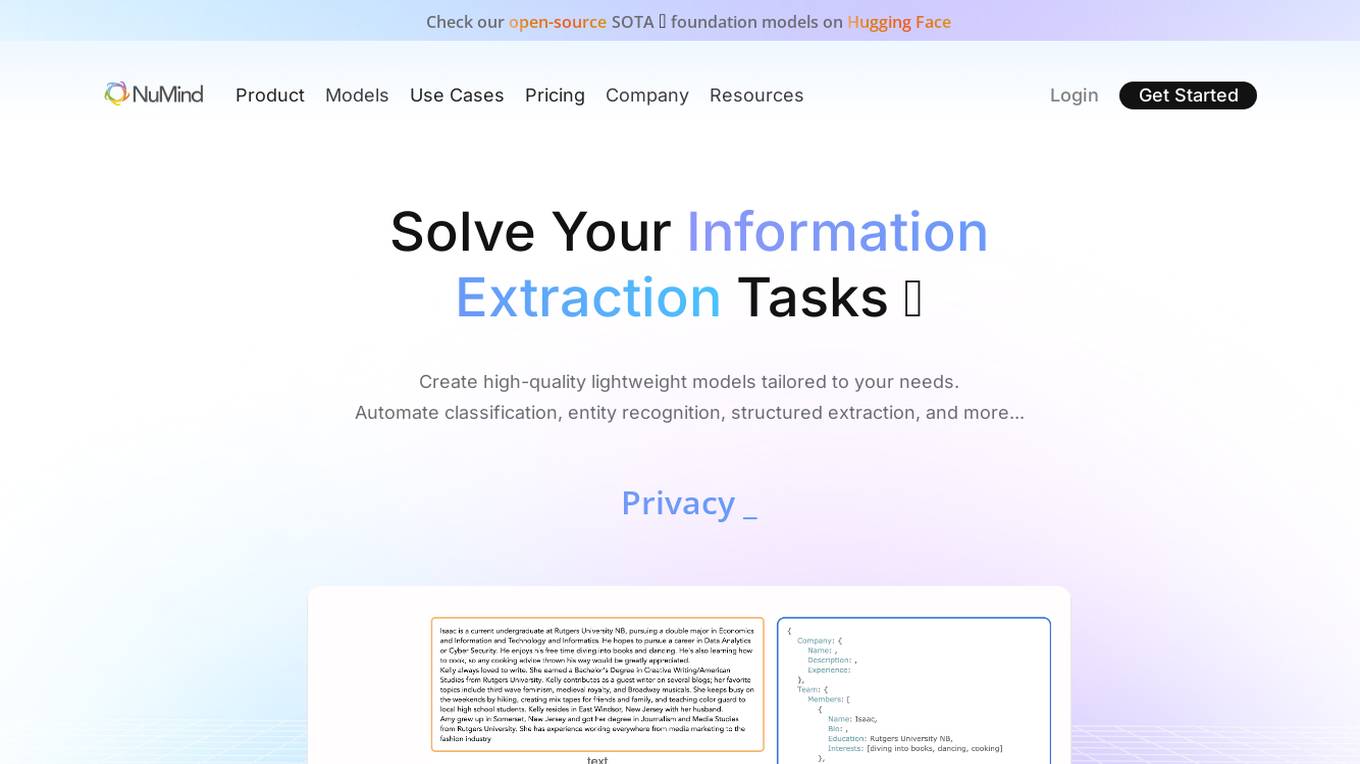
NuMind
NuMind is an AI tool designed to solve information extraction tasks efficiently. It offers high-quality lightweight models tailored to users' needs, automating classification, entity recognition, and structured extraction. The tool is powered by task-specific and domain-agnostic foundation models, outperforming GPT-4 and similar models. NuMind provides solutions for various industries such as insurance and healthcare, ensuring privacy, cost-effectiveness, and faster NLP projects.
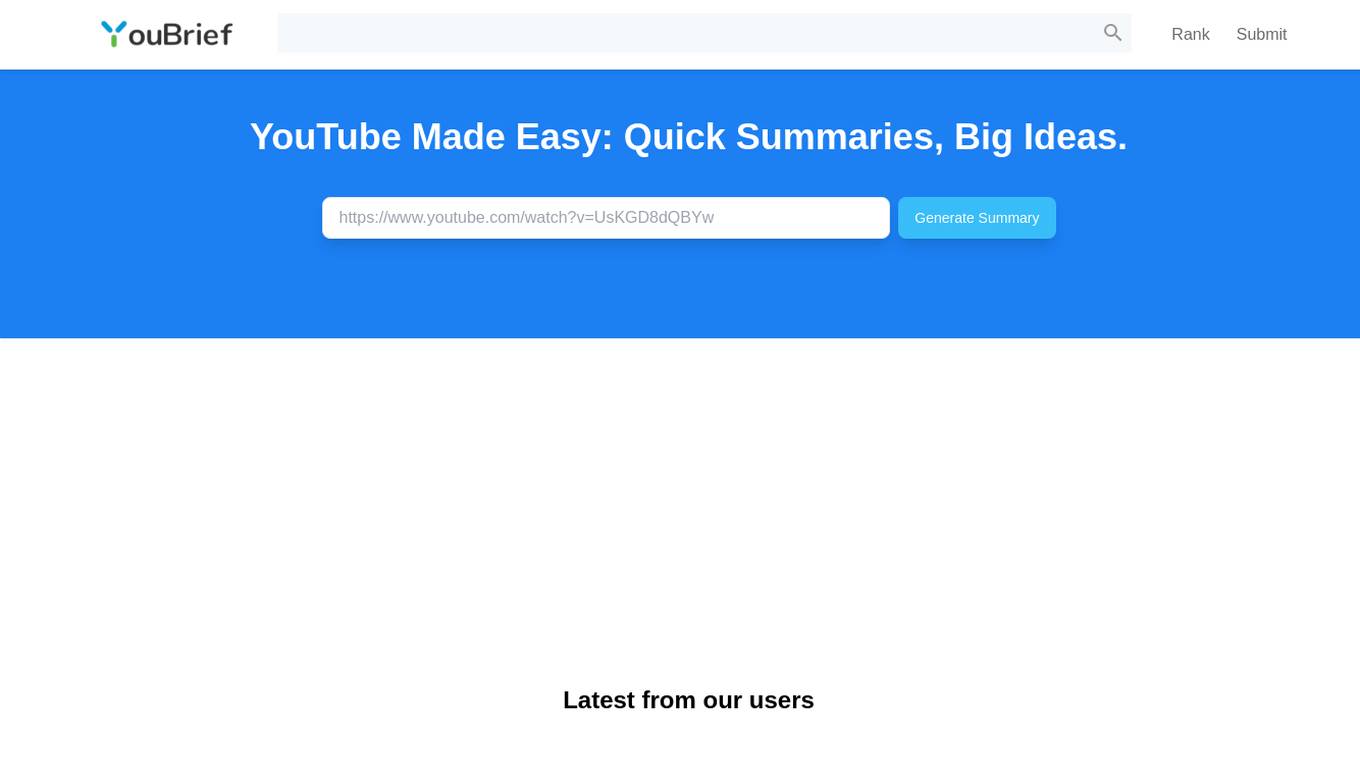
YouBrief
YouBrief is an AI-powered platform that provides instant YouTube video summaries for efficient learning. It offers quick summaries of various YouTube videos, highlighting key ideas and insights to help users save time and stay informed. With YouBrief, users can easily absorb essential information from a wide range of content, enhancing their learning experience and knowledge acquisition.
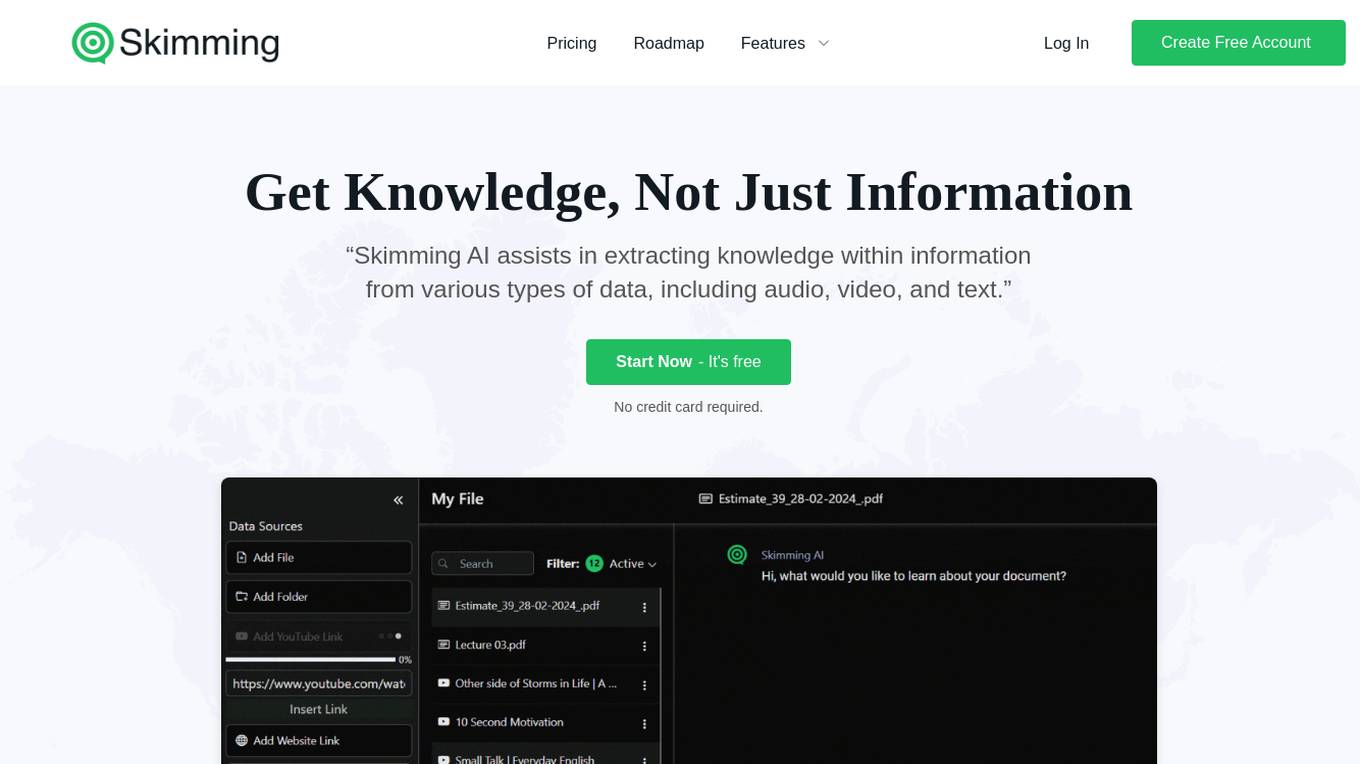
Skimming
Skimming is an AI tool that enables users to interact with various types of data, including audio, video, and text, to extract knowledge. It offers features like chatting with documents, YouTube videos, websites, audio, and video, as well as custom prompts and multilingual support. Skimming is trusted by over 100,000 users and is designed to save time and enhance information extraction. The tool caters to a diverse audience, including teachers, students, businesses, researchers, scholars, lawyers, HR professionals, YouTubers, and podcasters.
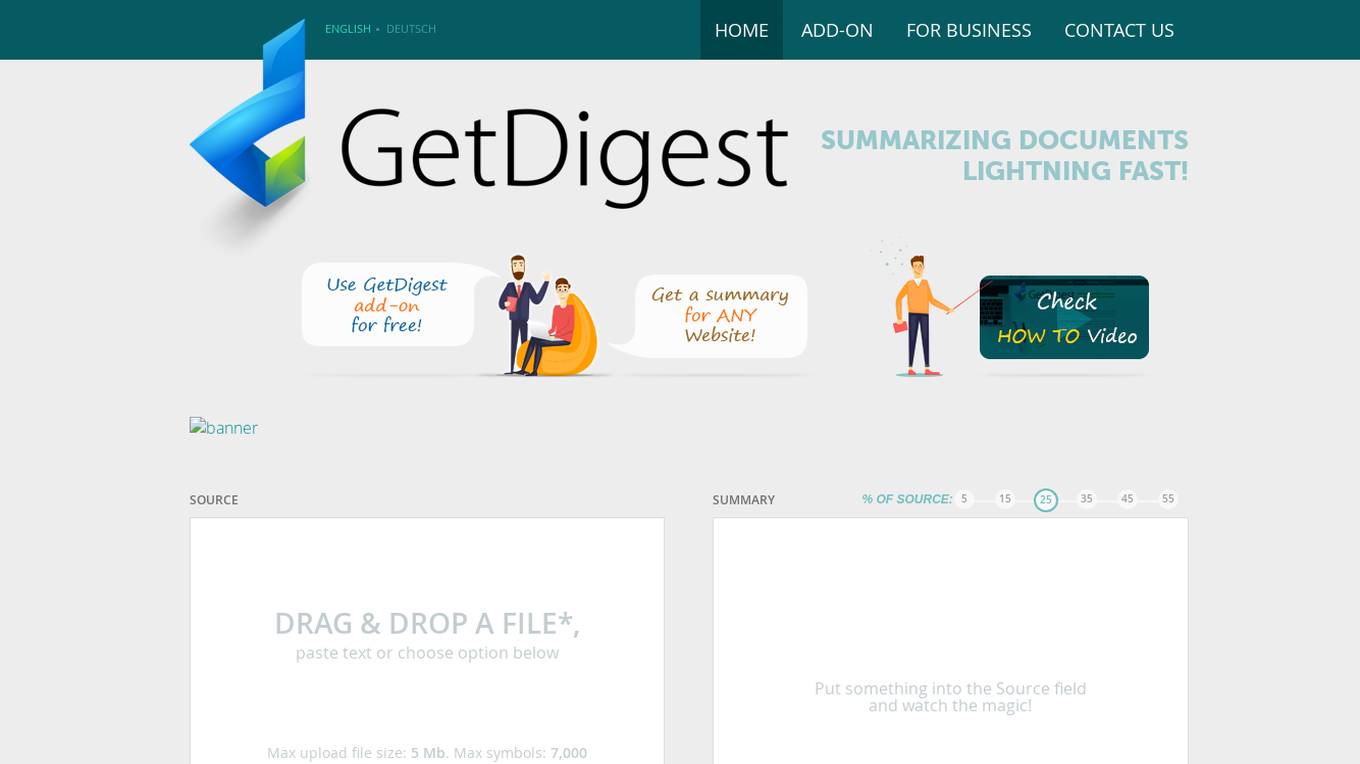
GetDigest
GetDigest is an AI-powered tool that provides lightning-fast document summarization. It can analyze web content and text documents in over 33 languages, summarizing them efficiently by ignoring irrelevant information. The technology is designed to help users process information more effectively, saving time and enhancing productivity. GetDigest offers businesses the opportunity to integrate its technology into their own infrastructure or software projects, supporting various text formats, web environments, archives, emails, and image formats.
Predibase
Predibase is a platform for fine-tuning and serving Large Language Models (LLMs). It provides a cost-effective and efficient way to train and deploy LLMs for a variety of tasks, including classification, information extraction, customer sentiment analysis, customer support, code generation, and named entity recognition. Predibase is built on proven open-source technology, including LoRAX, Ludwig, and Horovod.
Legal Benchmarks
Legal Benchmarks is a platform that provides independent lawyer-led AI evaluations for in-house legal work in the legal industry. The platform evaluates AI assistants on critical legal tasks like contract drafting and information extraction. It offers rankings based on how different AI tools perform on real-world legal tasks, helping legal teams understand and adopt AI solutions. Legal Benchmarks also allows legal AI vendors to submit their tools for evaluation and provides access to customized private reports, insights, and practical breakdowns of AI tools' performance.
NuShift Inc
NuShift Inc is an AI-powered application that offers ELMR-T, a cutting-edge solution for converting data into actionable knowledge in the maintenance and engineering domain. Leveraging machine learning, machine translation, speech recognition, question answering, and information extraction, ELMR-T provides intelligent AI insights to empower maintenance teams. The application is designed to streamline data-driven decision-making, enhance user interaction, and boost efficiency by delivering precise and meaningful results effortlessly.
Wunderschild
Schwarzthal Tech's Wunderschild is an AI-driven platform for financial crime intelligence that revolutionizes compliance and investigation techniques. It provides intelligence solutions based on network assessment, data linkage, flow aggregation, and machine learning. The platform offers expertise and insights on strategic risks related to Politically Exposed Persons, Serious Organised Crime, Terrorism Financing, and more. With features like Compliance, Investigation, Know Your Network, Media Scan, Document Drill, and Transaction Monitoring, Wunderschild empowers users to enhance compliance functions, conduct deep dives into complex transnational crime cases, and detect suspicious activities. The platform is trusted by global companies and offers advanced OCR, multilingual support, and key information extraction capabilities.
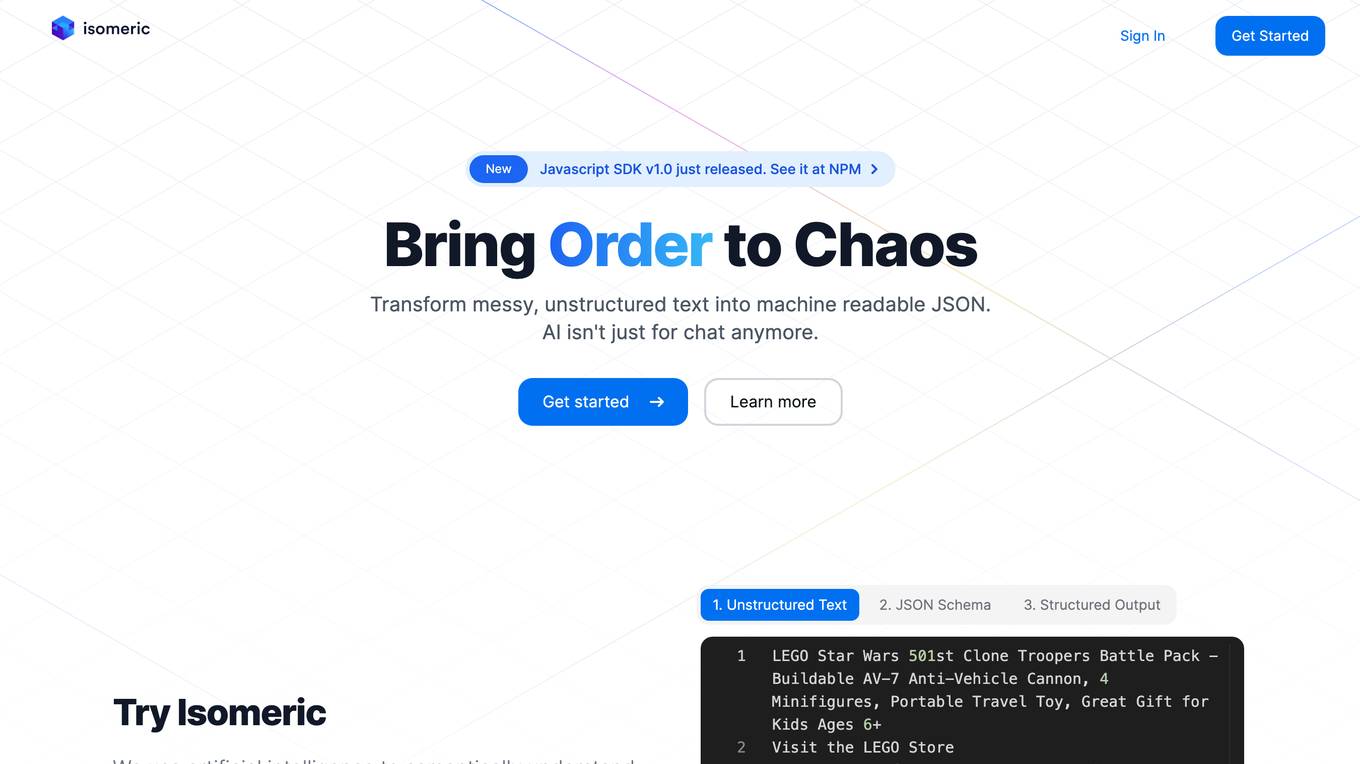
Isomeric
Isomeric is an AI tool that uses artificial intelligence to semantically understand unstructured text and extract specific data. It helps transform messy text into machine-readable JSON, enabling tasks such as web scraping, browser extensions, and general information extraction. With Isomeric, users can scale their data gathering pipeline in seconds, making it a valuable tool for various industries like customer support, data platforms, and legal services.
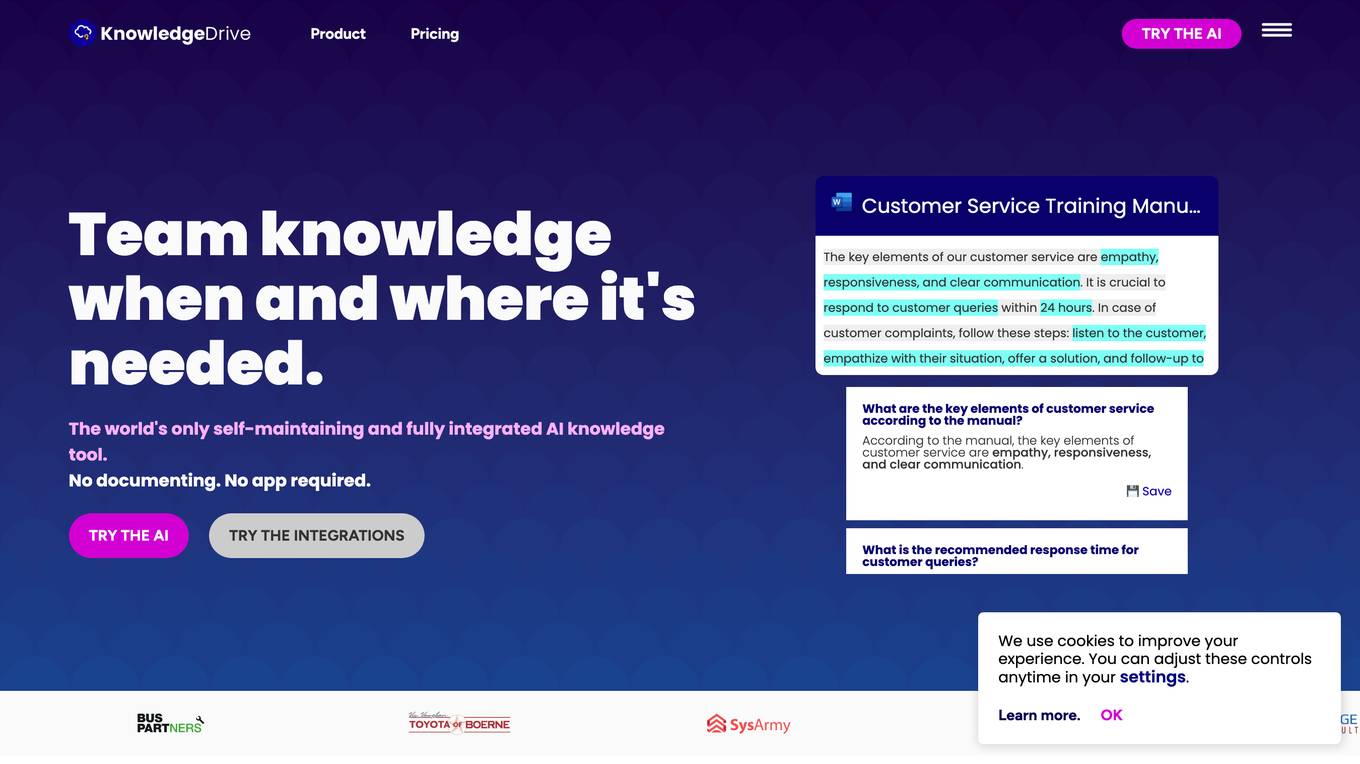
Knowledge Drive
Knowledge Drive is the world's only self-organizing, self-maintaining, and fully integrated work knowledge system. It utilizes AI technology to automatically build a knowledge base by extracting useful information from documents. The system ensures knowledge freshness, easy access to information, and seamless integration across various platforms like Microsoft Office 365, Google Workspace, and Slack. Knowledge Drive aims to revolutionize knowledge management and boost productivity in teams by providing a central source of truth and eliminating the need for manual documentation.

Skim.ai
Skim.ai is an AI-powered tool designed to assist users in summarizing and extracting key information from text. By leveraging advanced natural language processing algorithms, Skim.ai can quickly analyze and condense lengthy documents, articles, or web pages into concise summaries. Users can easily access the summarized content, saving time and effort in information consumption. Skim.ai aims to enhance productivity and efficiency by providing a streamlined way to digest and comprehend textual data.
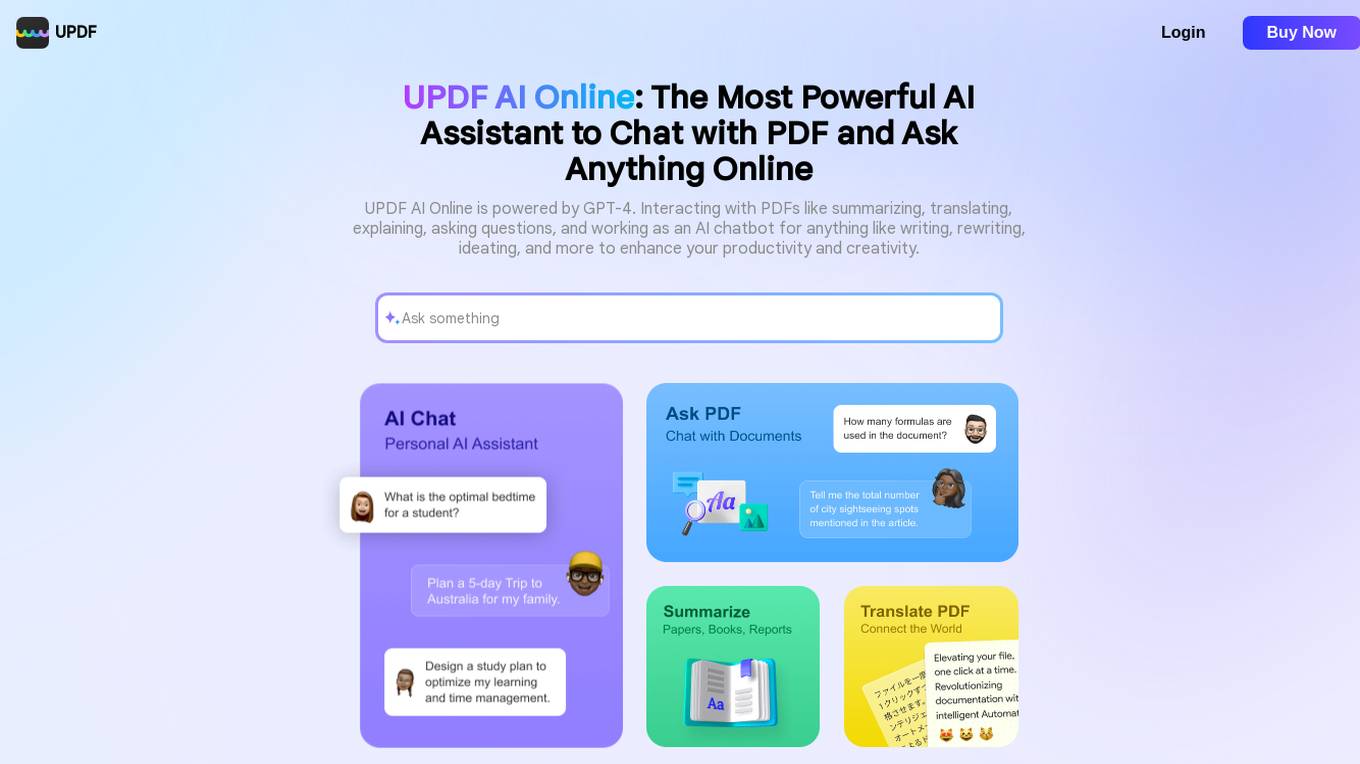
UPDF AI Online
UPDF AI Online is an AI-powered platform that allows users to interact with PDF documents through a chat interface. The platform is powered by GPT-4, a state-of-the-art language model, enabling users to ask questions, extract information, and perform various tasks on PDF files seamlessly. With UPDF AI Online, users can easily navigate through complex documents, search for specific content, summarize text, and much more, all through a conversational interface. The platform aims to simplify the way users interact with PDFs, making document management more efficient and user-friendly.
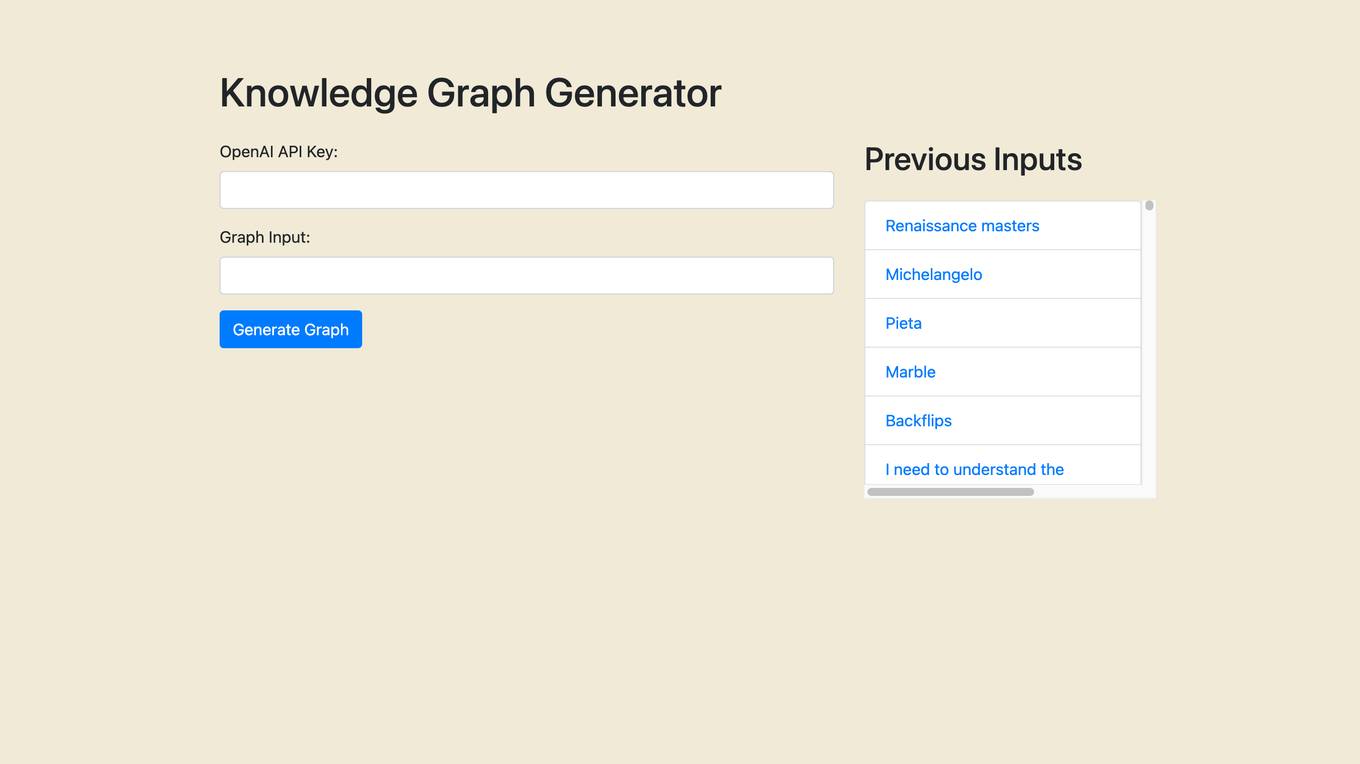
Knowledge Graph Generator
The website is an AI tool designed to generate a knowledge graph based on input text. It uses advanced algorithms and machine learning capabilities to streamline operations, deliver personalized experiences, and unlock new possibilities. Users can input text related to various topics, and the tool processes the information to create a structured knowledge graph.
FragDasPDF
**FragDasPDF** is an AI-powered tool that allows users to ask questions about PDF documents and receive answers in natural language. It supports a wide range of languages and can extract information from complex documents quickly and easily. With FragDasPDF, users can save time and effort by getting the information they need without having to read through long and dense documents.
Recap
Recap is an open-source browser extension that allows users to easily summarize any portion of a webpage using ChatGPT. It provides a convenient way to extract key information from online content, making it easier for users to digest and comprehend information quickly. With Recap, users can efficiently split and summarize text with the help of AI technology, enhancing their browsing experience and productivity.
BabblerAI
BabblerAI is an advanced artificial intelligence tool designed to assist businesses in analyzing and extracting valuable insights from large volumes of text data. The application utilizes natural language processing and machine learning algorithms to provide users with actionable intelligence and automate the process of information extraction. With BabblerAI, users can streamline their data analysis workflows, uncover trends and patterns, and make data-driven decisions with confidence. The tool is user-friendly and offers a range of features to enhance productivity and efficiency in data analysis tasks.

Daxtra
Daxtra is an AI-powered recruitment technology tool designed to help staffing and recruiting professionals find, parse, match, and engage the best candidates quickly and efficiently. The tool offers a suite of products that seamlessly integrate with existing ATS or CRM systems, automating various recruitment processes such as candidate data loading, CV/resume formatting, information extraction, and job matching. Daxtra's solutions cater to corporates, vendors, job boards, and social media partners, providing a comprehensive set of developer components to enhance recruitment workflows.

Summarizely
Summarizely.org is a website that provides a text summarization tool to help users condense lengthy articles or documents into shorter, more digestible versions. The tool uses advanced algorithms to analyze the content and generate concise summaries, saving users time and effort in extracting key information. Users can simply paste the text they want to summarize into the tool, and within seconds, receive a condensed version that captures the main points of the original text. Summarizely.org aims to enhance productivity and efficiency for individuals who need to quickly grasp the essence of complex information.
Chat With PDF AI Tool
The Chat With PDF AI Tool is an innovative application that allows users to interact with PDF documents using artificial intelligence technology. Users can engage in conversations with the AI tool to extract information, ask questions, and receive instant responses. The tool simplifies the process of working with PDF files by providing a conversational interface, making it user-friendly and efficient. With its advanced AI capabilities, the tool can understand natural language queries and provide accurate results, enhancing productivity and workflow efficiency.
Honeybear.ai
Honeybear.ai is an AI tool designed to simplify document reading tasks. It utilizes advanced algorithms to extract and analyze text from various documents, making it easier for users to access and comprehend information. With Honeybear.ai, users can streamline their document processing workflows and enhance productivity.
1 - Open Source AI Tools
awesome-deeplogic
Awesome deep logic is a curated list of papers and resources focusing on integrating symbolic logic into deep neural networks. It includes surveys, tutorials, and research papers that explore the intersection of logic and deep learning. The repository aims to provide valuable insights and knowledge on how logic can be used to enhance reasoning, knowledge regularization, weak supervision, and explainability in neural networks.
20 - OpenAI Gpts


Alien meaning?
What is Alien lyrics meaning? Alien singer:P. Sears, J. Sears,album:Modern Times ,album_time:1981. Click The LINK For More ↓↓↓
Website Speed Reader
Expert in website summarization, providing clear and concise info summaries. You can also ask it to find specific info from the site.
Create a Business 1-Pager Snippet v2
1) Input a URL, attachment, or copy/paste a bunch of info about your biz. 2) I will return a summary of what's important. 3) Use what I give you for other prompts, e.g.: marketing strategy, content ideas, competitive analysis, etc

Business Card Digitizer
Simply take a photo of your business cards and upload it to the chat. I'll take it from there!
Procedure Extraction and Formatting
Extracts and formats procedures from manuals into templates
Data Extractor Pro
Expert in data extraction and context-driven analysis. Can read most filetypes including PDFS, XLSX, Word, TXT, CSV, EML, Etc.
The Librarian
A digital librarian who identifies books from photos and provides detailed information.


Dissertation & Thesis GPT
An Ivy Leage Scholar GPT equipped to understand your research needs, formulate comprehensive literature review strategies, and extract pertinent information from a plethora of academic databases and journals. I'll then compose a peer review-quality paper with citations.
Information Framework Assistant
A SID framework companion for understanding and utilizing the Information Framework.
Gecko Tech Male Menopause Information
Information on male menopause, providing insights and explanations.