Best AI tools for< Generate Multimodal Content >
20 - AI tool Sites
Skywork AI
Skywork AI is an AI-powered productivity tool designed to revolutionize the way people work. It offers a range of features to enhance workflow efficiency and productivity, such as generating professional documents, slides, and reports in minutes, and providing instant answers from credible sources. Skywork AI is tailored for modern knowledge workers, including students looking to save time on research projects. With its AI Workspace Agents, Skywork AI aims to boost productivity by 10x, turning 8 hours of work into just 8 minutes.
Typeface
Typeface is a multimodal content hub built for enterprise growth. It is an enterprise-grade platform that provides access to the latest and best Generative AI (GenAI) models for all content types. Typeface also offers deep brand personalization, integrated workflows, and secure content ownership. With Typeface, businesses can boost their content output, transform existing material, and personalize content at scale.
Seedance 2.0
Seedance 2.0 is an AI video generator platform that allows users to create stunning videos from text or images. It leverages advanced multimodal AI technology to transform creative ideas into professional-quality content. The platform is free to start and caters to both beginners and professionals in video creation. Seedance 2.0 offers features such as text to video conversion, image to video conversion, and a showcase of professional work. Users can access resources, help center, blog, and API documentation on the website.

Lyria 3
Lyria 3 is an AI-powered application that transforms text, image, and video content into 30-second music clips with auto-generated lyrics, enhanced song structure, and SynthID watermarking. It simplifies music composition by automating manual tasks and offering better control over genre, tone, and mood. The application is designed for both non-musicians and professional creators, aiming to streamline the music production process and provide high-quality short-form audio outputs.
Wan 2.5.AI
Wan 2.5.AI is a revolutionary native multimodal video generation platform that offers synchronized audio-visual generation with cinematic quality output. It features a unified framework for text, image, video, and audio processing, advanced image editing capabilities, and human preference alignment through RLHF. Wan 2.5.AI is designed to transform creative challenges, support AI research and development, enhance interactive education, and facilitate creative prototyping.
Trendee
Trendee by Wissee Tech is a GEO-optimized AI content platform that enhances product visibility in the AI search era. It utilizes a multi-agent system to automatically optimize content strategies, ensuring AI recommendations that align with customer needs. Trendee offers user prompt simulation, AI visibility tracking, competitor intelligence, smart action center, content generation, and content distribution to empower brands in the digital landscape. It focuses on Generative Engine Optimization (GEO) to secure visibility and be recommended by AI platforms, catering to diverse industries such as fashion, cosmetics, home furnishings, and hardware tools.

BestBanner
BestBanner is a user-friendly online tool that allows users to easily convert text into visually appealing banners without the need for any prompts. With a simple and intuitive interface, users can quickly create eye-catching banners for various purposes such as social media posts, website headers, and promotional materials. BestBanner offers a wide range of customization options, including different fonts, colors, backgrounds, and effects, to help users create unique and professional-looking banners in just a few clicks. Whether you're a small business owner, a social media influencer, or a marketing professional, BestBanner is the perfect tool to enhance your online presence and make your content stand out.
Soca AI
Soca AI is a company that specializes in language and voice technology. They offer a variety of products and services for both consumers and enterprises, including a custom LLM for enterprise, a speech and audio API, and a voice and dubbing studio. Soca AI's mission is to democratize creativity and productivity through AI, and they are committed to developing multimodal AI systems that unleash superhuman potential.
MyCharacter.AI
MyCharacter.AI is a dApp built on the AI Protocol that leverages the CharacterGPT V2 Multimodal AI System to generate realistic, intelligent, and interactive AI Characters that are collectible on the Polygon blockchain.
Janus Pro AI
Janus Pro AI is a cutting-edge multimodal image generation and understanding platform that empowers users to create high-quality images for various projects. It offers powerful features such as multiple art styles, smart editing, lightning-fast image generation, high resolution output, commercial rights, and 24/7 generation service. The platform is built on DeepSeek's advanced architecture, providing users with a seamless experience in generating images in different styles and settings.
Seedance2 Pro
Seedance2 Pro is an unofficial AI video generator that allows users to create cinematic clips using text, images, videos, and audio references. It offers full API access and features like multimodal inputs, director control, and clip generation within the range of 4-15 seconds. Users can mix various references to maintain consistency, mimic camera moves, and enhance storytelling. The platform provides affordable access to AI video generation without the need for a Chinese phone number or local account.

Luma AI
Luma AI is an AI application that specializes in AI video generation using advanced models like Ray3 and Dream Machine. The platform aims to provide production-ready images and videos with precision, speed, and control. Luma AI focuses on building multimodal general intelligence to generate, understand, and operate in the physical world, catering to a new era of creativity and human expression.

GPT-4o
GPT-4o is an advanced multimodal AI platform developed by OpenAI, offering a comprehensive AI interaction experience across text, imagery, and audio. It excels in text comprehension, image analysis, and voice recognition, providing swift, cost-effective, and universally accessible AI technology. GPT-4o democratizes AI by balancing free access with premium features for paid subscribers, revolutionizing the way we interact with artificial intelligence.
ChatSlide
ChatSlide is an AI workspace for knowledge sharing that offers AI-powered features to create personalized slides, videos, charts, posters, and podcasts. It allows users to easily generate content and slides with the help of ChatSlide AI, supporting multimodal documents. Trusted by users in 170 countries and 29 languages, ChatSlide transforms complex documents into structured content, offering real-world use cases for industries like healthcare. With flexible pricing plans, ChatSlide aims to revolutionize content creation by leveraging AI technology.
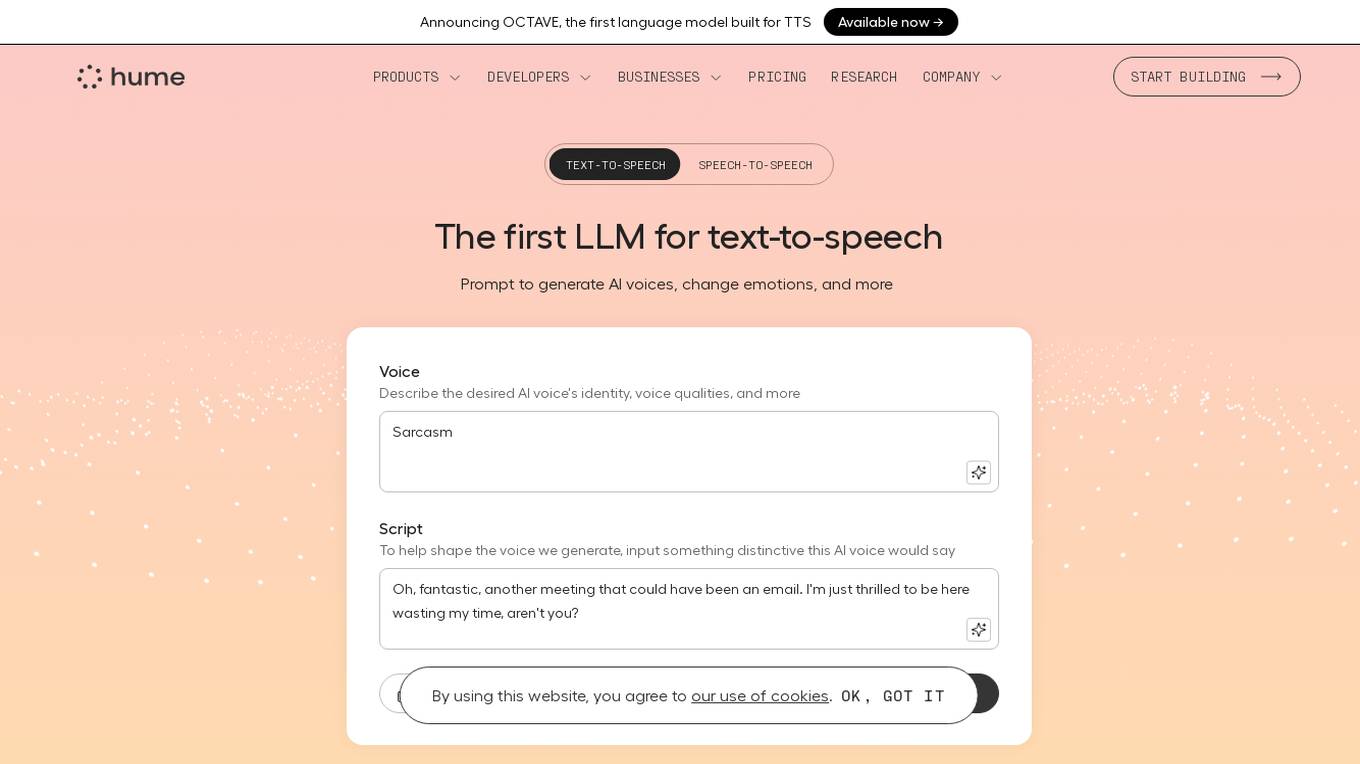
Hume AI - Octave
Hume AI is an AI application that offers the Octave language model for text-to-speech (TTS) capabilities. It provides a voice-based LLM that understands words in context to predict emotions, cadence, and more. Users can create various AI voices with specific prompts and scripts, adjusting emotional delivery and speaking styles on command. The application aims to generate expressive AI voices for podcasts, voiceovers, audiobooks, and more, with total control over the voice output.
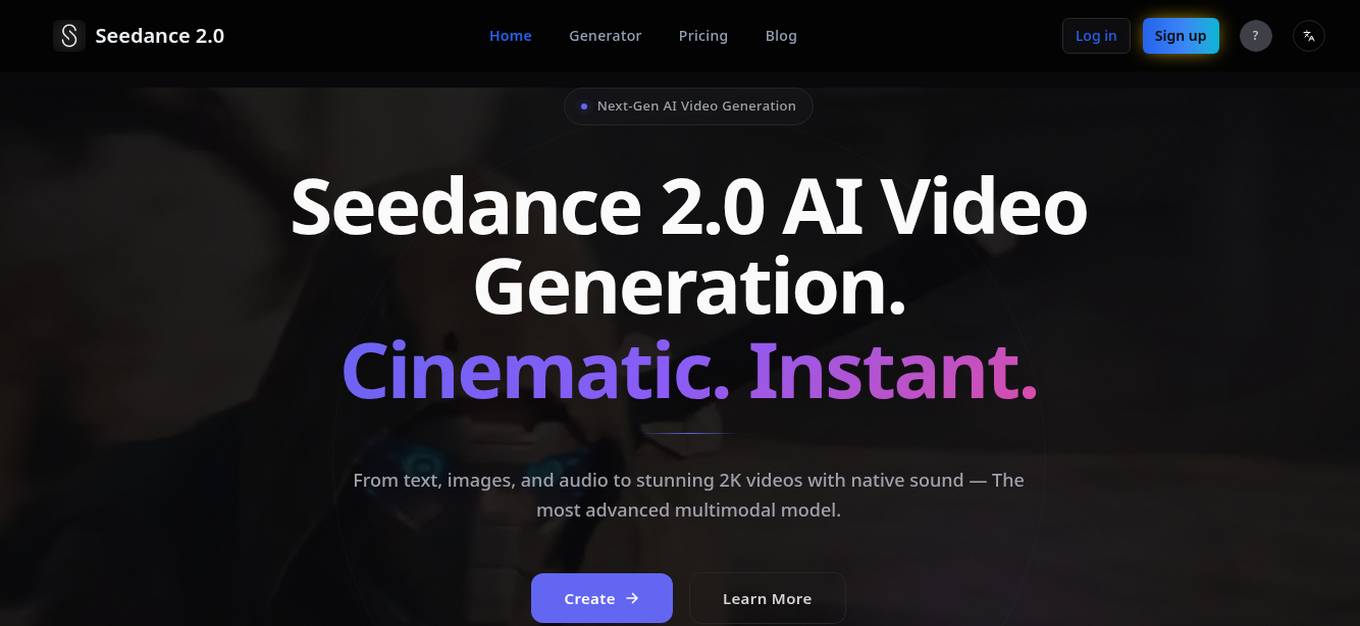
Seedance 2.0
Seedance 2.0 is a next-generation AI video generation tool that allows users to create cinematic-quality videos from text prompts, images, videos, and audio references. It features a multimodal input system, native audio generation with lip-sync, a physics engine for realistic motion, multi-shot narrative generation, and video editing capabilities. With Seedance 2.0, users can produce studio-quality videos at speed, with character consistency across shots and high fidelity to creative input.
ChatGPT4o
ChatGPT4o is OpenAI's latest flagship model, capable of processing text, audio, image, and video inputs, and generating corresponding outputs. It offers both free and paid usage options, with enhanced performance in English and coding tasks, and significantly improved capabilities in processing non-English languages. ChatGPT4o includes built-in safety measures and has undergone extensive external testing to ensure safety. It supports multimodal inputs and outputs, with advantages in response speed, language support, and safety, making it suitable for various applications such as real-time translation, customer support, creative content generation, and interactive learning.
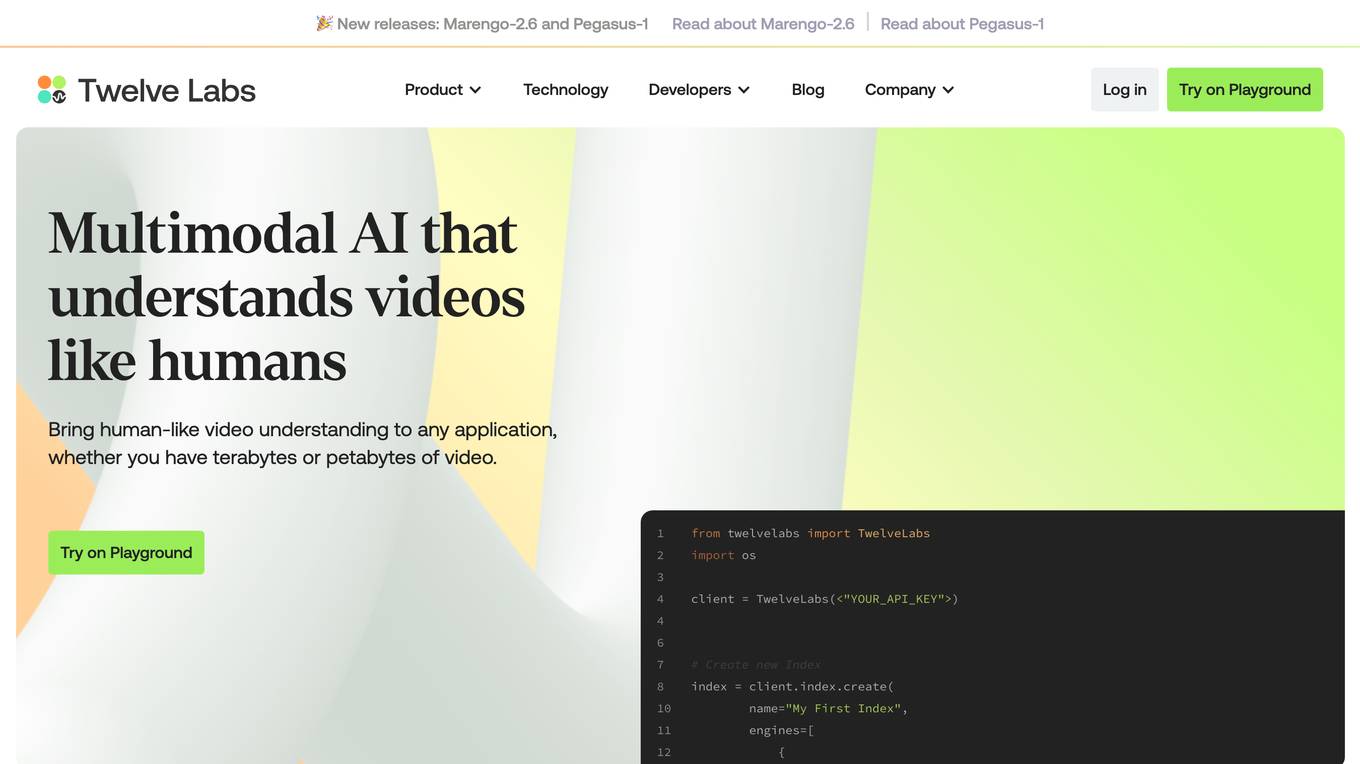
Twelve Labs
Twelve Labs is a cutting-edge AI tool that specializes in multimodal video understanding, allowing users to bring human-like video comprehension to any application. The tool enables users to search, generate, and embed video content with state-of-the-art accuracy and scalability. With the ability to handle vast video libraries and provide rich video embeddings, Twelve Labs is a game-changer in the field of video analysis and content creation.
Stable Diffusion 3
Stable Diffusion 3 is an advanced text-to-image model developed by Stability AI, offering significant improvements in image fidelity, multi-subject handling, and text adherence. Leveraging the Multimodal Diffusion Transformer (MMDiT) architecture, it features separate weights for image and language representations. Users can access the model through the Stable Diffusion 3 API, download options, and online platforms to experience its capabilities and benefits.
Runway
Runway is an AI tool that advances creativity by building multimodal AI systems to usher in a new era of human creativity. It offers a suite of creative tools designed to turn ideas into reality using AI models that understand and generate worlds. Runway empowers filmmakers to achieve their creative vision with AI, and it also hosts platforms and initiatives to celebrate and empower the next generation of storytellers.
1 - Open Source AI Tools
NExT-GPT
NExT-GPT is an end-to-end multimodal large language model that can process input and generate output in various combinations of text, image, video, and audio. It leverages existing pre-trained models and diffusion models with end-to-end instruction tuning. The repository contains code, data, and model weights for NExT-GPT, allowing users to work with different modalities and perform tasks like encoding, understanding, reasoning, and generating multimodal content.
20 - OpenAI Gpts

Angular Architect AI: Generate Angular Components
Generates Angular components based on requirements, with a focus on code-first responses.
🖌️ Line to Image: Generate The Evolved Prompt!
Transforms lines into detailed prompts for visual storytelling.
Generate text imperceptible to detectors.
Discover how your writing can shine with a unique and human style. This prompt guides you to create rich and varied texts, surprising with original twists and maintaining coherence and originality. Transform your writing and challenge AI detection tools!

Fantasy Banter Bot - Special Teams
I generate witty trash talk for fantasy football leagues.

Product StoryBoard Director
Helps you generate script keyframes, for better experience please visit museclip.ai
Visual Storyteller
Extract the essence of the novel story according to the quantity requirements and generate corresponding images. The images can be used directly to create novel videos.小说推文图片自动批量生成,可自动生成风格一致性图片
CodeGPT
This GPT can generate code for you. For now it creates full-stack apps using Typescript. Just describe the feature you want and you will get a link to the Github code pull request and the live app deployed.