Best AI tools for< Fuse Language Models >
1 - AI tool Sites
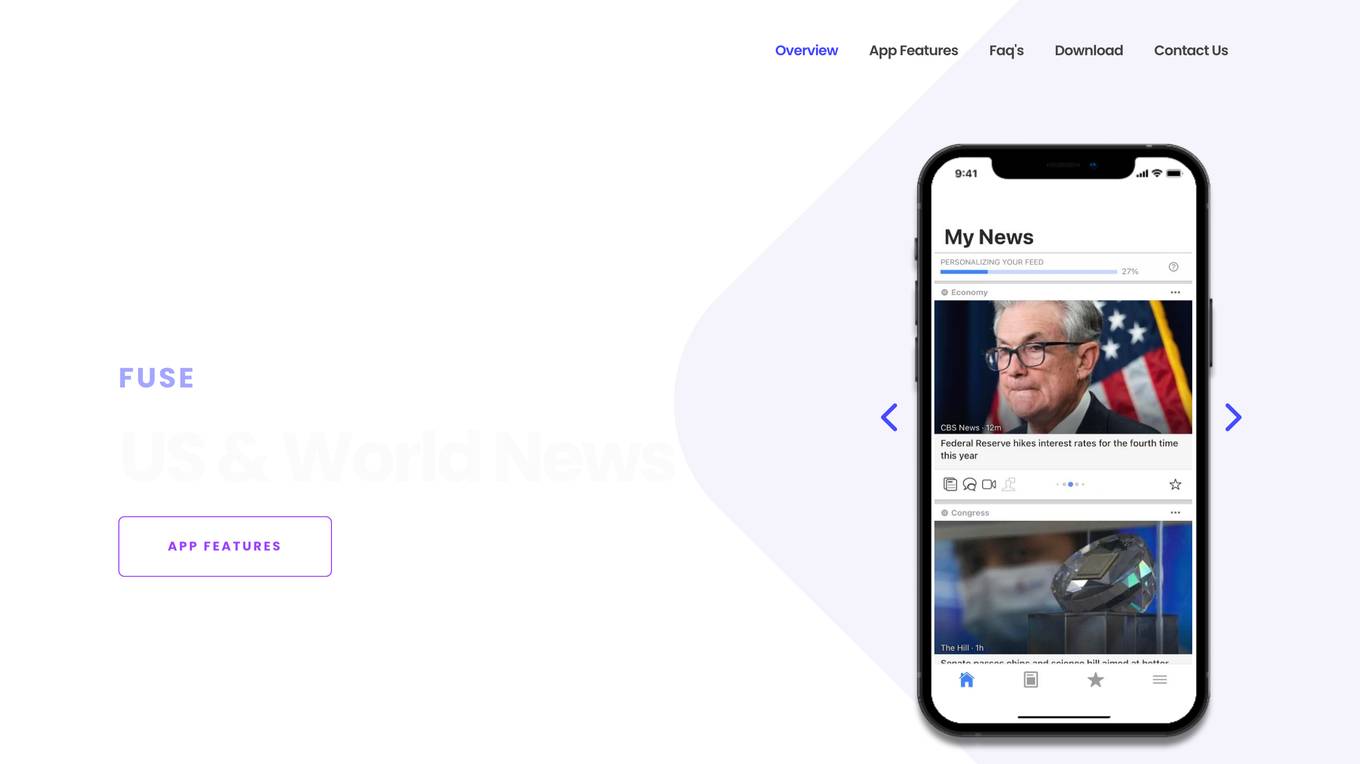
Fuse
Fuse is a smart news aggregator that delivers personalized and complete coverage of top news stories from the U.S. and around the world. Stories are covered from every angle - with articles, videos and opinions from trusted sources. Fuse employs AI/ML algorithms to continuously collect, organize, prioritize and personalize news stories. Articles, videos and opinions are collected from all the major news media outlets and automatically organized by stories and topics.
1 - Open Source AI Tools

FuseAI
FuseAI is a repository that focuses on knowledge fusion of large language models. It includes FuseChat, a state-of-the-art 7B LLM on MT-Bench, and FuseLLM, which surpasses Llama-2-7B by fusing three open-source foundation LLMs. The repository provides tech reports, releases, and datasets for FuseChat and FuseLLM, showcasing their performance and advancements in the field of chat models and large language models.
2 - OpenAI Gpts
PokedexGPT V3
Containing The Entire Pokemon Universe | All Gen Pokemon, Items, Abilities, Berrys, Eggs, Region Details, Etc | Battle Simulation | Upload Image for Pokedex to ID | Fuse Pokemon | Explore || Type Menu to see full options.
