Best AI tools for< Fuse And Deliver Data >
1 - AI tool Sites
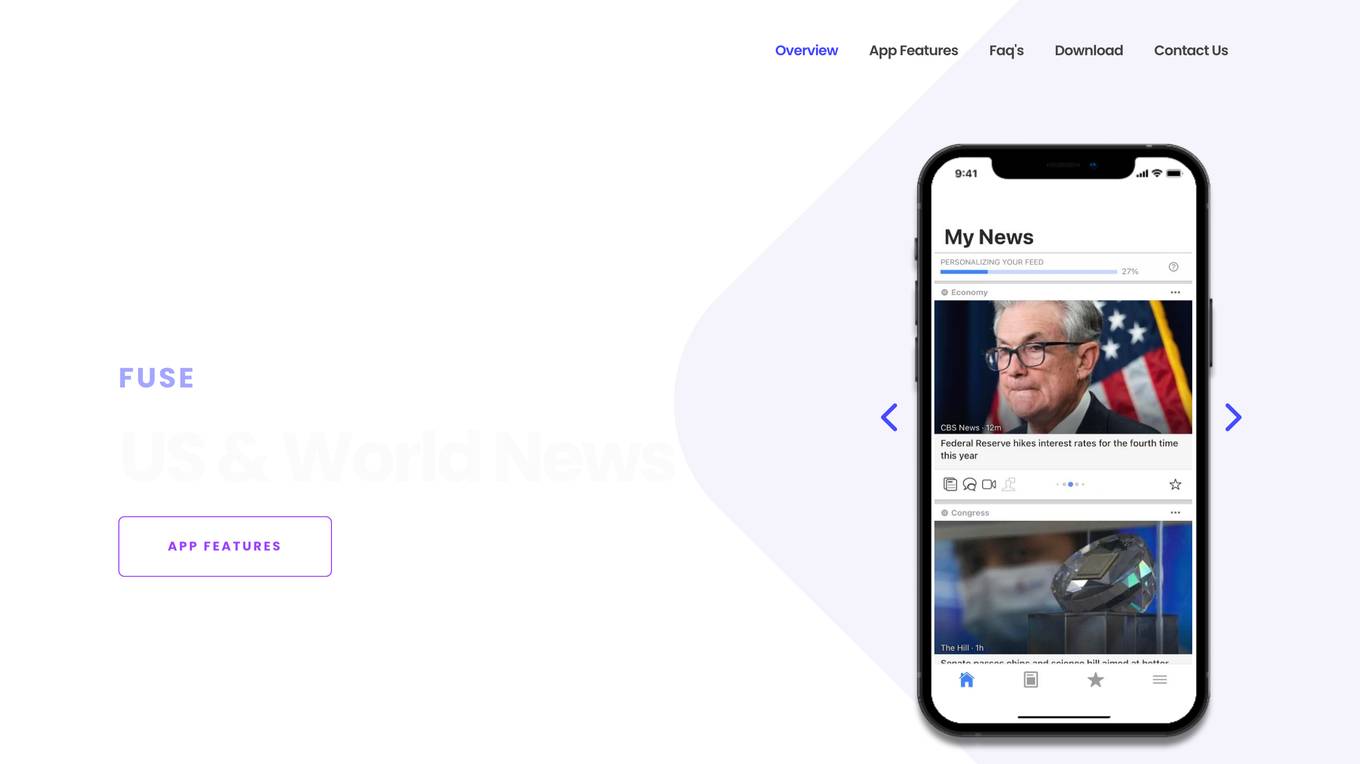
Fuse
Fuse is a smart news aggregator that delivers personalized and complete coverage of top news stories from the U.S. and around the world. Stories are covered from every angle - with articles, videos and opinions from trusted sources. Fuse employs AI/ML algorithms to continuously collect, organize, prioritize and personalize news stories. Articles, videos and opinions are collected from all the major news media outlets and automatically organized by stories and topics.
1 - Open Source AI Tools

spiceai
Spice is a portable runtime written in Rust that offers developers a unified SQL interface to materialize, accelerate, and query data from any database, data warehouse, or data lake. It connects, fuses, and delivers data to applications, machine-learning models, and AI-backends, functioning as an application-specific, tier-optimized Database CDN. Built with industry-leading technologies such as Apache DataFusion, Apache Arrow, Apache Arrow Flight, SQLite, and DuckDB. Spice makes it fast and easy to query data from one or more sources using SQL, co-locating a managed dataset with applications or machine learning models, and accelerating it with Arrow in-memory, SQLite/DuckDB, or attached PostgreSQL for fast, high-concurrency, low-latency queries.
2 - OpenAI Gpts
PokedexGPT V3
Containing The Entire Pokemon Universe | All Gen Pokemon, Items, Abilities, Berrys, Eggs, Region Details, Etc | Battle Simulation | Upload Image for Pokedex to ID | Fuse Pokemon | Explore || Type Menu to see full options.
