Best AI tools for< Fine-tune Outputs >
20 - AI tool Sites
Pony Diffusion
Pony Diffusion V6 XL is an AI tool designed for creating stunning SFW and NSFW visuals featuring various species through a text-to-image generation model. It offers an intuitive interface, community engagement, and open access license, making it ideal for artists and enthusiasts to explore creative possibilities and bring imaginative concepts to life.
SD3 Medium
SD3 Medium is an advanced text-to-image model developed by Stability AI. It offers a cutting-edge approach to generating high-quality, photorealistic images based on textual prompts. The model is equipped with 2 billion parameters, ensuring exceptional quality and resource efficiency. SD3 Medium is currently in a research preview phase, primarily catering to educational and creative purposes. Users can access the model through various licensing options and explore its capabilities via the Stability Platform.

FinetuneDB
FinetuneDB is an AI fine-tuning platform that allows users to easily create and manage datasets to fine-tune LLMs, evaluate outputs, and iterate on production data. It integrates with open-source and proprietary foundation models, and provides a collaborative editor for building datasets. FinetuneDB also offers a variety of features for evaluating model performance, including human and AI feedback, automated evaluations, and model metrics tracking.
QuickMail AI
QuickMail AI is an AI-powered email assistant that helps users craft professional emails in seconds. It utilizes AI technology to generate full, well-structured emails from brief prompts, saving users time and effort. The tool offers customizable outputs, allowing users to fine-tune emails to match their personal style. With features like AI-powered generation and time-saving efficiency, QuickMail AI is designed to streamline the email writing process and enhance productivity.
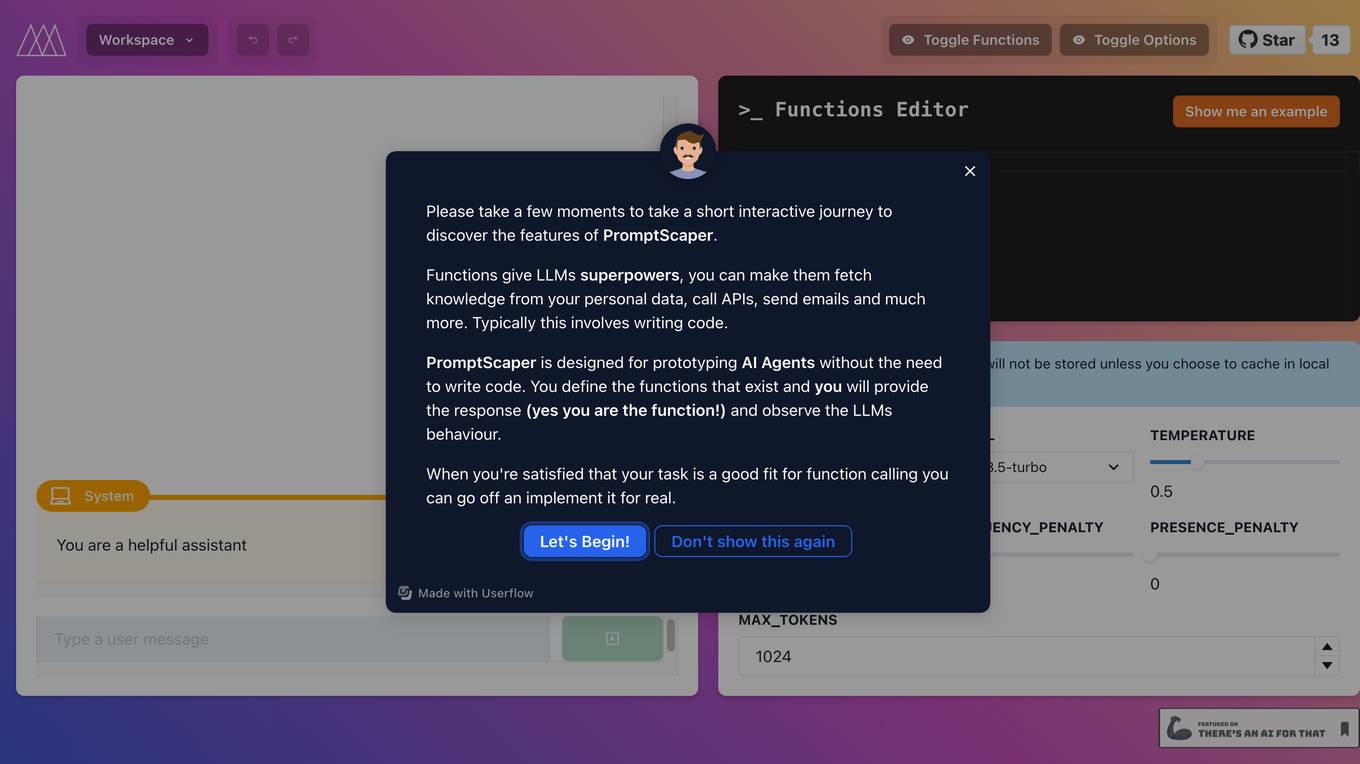
PromptScaper Workspace
PromptScaper Workspace is an AI tool designed to assist users in generating text using OpenAI's powerful language models. The tool provides a user-friendly interface for interacting with OpenAI's API to generate text based on specified parameters. Users can input prompts and customize various settings to fine-tune the generated text output. PromptScaper Workspace streamlines the process of leveraging advanced AI language models for text generation tasks, making it easier for users to create content efficiently.
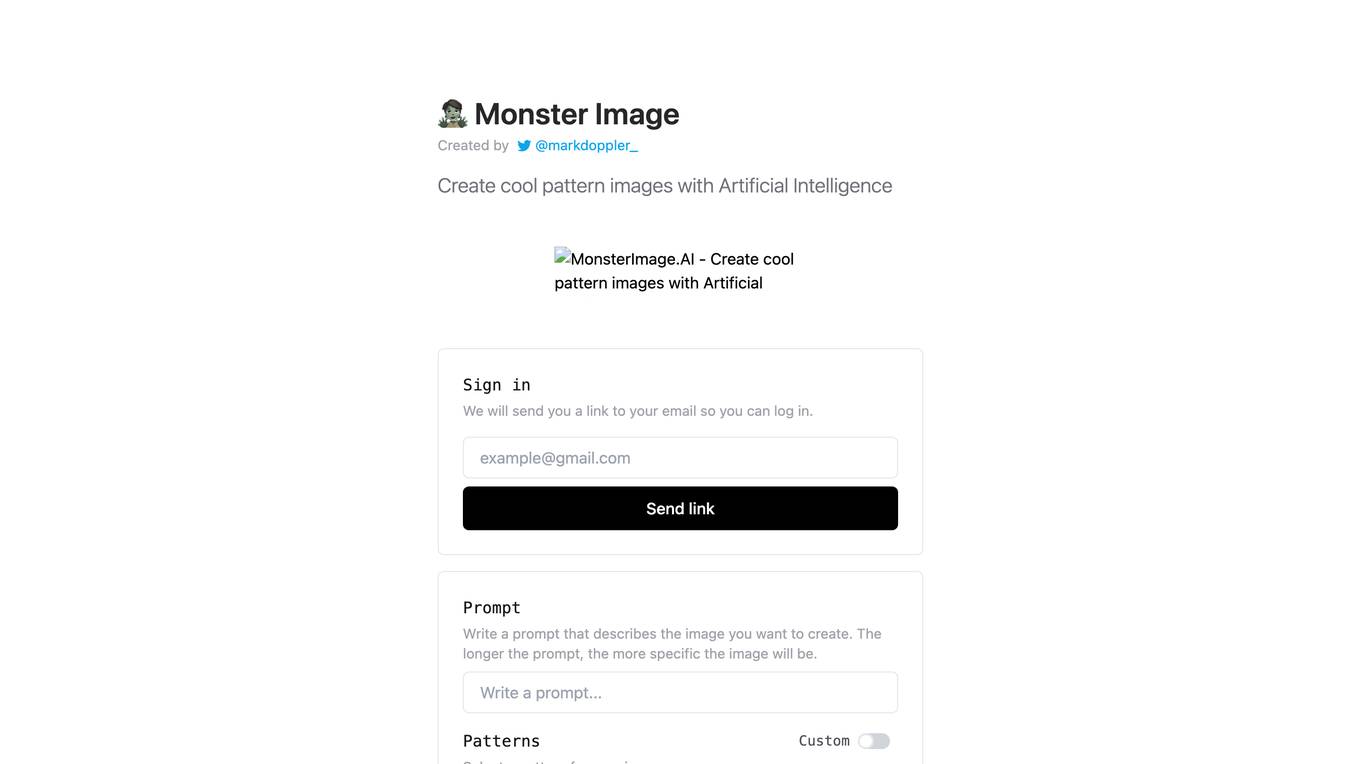
MonsterImage.AI
MonsterImage.AI is an AI-powered tool that allows users to create cool pattern images using Artificial Intelligence. Users can sign in to the platform and receive a link via email to log in. They can write a prompt to describe the image they want to create, select a pattern, specify negative prompts, use a seed for reproduction, adjust guidance scale, controlnet conditioning scale, and inference steps. The tool offers advanced options for creating images and allows users to save their creations in a public collection.

Narration Box
Narration Box is a text-to-speech tool that uses artificial intelligence to generate realistic voiceovers in over 70 languages. It offers a variety of features, including the ability to create multi-speaker content, fine-tune the voice's output, and generate speech in real-time. Narration Box is used by a variety of professionals, including authors, educators, product managers, marketing teams, founders, podcasters, content creators, media houses, and agencies.
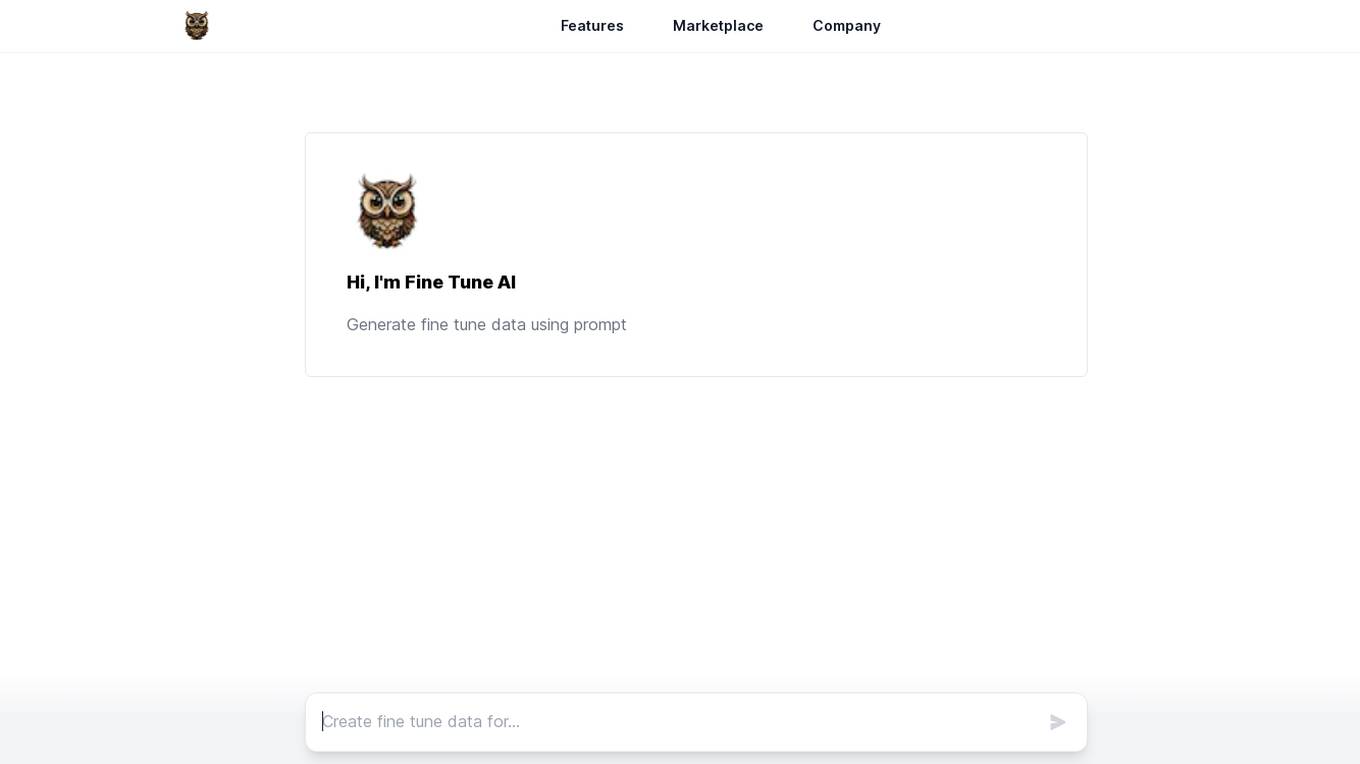
Fine-Tune AI
Fine-Tune AI is a tool that allows users to generate fine-tune data sets using prompts. This can be useful for a variety of tasks, such as improving the accuracy of machine learning models or creating new training data for AI applications.
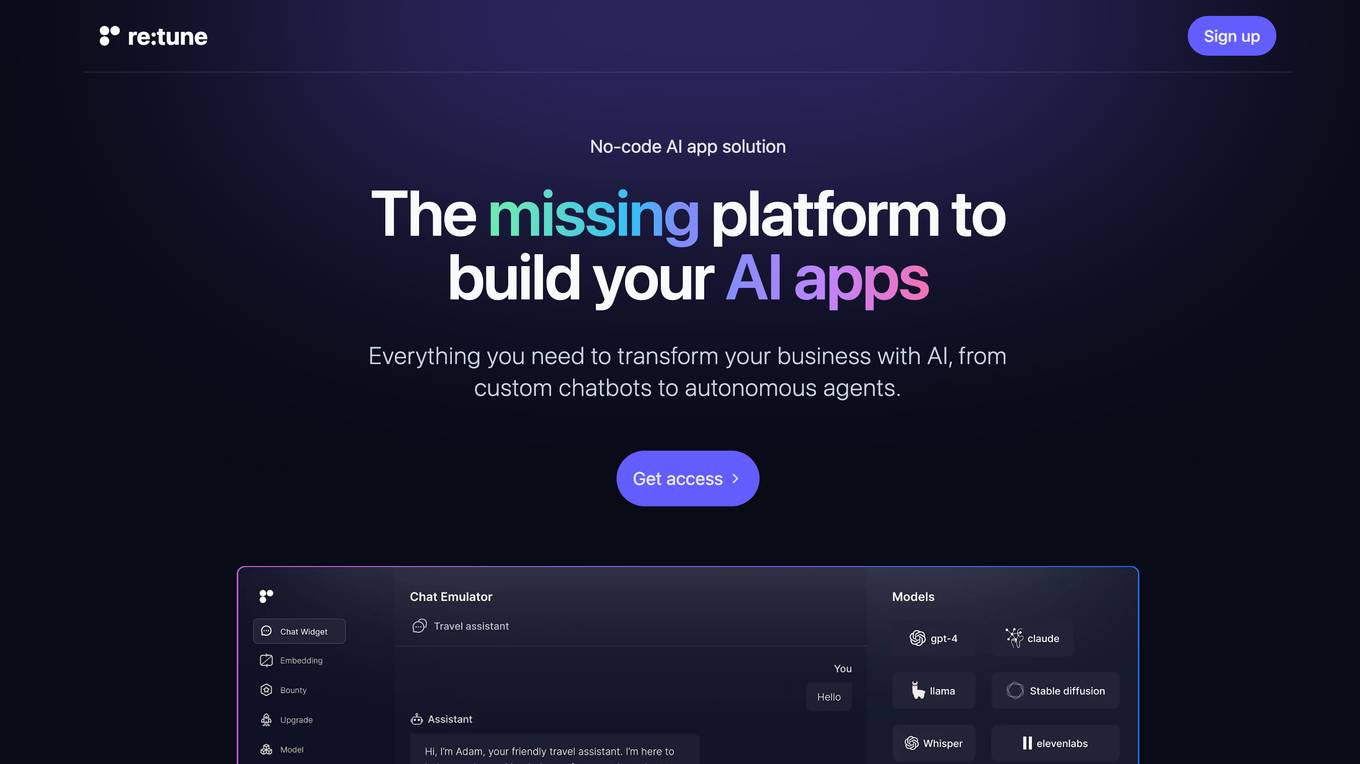
re:tune
re:tune is a no-code AI app solution that provides everything you need to transform your business with AI, from custom chatbots to autonomous agents. With re:tune, you can build chatbots for any use case, connect any data source, and integrate with all your favorite tools and platforms. re:tune is the missing platform to build your AI apps.

prompteasy.ai
Prompteasy.ai is an AI tool that allows users to fine-tune AI models in less than 5 minutes. It simplifies the process of training AI models on user data, making it as easy as having a conversation. Users can fully customize GPT by fine-tuning it to meet their specific needs. The tool offers data-driven customization, interactive AI coaching, and seamless model enhancement, providing users with a competitive edge and simplifying AI integration into their workflows.
FineTuneAIs.com
FineTuneAIs.com is a platform that specializes in custom AI model fine-tuning. Users can fine-tune their AI models to achieve better performance and accuracy. The platform requires JavaScript to be enabled for optimal functionality.

Sapien.io
Sapien.io is a decentralized data foundry that offers data labeling services powered by a decentralized workforce and gamified platform. The platform provides high-quality training data for large language models through a human-in-the-loop labeling process, enabling fine-tuning of datasets to build performant AI models. Sapien combines AI and human intelligence to collect and annotate various data types for any model, offering customized data collection and labeling models across industries.

Tune AI
Tune AI is an enterprise Gen AI stack that offers custom models to build competitive advantage. It provides a range of features such as accelerating coding, content creation, indexing patent documents, data audit, automatic speech recognition, and more. The application leverages generative AI to help users solve real-world problems and create custom models on top of industry-leading open source models. With enterprise-grade security and flexible infrastructure, Tune AI caters to developers and enterprises looking to harness the power of AI.

ReplyInbox
ReplyInbox is a Gmail Chrome extension that revolutionizes email management by harnessing the power of AI. It automates email replies based on your product or service knowledge base, saving you time and effort. Simply select the text you want to respond to, click generate, and let ReplyInbox craft a personalized and high-quality reply. You can also share website links and other documentation with ReplyInbox's AI to facilitate even more accurate and informative responses.
Predibase
Predibase is a platform for fine-tuning and serving Large Language Models (LLMs). It provides a cost-effective and efficient way to train and deploy LLMs for a variety of tasks, including classification, information extraction, customer sentiment analysis, customer support, code generation, and named entity recognition. Predibase is built on proven open-source technology, including LoRAX, Ludwig, and Horovod.
Imajinn AI
Imajinn AI is a cutting-edge visualization tool that utilizes AI technology to transform photos and images into stunning works of art. With a suite of AI-powered products and tools, users can create personalized children's books, printed couples portraits, profile picture photobooth images, product photo visualizations, and design unique sneakers. The tool also offers an AI plugin for WordPress websites, allowing users to generate royalty-free images effortlessly. Imajinn AI provides a fun and creative way to bring ideas to life, catering to individuals, small businesses, and enterprises alike.
Empower
Empower is a serverless fine-tuned LLM hosting platform that offers a developer platform for fine-tuned LLMs. It provides prebuilt task-specific base models with GPT4 level response quality, enabling users to save up to 80% on LLM bills with just 5 lines of code change. Empower allows users to own their models, offers cost-effective serving with no compromise on performance, and charges on a per-token basis. The platform is designed to be user-friendly, efficient, and cost-effective for deploying and serving fine-tuned LLMs.
Together AI
Together AI is an AI Acceleration Cloud platform that offers fast inference, fine-tuning, and training services. It provides self-service NVIDIA GPUs, model deployment on custom hardware, AI chat app, code execution sandbox, and tools to find the right model for specific use cases. The platform also includes a model library with open-source models, documentation for developers, and resources for advancing open-source AI. Together AI enables users to leverage pre-trained models, fine-tune them, or build custom models from scratch, catering to various generative AI needs.
Synthetic Data Generation for Agentic AI
The website provides information on Synthetic Data Generation for Agentic AI, offering high-quality, domain-specific synthetic data to accelerate the development of agentic workflows. It explains the technical implementation, benefits, and usage of synthetic data in training specialized agentic systems. The site also showcases related use cases, quick links for further exploration, and detailed steps for generating synthetic data.

JobHire
JobHire is an AI-powered job search automation platform that helps users find and apply to relevant job openings. It uses artificial intelligence to analyze and recreate users' resumes, making them more attractive to potential employers. JobHire also automatically creates email addresses and uses them to send responses to suitable vacancies, modifying users' resumes for each specific position. Additionally, it tracks responses from employers and provides users with a dashboard to track their progress.
0 - Open Source AI Tools
19 - OpenAI Gpts
Joke Smith | Joke Edits for Standup Comedy
A witty editor to fine-tune stand-up comedy jokes.
BrandChic Strategic
I'm Chic Strategic, your ally in carving out a distinct brand position and fine-tuning your voice. Let's make your brand's presence robust and its message clear in a bustling market.
AI绘画|画图|画画|超级绘图|牛逼dalle|painting
👉AI绘画,无视版权,精准创作提示词。👈1.可描述画面2.可给出midjourney的绘画提示词3.为每幅画作指定专属 ID,便于精调4.可以画绘制皮克斯拟人可爱动物。1. Can describe the picture . 2. Can give the prompt words for midjourney's painting . 3. Assign a unique ID to each painting to facilitate fine-tuning

Pytorch Trainer GPT
Your purpose is to create the pytorch code to train language models using pytorch


HuggingFace Helper
A witty yet succinct guide for HuggingFace, offering technical assistance on using the platform - based on their Learning Hub
Fine dining cuisine Chef (with images)
A Michelin-starred chef offering French-style plating and recipes.

Boundary Coach
Boundary Coach is now fine-tuned and ready for use! It's an advanced guide for assertive boundary setting, offering nuanced advice, practical tips, and interactive exercises. It will provide tailored guidance, avoiding medical or legal advice and suggesting professional help when needed.
Secret Somm
Enter the world of Secret Somm, where intrigue and fine wine meet. Whether you're a rookie or a connoisseur, your personal wine agent awaits—ready to unveil the secrets of the perfect pour. Your mission, should you choose to accept it, will lead to unparalleled wine discoveries.

The Magic Money Tree
Tell us your favourite animal and let us create some fine banknotes for you !
Prompt QA
Designed for excellence in Quality Assurance, fine-tuning custom GPT configurations through continuous refinement.
ArtGPT
Doing art design and research, including fine arts, audio arts and video arts, designed by Prof. Dr. Fred Y. Ye (Ying Ye)
Music Production Teacher
It acts as an instructor guiding you through music production skills, such as fine-tuning parameters in mixing, mastering, and compression. Additionally, it functions as an aide, offering advice for your music production hurdles with just a screenshot of your production or parameter settings.
Copywriter GPT
Your innovative partner for viral ad copywriting! Dive into viral marketing strategies fine-tuned to your needs!