Best AI tools for< Find Parks >
20 - AI tool Sites
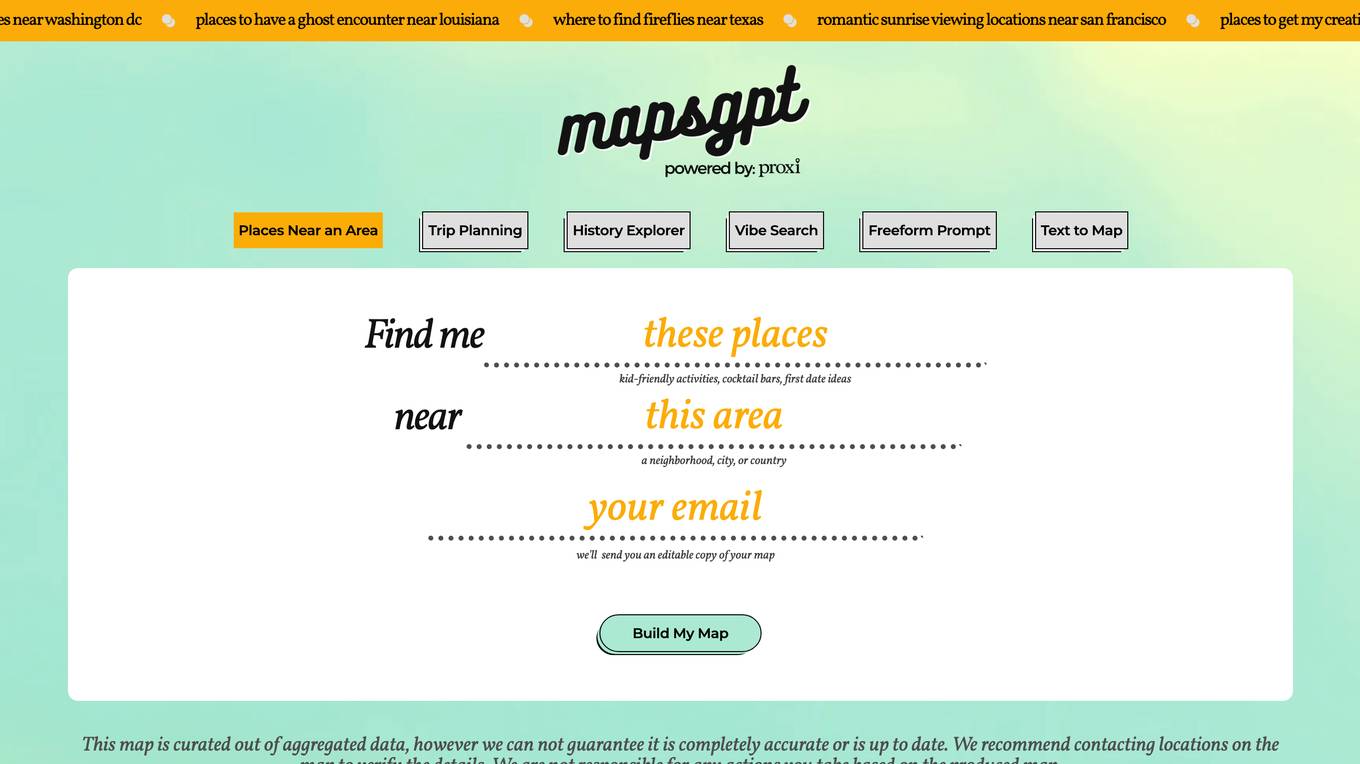
Proxi
Proxi is a web-based application that allows users to create custom maps with pins. Users can search for places near an area, plan day trips, explore history, find places with a specific vibe, and paste text to map the places. Proxi also offers a variety of map templates that users can customize to create their own maps.
Metropolis
Metropolis is an artificial intelligence company that provides checkout-free payment for drivers and revenue-generating operations for real estate owners. Metropolis' computer vision technology enables drivers to enter and exit parking facilities without having to stop and pay. Metropolis also offers a variety of other services, including parking management, valet services, and event parking. Metropolis is committed to providing a seamless and efficient parking experience for drivers and real estate owners alike.
Ai Drive
Ai Drive is an innovative AI-powered tool designed to streamline and enhance the driving experience. It utilizes advanced algorithms and machine learning to provide real-time navigation, traffic updates, and personalized recommendations to optimize routes. With its intuitive interface and smart features, Ai Drive aims to revolutionize the way people navigate and commute, making driving safer, more efficient, and enjoyable.
Leo AI
Leo AI is an AI-powered engineering design copilot tailored for mechanical engineers. It provides real answers, parts, and concepts to assist engineers in their design process. Leo leverages organization's data, centralizes engineering knowledge, handles problem-solving tasks, finds components using natural language, and helps brainstorm ideas collaboratively. The application aims to streamline the engineering process, reduce errors, accelerate onboarding, and promote consistency across teams.

ExpiredDomains.com
ExpiredDomains.com is a free online platform that helps users find valuable expired and expiring domain names. It aggregates domain data from hundreds of top-level domains (TLDs) and displays them in a searchable, filterable format. Whether you’re seeking domains with SEO authority, existing traffic, or strong brand potential, the platform provides tools and insights to support smarter decisions. Users can access over 1 million domains across 677+ TLDs with exclusive data metrics, a user-friendly interface, and professional trust. ExpiredDomains.com does not register domains itself but connects users to trusted external registrars and marketplaces like GoDaddy for domain purchases.

Daxtra
Daxtra is an AI-powered recruitment technology tool designed to help staffing and recruiting professionals find, parse, match, and engage the best candidates quickly and efficiently. The tool offers a suite of products that seamlessly integrate with existing ATS or CRM systems, automating various recruitment processes such as candidate data loading, CV/resume formatting, information extraction, and job matching. Daxtra's solutions cater to corporates, vendors, job boards, and social media partners, providing a comprehensive set of developer components to enhance recruitment workflows.
HarmonySnippetsAI
HarmonySnippetsAI is an AI application designed to help music creators and content producers identify engaging segments within their tracks quickly and efficiently. By leveraging AI algorithms, users can upload audio files and receive results that highlight the most captivating parts of their music. This tool is ideal for musicians looking to promote their work on social media platforms like Instagram, Facebook, and TikTok, enhancing audience engagement and expanding their reach.
Quackpad
Quackpad.co is a website that serves as a domain parking page created by Sedo. It provides resources and information related to domain ownership and management. The webpage does not offer any specific services or tools but rather acts as a placeholder for the domain owner. Users visiting the site can find general information about domain parking and may come across advertisements from third-party advertisers. Please note that Sedo, the platform behind Quackpad.co, does not endorse or control any specific services or trademarks mentioned on the page.
AIPodNav
AIPodNav is an AI-powered tool designed to enhance your podcast listening experience by providing features such as mind maps, summaries, takeaways, keywords, chapters, and transcriptions. It accelerates knowledge acquisition by 10 times faster than traditional podcast listening methods. AIPodNav aims to revolutionize how users engage with podcasts by offering innovative AI-driven functionalities.
Collato
Collato is an AI assistant designed to help product teams save time on writing documents, answering questions, and generating new content. It can find, summarize, and generate new content based on your own product knowledge, saving you hours in manual work. Collato is also self-hosted, so you can keep your data private and secure.
DoNotPay
DoNotPay is an AI-powered platform that helps consumers fight big corporations, protect their privacy, find hidden money, and beat bureaucracy. It offers a wide range of tools and services to help users with tasks such as disputing traffic tickets, canceling subscriptions, and getting refunds. DoNotPay is not a law firm and is not licensed to practice law. It provides a platform for legal information and self-help.

Whitetable
Whitetable is an AI tool that simplifies the hiring process by providing intelligent AI APIs for ultra-fast and optimal hiring. It offers features such as Resume Parsing API, Question API, Ranking API, and Evaluation API to streamline the recruitment process. Whitetable also provides a free AI-powered job search platform and an AI-powered ATS to help companies find the right candidates faster. With a focus on eliminating bias and improving efficiency, Whitetable is shaping the AI-driven future of hiring.
Translatioai
Translatioai.net is a domain currently listed for sale. The website provides resources and information related to translation and artificial intelligence. It seems to be a placeholder webpage generated by the domain owner using Sedo Domain Parking. Please note that Sedo, the domain parking service, does not have any direct relationship with third-party advertisers. The website does not offer any specific AI tool or application at the moment.
The Business Hero
The website the-business-hero.com provides resources and information for business owners and entrepreneurs. It seems to be a domain parking page generated by Sedo, a domain marketplace. The site offers general business-related content and may include articles, guides, and tips for running a successful business. Please note that the website does not have a specific focus or detailed information available.
ATS Friendly
ATS Friendly is a free resume checker that uses AI to help you get your resume shortlisted by Applicant Tracking Systems (ATS). With our comprehensive resume keyword scanner, our AI powered ATS Resume Checker will definitely enhance your chances of getting filtered through Applicant Tracking Systems (ATS). Our FREE ATS Friendly Resume Checker allows you to check your resume against the job posting, before applying. Our AI powered ATS Scanner will go through the keywords, hard skills, soft skills and other requirements of the job description, and provide you with a comprehensive analysis. We have helped over 100,000 job seekers to get shortlisted and hired faster. Try our Free ATS Checker now and get hired faster!

postai.pro
postai.pro is a domain that is currently up for sale. The website serves as a platform for the sale of the domain postai.pro. It was created using Sedo Domain Parking by the domain owner. The site provides information about the domain and offers it for sale to potential buyers. Please note that Sedo, the platform used to create the webpage, does not have any direct relationship with third-party advertisers. Any references to specific services or trademarks are not endorsed or controlled by Sedo.
ddle.dev
ddle.dev is a website that provides resources and information. It seems to be a domain parking page generated by Sedo, a domain marketplace. The site does not offer any specific services or tools but rather serves as a placeholder for the domain owner. Visitors may find general information about the domain and its ownership.

Posylanki.live
Posylanki.live is a website currently up for sale. The domain owner is offering it for sale at an asking price of 500 EUR. The webpage was created using Sedo Domain Parking. The website provides resources and information related to posylanki. Please note that Sedo, the platform used for domain parking, does not have any relationship with third-party advertisers. Any reference to a specific service or trademark is not controlled by Sedo and does not imply any association, endorsement, or recommendation by Sedo. Users can find the privacy policy on the website.
Hacker AI
Hacker-ai.online is a website that provides resources and information related to hacking and artificial intelligence. The webpage seems to be generated by the domain owner using Sedo Domain Parking. It is important to note that Sedo, the domain parking service, has no relationship with third-party advertisers. The website does not imply any association, endorsement, or recommendation of specific services or trademarks. Users can find resources and information on hacking and AI on this platform.
Find AI
Find AI is an AI-powered search engine that provides users with advanced search capabilities to unlock contact details and gain more accurate insights. The platform caters to individuals and companies looking to research people, companies, startups, founders, and more. Users can access email addresses and premium search features to explore a wide range of data related to various industries and sectors. Find AI offers a user-friendly interface and efficient search algorithms to deliver relevant results in a timely manner.
0 - Open Source AI Tools
20 - OpenAI Gpts
Toronto Parks and Rec Bot
Helpful Parks and Rec Bot for Toronto, built with Toronto civic open data.
Kenyan Parks
Welcome to your AI-powered Kenyan National Parks!! I am your friendly and personalized guide to Kenya's parks, wild animals, safaris and accommodation. I am here to help. Ask me anything!!
Orlando's Theme Park Planner
Your ultimate guide to Orlando's theme parks with insider tips, weather, lodging, and more!


KnopeGPT
Leslie Knope-inspired town council member, providing local info with charm and wit.
Outdoor Power Equipment Service Bot
Parts Lookup, Troubleshooting & Advice for Honda Outdoor Power Equipment << Release 0.01 ALPHA >>

Parking Sign Solver
Give me the time + day of week and upload your parking sign photo for a simple explanation.


Car Repair Manuals
Access free car repair manuals and auto repair manuals with our AI tool. Ideal for DIY car repair, use online car repair manuals and download car repair manuals. Discover the best car repair manuals for beginners and use car diagnostic tools. Buy car parts online and follow a car maintenance .
James Laplanche
James Laplanche est un expert renommé dans le domaine des casinos en ligne et un rédacteur éminent pour le site jeux.ca. Il possède une expertise approfondie dans les jeux de casino, les stratégies de paris et les nouvelles tendances de l'industrie.

Apple Foundation Complete Code Expert
A detailed expert trained on all 72,000 pages of Apple Foundation, offering complete coding solutions. Saving time? https://www.buymeacoffee.com/parkerrex ☕️❤️
Isle Royale Explorer
Isle Royale expert, offering guides on wildlife, history, camping, boating, and dining.